大数据时代的结构化存储--HBase
迄今,相信大家肯定听说过 HBase,但是对于 HBase 的了解可能仅仅是它是 Hadoop 生态圈重要的一员,是一个大数据相关的数据库技术。
今天我带你们一起领略一下 HBase 体系架构,看看它是如何大规模处理海量数据。
一、什么是 HBase?
关于 HBase 的实现,是基本遵循 Bigtable 的论文。HBase 是一个面向列的分布式数据库,也是个非关系型数据库系统(NoSQL),它建立在 Hadoop 文件系统之上。面向列的数据库是将数据表存储为数据列的一部分而不是数据行的数据库。
HBase 是一个分布式,持久,严格一致的存储系统,具有接近最佳的写入 I / O 通道饱和度和出色的读取性能。而且 HBase 只考虑单个索引,类似于 RDBMS 中的主键,提供服务器端实现灵活的二级索引解决方案。
二、为什么使用 HBase?
HBase 是 Hadoop 生态圈中重要的一环,用于存储,管理和处理数据。我们知道 Hadoop HDFS 是无法处理高速随机写入和读取,也无法在不重写文件的情况下对文件进行修改。HBase 正好解决了 HDFS 的缺点,因为它使用优化的方式快速随机写入和读取。此外,随着数据呈指数增长,关系数据库无法提供更好性能去处理海量的数据。HBase提供可扩展性和分区,以实现高效的存储和检索。
三、HBase 体系架构
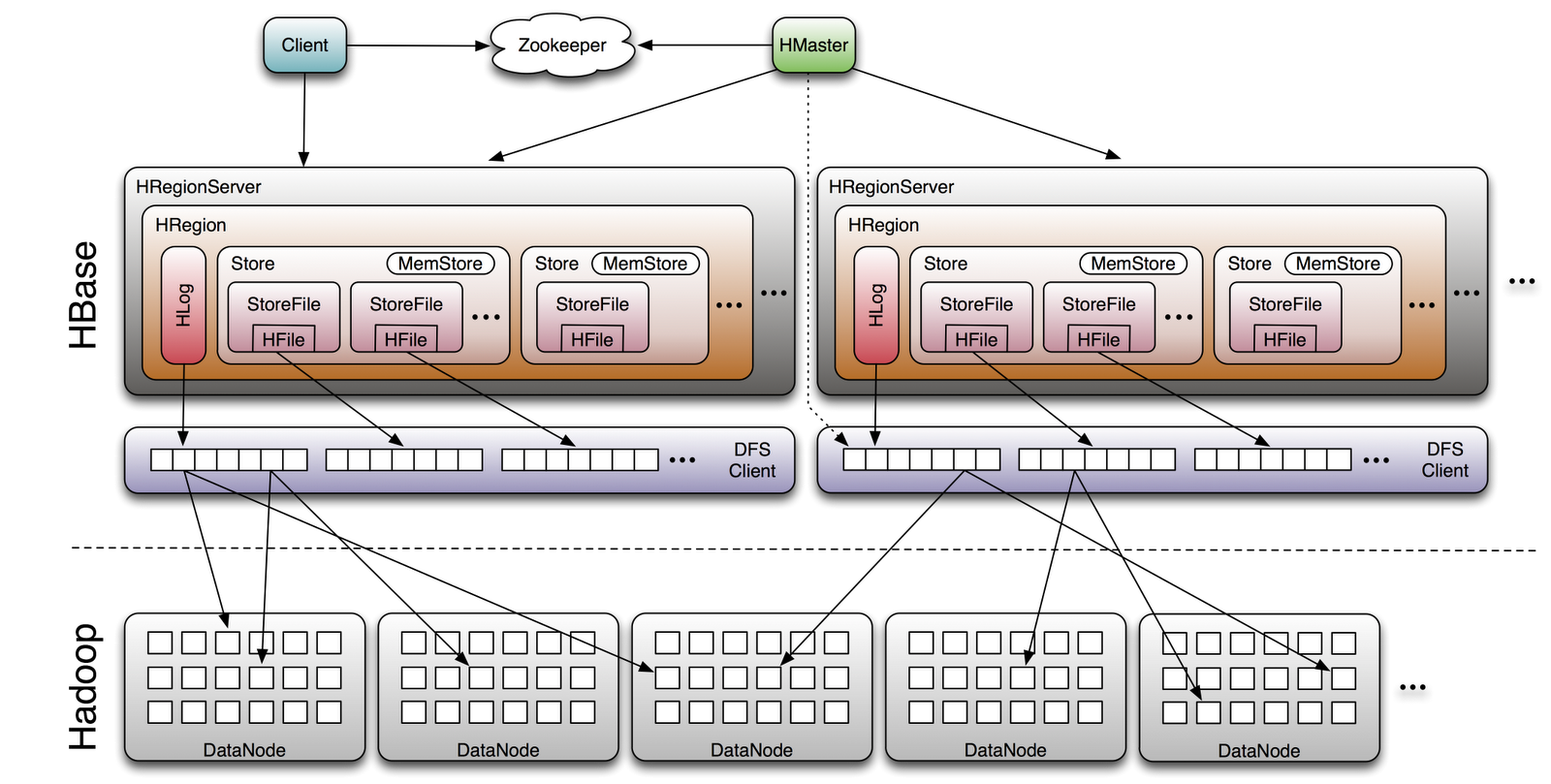
我们先来看看 HBase 的架构设计,由上图我们可以得知,HBase 主要由以下及部分组成:
Master
对 Region 进行负载均衡,分配到合适的 HRegionServer。
所有 HRegion 的信息,包括存储的 Key 值区间、所在 HRegionServer 地址、访问端口号等,都记录在 HMaster 服务器上。
ZooKeeper
HBase 会启动多个 HMaster,并通过 ZooKeeper 选举出一个主服务器。
Region Server
负责实际数据的读写. 当访问数据时, 客户端与 HBase 的 Region Server 直接通信。
Region: HBase 中的数据都是按 Rowkey 进行排序的,对这些按 Rowkey 排序的数据进行水平切分,每一片称为一个 Region。 当一个 Region 中数据量太多时,这个 Region 连同 HFile 会分裂成两个 Region,并根据集群中服务器负载进行迁移。
五、HBase 如何寻址?
如你所知,Zookeeper 存储 META 表。每当客户端对 HBase 的读取或写入请求时,就会发生以下操作:
1、 客户端从 ZooKeeper 中检索 META 表的位置。
2、 然后,客户端从 META 表请求相应 Rowkey 的 Region Server 的位置以访问它。客户端会缓存当前 META 表的信息。
3、 然后它将通过从相应的 Region Server 请求获取行位置。
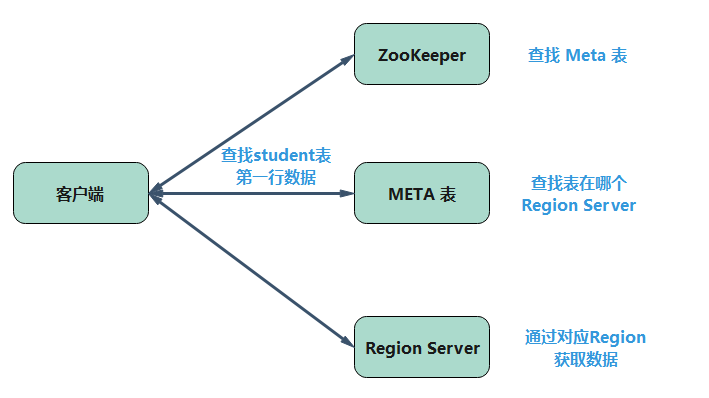
在这里有一个地方要注意,客户端会缓存 META 表信息,所以之后请求不会直接通过 META 表检索 Region Server 的位置,除非因为区域被移位或移动而导致查询失败。然后它才会再次请求 META 服务器并更新缓存。这样可以节省时间而且搜索过程会更快。
六、HBase 写机制
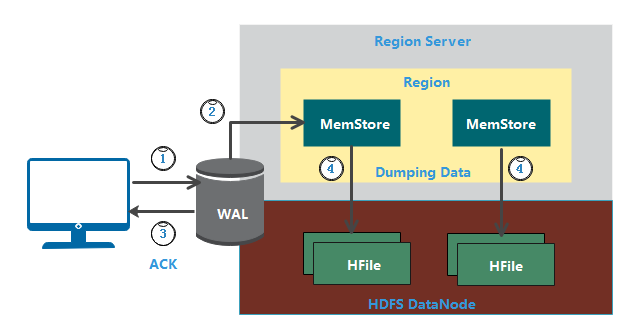
数据写入过程一样要进行寻址,需要先得到 Region Server 才能继续操作。写入机制按顺序执行以下过程(参见上图):
1、 每当客户端有写请求时,客户端将数据写入预写日 WAL;
- 新增附加到存储在磁盘上的 WAL 文件的末尾
- WAL 用于在服务器崩溃时恢复尚未保留的数据
2、 将数据写入 WAL 后,将其复制到 MemStore;
3、 将数据放入 MemStore 后,客户端将收到确认;
4、 当 MemStore 达到阈值时,它将数据转储或提交到 HFile。
MemStore
MemStore 在内存按照 Key 的顺序, 以 Key-Value 对进行存储。每个列族都有一个 MemStore,因此更新是以每个列族的排序方式存储。当 MemStore 达到阈值时,它会将已排序的所有数据转储到新的 HFile 中,HFile 存储在 HDFS 中。HBase 为每个列族包含多个 HFile。
MemStore 还保存了最后写入的序列号,因此 Master Server 和 MemStore 都知道,到目前为止提交的内容以及从哪里开始。当区域启动时,将读取最后一个序列号,并从该序列号开始新的写入。
HFile
写入顺序放在磁盘上。因此,磁盘读写磁头的移动非常少。这使得写入和搜索机制非常快。只要 HFile 打开,HFile索引就会加载到内存中。这有助于在单个搜索中查找记录。
七、什么情况应该使用HBase?
作为 NoSQL DB,HBase 提供了许多良好的功能,但它仍然不是适用所有情况的解决方案,进一步说它是为了解决某一些方面而存在的。当你的应用程序要使用 HBase,需要考虑一些关键因数。
数据量: 数据量是最常考虑。在分布式环境中一般处理 PB 级别的数据。否则,对于少量数据,它将在单个节点中存储和处理,而其他节点空闲,这是对技术框架的滥用。
吞吐量: HBase 其中一个最大优势就是接近最优的 I/O 读写速度,持续的大量的插入可以达到每秒百万的吞吐量。
关系特性: 应用程序对事务,触发器,复杂查询,复杂连接等 RDBMS 功能不做任何要求,HBase 对于这些基本都不支持。
除了以上几点,当需要在非关系环境中进行容错和可用的数据管理时,HBase也是合适的。在这里许多人会拿 RDBMS 和 Hbase 进行比较, 其实两者的对比毫无意义,从上面几点关键因数也可以看出,两者适用于不同的场景,比较是毫无意义的。
八、小结
HBase 是在 HDFS 之上运行的非关系型(NoSQL)数据库,提供对这些大型数据集的实时读/写访问。HBase 水平扩展使其处理具有数十亿行和数百万列的大量数据集,并且它可以轻松组合使用各种不同结构和模式的数据。正是如此,HBase 成为 Hadoop 生态圈 中重要的一环,用于存储,管理和处理大数据。

更多干货,欢迎关注公众号,哈尔的数据城堡,关注免费领取学习资料~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号