一条SQL语句的千回百转
SQL语言相信大家都不陌生,从本质上来说,它是一种结构化查询语言,是用来数据库之间的通信的编程语言。作为一名Java程序员,我们从Java角度来看,SQL语言相当于Java接口,而数据库是实现这个接口的实现类,SQL语句则是实现类的方法!!。从这里我们就可以理解了,每个数据库都有着自己独特的规则,但大体上是遵循SQL标准。
SQL 语句有一个让大部分人都感到困惑的地方,就是我写的 SQL 语句的跟我预想要的结果不一样。在这里,我们就以 Mysql 数据库为例,对一条 SQL 语句的执行顺序进行分析。
首先看一下示例语句

它的执行顺序是这样的

准备数据
我们会先准备一些数据,即创建 classes、student 表,并插入测试数据, SQL语句如下:
DROP TABLE classes;
CREATE TABLE classes (class_id varchar(10), class_name varchar(10)) ENGINE=InnoDB DEFAULT CHARSET=utf8 DEFAULT COLLATE=utf8_general_ci;
INSERT INTO classes (class_id, class_name) VALUES ('2', '2班');
INSERT INTO classes (class_id, class_name) VALUES ('1', '1班');
DROP TABLE student;
CREATE TABLE student (stu_name varchar(10), class_id varchar(10), stu_id varchar(10)) ENGINE=InnoDB DEFAULT CHARSET=utf8 DEFAULT COLLATE=utf8_general_ci;
INSERT INTO student (stu_name, class_id, stu_id) VALUES ('王五', '2', '124');
INSERT INTO student (stu_name, class_id, stu_id) VALUES ('王五', '2', '123');
INSERT INTO student (stu_name, class_id, stu_id) VALUES ('李四', '2', '122');
INSERT INTO student (stu_name, class_id, stu_id) VALUES ('李四', '1', '114');
INSERT INTO student (stu_name, class_id, stu_id) VALUES ('张三', '1', '112');
INSERT INTO student (stu_name, class_id, stu_id) VALUES ('张三', '2', '121');
INSERT INTO student (stu_name, class_id, stu_id) VALUES ('李四', '1', '113');
INSERT INTO student (stu_name, class_id, stu_id) VALUES ('张三', '1', '111');
INSERT INTO student (stu_name, class_id, stu_id) VALUES ('小红', '', '141');
INSERT INTO student (stu_name, class_id, stu_id) VALUES ('王五', '2', '125');
OK,有了数据之后,我们就可以来看看 SQL 语句在 MySQL 中执行过程了,SQL 语句如下:
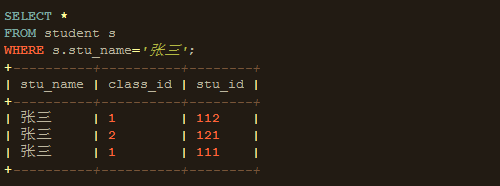
select stu_name as name,count(stu_name) total from student s left join classes c on s.class_id=c.class_id where stu_name in('张三','王五','李四') group by name HAVING count(stu_name)>2 order by stu_id desc limit 1;
SQL执行之旅
可能你现在还对 Mysql 语句的执行顺序一知半解,没关系,下来我将按 SQL 执行的顺序详细介绍每个关键字的作用,以及注意的地方。
1、FROM:对FROM子句中的前两个表执行笛卡尔积(交叉联接),生成虚拟表VT1。
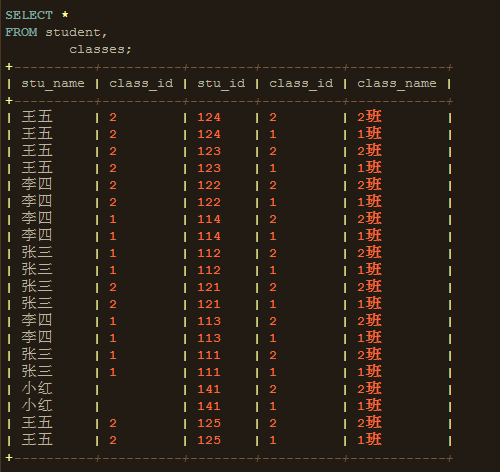
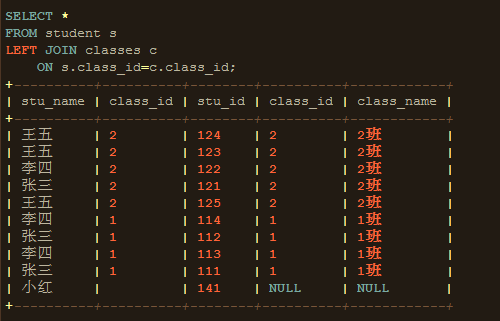
2、ON:对VT1应用ON筛选器,只有那些使为真才被插入到VT2。ON不能单独,在这里你可以把ON理解为WHERE。
3、JOIN:如果指定了OUTER JOIN(相对于CROSS JOIN或INNER JOIN),保留表(主表)中不符合ON条件匹配的行将作为外部行添加到VT2,生成VT3。如果FROM子句超过两个表,上一个联接生成的结果表会和下一个表重复执行步骤1到步骤3,直到处理完所有的表的关联。
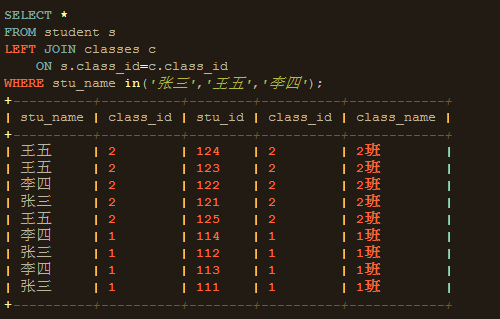
4、WHERE:对VT3应用WHERE筛选器,只有为true的行才插入VT4。
5、GROUP BY:按GROUP BY子句中的列列表对VT4中的行进行分组,生成VT5。
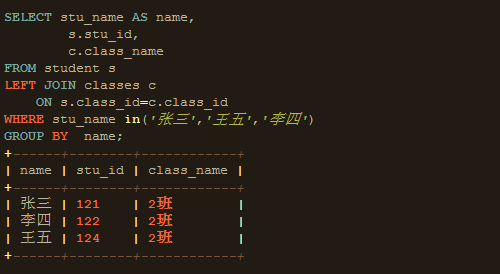
在这里会有一个奇怪的现象,MySQL执行顺序GROUP BY -> HAVING -> SELECT,从顺序看SELECL在GROUP BY之后,GROUP BY 应该不可以使用SELECT字段别名,但是在GROUP BY却可以使用SELECT字段别名,主要原因MySQL扩展了标准SQL,允许GROUP BY子句使用的SELECT子句中的别名以及和非列表表达式等标准, 并认为语句是有效的。
从MySQL 5.7.5开始,默认SQL mode模式包括 ONLY_FULL_GROUP_BY。(在5.7.5之前,MySQL不检测功能依赖性,ONLY_FULL_GROUP_BY默认情况下不启用。更多请参考:MySQL 5.7 Reference Manual-GROUP BY
6、HAVING :对VT5应用HAVING筛选器,只有为true的组插入到VT6。

HAVING同GROUP BY一样,MySQL拓展SQL标准以允许HAVING可以使用别名和非列表表达式
7、SELECT:将VT6每一组数据执行select xx,有几组就执行几次,产生VT7。
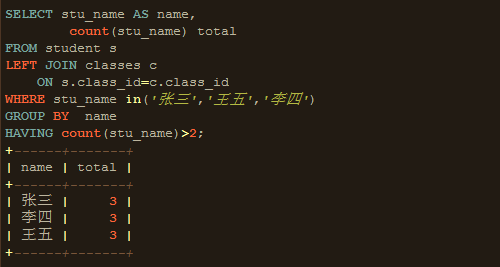
这里有一点要注意,当SQL mode 模式ONLY_FULL_GROUP_BY不开启,不会强制SELECT指定的字段必须属于GROUP BY后的条件。若符合条件的字段有多个,则只显示第一次出现的字段。虽然这种查询在语法上通过了,但结果并没有什么意义,因为其他字段并非需要的准确值。所以最好select语句指定的字段必须是“分组依据字段”。
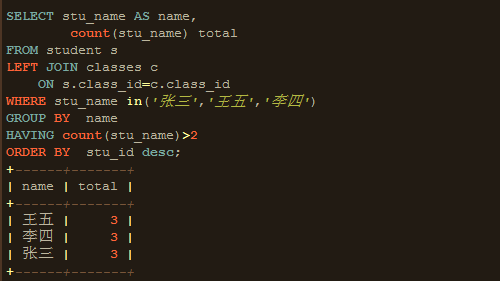
8、ORDER BY:将VT7中的行按ORDER BY子句中的列列表顺序,ORDER BY只能选择SELECT的字段
9、LIMIT:从VT7的开始处选择指定数量或比例的行,生成表VT8,并返回给调用者。
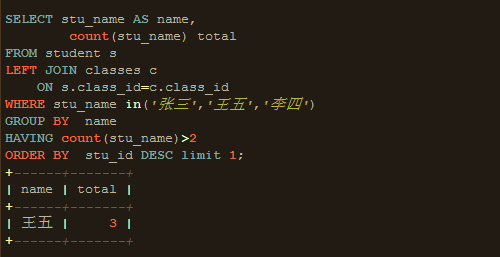
OK,到这里就执行结束了。我们可以发现,SQL 语句的语法顺序和执行顺序并不一致,如果你已经可以清醒知道它们之间差异,你就可以看出为什么以前写的SQL总是和我们预想的不一致。你看,哪怕只有一条小小的 SQL 语句都有这么多门道,只有不断专研探究,我们才可以真正掌握这一门技术。
这里多提一下,在SQL语法有几点要特别注意,SELECT虽然在GROUP BY和HAVING 之后,但是如果SQL mode模式 ONLY_FULL_GROUP_BY不开启,GROUP BY和HAVING是允许使用SELECT的字段,而且也不会强制SELECT指定的字段必须属于GROUP BY后的条件。至此SQL的解析之旅就结束了,最后用一张图总结一下今天的内容:


更多干货,欢迎关注公众号,哈尔的数据城堡,关注免费领取学习资料~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号