
MappReduce例子和总结02
1.计算每个人相应科目的平均分。
将同一个科目的放在一个文件中,并按照平均分从大到小排序。
部分数据文件:
1.创建对象并实现接口
public class NameScort implements WritableComparable { private String name; private String kemu; private Double score; @Override public int compareTo(Object o) {//按照成绩排序 NameScort scort=(NameScort) o; if (scort.getScore()<this.score){ return -1; }else { return 1; } } @Override public void write(DataOutput dataOutput) throws IOException {//读取的数据 dataOutput.writeDouble(this.score); dataOutput.writeUTF(this.name); dataOutput.writeUTF(this.kemu); } @Override public void readFields(DataInput dataInput) throws IOException {//写出的数据 this.score=dataInput.readDouble(); this.name = dataInput.readUTF(); this.kemu=dataInput.readUTF(); }
2.自定义分区
public class ScoreParta extends Partitioner<NameScort, NullWritable> {//和Mapp的k,v类型一致 @Override public int getPartition(NameScort text, NullWritable doubleWritable,int i) { if ("english".equals(text.getKemu())) { return 0; } else if ("math".equals(text.getKemu())) { return 1; } else if ("computer".equals(text.getKemu())) { return 2; } else if ("algorithm".equals(text.getKemu())) { return 3; } return 4; } }
3.编写MappReduce方法
public class WorkTest02 { public static class w2Mapp extends Mapper<LongWritable, Text,NameScort, NullWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split("\n"); String[] split1 = split[0].split(","); // String keys=split1[0]+" "+split1[1]; int j=0; double sum=0; for (int i=2;i<split1.length;i++){ sum+=Integer.parseInt(split1[i]); j++; } double avg=sum/j; NameScort scort=new NameScort(); scort.setKemu(split1[0]); scort.setName(split1[1]); scort.setScore(avg); context.write(scort,NullWritable.get()); } } public static class w2reduce extends Reducer<NameScort,NullWritable,NameScort,NullWritable>{ @Override protected void reduce(NameScort key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key,NullWritable.get()); } } public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(WorkTest02.class); job.setMapperClass(w2Mapp.class); job.setReducerClass(w2reduce.class); //设置map的k,v类型 job.setMapOutputKeyClass(NameScort.class); job.setMapOutputValueClass(NullWritable.class); //设置reduce的k,v类型 job.setOutputKeyClass(NameScort.class); job.setOutputValueClass(NullWritable.class); //设置分区数量 job.setNumReduceTasks(4); //根据返回值去往指定的分区 job.setPartitionerClass(ScoreParta.class); FileInputFormat.setInputPaths(job,"F:\\input\\score.txt"); Path path=new Path("F:\\out6"); FileSystem fs = FileSystem.get(conf); if (fs.exists(path)){ fs.delete(path,true); } FileOutputFormat.setOutputPath(job,path); job.submit(); } }
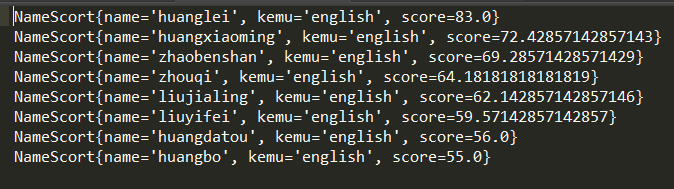
4.部分结果文件
2.MapJoin:当有多个文件要一起处理时,可以先将小文件读取到内存中,在和大文件一块处理
数据文件格式:两个文件


1.编写MapReducer方法
public class MappJoin { public static class mapp extends Mapper<LongWritable,Text,Text,NullWritable>{ HashMap<String,String> usermap=new HashMap(); @Override //先将小文件读取到内存中 protected void setup(Context context) throws IOException, InterruptedException { // String line=new String(value.getBytes(),0,value.getLength(),"GBK"); BufferedReader reader = new BufferedReader(new FileReader("F:\\input\\goods2.txt")); String line=""; while ((line=reader.readLine())!=null){ String[] split = line.split(","); usermap.put(split[0],split[1]); } } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line=new String(value.getBytes(),0,value.getLength(),"GBK"); String[] split = line.split(","); String s = usermap.get(split[0]); // String gbk = new String(s.getBytes(), "GBK"); context.write(new Text(split[0]+","+split[1]+","+s), NullWritable.get()); } public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(MappJoin.class); job.setMapperClass(mapp.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); job.setNumReduceTasks(0); FileInputFormat.setInputPaths(job,"F:\\input\\goods1.txt"); Path path=new Path("F:\\out7"); FileSystem fs = FileSystem.get(conf); if (fs.exists(path)){ fs.delete(path,true); } FileOutputFormat.setOutputPath(job,path); job.submit(); } } }
2.处理结果文件


 浙公网安备 33010602011771号
浙公网安备 33010602011771号