生而为人,我很抱歉!深夜爬虫, 我很抱歉 ,附微信 “ 网抑云” 公众号爬虫教程!
生而为人,我很抱歉!深夜爬虫, 我很抱歉 ,附微信 “ 网抑云” 公众号爬虫教程!
最近真的是被
网抑云这个梗刷爆了,到处都是, 生而为人,我很抱歉,哈哈哈, 碰巧最近学习了一波微信公众号的爬取方式,想试一试, 特地在此献丑了。我是小何, 不定期更新自动化测试教学, 其余时间学软件测试和linux中。 八月,继续加油。
关注我哟!!!
资料参考: 本篇博客,基于她的思想之中, 改编于我自己,我自己动手敲了一下, 发现还是存在很大的不同, 也是存在一点问题的, 所以这篇博客,我用我自己的话讲一下这次爬虫的思路,用简单的话说明白。
工具:
- 抓包工具 Fiddle 官网下载,有点慢
- 第三方包:
import requests
import json
from urllib.parse import urlencode
import pdfkit
# wkhtmltopdf github : https://github.com/JazzCore/python-pdfkit/wiki/Installing-wkhtmltopdf
import os
import warnings # 关闭警告
关于pdfkit 这是一个三方库, 它可以将html转换为pdf 或者 image 图像, 他需要一个软件的支持, 就是wkhtmltopdf wkhtmltopdf 官网 说一下, 官网我下了半小时都没动一下, 不知道是不是我个人原因, 推荐还是去第三方网站随便下一个,绝对比这个快!

下载之后, 在 bin 目录下 可以看到 wkhtmltopdf.exe 这个工具,先记下路径,后面需要用到。
打开fiddle,开始抓包
- 关于fiddle的基础配置, 在下载的时候,都会提到, 这里就不提了。
打开fiddle 随意打开一个微信公众号。往下拖动微信下拉条,让他加载更多文章,就像这样。
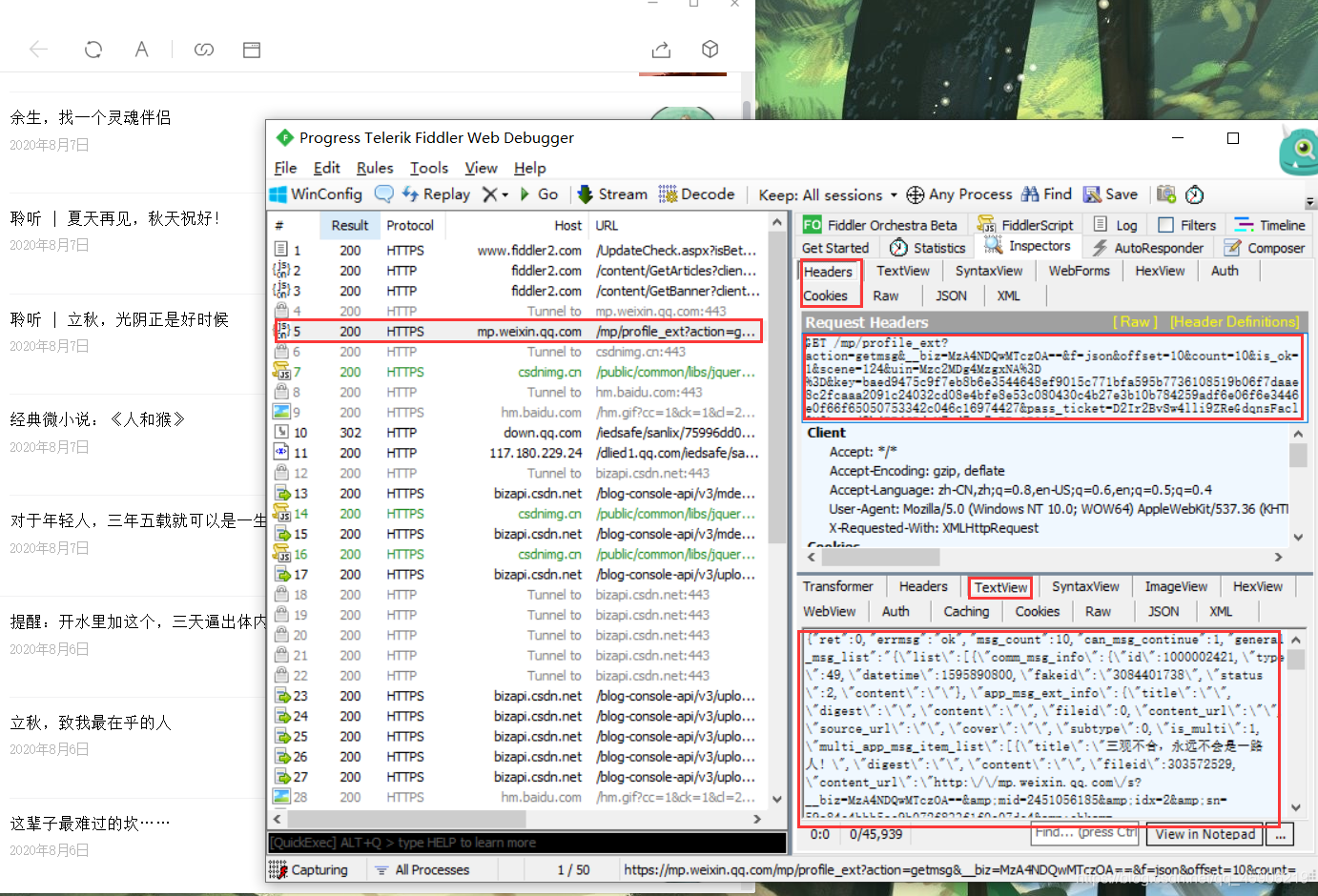
微信公众号的包很好分别的,主要他是一个json包, 而且通过网址我们也可以很好的认出来, 这张截图上注意的点我都标出来了。
其实这也可以理解成一个ajax请求吧, 我们只要构造一个字典参数加入,就可以构造成一个请求网址,这样就可以实现多页爬取了。原理我觉得差不多, 主要还是 构造参数 params 的甄别了,这个很重要, 有些参数没构造成功就不能正确的访问进去。
关于ajax的我也写了一篇博客, 可以进去看看 = =
那下面我们就开始编写爬虫吧!
构造基本参数:
一般我们所讲的基本参数 也就是浏览器的请求头, 还有一些请求参数, cookies之类的, 这里额外加一个 请求参数params , 看代码:
图方便, 这里也可以先构造一个文件 to_pdf
to_pdf.py
# -*- coding : utf-8 -*-
# @Time : 2020/8/6 18:31
# @author : 公众号【测试员小何】
# @Software : PyCharm
# @CSDN : https://me.csdn.net/qq_45906219
## to_pdf.py
# 目标公众号【测试员小何】
biz = 'MzA4NDQwMTczOA=='
# 微信登录后的一些标识参数
pass_ticket = 'DdDXKrOnQztW4p81Nm3nRQQ/EAFMCDz5MZO5KeBYdedjaZPH4nLFHL2LWE1uxHVJ'
appmsg_token = '1073_tnlzQTEqvlr9EgXQdC6zALGHfcJw4By9Bx69bQ~~'
uin = 'Mzc2MDg4MzgxNA=='
key = '360754e56e033319af5321321189d5b230b2bfe570313f76e4ed2ef0cd8a1fcfd087786d9da1d826ed30da55f477215359ba761e2a2af5f92213b05c17d89153631a537e35fc91f6d7fb3009e7113958'
# 安装的wkhtmltopdf.exe文件路径 这个是保存为pdf的 其实他还有保存为文件
wkhtmltopdf_path = r'D:\wkhtmltox\wkhtmltopdf\bin\wkhtmltopdf.exe'
上面提到一些 biz , passticket 之类参数的,我们可以在这里看到。
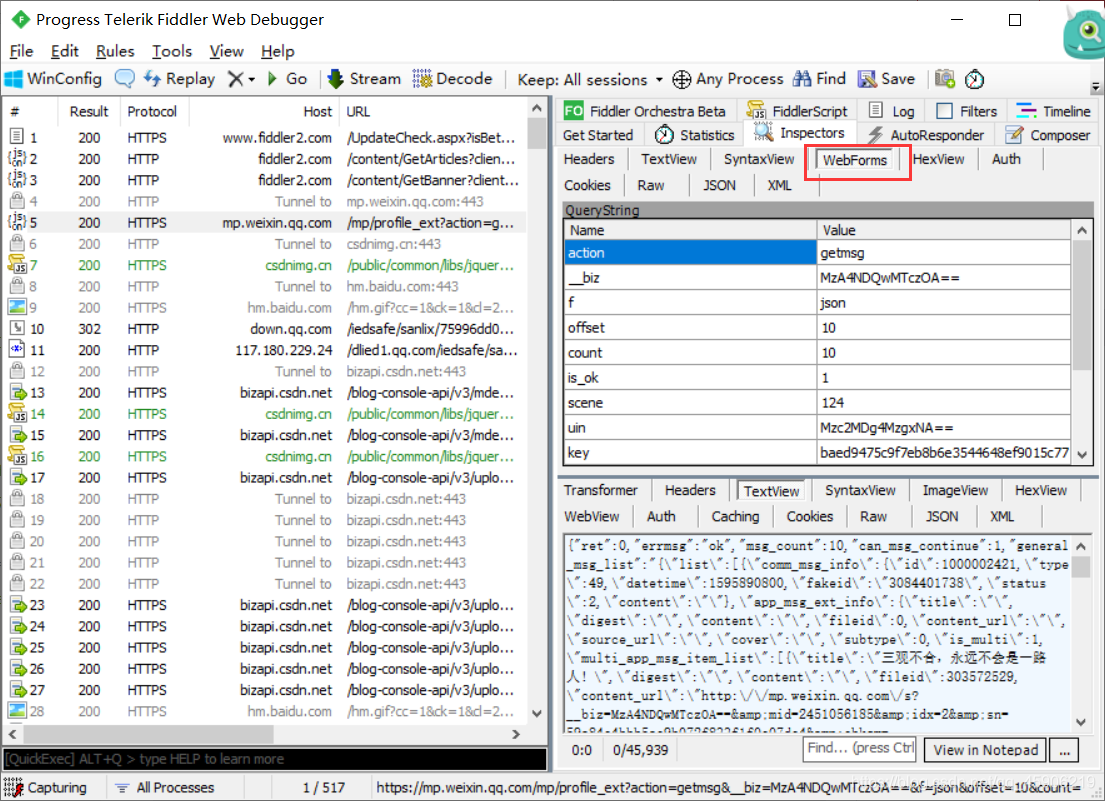
#公众号【测试员小何】
def __init__(self):
"""spider the wxChat station"""
self.session = requests.session()
self.offset = 0 # 偏移量
self.json_name = 'wxChat.json' # 保存json文件名
self.down_path = 'D:/wxChatPDF/' # 下载地址
self.__initGetBaseData()
def __initGetBaseData(self):
"""
input some BaseParams about the requests session
"""
self.headers = {
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.5;q=0.4',
"User-Agent": 这个太长了,在fiddle上面直接复制就可以
'X-Requested-With': 'XMLHttpRequest'
}
self.cookies = {
'wxtokenkey': '777',
"wxuin": "3760883814",
"devicetype": "android - 29",
"version": "27000",
"lang": "zh_CN",
"pass_ticket": to_pdf.pass_ticket,
"wap_sid2": "COaQqoEOElxramROblROTTRtTktEa29yU3drdExUODg4RjZCaVVsX3lycHV0VUJ"
"3aWtmMl9xNDlJVFN0YTZJY0NxdzZsTXdfaHJxMmZyTTRUZGlGdTZHNVEtNzh5REVFQUFBfjDDsK / 5BTgNQJVO"
}
self.profile_url = "https://mp.weixin.qq.com/mp/profile_ext?"
self.session.headers.update(self.headers) # 更新headers
self.session.cookies.update(self.cookies) # 更新cookies
self.params = {
'action': 'getmsg',
'__biz': to_pdf.biz,
'f': 'json',
'offset': '10', # 若需要多页爬取, 构造 : str(self.offset)
'count': '10',
'is_ok': '1',
'scene': '124',
'uin': to_pdf.uin,
'key': to_pdf.key, # 这个好像二十分钟就会失效, 需要隔段时间更换
'pass_ticket': to_pdf.pass_ticket,
'wxtoken': '',
'appmsg_token': to_pdf.appmsg_token,
'x5': '0',
}
这里讲一下 self.profile_url 这个参数, 我们在fiddle上面获得的网址是很长的一段, 其实只要卡到 ? 这里就可以了, 可以试试的。
请求网址, 通过json包,分割出标题和网址:
上面我们构造了一些参数,然后就可以正常的请求网址了,如下:
#公众号【测试员小何】
def run(self):
"""提取出标题和网址,
保存到json包 然后下载转换为Pdf"""
items = {}
for jsons in self.get_json():
json_list = jsons.get('general_msg_list')
json_list = json.loads(json_list) # 转换为json 类型
json_list1 = json_list.get('list')
for json_one in json_list1:
# 遍历这个列表字典 先解析最外层标题和网址
json_list_info = json_one.get('app_msg_ext_info')
title = json_list_info.get('title')
content_url = json_list_info.get('content_url')
items[title] = content_url # 装入字典
json_list_info1 = json_list_info.get('multi_app_msg_item_list')
for json_two in json_list_info1: # 解析第二层标题和网址
title2 = json_two.get('title')
content_url2 = json_two.get('content_url')
items[title2] = content_url2
# 转换字典类型
items_json = json.dump(items, ensure_ascii=False, indent=4,
fp=self.json_name) # ensure_ascii=False(输出中文), indent=4(缩进为4)
# 先写入文件,避免占用太多内存消耗
with open(self.json_name, 'a+', encoding='utf-8') as fw:
fw.write(items_json)
print('dump the wxChat.json is successful!')
# 下载ok之后, 就开始下载
self.down()
def get_json(self):
"""得到所有文章的链接
构造一个office偏移量 不断的请求构造网址 分析Json包
"""
print('【ps】 spider the wxChart is starting!')
for i in range(1, 2):
print(f'The SpiderDemo is spider doing {i} pages')
# self.offset += 10 * i # 开启这个 表示 多页爬取
# 对比了很多次 构造网址 和 原网址 还是有很多的区别 在这里改一改才能正确的成功
self.profile_url += (urlencode(self.params) + '&f=json HTTP/1.1')
self.profile_url = self.profile_url.replace('%3D%3D&f=json', '==&f=json', 1)
r = self.session.get(self.profile_url, verify=False)
yield r.json()
这里发现了一个很大的问题, 不管是在 get() 里面构造字典, 还是先构造字典,都发现我不能正确的获取到数据, 最后打印了一下构造网址, 发现存在很大问题。
我构造的
https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MzA4NDQwMTczOA%3D%3D&f=json&offset=10&count=10&is_ok=1&scene=124&uin=Mzc2MDg4MzgxNA%3D%3D&key=9a979acccbefb6032e6ea1a3ed3fbe82a67e7244eb884c9b4fd497550577b4c57f82cb7c0998ef8dc91cf1dca069ca16fe8cce902f238a72294726745094a68c5efb99f91df5e2592c7540ec90d5b09b&pass_ticket=DdDXKrOnQztW4p81Nm3nRQQ%2FEAFMCDz5MZO5KeBYdedjaZPH4nLFHL2LWE1uxHVJ&wxtoken=&appmsg_token=1073_tnlzQTEqvlr9EgXQdC6zALGHfcJw4By9Bx69bQ~~&x5=0&f=json
从fiddle上面复制的
https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MzA4NDQwMTczOA==&f=json&offset=10&count=10&is_ok=1&scene=124&uin=Mzc2MDg4MzgxNA%3D%3D&key=9a979acccbefb6032e6ea1a3ed3fbe82a67e7244eb884c9b4fd497550577b4c57f82cb7c0998ef8dc91cf1dca069ca16fe8cce902f238a72294726745094a68c5efb99f91df5e2592c7540ec90d5b09b&pass_ticket=D2Ir2BvSw4lli9ZReGdqnsFacl0N6Lnpmj9h4EE4CBdqV7cd7co7eRRnOBO4EsG%2F&wxtoken=&appmsg_token=1073_o%252FrQqQ5kpRJZNWMKabr8tLelugCSKx8mIN5IGQ~~&x5=0&f=json HTTP/1.1
对比了一下,发现我自己的url 第一个 == 变成了 %3D%3D , 后缀也少了很多。然后进行了修改, 最后成功进入了。
如下:
#公众号【测试员小何】
self.profile_url += (urlencode(self.params) + '&f=json HTTP/1.1')
self.profile_url = self.profile_url.replace('%3D%3D&f=json', '==&f=json', 1)
上面的代码包括很多json的拆分, 这个我推荐一个网址, 很好用。

可以在线解析 json 包, 在线解析json
读入本地文件,下载html,转换pdf
上面我们代码中讲到, 为了减少内存的占用, 我把文件先保存到本地了,那么现在就可以直接读取本地文件,代码如下:
#公众号【测试员小何】
def pathisok(self, path):
"""判断目录是否存在, 不存在就创建 进入文件"""
if not os.path.exists(self.down_path):
os.mkdir(self.down_path)
def down(self):
"""
打开json包,根据标题,网址开始下载,
爬取之后保存的格式可以很多种,这里我使用一下之前学到的一个新工具 to_pdf
将网页转换为html页面
"""
self.pathisok(self.down_path)
with open(self.json_name, 'r', encoding='utf-8') as fr:
for index in fr:
if ':' in index: # 判断是否是不是标题和网址
title = index.strip().split(':')[0]
url = ''.join(index.strip().split(':')[1:]).strip(',')
# 对网址进一步处理
url = url.replace('http', 'https:')
# 如果不修改文件名称 一定会报错 OsError的错误 找了很久
title = title.replace('\\', '').replace('/', '').replace(':', '').replace(':', '') \
.replace('*', '').replace('?', '').replace('?', '').replace('“', '') \
.replace('"', '').replace('<', '').replace('>', '').replace('|', '_')
print('- ' * 40)
print(f'The title is {title} starting spider')
print('- ' * 40)
# print(os.path.join(self.down_path, title + '.pdf'))
pdfkit.from_url(url, os.path.join(self.down_path, title + '.pdf'),
configuration=pdfkit.configuration(wkhtmltopdf=to_pdf.wkhtmltopdf_path))
# pdfkit.from_url(value, os.path.join(self.savedir, key + '.pdf'),
# configuration=pdfkit.configuration(wkhtmltopdf=self.cfg.wkhtmltopdf_path))
print('- ' * 40)
print(f'The title is {title} spider is successful')
print('- ' * 40)
else:
pass
这里要注意一点的, 关于文件的名称,有的时候爬虫我们给文件起名称不会在意很多细节, 如果文件名中有特殊符号, 或者其他不允许的符号,那么创建文件或者目录就会报错, 大致就是IOError 之类的错误了。 所以我们需要对 Title 进行再一次的修改, 确保不会出现问题。
打开pdf, 深夜了,打开 ‘网抑云’ 。
好了, 这就是本次爬虫的全部过程了。
全部代码:
如果对软件测试有兴趣,想了解更多的测试知识,解决测试问题,以及入门指导,
帮你解决测试中遇到的困惑,我们这里有技术高手。如果你正在找工作或者刚刚学校出来,
又或者已经工作但是经常觉得难点很多,觉得自己测试方面学的不够精想要继续学习的,
想转行怕学不会的,都可以加入我们644956177或者关注公众号【测试员小何】领取资料哦~。
群内可领取最新软件测试大厂面试资料和Python自动化、接口、框架搭建学习资料!
# -*- coding : utf-8 -*-
# @Time : 2020/8/6 17:00
# @author : 公众号【测试员小何】
# @Software : PyCharm
# @CSDN : https://me.csdn.net/qq_45906219
import requests
import json
from urllib.parse import urlencode
import pdfkit
# wkhtmltopdf github : https://github.com/JazzCore/python-pdfkit/wiki/Installing-wkhtmltopdf
import os
import warnings
warnings.filterwarnings('ignore')
class wxChatSpider(object):
def __init__(self):
"""spider the wxChat station"""
self.session = requests.session()
self.offset = 0
self.json_name = 'wxChat.json'
self.down_path = 'D:/wxChatPDF/' # 下载地址
self.__initGetBaseData()
def run(self):
"""提取出标题和网址,
保存到json包 然后下载转换为Pdf"""
items = {}
for jsons in self.get_json():
json_list = jsons.get('general_msg_list')
json_list = json.loads(json_list) # 转换为json 类型
json_list1 = json_list.get('list')
for json_one in json_list1:
# 遍历这个列表字典 先解析最外层标题和网址
json_list_info = json_one.get('app_msg_ext_info')
title = json_list_info.get('title')
content_url = json_list_info.get('content_url')
items[title] = content_url # 装入字典
json_list_info1 = json_list_info.get('multi_app_msg_item_list')
for json_two in json_list_info1: # 解析第二层标题和网址
title2 = json_two.get('title')
content_url2 = json_two.get('content_url')
items[title2] = content_url2
# 转换字典类型
items_json = json.dump(items, ensure_ascii=False, indent=4,
fp=self.json_name) # ensure_ascii=False(输出中文), indent=4(缩进为4)
# 先写入文件,避免占用太多内存消耗
with open(self.json_name, 'a+', encoding='utf-8') as fw:
fw.write(items_json)
print('dump the wxChat.json is successful!')
# 下载ok之后, 就开始下载
self.down()
def get_json(self):
"""得到所有文章的链接
构造一个office偏移量 不断的请求构造网址 分析Json包
"""
print('【ps】 spider the wxChart is starting!')
for i in range(1, 2):
print(f'The SpiderDemo is spider doing {i} pages')
# self.offset += 10 * i # 开启这个 表示 多页爬取
# 对比了很多次 构造网址 和 原网址 还是有很多的区别 在这里改一改才能正确的成功
self.profile_url += (urlencode(self.params) + '&f=json HTTP/1.1')
self.profile_url = self.profile_url.replace('%3D%3D&f=json', '==&f=json', 1)
r = self.session.get(self.profile_url, verify=False)
yield r.json()
def pathisok(self, path):
"""判断目录是否存在, 不存在就创建 进入文件"""
if not os.path.exists(self.down_path):
os.mkdir(self.down_path)
def down(self):
"""
打开json包,根据标题,网址开始下载,
爬取之后保存的格式可以很多种,这里我使用一下之前学到的一个新工具 to_pdf
将网页转换为html页面
"""
self.pathisok(self.down_path)
with open(self.json_name, 'r', encoding='utf-8') as fr:
for index in fr:
if ':' in index: # 判断是否是不是标题和网址
title = index.strip().split(':')[0]
url = ''.join(index.strip().split(':')[1:]).strip(',')
# 对网址进一步处理
url = url.replace('http', 'https:')
# 如果不修改文件名称 一定会报错 OsError的错误 找了很久
title = title.replace('\\', '').replace('/', '').replace(':', '').replace(':', '') \
.replace('*', '').replace('?', '').replace('?', '').replace('“', '') \
.replace('"', '').replace('<', '').replace('>', '').replace('|', '_')
print('- ' * 40)
print(f'The title is {title} starting spider')
print('- ' * 40)
# print(os.path.join(self.down_path, title + '.pdf'))
pdfkit.from_url(url, os.path.join(self.down_path, title + '.pdf'),
configuration=pdfkit.configuration(wkhtmltopdf=to_pdf.wkhtmltopdf_path))
# pdfkit.from_url(value, os.path.join(self.savedir, key + '.pdf'),
# configuration=pdfkit.configuration(wkhtmltopdf=self.cfg.wkhtmltopdf_path))
print('- ' * 40)
print(f'The title is {title} spider is successful')
print('- ' * 40)
else:
pass
def __initGetBaseData(self):
"""
input some BaseParams about the requests session
"""
self.headers = {
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.5;q=0.4',
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36"
" (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1301.400 "
"QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64)"
" AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2875.116"
" Safari/537.36 NetType/WIFI MicroMessenger/7.0.5 WindowsWechat",
'X-Requested-With': 'XMLHttpRequest'
}
self.cookies = {
'wxtokenkey': '777',
"wxuin": "3760883814",
"devicetype": "android - 29",
"version": "27000",
"lang": "zh_CN",
"pass_ticket": to_pdf.pass_ticket,
"wap_sid2": "COaQqoEOElxramROblROTTRtTktEa29yU3drdExUODg4RjZCaVVsX3lycHV0VUJ"
"3aWtmMl9xNDlJVFN0YTZJY0NxdzZsTXdfaHJxMmZyTTRUZGlGdTZHNVEtNzh5REVFQUFBfjDDsK / 5BTgNQJVO"
}
self.profile_url = "https://mp.weixin.qq.com/mp/profile_ext?"
self.session.headers.update(self.headers) # 更新headers
self.session.cookies.update(self.cookies) # 更新cookies
self.saveDir = 'D:/wxChatSpider'
self.params = {
'action': 'getmsg',
'__biz': to_pdf.biz,
'f': 'json',
'offset': '10', # 若需要多页爬取, 构造 : str(self.offset)
'count': '10',
'is_ok': '1',
'scene': '124',
'uin': to_pdf.uin,
'key': to_pdf.key, # 这个好像二十分钟就会失效, 需要隔段时间更换
'pass_ticket': to_pdf.pass_ticket,
'wxtoken': '',
'appmsg_token': to_pdf.appmsg_token,
'x5': '0',
}
if __name__ == '__main__':
import to_pdf
# 里面是第三方库的配置, 以及一些微信公众号的参数
spider = wxChatSpider()
spider.run()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号