Robot Framework做UI自动化测试
Selenium2Library库安装与配置
selenium是一款用于Web应用程序测试的工具,它支持多平台、多语言、多浏览器去实现自动化测试。
针对robot framework的库有两个:SeleniumLibrary和Selenium2Library。SeleniumLibrary是针对Selenium1.0开发的,Selenium2Library是针对Selenium2.0开发的。我们直接安装Selenium2Library即可。
Selenium2Library库安装:
安装方式一:pip install robotframework-selenium2library==3.0.0 联网安装
pip install --upgrade robotframework-selenium2library --升级
pip uninstall robotframework-selenium2library --卸载
安装方式二:压缩包下载:下载地址https://pypi.python.org/pypi/robotframework-selenium2library然后解压,通过python setup.py install 安装
webdriver安装:
Windows操作系统把对应浏览器的driver.exe文件放置到放到/python27/scripts目录下即可。
浏览器操作API
Selenium2Library库中的关键字可以通过按F5,然后选择Source下拉框中的Selenium2Library库,即可查看所有Selenium2Library的关键字和帮助信息。
常用的关键字如下:
open browser:打开浏览器

浏览器对应的关键字:
谷歌浏览器:chrome googlechrome gc
火狐浏览器:firefox ff
IE浏览器:ie internetexplorer
close browser:关闭当前浏览器
close all browsers:关闭所有浏览器和缓存重置
maximize browser window:浏览器最大化
set window size :设置浏览器宽、高
get window size :获取浏览器宽、高

go back :浏览器进行回退操作
reload page:页面重新加载,即页面刷新操作
get title:获取当前浏览器窗口的标题
get location:获取当前URL

元素识别工具与定位API
元素识别工具:
Firebug
Firebug是网页浏览器 Mozilla Firefox下的一款开发类插件,它集HTML查看和编辑、Javascript控制台、网络状况监视器于一体,是开发 JavaScript、CSS、HTML和Ajax的得力助手。
安装Firebug:
Mozilla Firefox菜单--附加组件--插件--搜索Firebug--安装--重启浏览器
chrome和IE的开发者工具
chrome 浏览器自带开发者工具,浏览器右上的小扳手,在下拉菜单中选择“工具”--“开发者工具” 即可打开,也可以使用快捷键Ctrl+Shift+I或者F12.
IE浏览器从IE8版本开始,加入了开发人员工具,通过菜单栏“工具”--“开发人员工具”或者通过快捷键F12即可打开。
元素定位API:
Selenium2Library提供了非常丰富的元素定位器,如下所示:

示例:
用户名文本框
百度新闻链接
新闻
1.通过id定位对象:

2.通过name定位对象:

- 通过link定位对象:

xpath定位:
xpath是一种在XML文档中定位元素的语言。因为HTML可以看作是XML的一种形式,selenium可使用这种强大语言在web应用中定位元素。Xpath有7种定位元素的方式:
1、通过绝对路径做定位
XPath的开头是一个斜线(/)代表这是绝对路径。
/html/body/div[3]/div[1]/div/div[3]/a[2]
2、通过相对路径做定位
如果开头是两个斜线(//)表示文件中所有符合模式的元素都会被选出来,即使是处于树中不同的层级也会被选出来。
//div[1]/div/div[3]/a
3、通过元素索引定位 ,索引的初始值为1
//div[3]/a[2] 定位文件中第2个a对象
4、使用属性定位
//a[@name=‘tj_trnews’]
//a[@name=‘tj_trnews’ and @class=‘mnav’]
//a[@name=‘tj_trnews’ or @class=‘mnav’]
5、使用部分属性值匹配
starts-with()
//a[starts-with(@name,‘tj_trnews’)]
ends-with()(XPath1.0中没有ends-with函数,2.0有,现在浏览器实现的都是1.0)
可以用如下代替:
//a[substring(@name,string-length(@name)-5)=‘trnews’]
contains()
//a[contains(@name,'trnews')]
6、使用任意属性值匹配元素
//[@=‘tj_trnews’]
7、使用xpath的text函数
//a[text()=‘新闻’]
//a[contians(text(),'新闻')]")) 包含(模糊)匹配
CssSelector定位:
CSS locator比XPath locator速度快,特别是在IE下面(IE没有自己的XPath 解析器(Parser))他比xpath更高效更准确更易编写,但根据页面文字时略有缺陷没有xpath直接。CssSelector有6种定位元素的方式:
1、使用绝对路径来定位元素。CSS绝对路径指的是在DOM结构中具体的位置,使用绝对路径来定位用户名输入字段,在使用绝对路径的时候,每个元素之间要有一个空格。
html body div div div div form span input
这种策略有一定的局限性,如果界面的布局改变了,那么可能就定位不到我们想要的元素了
2、 使用相对路径来定位元素
当使用CSS选择器来查找元素的时候,我们可以使用class属性来定位元素,我们可以先指定一个HTML的标签,然后加上一个”.”符合,跟上class属性的值
div a.mnav
3、定位下个节点:
div a.mnav + a
.mnav 找界面所有className为mnav的元素
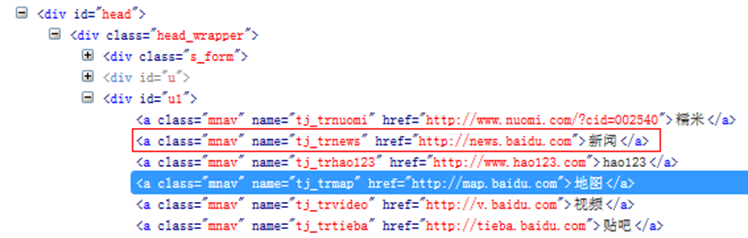
4、列表选择具体的匹配
Selenium中的CSS选择器允许我们更细致的浏览列表下的元素,如图,我想选择第三行链接,可以用nth-of-type或者nth-child
div a[class=‘mnav’]:nth-of-type(3)
div a[class=‘mnav’]:nth-child(3)
5、 使用相对ID选择器来定位元素
可以使用元素的ID来定位元素,先指定一个HTML标签,然后加上一个”#”符号,跟上id的属性值
input#kw #kw
这种方法也是会找界面所有id=kw的元素,不一定能定位到我们要的元素上
6 、使用属性值选择器来定位元素
通过指定元素中属性值来定位元素
单属性:a[name=‘tj_trnews’]
多属性:a[name=‘tj_trnews’][class=‘mnav’]
7、部分属性值的匹配
CSS选择器提供了一个部分属性值匹配定位元素的方法,这为了测试那些页面上具有动态变化的属性的元素是非常有用的,例如界面技术EXTJS的id,className是动态变化的。
匹配前缀:^= 匹配后缀:$=
匹配字符串:*=
a[name^=‘tj_’][class=‘mnav’]
常用CSS定位语法如下:

元素操作API
input text:输入文本
click button/click element:点击按钮/点击元素
sumbit form: 表单提交,要求对象必须是表单,或者为空
clear element text:清空元素内容

get text:获取元素文本内容
get element attribute : 获取元素属性
get element size:获取元素尺寸

设置等待相关API
为了保证脚本的稳定性,有时候需要引入等待时间,等待页面加载元素后再进行操作,robot framework提供多种等待时间设置方式。
固定时间等待:
sleep:固定时间等待
隐式等待:可以在一个时间范围内等待,且是识别元素的全局设置。
set browser implicit wait:隐式等待,针对当前浏览器生效
set selenium implicit wait:隐式等待,针对所有打开的浏览器都生效
显示等待:针对单一元素在时间范围内达到条件的等待,也有相应的否定用法
wait until element contains:直到元素包含指定的text才结束等待
wait until element is enabled:直到元素可以使用才结束等待
wait until element is visible:直到元素可见才结束等待
其它等待:也有相应的否定用法
wait until page contains:直到当前页面出现指定的text才结束等待
wait until page contains element:直到当前页面出现指定的元素才结束等待
wait for condition:当满足条件时结束等待,条件是带返回布尔值的js脚本
等待相关API写法示例:

其它操作API
定位frame中的对象:
select frame:定位frame中的对象,进入到frame(表单),参数是id、name属性,或者是xpath识别元素的值。
unselect frame: 退出frame(表单)

原生js弹窗(alert/confirm/prompt)的处理:
handle alert :操作原生弹窗并且可以返回弹窗的消息内容

下拉框处理:
Select From List By Value:通过value属性去选择下拉框的值
Select From List By Index:通过索引去选择下拉框的值,索引从0开始
Select From List By Label:通过可见文本属性去选择下拉框的值

执行Javascript脚本:
当robotframework遇到无法完成的操作时候,这个时候可以使用javascript来完成,robotframework提供了API来调用js代码执行。
Execute JavaScript:执行js脚本

浏览器多窗口处理:
在进行自动化测试过程中,过程中会出现跳转到新窗口继续执行操作的情况,robotframework可以通过如下API处理:
Select window:跳转到指定窗口,参数可以是title、URL、handle、NEW、MAIN
其中NEW为最新打开的窗口、MAIN为回到主窗口
Get window Handles:获取所有窗口的句柄,返回一个list

鼠标键盘事件API
鼠标键盘事件:
Mouse Down:模拟鼠标在指定的元素上按下鼠标左键
Mouse Up:模拟鼠标在指定的元素上释放鼠标左键
Mouse Over:模拟移动鼠标悬停在指定的元素上
Mouse Out:模拟移动鼠标远离指定的元素
Double Click Element:在指定的元素上进行双击操作
Press key:实现在元素上进行按键操作 ,参数可以 是单个字符、字符串、ascii码的值(作为参数需要加上 \)

断言API
系统断言API:
should Be Empty:判断是否为空,如果是空,断言成功
Should Be Equal:判断是否相等,如果相等,断言成功
Should Be True:判断条件是否为真,如果条件为真,断言成功
Should Contain:判断是否包含,如果包含,断言成功

Should Start With:判断字符串是否以指定的值开头,如果是,断言成功
Should End With:判断字符串是否以指定的值结尾,如果是,断言成功
length Should Be:判断对象的长度是否是指定值,如果是,断言成功

Selenium断言API:
Page Should Contain:页面是否包含指定的文本内容
Page Should Contain Element:页面是否包含指定的元素,相类似的还有Button、Checkbox、Image、Link、List、Radio Button、Textfield,如下图举例:

备注:
Element\List\Textfield的元素定位信息必须写完整
其余可以只用写id、name等的值,不需要写定位的属性名
Limit参数表示元素出现的次数,none为默认,表示出现即可;如果是2,必须出现2次
Loglevel表示日志级别,共有4个选项:DEBUG, INFO (default), WARN和 NONE,如果
设置成WARN,只会打印WARN以及该级别以上的信息。
Element Should Contain:元素的text是否包含指定的内容(可以是部分内容)
Element Should Be Visible:判断元素是否可见,相类似的还有Focused(选中)、Enabled(启用)
Alert Should Be Present:是否出现弹出窗
Checkbox Should Be Selected:复选框是否已经被选中


 浙公网安备 33010602011771号
浙公网安备 33010602011771号