快速解决正则----模糊匹配、字符类、量词
主体概要
正则表达式是什么
是匹配模式。要么匹配字符、要么匹配位置
内容
掌握字符类和量词就能解决大部分常见正则问题
关键内容:字符组、量词、贪婪、惰性、模糊、横向、纵向、分支、位置
重要的基础
如何匹配字符,就靠量词和字符类
量词
量词即重复,找/匹配 重复字符,标志 {}
贪婪:在范围内,匹配越多越好( greedy quantifiers)


1 var regex = /\d{2,5}/g; 2 var string = "123 1234 12345 123456"; 3 console.log( string.match(regex) ); 4 // => ["123", "1234", "12345", "12345"] 5 //其中正则 /\d{2,5}/,表示数字连续出现 2 到 5 次。会匹配 2 位、3 位、4 位、5 位连续数字。
有贪婪就会有懒惰
惰性:匹配到就行,尽力少匹配 (lazy quantifiers),标志在后面加?
1 var regex = /\d{2,5}?/g; 2 var string = "123 1234 12345 123456"; 3 console.log( string.match(regex) ); 4 // => ["12", "12", "34", "12", "34", "12", "34", "56"] 5 //其中 /\d{2,5}?/ 表示,虽然 2 到 5 次都行,当 2 个就够的时候,就不再往下尝试了。

? 有吗
+ 至少
* 任意
字符类
在范围内找\匹配,标志【】,可以是一组,也可以是其中一个字符 ,
字符类,也称字符组
反字符类:字符类的第一位放 ^(脱字符),表示求反的概念。
例如 [^abc],表示是一个除 "a"、"b"、"c"之外的任意一个字符

当字符组里有特别多字符,比如 [123456abcdefGHIJKLM],可以写成 [1-6a-fG-M]。用连字符 - 来省略和简写。
过人之处:模糊匹配
正则只有精确匹配,就没什么可深入的东西。但模糊匹配才是让正则强大的原因。
模糊匹配分为横向匹配和纵向匹配。
横向匹配指的是,一个正则可匹配的字符串的长度不是固定的,可以是多种情况的。
基本和量词配合使用,要匹配字符,可以重复多少
譬如 {m,n},表示连续出现最少 m 次,最多 n 次。
1 //模糊匹配之--横向匹配 2 var regex =/ab{2,5}c/g; 3 var string="abc abbc abbbc abbbbc abbbbbc abbbbbbc"; 4 console.log(string.match(regex)); 5 //=> ["abbc","abbbc","abbbbc","abbbbbc"]
纵向匹配指的是,一个正则匹配的字符串,具体到某一位字符时,它可以不是某个确定的字符,可以有多种可能。
通常用字符类配合使用,在一组里找想要字符
其实现的方式是使用字符类。譬如 [abc],表示该字符是可以字符 "a"、"b"、"c" 中的任何一个。
1 //模糊匹配之--纵向匹配 2 var regex=/a[123]b/g; 3 var string="a0b a1b a2b a3b a4b"; 4 console.log(string.match(regex)); //=> ["a1b","a2b","a3b"]
选择分支
用 |(管道符)分隔,表示其中任何之一。
1 var regex =/good|nice/g; 2 var string="good idea,nice try."; 3 console.log(string.match(regex)); //=>["good","nice"] 匹配字符串 "good" 和 "nice"
注意:默认从左到右匹配,左边能匹配,就会忽略右边
比如我用 /good|goodbye/,去匹配 "goodbye" 字符串时,结果是 "good":
1 var regex = /goodbye|good/g; 2 var string = "goodbye"; 3 console.log( string.match(regex) ); // => ["goodbye"]
优先级
优先级 由高到低
转义 \
括号 (?!) () [] (?:)
量词 {m} {m,n}
位置 ^ $
分隔 |
匹配位置
1、位置(锚)是相邻字符之间的位置 。对于位置的理解,我们可以理解成空字符 ""。 字符之间的位置,可以写成多个
比如,下图中箭头所指的地方:
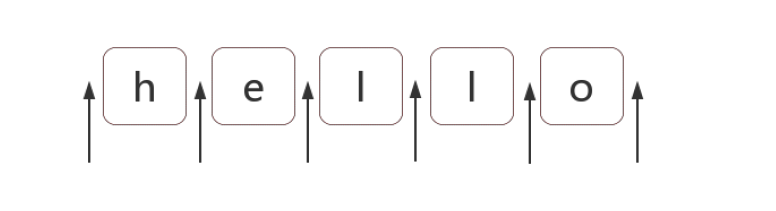
1 //比如 "hello" 字符串等价于如下的形式: 2 "hello" == "" + "h" + "" + "e" + "" + "l" + "" + "l" + "" + "o" + ""; 3 //也等价于: 4 "hello" == "" + "" + "hello" 5 //把 /^hello$/ 写成 /^^hello$$$/,是没有任何问题的: 6 var result = /^^hello$$$/.test("hello"); 7 console.log(result); // => true
2、 断言
先行断言:(?=) 表示 匹配 前面的位置
1 //比如 (?=l),表示 "l" 字符前面的位置,例如: 2 var result = "hello".replace(/(?=l)/g, '#'); 3 console.log(result);// => "he#l#lo"
后行断言:(?<=) 表示 匹配 后面的位置
如:只匹配美元符号之后数字:/(?<=\$)\d+/
否定-先行断言:(?!) 表示 匹配不在 前面位置就行, 与 (?=) 的互补
1 var result = "hello".replace(/(?!l)/g, '#'); 2 console.log(result); // => "#h#ell#o#"
3、关于位置
^(脱字符)匹配开头,在多行匹配中匹配行开头。
$(美元符号)匹配结尾,在多行匹配中匹配行结尾。
^和$ 一起用,匹配整体
\b 是单词边界,具体就是 \w 与 \W 之间的位置,也包括 \w 与 ^ 之间的位置,和 \w 与 $ 之间的位置。
1 //比如考察文件名 "[JS] Lesson_01.mp4" 中的 \b,如下: 2 var result = "[JS] Lesson_01.mp4".replace(/\b/g, '#'); 3 console.log(result); // => "[#JS#] #Lesson_01#.#mp4#"
\B 非单词边界
1 //比如上面的例子,把所有 \B 替换成 "#": 2 var result = "[JS] Lesson_01.mp4".replace(/\B/g, '#'); 3 console.log(result); 4 // => "#[J#S]# L#e#s#s#o#n#_#0#1.m#p#4"
正则表达式,太多字符、元字符要记,且好乱。本篇是笔记、是我个人的理解、围绕如何”懂“正则表达式,且本篇大多数是源于《javascript正则表达式迷你书》的内容,这书比较深入理解正则表达式及正则内部匹配准则(原理)。
下一篇:快速解决正则续---属性、方法、综合应用 会更多地展示这书的精华。
