CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation笔记
Motivation
- 以前的模型大多都只依赖于encoder或关注于decoder,分别对于生成和理解任务是次优的;
- 此外,大多数现有的方法把code看作是像NL这样的标记序列,只是在其上采用传统的NLP预训练技术,这在很大程度上忽略了代码中丰富的结构性信息,而这对于完全理解代码的语义至关重要
Introduction
在这项工作中,我们提出了CodeT5,一个预先训练的编码器-解码器模型,它考虑了代码中的令牌类型信息。
模型框架基于T5,此外,我们提出在代码中利用developer设计的标识符。为了融合这种特定于代码的知识,我们提出了一种新的标识符感知目标函数,它训练模型来区分哪些令牌是标识符,并在它们被屏蔽时恢复它们。
另外,我们还利用代码中的注释来让模型学习代码和文本的对齐属性。
我们将NL-PL和PL-NL视为dual task,同时优化这两个任务。
Contribution
- 我们提出了第一个统一的编码解码器模型CodeT5,以支持编码相关的理解和生成任务,也允许多任务学习
- 提出了一种新的基于标识符感知的预训练目标,它考虑了代码中的关键令牌类型信息(标识符)。此外,我们建议利用源代码中自然可用的NL-PL对来学习更好的跨模态对齐。
- 大量的实验表明,CodeT5在CodeXGLUE中的14个子任务上产生了最先进的结果。进一步的分析表明,我们的CodeT5可以更好地捕获代码语义,提出的识别符感知预训练和双模态dual generation主要有利于NL-PL任务。
CodeT5
Encoding NL and PL
两个序列通过\(\verb|[SEP]|\)token拼接起来:\(x = ([\verb|CLS|], w_1, \dots, w_n, \verb|[SEP]|, c_1, \dots, c_m, \verb|[SEP]|)\)。
为了捕捉代码特征,我们提取每个token的type(是否是identifier),用序列\(y \in {0, 1}^m\)来表示\(c_i\)是否是identifier。
预训练任务
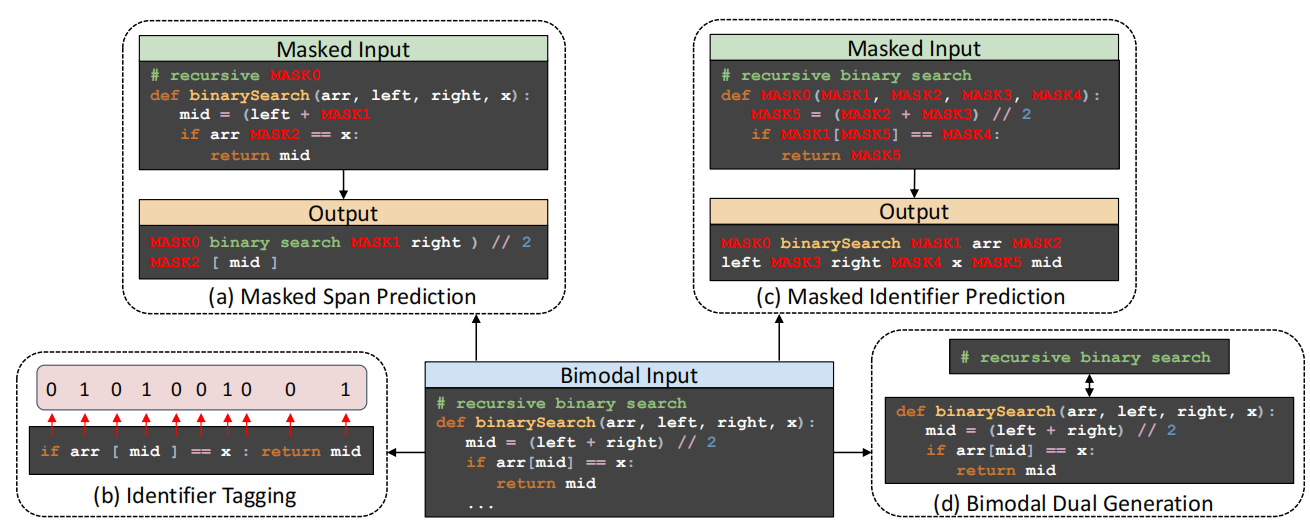
Identifier-aware Denoising Pre-training
- Masked Span Prediction (MSP)
- 通过某个噪声函数给序列加噪音,然后让解码器恢复原始文本
-
\[ \mathcal{L}_{MSP}(\theta) = \sum_{t=1}^k - \log P_{\theta} (x_t^{mask} | x ^{\backslash mask}, x^{mask}_{<t}) \]
- Identifier Tagging (IT)
- 它的目的是通知模型,并知道这个代码标记是否是一个标识符,这在一些开发辅助工具中具有类似的语法突出显示精神。
-
\[\]\[\]
- 我们屏蔽了PL段中的所有标识符,并对一个特定标识符的所有出现使用一个唯一的哨兵令牌。在软件工程领域中,这被称为混淆,因为更改标识符名称不会影响代码的语义。
-
\[\]\[ \]
Bimodal Dual Generation
在训练前阶段,解码器只看到离散的mask span和identifiers,这和下游任务有gap。为了减小这种gap,我们同时优化\(\text{PL} \rightarrow \text{NL}\)和\(\text{NL} \rightarrow \text{PL}\)。对于每一个NL-PL的实例对,我们反转顺序,并且添加语言id。这种操作可以看作span mask的一种特殊情况。
fine tune
- Task-specific Transfer Learning: Generation vs. Understanding Tasks.
- 与代码相关的任务可以分为生成任务和理解任务。对于前者,我们的CodeT5可以自然地适应其Seq2Seq框架。对于理解任务,我们研究了两种方法,要么将标签生成为单组目标序列,要么根据最后一个解码器隐藏状态从类标签的词汇表中预测它。
- Multi-task Learning
- 采样频率
-
\[\]
\[- $\alpha$设置为0.7 \]
一个人没有梦想,和咸鱼有什么区别!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号