ABCNN 学习笔记
介绍
ABCNN是将注意力机制应用在卷积网络中的模型,在 answer selection(AS)、paraphrase identification(PI)和textual entailment(TE)等领域有很大价值。文章指出,之前的模型大多对两个要匹配的句子提取语义时,都不会考虑句子间的影响,而是单独提取特征,而ABCNN在编码句子的时候使用注意力机制考虑句子间的相互影响。
作者介绍了基础的BCNN模型,并分别讨论了三种ABCNN模型。
下表中,\((s_0, s_1^+)\)为正确的配对,\((s_0,s_2^-)\)为错误的。
| \(s_0\) | \(s_1^+\) | \(s_2^-\) | |
|---|---|---|---|
| \(\textrm{AS}\) | how much did Waterboy gross? | the movie earned $161.5 million | this was Jerry Reed’s final film appearance |
| \(\textrm{PI}\) | she struck a deal with RH to pen a book today | she signed a contract with RH to write a book | she denied today that she struck a deal with RH |
| \(\textrm{TE}\) | an ice skating rink placed outdoors is full of people | a lot of people are in an ice skating park | an ice skating rink placed indoors is full of people |
BCNN
Basic Bi-CNN(BCNN)是基础的模型,不涉及到注意力。模型中的参数见下表。

在BCNN中,主要有输入层、卷积层、池化层、输出层。
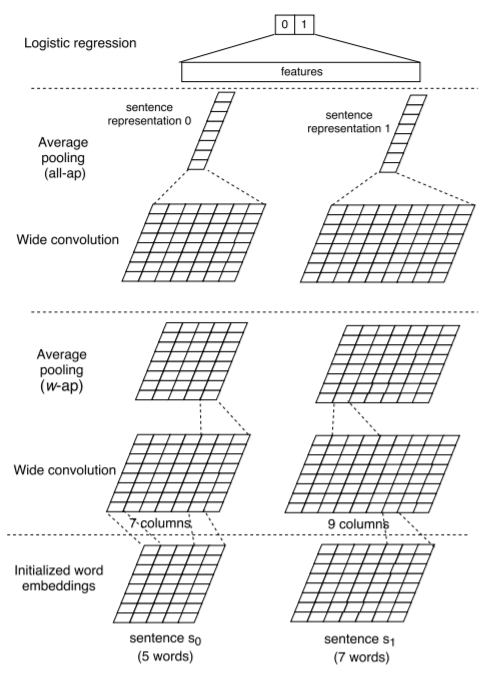
输入层
模型使用时,将句子长度补到最大长度\(s = \max_i length_i = \max \{\text{length of }s_0, \text{length of }s_1\}\),但是图示中,为了能够更清楚的展示模型是如何运作的,将句子长度设为5和7。
每一个单词经过编码后为\(\mathbb{R}^{d_0}\),句子则会变成\(\mathbb{R}^{d_0 \times s}\)。其中,句子方向为列方向,单词的表示维度为行。
卷积层
图中表示的卷积层为\(\mathbb{R}^{d_0 \times w},w=3\),叠加\(d_1\)个,就会得到卷积层的输出,此时列方向长度\(s + w - 1\)。卷积时设置\(v_j = 0,j < 1 \text{ or } j > s\)。对于第\(i\)个单词,\(c_i\)为它的向量表示,卷积层输出为
\(W\)为卷积核的集合。
池化层
经过卷积层,数据已经可以从单词粒度表示到词语(phrase)了。
这里的平均池化层有两种,一种应用在最后一层,最后一层输出层之前的池化都为另一种。
w-ap
这种池化层对应模型图中的w-ap,池化层的步长为1,跨度为\(w\),这样就会将输入向量的列长度转换回句子长度\(s\),所以,这种池化层搭配上面的卷积层可以无限叠加,直到提取出高抽象度的语义。
all-ap
而all-ap池化层是在输出层前的最后一步,在列方向上求一次平均,将向量转换为\(d_1\)一个维度。
输出层
输出层一般是一个logistic regression,应该根据具体任务进行设计。
作者发现,如果将不同卷积-池化层的输出都传递给output layer,效果会更好,因为这种方式考虑了不同的级别上的语义。
ABCNN
作者介绍了三种的ABCNN模型,并解释了每种注意力机制的原理,三种模型如图。
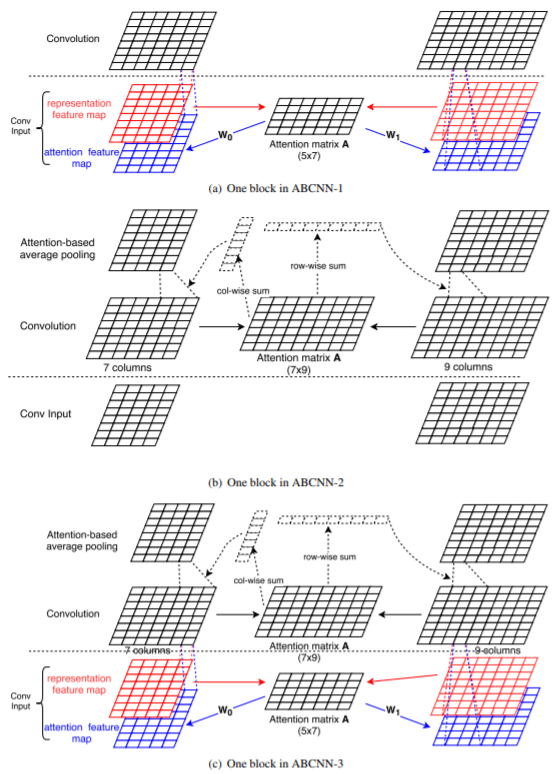
ABCNN-1
模型如(a)所示。卷积层的输入,由之前的 feature map,变成了 feature map 和 attention feature map 的加权结果,而后者是由注意力矩阵通过两个学习出的矩阵\(W_1\)和\(W_2\)得来的,下面说一说这个注意力矩阵\(A\)。
注意力矩阵\(A\)是考虑到两个句子的feature map 的。我们称第一个句子的特征矩阵每一列为第一个句子的一个unit,第二个句子特征矩阵的每一列为第二个句子的一个unit。\(A \in \mathbb{R}^{len_1 \times len_2}\),注意力矩阵的每一行可以表示为与第一个句子的每一个unit相关,每一列与第二个句子的每一个unit相关。
令\(F_{i,r} \in \mathbb{R}^{d \times s},i\in \{ 0, 1 \}\)为representation feature map,注意力矩阵可以这样计算:
而attention feature map:
作者说,match-score取\(\frac{1}{1 + |x - y|}\)效果很好。
ABCNN-2
第二种ABCNN的注意力是放在池化层的,不再使用平均池化,而是加权的,权重和注意力机制有关。
注意力矩阵\(A \in \mathbb{R}^{len_1 \times len_2}\),每一行都和第一个句子的一个unit相关,每一列都和第二个句子的unit的相关。计算时,第一个句子的池化的权重系数为\(A\)的列方向和,第二个句子用行方向和,设\(F_{i, r}^c\)为第\(i\)个句子的卷积层输出,\(F_{i,r}^p\)为池化输出,如下式
其中,\(a_{0,j} = \sum A[j,:],a_{1,j} = \sum A[:, j]\)。
我们可以注意到几点区别。
- ABCNN-1在卷积层添加注意力,ABCNN-2在池化层,相比较而言,在池化层的影响更大,即第二种方式可以在更大层面上影响句子的语义。
- ABCNN-1相比ABCNN-2多了两个将representation feature map转化为 attention feature map 的矩阵,所以参数更多。
ABCNN-3
通过研究前两种模型,很容易产生将二者融合起来的想法。
ABCNN-3就是将前两种做法融合起来,在词层面、短语层面都有很好的表示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号