

linux学习之正则表达式(Regular Expression)
以下内容摘抄翻译自 The Linux Command Line: A Complete Introduction written by William Shotts.有疏漏在所难免,还请批评指正。
正则表达式是什么
简单的说,正则表达式一种用来鉴别文本中的模式(patterns)的符号表示法。有时候,它们与shell用来匹配文件和路径名的通配符相似,但是规模更大。很多命令行工具和编程语言都支持正则表达式以便利文本操作。然而,它们对正则表达式的“理解”略有差异。在之后的讨论中,我们将使用POSIX标准描述的正则表达式。
grep
我们用在之前的Linux学习中认识的grep来学习正则表达式。实际上,grep就是"gloabl regular expression print"的缩写,从中可以看出grep和正则表达式的关系。本质上,grep程序会在文本文件中寻找与某个特定的正则表达式相匹配的文本并把文件中所有包含这些文本的行输出到标准输出。
grep程序如此接受选项(options)和参数(arguments),其中regex指正则表达式:
grep [options] regex [file...]
下表给出了grep常用的几个选项。
| Option | Long option | Description |
|---|---|---|
| -i | --ignore-case | 忽略大小写。 |
| -v | --invert-match | 反向匹配,使grep输出所有不匹配的行。 |
| -c | --count | 输出要输出的行的行数而非这些行本身。 |
| -l | --files-with-matches | 输出包含要输出的行的文件名而非这些行本身。 |
| -L | --files-without-natch | 与 -l 相似,不过输出不包含要输出的行的文件名而非这些行本身。 |
| -n | --line-number | 在输出的这些行前加上这些行在相应文件中的行数。 |
| -h | --no-filename | 对于多文件查找,在输出行时不输出相应文件名。 |
为了充分探索grep,我们先创建一些用于查找的文本文件:
[me@linuxbox ~]$ ls /bin > dirlist-bin.txt [me@linuxbox ~]$ ls /usr/bin > dirlist-usr-bin.txt [me@linuxbox ~]$ ls /sbin > dirlist-sbin.txt [me@linuxbox ~]$ ls /usr/sbin > dirlist-usr-sbin.txt
我们可以对其进行简单的搜索:
[me@linuxbox ~]$ grep bzip dirlist*.txt
如果我们只对包含要输出的行的文件本身感兴趣而非这些行本身,可以在命令中加上-l选项:
[me@linuxbox ~]$ grep -l bzip dirlist*.txt
相反,如果我们想看到所有不包含要输出的行的文件,可以这么操作:
[me@linuxbox ~]$ grep -L bzip dirlist*.txt
元字符和字面量字符
我们的grep搜索时一直在使用正则表达式,但并不是很明显,因为我们使用的都是非常简单的例子。在上个例子中,正则表达式"bzip"意思是文件中只有包含至少有'b'、 'z'、 'i'、 'p'4个字符且这四个字符按照"bzip"的顺序紧密排列的行才是匹配的行。在字符串"bzip"中所有的字符都被称为字面量字符,因为它们都与自己匹配。除了字面量字符,在正则表达式中还有一种叫做元字符的字符用来指定更复杂的匹配项,它们为:
^ $ . [ ] { } - ? + ( ) | \
其他所有的字符都是字面量字符。此外,我们还可以使用\把元字符转义成字面量字符。
注:不难注意到不少元字符对于shell也有特殊的含义。当我们在shell中传递包含元字符的正则表达式,为了避免shell将其展开成我们不想见到的结果,可以在正则表达式两边加上引号。
任意符
我们先来看圆点字符.,它被用来匹配与它同位置的任何字符。以下是原书中的一个例子:
[me@linuxbox ~]$ grep -h '.zip' dirlist*.txt
以下是我运行的结果:
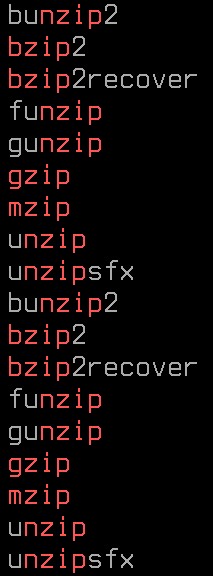
可以发现,结果中并没有"zip"。这是因为,圆点符的加入导致我们的正则表达式的长度变为了4而"zip"的长度为3,它们并不匹配。
显然,如果我们的文件中包含".zip",它也可以被匹配。
锚点(Anchors)
在正则表达式中,字符^和$被视为锚点。这意味着匹配发生只有在正则表达式在行首(^)或行尾($)被找到时才发生。
不妨分别运行以下命令,看看会输出什么:
[me@linuxbox ~]$ grep -h '^zip' dirlist*.txt [me@linuxbox ~]$ grep -h 'zip$' dirlist*.txt [me@linuxbox ~]$ grep -h '^zip$' dirlist*.txt
此外,正则表达式"^$" 会匹配空行。
中括号表达式和字符类
除了在正则表达式中给定位置上匹配任意字符,我们也可以使用中括号表达式使其匹配属于特定集合的某个字符。在以下例子中,我们匹配所有包含字符串"bzip"和"gzip"的行:
[me@linuxbox ~]$ grep -h '[bg]zip' dirlist*.txt
这个由[]包起的字符集合可以包含任意数目的字符,大多数元字符在中括号中也会失去其特殊含义,除了^用来表示否定,-用来表示字符区间。
否定
如果在中括号表达式中的首字符为^时,这时这个字符集合余下的字符都不能是匹配的行在当前位置的字符。例如:
[me@linuxbox ~]$ grep -h '[^bg]zip' dirlist*.txt
以下是我运行的结果:
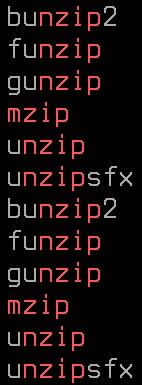
在此输出中,所有行的"zip"前的字符都不是'b'或'g'。
注意到"zip"并没有被找到,这是由于一个否定的字符集要求在当前位置有一个字符,只不过这个字符不能是这个集合的元素。
此外,字符^只有作为中括号表达式中的第一个元素时才会触发否定的效果;否则,它只会是这个字符集合中的一个普通字符。
传统的字符区间
如果我们想用一个正则表达式匹配所有开头为大写字母的行,可以有如下操作:
[me@linuxbox ~]$ grep -h '^[ABCDEFGHIJKLMNOPQRSTUVWXYZ]' dirlist*.txt
但这么操作实在麻烦,因而产生了如下简化的写法:
[me@linuxbox ~]$ grep -h '^[A-Z]' dirlist*.txt
类似地,还有a-z、0-9。
因此,如果我们想用正则表达式匹配所有以字母或数字开头的行,可以作如下操作:
[me@linuxbox ~]$ grep -h '^[A-Za-z0-9]' dirlist*.txt
如果-被放在中括号表达式的首位,那么它就变成了普通的-符号。
POSIX字符类
POSIX标准包括了一系列字符类以提供使用便利的字符区间,如下表所示:
| Character class | Description |
|---|---|
[:alnum:] |
字母和数字字符,等价于[A-Za-z0-9] |
[:word:] |
比[:alnum:]多了字符_ |
[:alpha:] |
字母字符,等价于[A-Za-z] |
[:blank:] |
空格和制表符 |
[:cntrl:] |
ASCII码中的控制码(0 ~ 31 + 127) |
[:digit:] |
数字字符0 ~ 9 |
[:graph:] |
可见字符,在ASCII码中指33 ~ 126的字符 |
[:lower:] |
小写字母 |
[:upper:] |
大写字母 |
[:punct:] |
标点字符,等价于[-!"#$%&'()*+,./:;<=>?@[\]_\`{|}~] |
[:print:] |
可打印字符,是所有属于[:graph:]的字符和空格字符 |
[:space:] |
空白字符,等价于[ \t\r\n\v\f] |
[:xdigit:] |
用于表示十六进制数字的字符,等价于[0-9A-Fa-f] |
POSIX的基础正则表达式(BRE)与拓展正则表达式(ERE)
POSIX标准把正则表达式分成了两类:基础正则表达式(BRE)和拓展正则表达式(ERE)。
BRE和ERE在元字符上存在差异。在BRE,以下字符为元字符:
^ $ . [ ] *
其他字符都是字面量字符。而在ERE相比与BRE,还把下列字符(包括相关的函数)视为元字符:
( ) { } ? + |
有趣的是,字符'(',')','{'和'}'在BRE中如果被\转义后则成为了元字符;而ERE中所有的元字符前加上了\都会变成字面量字符。
若要使用拓展正则表达式,可以使用grep + -E选项,或者干脆使用egrep程序。
交替(Alternation)
交替允许一次匹配因一些正则表达式中的某个表达式匹配而发生,就好比中括号表达式允许一个字符同一堆特定的字符作匹配。
为了说明,我们先使用echo和grep作一次简单的匹配:
[me@linuxbox ~]$ echo "AAA" | grep AAA AAA [me@linuxbox ~]$ echo "BBB" | grep AAA [me@linuxbox ~]$
这是一个很直接的例子,我们把echo的输出传递给grep以看结果。当匹配发生时,我们注意到匹配的行会被输出;相反,我们则看不到结果。
现在,让我们加上交替,即字符|的含义:
[me@linuxbox ~]$ echo "AAA" | grep -E 'AAA|BBB' AAA [me@linuxbox ~]$ echo "BBB" | grep -E 'AAA|BBB' BBB [me@linuxbox ~]$ echo "CCC" | grep -E 'AAA|BBB' [me@linuxbox ~]$
这里使用了正则表达式'AAA|BBB',意思是“要么与'AAA'匹配要么与'BBB'匹配”。因为交替是拓展正则表达式的特性,故我们使用了-E选项。注意到我们把正则表达式两边加上了引号,这是为了避免元字符|被shell翻译成管道符。
此外,交替并不局限于两个表达式:
[me@linuxbox ~]$ echo "AAA" | grep -E 'AAA|BBB|CCC'
为了结合使用交替与其他正则表达式元素我们可以用()把交替包起来:
[me@linuxbox ~]$ grep -Eh '^(bz|gz|zip)' dirlist*.txt
这个表达式会匹配我们的文件中以"bz","gz"或"zip"打头的行。如果我们去掉括号,上式的含义就变成了匹配文件中所有以"bz"打头或包含"gz"或"zip"的行:
[me@linuxbox ~]$ grep -Eh '^bz|gz|zip' dirlist*.txt
量词(Quantifiers)
拓展正则表达式支持以下几种方式来指定一个元素被匹配的次数。
? —— 匹配一个元素0或1次
实际上,这个量词的意思是“让前面的元素是可选的”。例如,我们要检查一串电话号是否有效,需要检查数字串是否是以下两种格式之一:
- $(nnn); nnn-nnnn$
- $nnn; nnn-nnnn$
我们可以构建如下正则表达式:
^\(?[0-9][0-9][0-9]\)? [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]$
在这个表达式中,我们在(、)后加上一个?表示括号可以被匹配0次或1次。
* —— 匹配一个元素0次或多次
类似于元字符?,字符*被用来表示一个可选的元素;然而,与?的差别是,这个元素可以出现任意次。
还是举个例子吧。我们想判断一个字符串是否是一个以大写字母打头,中间包含了众多大小写字母和空格,最后以.作尾。为了匹配一个句子,我们可以使用这样的正则表达式:
[[:upper:]][[:upper:][:lower:] ]*\.
我们看到上式中第二个元素后加上了一个*,于是其后所有的大小写字母和空格都会与之匹配。
+ —— 匹配一个元素1次或多次
元字符+含义与*相近,不过它要求之前的元素至少发生一次匹配。
以下的正则表达式用来匹配由单个空格分隔的一个或多个字母字符组成的行:
^([[:alpha:]]+ ?)+$
{} —— 匹配一个元素特定次
元字符{和}用来表示最少和最大的匹配次数。它们有以下四种表示方式:
| Specifier | Meaning |
|---|---|
| 匹配之前的元素如果它恰好出现了 $n$ 次。 | |
| 匹配之前的元素如果它至少出现了 $n$ 次,但是不多于 $m$ 次。 | |
| 匹配之前的元素如果它至少出现了 $n$ 次。 | |
| 匹配之前的元素如果它至多出现了 $m$ 次。 |
因此,我们之前匹配数字串的正则表达式:
^\(?[0-9][0-9][0-9]\)? [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]$
就可以简化为:
^\(?[0-9]{3}\)? [0-9]{3}-[0-9]{4}$
使用正则表达式
让我们看看一些我们已经了解过的命令如何同正则表达式一块使用。
使用grep看看电话号是否合法
在我们先前的例子中,我们已经可以判断某一数字串是否是合法的电话号,现在要判断某个电话号列表的各行是否为合法的电话号。
先来创建这么一个列表:
[me@linuxbox ~]$ for i in {1..10}; do echo "(${RANDOM:0:3}) ${RANDOM:0:3}-${RANDOM:0:4}" >> phonelist.txt; done
这个命令将会产生一个包含10个电话号的名为phonelist.txt的文件,但是其中有些行并不是合法的电话号。所以我们使用grep来检查:
[me@linuxbox ~]$ grep -Ev '^\([0-9]{3}\) [0-9]{3}-[0-9]{4}$' phonelist.txt
使用find找到“不当的”文件名
grep会输出包含与正则表达式匹配的字符串的行,然而find要求路径名必须要恰好匹配正则表达式。在下面的例子中,我们使用find加上正则表达式来找到包含不属于以下字符集合的字符的路径名:
[-_./0-9a-zA-Z]
这样的寻找会找到包含空格或者其他非法字符的路径名。
[me@linuxbox ~]$ find . -regex '.*[^-_./0-9a-zA-Z].*'
因为find要求恰好匹配,我们使用.*去匹配0个或多个任意的字符。在表达式的中间,我们使用了一个否定中括号表达式(^的作用)包含我们可以接受的字符。
使用locate寻找文件
locate程序既支持基本正则表达式(使用--regexp选项)也支持拓展正则表达式(使用--regex选项)。有了它,我们可以执行很多查找文件的操作:
[me@linuxbox ~]$ locate --regex 'bin/(bz|gz|zip)'
使用less和vim寻找文本
在less和vim中按下/键则可以使用正则表达式寻找文本。例如我们通过less查看phonelist.txt里的内容,再寻找匹配下列正则表达式的文本:
^\([0-9]{3}\) [0-9]{3}-[0-9]{4}$
less就会把匹配的字符串高亮显示出来,这样也就很容易看到不合法的电话号。
vim也是同理的,不过要注意区分BRE和ERE。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具