基于python实现xmind测试用例导出excel格式
前言
由于部门内部需要统计测试用例执行的测试报告情况,现阶段都是使用xmind写测试用例,所以需要转成excel,就网上百度了下,怎么直接把xmind脑图转换成excel测试用例,纯个人学习笔记;
一、确定好自己的xmind的用例格式
我的源码支持11级xmind,所以需要确保xmind层级数保持在11层及以内即可,其他没有限制,否则需要改源码;
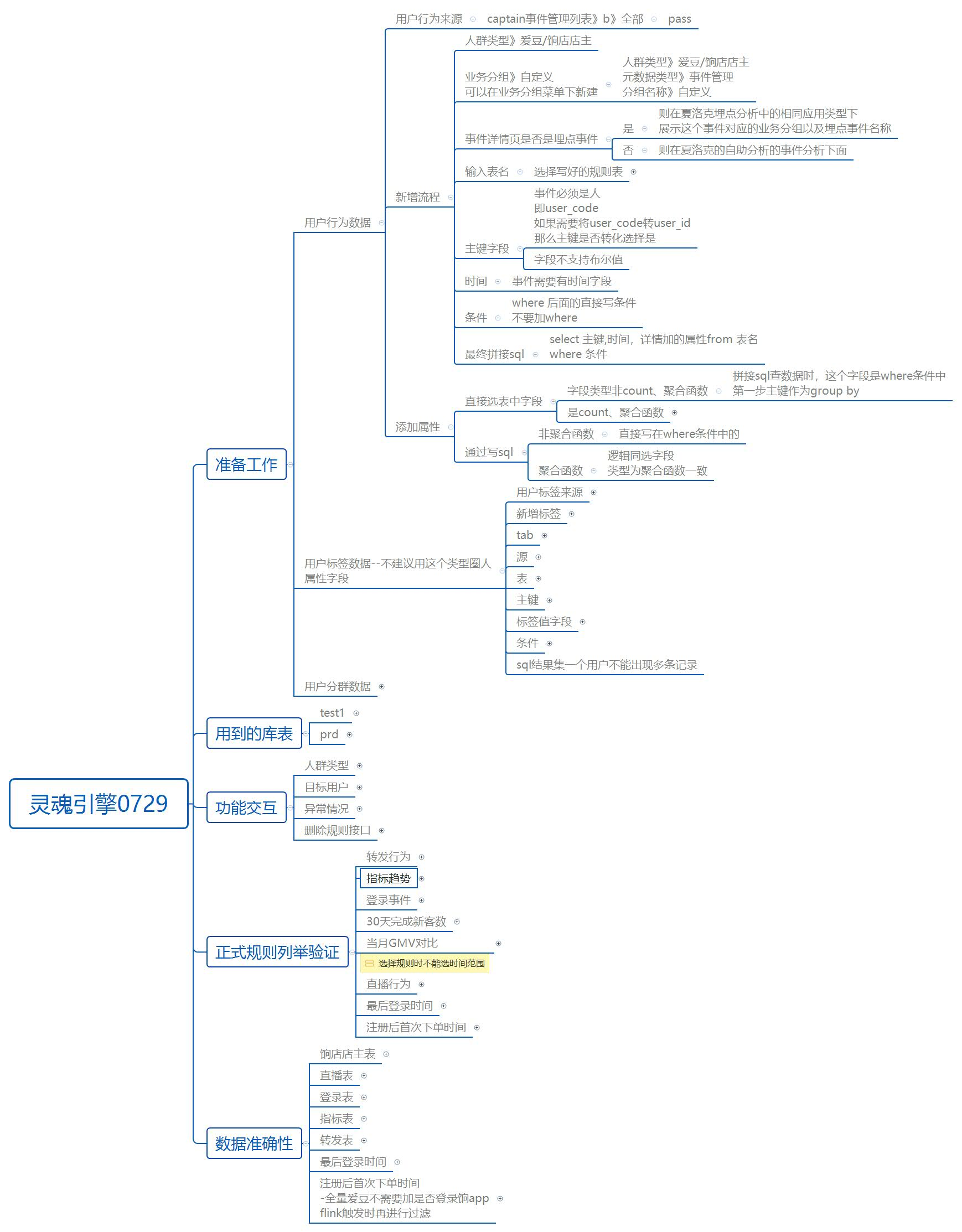
二、导入xmindparser、xlwt库
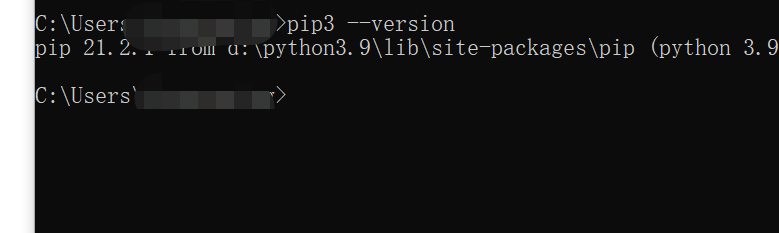
1.下载xmindparser库
命令行形式
pip 是 Python 包管理工具,该工具提供了对Python 包的查找、下载、安装、卸载的功能。
你可以通过以下命令来判断是否已安装:
pip --version # Python2.x 版本命令
pip3 --version # Python3.x 版本命令
配置好python3环境变量
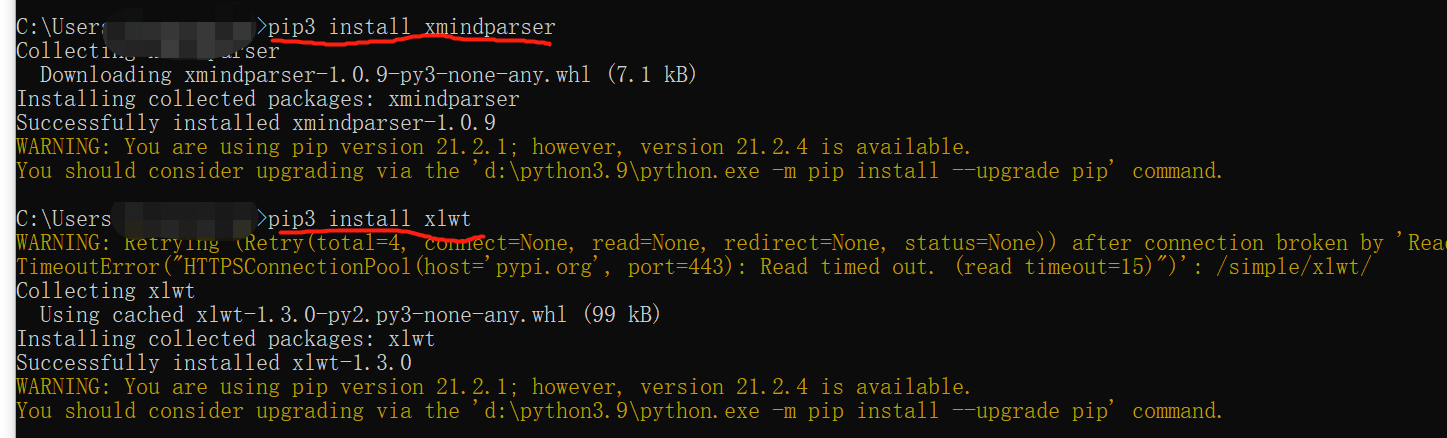
默认下载最新库,在配好环境python环境变量的前提下,cmd中输入如下命令:pip3 install xmindparser/xlwt
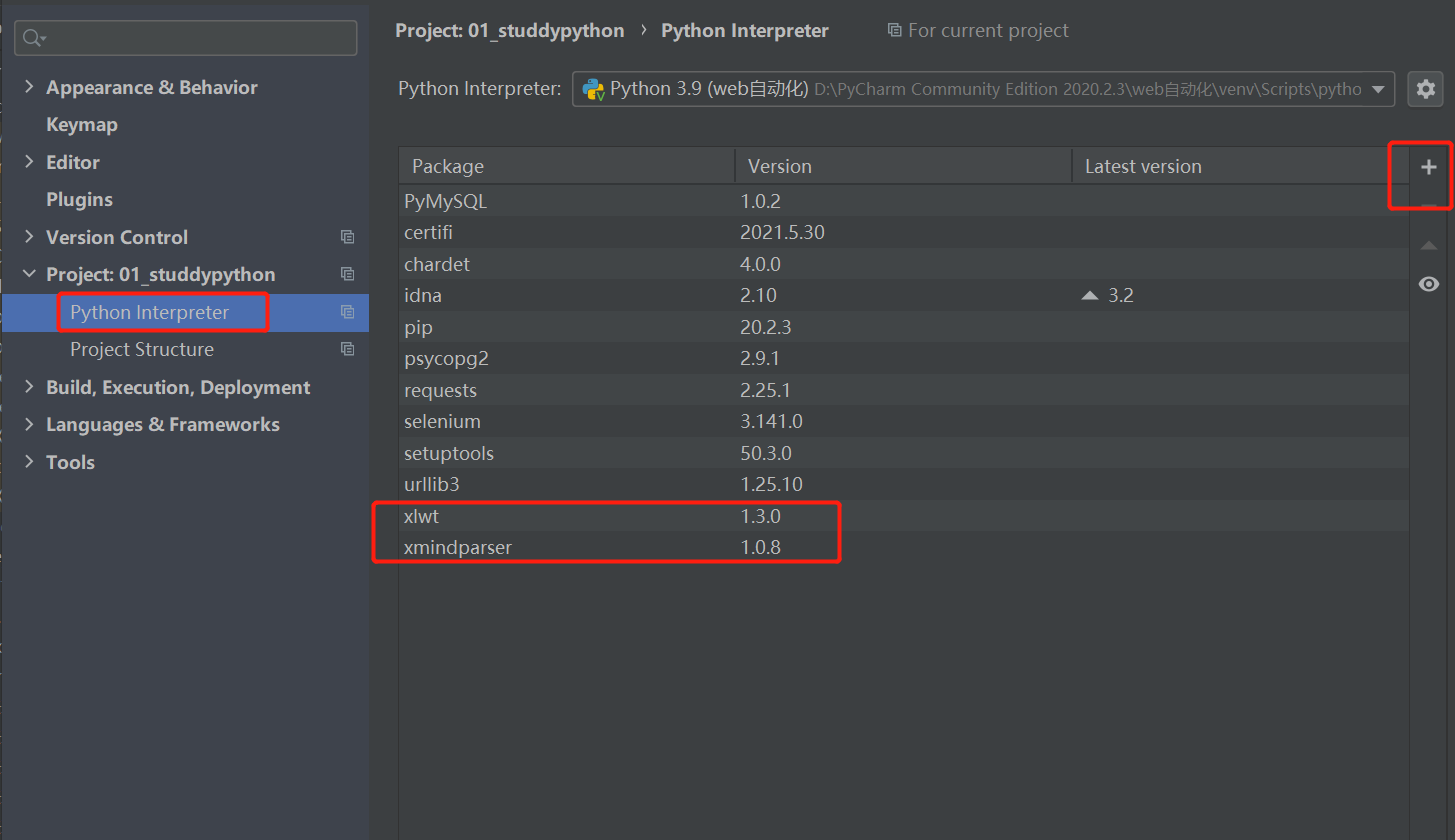
手动从pycharm导入
file》setting》项目名称下选择Python Interpreter》选择+,搜索这两个包安装即可 Install Package
三、具体代码
一个类里封装了所有功能点
# @Time : 2021/7/21 12:21
# @Author : cici
"""
导入xmindparser模块是为了解析xmind获得字典列表
"""
import xmindparser
#导入xlwt模块是为了创建excel并写入数据的
import xlwt
#定义一个类
class Xmind2Excel():
#定义一个解析xmind内容的方法
def xmind(self):
#在windows系统当中读取文件路径可以使用,但是在python字符串中\有转义的含义。需要采取一些方式使得\不被解读为转义字符。替换为双反斜杠即可
filePath = 'C:\\Users\\chengyaping\\Desktop\\worklist\\灵魂引擎210729\\灵魂引擎0729new.xmind'
filePath1 = 'C:\\Users\\chengyaping\\Desktop\\worklist\\百宝箱\\百宝箱二期功能交互.xmind'
filePath2 = 'C:\\Users\\chengyaping\\Desktop\\worklist\\灵魂引擎210729\\灵魂引擎0729new.xmind'
filePath3 = 'C:\\Users\\chengyaping\\Desktop\\worklist\\compass\\922大屏\\test1.xmind'
# 解析成dict字典数据类型
# 获取列表中的第1个字典中的topic:内容即包括一级标题在内的xmind内容,content行参
content = xmindparser.xmind_to_dict(filePath2)[0]['topic']
#将content属性返回给方法的调用处self,实例化类对象调用方法时才会获取该属性值
return content
#定义初始化excel字体样式,bold和height是形参代表是否加粗和字体大小
def styles(self,bold,height):
# 初始化样式,就是将excel样式初始化一个对象,可以理解为对这个样式类实例化对象style
style = xlwt.XFStyle()
# 为样式创建字体,也是对字体类实例化对象front
font = xlwt.Font()
font.name = 'Times New Roman'
# 加粗
font.bold = bold
# 字体大小,20是基数不变,18是字体大小
font.height = 20 * height
# 将设置的字体,赋值给类对象
style.font = font
#将配置好的格式返回给调用处
return style
#创建背景色
def patterns(self,colors=23):
"""
设置单元格的背景颜色,该数字表示的颜色在xlwt库的其他方法中也适用,默认颜色为白色
0 = Black, 1 = White,2 = Red, 3 = Green, 4 = Blue,5 = Yellow, 6 = Magenta, 7 = Cyan,
16 = Maroon, 17 = Dark Green,18 = Dark Blue, 19 = Dark Yellow ,almost brown), 20 = Dark Magenta,
21 = Teal, 22 = Light Gray,23 = Dark Gray, the list goes on...
"""
pattern = xlwt.Pattern()
pattern.pattern = xlwt.Pattern.SOLID_PATTERN
pattern.pattern_fore_colour = colors
return pattern
#合并单元格方法
def alignment(self):
# 创建对齐格式对象
alignment = xlwt.Alignment()
# 左右的对其,水平居中 May be: HORZ_GENERAL, HORZ_LEFT, HORZ_CENTER,
# HORZ_RIGHT, HORZ_FILLED, HORZ_JUSTIFIED,
# HORZ_CENTER_ACROSS_SEL, HORZ_DISTRIBUTED
alignment.horz = xlwt.Alignment.HORZ_CENTER
# 上下对齐 May be: VERT_TOP, VERT_CENTER, VERT_BOTTOM, VERT_JUSTIFIED, VERT_DISTRIBUTED
alignment.vert = xlwt.Alignment.VERT_CENTER
return alignment
#创建excel模板
def buildExcel(self):
# 将styles方法中的字体格式赋值给新的对象,字体加粗且字体大小为18
style2 = self.styles(True, 18)
#并将背景色方法赋值给给新的对象的背景色属性=style2.pattern
style2.pattern = self.patterns()
#居中方式赋值给新的对象
style2.alignment=self.alignment()
# 创建一个excel模板,实例化变量self.workexcel
self.workexcel = xlwt.Workbook(encoding='utf-8')
# 创建一个worksheet变量就是excel中的第一个表,第二个参数是指单元格是否允许重设置,为了防止重复对一个单元格写入报错,设置允许true
self.worksheet = self.workexcel.add_sheet('test1', cell_overwrite_ok=True)
# 设置worksheet每一列的宽度256 * 20,设置15列,range从0开始不包含15
for m in range(15):
first_col = self.worksheet.col(m)
first_col.width = 256 * 20
# 表头
title = ['功能模块', '前提条件', '执行步骤1','执行步骤2','执行步骤3','执行步骤4','执行步骤5','执行步骤6','执行步骤7', '执行步骤8','执行步骤9','执行步骤10','执行步骤11','期望结果', '备注'] # 写成excel表格用例的要素
# 列表长度15
num = len(title)
# for循环遍历最大到14,从0开始不含15
for i in range(num):
# 往表格中填充表头
## 第一个参数代表行,第二个参数是列,第三个参数是内容,第四个参数是格式调用styles2格式
self.worksheet.write(0, i, title[i], style2)
#将xmind字典内容写入excel
def writeExcel(self):
# 调用类内方法时,如果调用的方法内参数写了self,那么调用方法时需要使用self.方法名()来调用
xm = self.xmind()
print(xm)
x = 1 # 初始化行数
m = 0 #初始化第一级步骤数
n = 0 #初始化第二级步骤数
z = 0 #初始化第三级步骤数
# 第一级topics
for a in range(len(xm["topics"])): # topics列表中只有一个{}
case1 = xm["topics"][a] # 获取{}元祖给case1,元祖中有一级标题及下一级4个分支模块
print(x)
print(case1["title"]) # 第一级title
#self.worksheet.write(x, 1, case2["title"], self.styles(False, 15))
x += 1
# 第二级topics
if len(case1) >= 2:
x -= 1
for b in range(len(case1["topics"])): # 元祖中的四个模块
case2 = case1["topics"][b] # 将case1四个模块中的第一个模块的title和topics都给case2,case2中有2个功能点
print(x)
print(case2["title"]) # 第二级模块
#self.worksheet.write(x, 1, case2["title"], self.styles(False, 15))
x += 1
# 第三级topics
if len(case2) >= 2:
x -= 1
for c in range(len(case2["topics"])): # 第三级功能点
# 将case2中的第一个功能点给case3,case3中有3个步骤,第二遍case3中只有功能点2,不满足len(case3)>=2
case3 = case2["topics"][c]
print(x)
print(case3["title"]) # 第三层功能点
#self.worksheet.write(x, 2, case3["title"], self.styles(False, 15))
x += 1
# 第四级topics
if len(case3) >= 2:
x -= 1
#当for语句不满足后会直接去执行if的else语句
for d in range(len(case3["topics"])):
case4 = case3["topics"][d] # 将case3中的第一个步骤给case4,case4中只有1个title
print(x)
print(case4["title"]) # 获取第4层内容
self.worksheet.write(x, 3, case4["title"], self.styles(False, 15))
x += 1
# 第五级topics
if len(case4) >= 2:
x -= 1
for e in range(len(case4["topics"])):
case5 = case4["topics"][e]
print(x)
print(case5["title"])
self.worksheet.write(x, 4, case5["title"], self.styles(False, 15))
x += 1
if len(case5) >= 2:
x -= 1
for h in range(len(case5["topics"])):
case6 = case5["topics"][h]
print(x)
print(case6["title"])
self.worksheet.write(x, 5, case6["title"], self.styles(False, 15))
x+=1
if len(case6) >= 2:
x -= 1
for j in range(len(case6["topics"])):
case7 = case6["topics"][j]
print(x)
print(case7["title"])
self.worksheet.write(x, 6, case7["title"],self.styles(False, 15))
x += 1
if len(case7) >= 2:
x -= 1
for k in range(len(case7["topics"])):
case8 = case7["topics"][k]
print(x)
print(case8["title"])
self.worksheet.write(x, 7, case8["title"],self.styles(False, 15))
x += 1
if len(case8) >= 2:
x -= 1
for l in range(len(case8["topics"])):
case9 = case8["topics"][l]
print(x)
print(case9["title"])
self.worksheet.write(x, 8, case9["title"],self.styles(False, 15))
x += 1
self.worksheet.write_merge( z + 1, x - 1, 2, 2, case3["title"],self.styles(False, 15))
z = x - 1
self.worksheet.write_merge( n + 1, x - 1, 1, 1, case2["title"],self.styles(False, 15))
n = x - 1
#如果步骤没有进入下一层,那么对于第三列的z就少记录一行,加上x在if前比实际多1,所以需要在这里执行一次z=x-1,就是上一个用例的行数
z = x - 1
# 调用类内其他方法的实例化变量,需要在方法中创建self.变量名,然后在需要调用的方法内部采用self.变量名调用,类内调用其他方法的实例化变量时必须先调用该方法,否则会报错
#合并单元格,X-1是当前一级标题的最后一个case的行数,因为最后一个case不满足条件后x是+1的,为了进入下一个模块,所以需要-1算当前模块所在行数
#write_merge是从第几行~第几行,当前模块所在行数-上个模块所在行数就是当前模块的步骤数,当前模块所在行数-步骤数+1就是当前模块开始行
#之所以选择case2的for判断语句是因为,如果b循环结束,那么这个模块也就结束了,正适合合并单元格
self.worksheet.write_merge(m + 1, x - 1, 0, 0, case1["title"], self.styles(False, 15))
#将上一个模块最后的行数赋值给m
m = x - 1
n = x - 1
z = x - 1
# 保存workexcel文件名为testcase2,存在项目文件夹内
self.workexcel.save('testcase2.xls')
#定义一个类对象,来调用类中的方法或者属性
xmindexcel=Xmind2Excel()
xmindexcel.buildExcel()
xmindexcel.writeExcel()
一个子类继承多个父类的方法
# 定义一个类,继承父类Xmind2Dict和DefineExcelclass Xmind2Excel(Xmind2Dict, DefineExcel):
# 将xmind字典内容写入excel
def writeExcel(self):
# 调用其他类方法时,如果调用类方法内参数写了self,那么调用方法时需要使用self.方法名()来调用也可以使用类对象名.方法名
# xm是xmind画布第0个列表中的字典key:topics的values,是一个字典集包含所有节点内容{},是中心主题title和他的topics
xm = xmind2dict.xmind()
#print(xm)
x = 1 # 初始化行数从第一行开始,因为第0行是表头
m = 0 # 初始化第一级步骤数
n = 0 # 初始化第二级步骤数
z = 0 # 初始化第三级步骤数
# 第一级topics
for a in range(len(xm["topics"])): # topics列表中只有一个{}
case1 = xm["topics"][a] # 获取{}元祖给case1,元祖中有一级标题及下一级4个分支模块
print(x)
print(case1["title"]) # 第一级title
# 第二级topics
if len(case1) >= 2:
for b in range(len(case1["topics"])): # 元祖中的四个模块
case2 = case1["topics"][b] # 将case1四个模块中的第一个模块的title和topics都给case2,case2中有2个功能点
print(x)
print(case2["title"]) # 第二级模块
#self.worksheet.write(x, 1, case2["title"], self.styles(False, 15))
x += 1
# 第三级topics
if len(case2) >= 2:
x -= 1
for c in range(len(case2["topics"])): # 第三级功能点
# 将case2中的第一个功能点给case3,case3中有3个步骤,第二遍case3中只有功能点2,不满足len(case3)>=2
case3 = case2["topics"][c]
print(x)
print(case3["title"]) # 第三层功能点
#self.worksheet.write(x, 2, case3["title"], self.styles(False, 15))
x += 1
# 第四级topics
if len(case3) >= 2:
x -= 1
#当for语句不满足后会直接去执行if的else语句
# 先实例化excel目标对象
defineexcel = DefineExcel()
# 创建模板方法
defineexcel.buildExcel()
# 实例化xmind转字典的对象
xmind2dict = Xmind2Dict()
# 调用转字典的类方法
xmind2dict.xmind()
# 类外调用方法的实例化变量,输出类方法中的实例化变量
# print(xmind2dict.content)
# 定义一个类对象,来调用类中的方法或者属性
xmindexcel = Xmind2Excel()
xmindexcel.writeExcel()
最终版本封装了多个类
# @Time : 2021/7/21 12:21
# @Author : cici
"""
导入xmindparser模块是为了解析xmind获得字典列表
"""
import xmindparser
# 导入xlwt模块是为了创建excel并写入数据的
import xlwt
class Xmind2Dict():
#初始化方法获取类对象,定义一个解析xmind内容的方法
def __init__(self):
# 在windows系统当中读取文件路径可以使用,但是在python字符串中\有转义的含义。需要采取一些方式使得\不被解读为转义字符。替换为双反斜杠即可
filePath1 = 'C:\\Users\\chengyaping\\Desktop\\worklist\\2111项目\\百宝箱\\百宝箱3期 -gmv指标迭代 20211111.xmind'
filePath2 = 'C:\\Users\\chengyaping\\Desktop\\worklist\\灵魂引擎210729\\灵魂引擎0729new.xmind'
filePath3 = 'C:\\Users\\chengyaping\\Desktop\\worklist\\compass\\922大屏\\test1.xmind'
filePath3 ='C:\\Users\\chengyaping\\Desktop\\worklist\\消返满返0817\\消返满返项目改造1019.xmind'
filePath4 = 'C:\\Users\\chengyaping\\Desktop\\worklist\\移动罗盘项目\\211019切换表以及字段\\罗盘指标来源变更211019.xmind'
filePath5 = 'C:\\Users\\chengyaping\\Desktop\\worklist\\权限管理项目20200927\\权限管理改造 20211021.xmind'
filePath6 = 'C:\\Users\\chengyaping\\Desktop\\worklist\\2111项目\\权限管理项目20200927\\智能运营接入权限211112.xmind'
filePath7 = 'C:\\Users\\chengyaping\\Desktop\\worklist\\2111项目\\移动罗盘项目\\211108移动罗盘netgmv预测\\移动罗盘预估值优化211108.xmind'
filePath8 = 'C:\\Users\\chengyaping\\Desktop\\worklist\\2111项目\\权限管理项目20200927\\compass接入新的权限211206.xmind'
# 解析成dict字典数据类型
# 获取列表中的第1个字典中的topic:内容即包括一级标题在内的xmind内容,content行参
self.content = xmindparser.xmind_to_dict(filePath8)[0]['topic']
# 将content属性返回给方法的调用处self,实例化类对象调用方法时才会获取该属性值,其他类也可以直接通过类对象.变量名调用xmind2dict.content
#return self.content
# 定义一个创建excel模板的类,继承xmind转字典类为了获取中心主题名
class DefineExcel():
# 初始化方法:类对象workexcel\worksheet
def __init__(self):
# 创建一个excel模板类对象为了写入excel类调用该对象进行保存
self.workexcel = xlwt.Workbook(encoding='utf-8')
# 创建一个worksheet类对象就是excel中的第一个表,第二个参数是指单元格是否允许重设置,为了防止重复对一个单元格写入报错,设置允许true
#xmind2dict.content['title']是获取xmind转字典中中心主题名
self.worksheet = self.workexcel.add_sheet('testsheet1',cell_overwrite_ok=True)
# 定义初始化excel字体样式,bold和height是形参代表是否加粗和字体大小
def styles(self, bold, height):
# 初始化样式,就是将excel样式初始化一个对象,可以理解为对这个样式类实例化对象style
style = xlwt.XFStyle()
# 为样式创建字体,也是对字体类实例化对象front
font = xlwt.Font()
font.name = 'Times New Roman'
# 加粗
font.bold = bold
# 字体大小,20是基数不变,18是字体大小
font.height = 20 * height
# 将设置的字体,赋值给类对象
style.font = font
# 将配置好的格式返回给调用处
return style
# 创建背景色
def patterns(self, colors=23):
"""
设置单元格的背景颜色,该数字表示的颜色在xlwt库的其他方法中也适用,默认颜色为白色
0 = Black, 1 = White,2 = Red, 3 = Green, 4 = Blue,5 = Yellow, 6 = Magenta, 7 = Cyan,
16 = Maroon, 17 = Dark Green,18 = Dark Blue, 19 = Dark Yellow ,almost brown), 20 = Dark Magenta,
21 = Teal, 22 = Light Gray,23 = Dark Gray, the list goes on...
"""
pattern = xlwt.Pattern()
pattern.pattern = xlwt.Pattern.SOLID_PATTERN
pattern.pattern_fore_colour = colors
return pattern
# 合并单元格方法
def alignment(self):
# 创建对齐格式对象
alignment = xlwt.Alignment()
# 左右的对其,水平居中 May be: HORZ_GENERAL, HORZ_LEFT, HORZ_CENTER,
# HORZ_RIGHT, HORZ_FILLED, HORZ_JUSTIFIED,
# HORZ_CENTER_ACROSS_SEL, HORZ_DISTRIBUTED
alignment.horz = xlwt.Alignment.HORZ_CENTER
# 上下对齐 May be: VERT_TOP, VERT_CENTER, VERT_BOTTOM, VERT_JUSTIFIED, VERT_DISTRIBUTED
alignment.vert = xlwt.Alignment.VERT_CENTER
return alignment
# 创建excel模板
def buildExcel(self):
# 将styles方法中的字体格式赋值给新的对象,字体加粗且字体大小为18
style2 = self.styles(True, 15)
# 并将背景色方法赋值给给新的对象的背景色属性=style2.pattern
style2.pattern = self.patterns()
# 居中方式赋值给新的对象
style2.alignment = self.alignment()
# 设置worksheet每一列的宽度256 * 20,设置15列,range从0开始不包含15
for m in range(20):
first_col = self.worksheet.col(m)
first_col.width = 256 * 20
# 表头
# 写成excel表格用例的要素
title = ['xmind二级标题', 'xmind三级标题', 'xmind四级标题', 'xmind五级标题', 'xmind六级标题', 'xmind七级标题', 'xmind八级标题', 'xmind九级标题', 'xmind十级标题', 'xmind十一级标题', 'xmind十二级标题', 'xmind十三级标题', 'xmind十四级标题', '是否通过']
# 列表长度15
num = len(title)
# for循环遍历最大到14,从0开始不含15
for i in range(num):
# 往表格中填充表头
## 第一个参数代表行,第二个参数是列,第三个参数是内容,第四个参数是格式调用styles2格式
self.worksheet.write(0, i, title[i], style2)
# 保存workexcel文件名为testcase1,存在项目文件夹内
#self.workexcel.save('testcase1.xls')
# 定义一个类,继承父类Xmind2Dict和DefineExcel
class Xmind2Excel(Xmind2Dict,DefineExcel):
# 将xmind字典内容写入excel
def writeExcel(self):
# 调用其他类方法时,如果调用类方法内参数写了self,那么调用方法时需要使用self.方法名()来调用也可以使用类对象名.方法名
# xm是xmind画布第0个列表中的字典key:topics的values,是一个字典集包含所有节点内容{},是中心主题title和他的topics
xm = xmind2dict.content
print(xm)
x = 1 # 初始化行数
m = 0 # 初始化第一级步骤数,为了合并单元格
n = 0 # 初始化第二级步骤数,为了合并单元格
z = 0 # 初始化第三级步骤数,为了合并单元格
# 二级topics-即二级标题个数,从二级标题开始写入excel topics中是一个list,有多个二级标题则list中有多个{dict}
#len数数据数量,range范围到<len最大数
for a in range(len(xm["topics"])):
testcase2=xm["topics"][a]#画布的第a个二级标题字典组{}
title2=testcase2["title"]#第a个二级标题
print(x)
print(title2)
#写入第a个二级标题
#defineexcel.worksheet.write(x, 0, title2, defineexcel.styles(False, 15))
#行数+1,如果没有三级标题则需要换行进入下一个二级标题
x+=1
#需要判断第a个二级标题字典组中{}是否有title和topics,2个长度,也就是是否会有三级标题,字典长度=2就是有三级标题,需要打印三级标题
if len(testcase2)>=2:
#因为有三级标题,所以行数不需要换行即要减回去
x-=1
for b in range(len(testcase2["topics"])):#topics长度即判断三级单个数
testcase3=testcase2["topics"][b]#画布的第b个三级标题字典组{}
title3=testcase3["title"]#第b个三级单标题
print(x)
print(title3)
#写入三级标题
#defineexcel.worksheet.write(x, 1, title3, defineexcel.styles(False, 15))
#行数+1,如果没有四级标题,则换行循环下一个三级、二级标题
x+=1
# 需要判断testcase2字典组个数是否有title和topics,如果有topics就证明有四级标题,需要打印四级标题
if len(testcase3)>=2:
# 因为有四级标题,所以行数不需要换行即要减回去
x -= 1
for c in range(len(testcase3["topics"])):
testcase4=testcase3["topics"][c]#第c个四级标题字典组{}
title4=testcase4["title"]
print(x)
print(title4)
# 写入四级标题
# defineexcel.worksheet.write(x, 2, title4, defineexcel.styles(False, 15))
# 行数+1,如果没有五级标题,则换行循环下一个四级、三级、二级标题
x += 1
# 需要判断testcase4字典组个数是否有title和topics,如果有topics就证明有五级标题,需要打印五级标题
if len(testcase4) >= 2:
# 因为有五级标题,所以行数不需要换行即要减回去
x -= 1
for d in range(len(testcase4["topics"])):
testcase5 = testcase4["topics"][d] # 第d个五级标题字典组{}
title5 = testcase5["title"]
print(x)
print(title5)
defineexcel.worksheet.write(x, 3, title5, defineexcel.styles(False, 15))
# 行数+1,如果没有六级标题,则换行循环下一个五级、四级、三级、二级标题
x += 1
if len(testcase5) >= 2:
# 因为有六级标题,所以行数不需要换行即要减回去
x -= 1
for e in range(len(testcase5["topics"])):
testcase6 = testcase5["topics"][e] # 第e个6级标题字典组{}
title6 = testcase6["title"]
print(x)
print(title6)
# 写入6级标题
defineexcel.worksheet.write(x, 4, title6, defineexcel.styles(False, 15))
# 行数+1,如果没有7级标题,则换行循环下一个6\5\4\3\2级标题
x += 1
if len(testcase6) >= 2:
# 因为有7级标题,所以行数不需要换行即要减回去
x -= 1
for h in range(len(testcase6["topics"])):
testcase7 = testcase6["topics"][h] # 第h个7级标题字典组{}
title7 = testcase7["title"]
print(x)
print(title7)
(defineexcel.worksheet.write(x, 5, title7,defineexcel.styles(False, 15)))
# 行数+1,如果没有8级标题,则换行循环下一个7\6\5\4\3\2级标题
x += 1
if len(testcase7) >= 2:
# 因为有8级标题,所以行数不需要换行即要减回去
x -= 1
for i in range(len(testcase7["topics"])):
testcase8 = testcase7["topics"][i] # 第i个8级标题字典组{}
title8 = testcase8["title"]
print(x)
print(title8)
defineexcel.worksheet.write(x, 6, title8,defineexcel.styles(False, 15))
# 行数+1,如果没有9级标题,则换行循环下一个8\7\6\5\4\3\2级标题
x += 1
if len(testcase8) >= 2:
# 因为有9级标题,所以行数不需要换行即要减回去
x -= 1
for j in range(len(testcase8["topics"])):
testcase9 = testcase8["topics"][j] # 第j个9级标题字典组{}
title9 = testcase9["title"]
print(x)
print(title9)
defineexcel.worksheet.write(x, 7, title9,defineexcel.styles(False, 15))
# 行数+1,如果没有10级标题,则换行循环下一个9\8\7\6\5\4\3\2级标题
x += 1
if len(testcase9) >= 2:
# 因为有10级标题,所以行数不需要换行即要减回去
x -= 1
for k in range(len(testcase9["topics"])):
testcase10 = testcase9["topics"][k] # 第k个10级标题字典组{}
title10 = testcase10["title"]
print(x)
print(title10)
defineexcel.worksheet.write(x, 8, title10,defineexcel.styles(False, 15))
# 行数+1,如果没有11级标题,则换行循环下一个10\9\8\7\6\5\4\3\2级标题
x += 1
if len(testcase10) >= 2:
# 因为有11级标题,所以行数不需要换行即要减回去
x -= 1
for l in range(len(testcase10["topics"])):
testcase11 = testcase10["topics"][l] # 第l个11级标题字典组{}
title11 = testcase11["title"]
print(x)
print(title11)
defineexcel.worksheet.write(x, 9,title11,defineexcel.styles(False,15))
# 行数+1,如果没有12级标题,则换行循环下一个11\10\9\8\7\6\5\4\3\2级标题
x += 1
if len(testcase11) >= 2:
# 因为有11级标题,所以行数不需要换行即要减回去
x -= 1
for l in range(len(testcase11["topics"])):
testcase12 = testcase11["topics"][l] # 第l个12级标题字典组{}
title12 = testcase12["title"]
print(x)
print(title12)
defineexcel.worksheet.write( x, 10, title12,defineexcel.styles(False, 15))
# 行数+1,如果没有13级标题,则换行循环下一个12\11\10\9\8\7\6\5\4\3\2级标题
x += 1
if len(testcase12) >= 2:
# 因为有11级标题,所以行数不需要换行即要减回去
x -= 1
for l in range(len(testcase12["topics"])):
testcase13 = testcase12["topics"][l] # 第l个12级标题字典组{}
title13 = testcase13["title"]
print(x)
print(title13)
defineexcel.worksheet.write(x, 11, title13,defineexcel.styles(False, 15))
# 行数+1,如果没有13级标题,则换行循环下一个12\11\10\9\8\7\6\5\4\3\2级标题
x += 1
if len(testcase13) >= 2:
# 因为有11级标题,所以行数不需要换行即要减回去
x -= 1
for l in range(len(testcase13["topics"])):
testcase14 = testcase13["topics"][l] # 第l个12级标题字典组{}
title14 = testcase14["title"]
print(x)
print(title14)
defineexcel.worksheet.write(x, 12,title14,defineexcel.styles(False,15))
# 行数+1,如果没有13级标题,则换行循环下一个12\11\10\9\8\7\6\5\4\3\2级标题
x += 1
# 第三列合并居中,不满足if或者满足if走下一个四级标题时走这条合并剧中语句
# 用上一个模块最后行数z+1算下一个模块的开始行,结束行为x-1
defineexcel.worksheet.write_merge( z + 1, x - 1, 2, 2, title4,defineexcel.styles(False, 15))
#模块结束即记录下该模块的行数,执行完居中语句再执行该语句,因为居中语句需要用上一个模块的最后的z,不是当前模块的z
z = x - 1
# 第二列合并居中,不满足if或者满足if走下一个三级标题时走这条合并剧中语句
# 用上一个模块最后行数n+1算下一个模块的开始行,结束行为x-1
defineexcel.worksheet.write_merge( n + 1, x - 1, 1, 1, title3,defineexcel.styles(False, 15))
n = x - 1
# 如果步骤没有进入下一层,那么对于第三列的z就少记录一行,加上x在if前比实际多1,所以需要在这里执行一次z=x-1,就是上一个用例的行数
z = x - 1
#第一列合并居中,不满足if或者满足if走下一个二级单时走这条合并剧中语句
#用上一个二级单最后行数m+1算下一个二级单的开始行,结束行为x-1
defineexcel.worksheet.write_merge(m + 1,x - 1, 0, 0, title2,defineexcel.styles(False, 15))
# 将上一个模块最后的行数赋值给m,因为每一行case结束后都+1了,所以要-1,为了合并居中获取上一个二级标题最后case行,下一个二级标题则从m+1开始到x-1行
m = x - 1
#同理如果一级标题没有走二级、三级则二级三级上一个模块的行就缺失记录了
n = x - 1
z = x - 1
# 保存workexcel文件名为testcase2,执行语句在方法体内即可,存在项目文件夹内
defineexcel.workexcel.save('testcase2.xls')
# 实例化xmind转字典的对象,会直接调类的初始化方法
xmind2dict = Xmind2Dict()
#print(xmind2dict.content)
# 先实例化excel目标对象
defineexcel = DefineExcel()
# 创建模板方法
defineexcel.buildExcel()
# 定义一个类对象,来调用类中的方法或者属性
xmindexcel = Xmind2Excel()
xmindexcel.writeExcel()
参考文档:https://www.jb51.net/article/197244.htm

 浙公网安备 33010602011771号
浙公网安备 33010602011771号