

《三国演义》人物出场统计
使用到的库:jieba
《三国演义》人物出场统计---上

1 #《三国演义》人物出场统计--上 2 import jieba 3 txt = open('I:\三国演义.txt', 'r', encoding = 'utf-8').read() 4 words = jieba.lcut(txt) 5 counts = {} 6 for word in words: 7 if len(word) == 1: 8 continue 9 else: 10 counts[word] = counts.get(word, 0) + 1 11 items = list(counts.items()) 12 items.sort(key=lambda x:x[1], reverse=True) 13 for i in range(15): 14 word, count =items[i] 15 print('{0:<10}{1:>5}'.format(word, count))
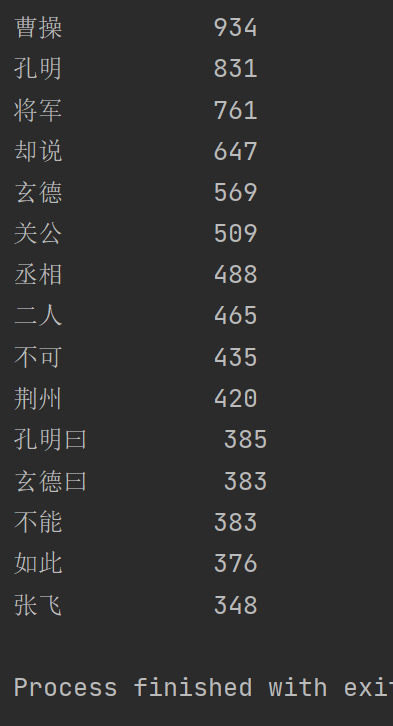
《三国演义》人物出场统计---下
1 import jieba 2 excludes ={'将军','却说','二人','不可','荆州','不能','如此','商议','如何','主公','军士','左右','军马','次日','引兵','大喜'} 3 txt = open('I:\三国演义.txt', 'r', encoding = 'utf-8').read() 4 words = jieba.lcut(txt) 5 counts = {} 6 for word in words: 7 if len(word) == 1: 8 continue 9 elif word == '诸葛亮' or word == '孔明曰': 10 rword = '孔明' 11 elif word == '关公' or word == '云长': 12 rword = '关羽' 13 elif word == '玄德' or word == '玄德曰': 14 rword = '刘备' 15 elif word == '孟德' or word == '丞相': 16 rword = '曹操' 17 else: 18 counts[word] = counts.get(word, 0) + 1 19 for word in excludes: 20 del counts[word] 21 items = list(counts.items()) 22 items.sort(key=lambda x:x[1], reverse=True) 23 for i in range(15): 24 word, count =items[i] 25 print('{0:<10}{1:>5}'.format(word, count))


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?