
CentOS7搭建flink1.6与消费Kafka消息实践
写在最前,本次环境搭建是在Hadoop2.6.1,三节点的基础上完成的。
(关于搭建Hadoop环境,可参考:https://www.cnblogs.com/SysoCjs/p/10835793.html)
说明:
#master,表示在master节点上操作;
#master,#slave1,#slave2,表示在三个节点上都要操作;
一、准备工作 再官网下载合适的flink的tgz压缩包:
http://mirror.bit.edu.cn/apache/flink/
这里下载的是flink-1.6.4-bin-hadoop26-scala_2.11.tgz
然后用scp命令(Git Base或者其他工具也可以)远程分发到CentOS7的master机器指定目录上。
二、解压 #master
cd /usr/local/src/
tar -zxvf flink-1.6.4-bin-hadoop26-scala_2.11.tgz
三、修改配置
#master
cd ./flink-1.6.4/conf/
1、配置JobManager远程地址
vim flink-conf.yaml
修改内容:
jobmanager.rpc.address: master

2、注册master
vim masters
修改内容,这个跟flink-conf-yarm的rest.port配置要一样:
master:8081
3、注册slave
vim slaves
修改内容:
slave1
slave2
四、分发文件
#master
scp -r /usr/local/src/flink-1.6.4 root@slave1:/usr/local/src/
scp -r /usr/local/src/flink-1.6.4 root@slave2:/usr/local/src/
五、验证
#master
1、启动集群
cd /usr/local/src/flink-1.6.4/bin
./start-cluster.sh
master节点:
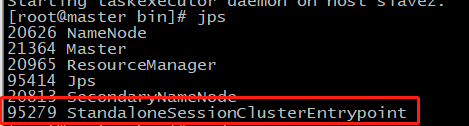
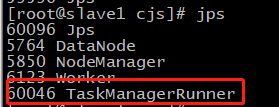
slave节点:
2、监控页面
http://192.168.112.10:8081

五、实例操作
1、在本地IDEA编写代码,然后打包发到虚拟机上:
package com.cjs import java.util.Properties import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer08 import org.apache.flink.streaming.api.scala._ object Kafka2FlinkTest { def main(args: Array[String]): Unit = { val senv = StreamExecutionEnvironment.getExecutionEnvironment val properties = new Properties() properties.setProperty("bootstrap.servers", "192.168.112.10:9092") properties.setProperty("zookeeper.connect", "192.168.112.10:2181") properties.setProperty("group.id", "test_flink") // val stream = senv.addSource(new FlinkKafkaConsumer08[String]("test_receiver",new SimpleStringSchema(),properties)) val stream = senv.addSource(new FlinkKafkaConsumer08[String]("kafka2flink",new SimpleStringSchema(),properties)) // stream.print() stream.flatMap(_.split(" ")).map((_,1L)).keyBy(0).sum(1).print() senv.execute("Flink Kafka") } }

2、执行脚本命令,提交任务
这里介绍的是yarn模式启动flink,所以必须开启hadoop,再之需要使用kafka,所以zk也要事先启动,kafka集群也是,一切环境都准备好之后,输入:
cd /usr/local/src/flink-1.6.4/bin/ ./start-cluster.sh ./flink run -m yarn-cluster -yn 2 -c com.cjs.Kafka2FlinkTest /newDiskB/code/flink/FlinkDemo-1.0-SNAPSHOT-jar-with-dependencies.jar

为了简便,生产者,直接使用kafka的producer:
cd /usr/local/src/kafka_2.11-0.10.2.1/bin/
./kafka-console-producer.sh --broker-list master:9092 --topic kafka2flink
3、查看yarn信息
输入网址:
192.168.112.10:8088

点击application_xxx,


消息生产:
 关闭任务:
关闭任务:

关闭相关环境。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号