
CentOS7安装scala2.11.8+spark2.0.2
说明:
(
1、安装JDK1.8+hadoop2.6+SSH:https://www.cnblogs.com/SysoCjs/p/10835793.html
2、安装hive1.2.2+mysql5.7:https://www.cnblogs.com/SysoCjs/p/10835954.html
)
Master 192.168.112.10
Slave1 192.168.112.11
Slave2 192.168.112.12
#master:表示在master节点上操作
#slave1:表示在slave1节点上操作
#slave2:表示在slave2节点上操作
一、下载资源包
#master
可以使用wget命令下载资源包,但前提是你有对应版本的镜像下载地址。本人习惯是直接到到官网下载资源包到windows下面,然后通过ctrl+c和ctrl+v的方式,将资源包放到虚拟机上面,虚拟机也必须是有可视化操作界面。
![]()
![]()
至于为什么选择这两个版本,首先,scala开发,是要在IDEA上面操作的,可以在IDE上面查看scala的插件版本,本人使用的IDEA是2018.2版本,所以对应的scala版本是2.11.8.
二、解压资源包
#master
将上一步下载回来的资源包拷贝到虚拟机的Desket,为了方便管理,使用mv命令统一移动到一个自己认为比较方便的文件夹下:
mv /home/cjs/Desktop/spark-2.0.2-bin-hadoop2.6.tgz /usr/local/src/
mv /home/cjs/Desktop/scala-2.11.8.tgz /usr/local/src/
去到src目录下,解压压缩包:
cd /usr/local/src/
tar -zxvf scala-2.11.8.tgz
tar -zxvf spark-2.0.2-bin-hadoop2.6.tgz
三、配置相关文件
#master
- 配置scala
vim ~/.bashrc
追加配置项:
export SCALA_HOME=/usr/local/src/scala-2.11.8
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$SCALA_HOME/bin

ESC退出编辑,摁shift+:后,输入wq保存修改,重启资源文件:
source ~/.bashrc
验证scala安装是否成功:
scala -version

远程分发文件到slave1和slave2:
scp -r /usr/local/src/scala-2.11.8 root@slave1:/usr/local/src/
scp -r /usr/local/src/scala-2.11.8 root@slave2:/usr/local/src/
#slave1、#slave2
vim ~/.bashrc
追加配置项:
export SCALA_HOME=/usr/local/src/scala-2.11.8
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$SCALA_HOME/bin
重启配置文件:source ~/.bashrc
- 配置spark
进入spark的conf文件夹:
cd /usr/local/src/spark-2.0.2-bin-hadoop2.6/conf/
编写spark-env.sh,因为本身是没有这个文件,所以采用cp的方式生成该文件:
cp spark-env.sh.template spark-env.sh
修改文件:
vim spark-env.sh
添加内容:
export SCALA_HOME=/usr/local/src/scala-2.11.8
export JAVA_HOME=/usr/local/src/jdk1.8.0_201
export HADOOP_HOME=/usr/local/src/hadoop-2.6.1
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_IP=master
SPARK_LOCAL_DIRS=/usr/local/src/spark-2.0.2-bin-hadoop2.6
SPARK_DRIVER_MEMORY=1G
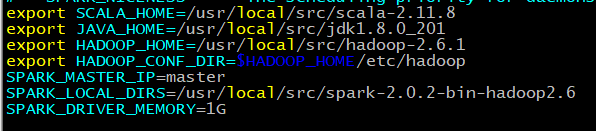
保存,退出。
SPARK_LOCAL_DIRS:此文件夹用于做shuffle和RDD数据
SPARK_DRIVER_MEMORY:驱动器内存大小
编写slaves文件,同样的,slaves文件也是没有的,采用cp方式生成:
cp slaves.template slaves
vim slaves
追加内容:
slave1
slave2

从注释可以看到,这个文件是决定worker节点在哪些机器上启动。
远程分发文件到slave1和slave2上:
scp -r /usr/local/src/spark-2.0.2-bin-hadoop2.6 root@slave1:/usr/local/src/
scp -r /usr/local/src/spark-2.0.2-bin-hadoop2.6 root@slave2:/usr/local/src/
启动spark集群:
/usr/local/src/spark-2.0.2-bin-hadoop2.6/sbin/start-all.sh

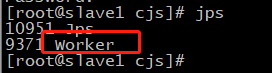
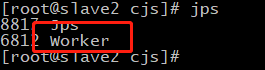
在master机器上出现master节点,slave机器上出现worker节点,说明spark安装成功了一半,还有另一半通过测试才知道。
四、测试spark集群
在spark-2.0.2-bin-hadoop2.6根目录下:
#本地模式
./bin/run-example SparkPi 10 --master local[2]

#yarn集群测试
hadoop集群和spark集群都要打开
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster examples/jars/spark-examples_2.11-2.0.2.jar 10

至此,说明spark安装100%成功

 浙公网安备 33010602011771号
浙公网安备 33010602011771号