
Redis知识点
Redis特征:
1. 数据间没有必然的关联关系
2. 内部采用单线程机制进行工作
3. 高性能。
4. 多数据类型支持
- 字符串类型 String ; 底层数据为String
- 列表类型 List ; 底层为LinkedList
- 散列类型 Hash ; 底层为HashMap
- 集合类型 Set ; 底层为HashSet
- 有序集合类型 Sorted_set ; 底层为TreeSet
注意:数据类型指的是value的类型, key永远都是字符串
5. 持久化支持。可以进行数据灾难恢复
Redis可应用的场景
- 任务队列(抢购、秒杀)
- 失效信息控制(验证码)
- 消息队列
- 分布式锁
- 分布式数据共享(如分布式集群架构中的session分离)
Redis基本操作
1.添加数据
set key value
示例: set name 账单2.查询数据
get key
示例:get name3.删除数据
del key
示例:del name4.清屏
clearRedis持久化方式
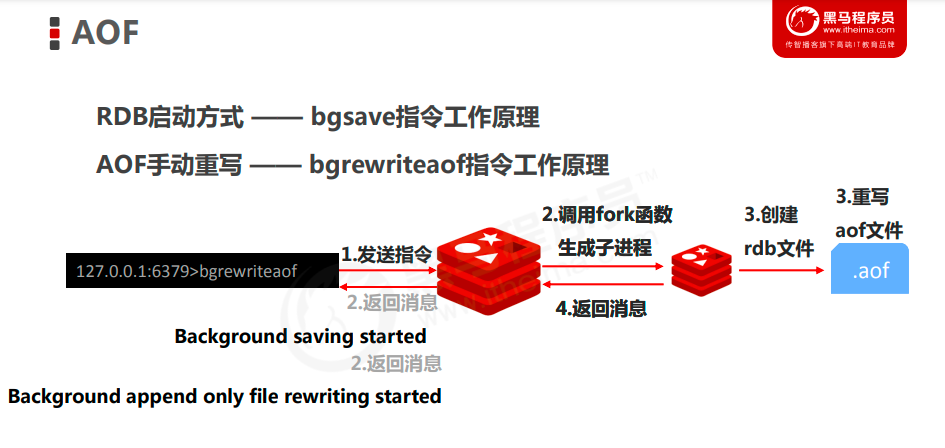
- AOF文件比RDB更新频率高,优先使用AOF还原数据。
- 如果两个都配了优先加载AOF
- RDB性能更能达到最大化:在进行持久化时,会单独开一个子进程来完成写的操作,让主进程继续处理命令,所以是IO最大化。使用单独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 redis 的高性能
4.AOF提供了3中写入策略
(1) always: 每个写命令执行完立马同步回写磁盘
(2) everySec: 每个写命令执行完先把命令存储在AOF文件的内存缓存区,1秒后才将缓冲区中的内容写入磁盘
(3) no: 每个写命令执行完先将命令存储在AOF文件内存缓冲区中,由操作系统控制回写
5. 大量重写,会导致AOF文件过大,解决方案:
AOF重写可以解决文件过大问题,原理:将Redis进程内的数据转化为写命令同步到新AOF文件的过程。简单说就是将对同一个数据的若干个条命令执行结果转化成最终结果数据对应的指令进行记录
6. AOF的重写规则
(1)进程内已超时的数据不在写入文件
(2)忽略无效的指令
(3)对一个数据的多条写命令合并成一条命令
Redis的过期键的删除策略
- 定时过期删除:每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。

- 惰性过期删除:只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。

- 定期过期删除:每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。

Redis对于事务的处理
1. Redis是一组命令的集合,一个集合中所有的命令都会被序列化,其他客户端发起的命令请求不会插入到该队列中
2. Redis对于事务的常用命令:
- multi : 开启事务
- exec : 执行事务
- discard: 取消事务
- watch: 监视一个key或多个key,如果事务在执行前,key已经被其他命令改动,那么会打断事务(写法: watch key 或 watch [key1 key2] )
- unwatch: 取消所有对key的监视
3. Redis事务的两类错误
- 在exec 执行事务前报错
由于语法或内存不足导致,只要出现某个命令无法写入缓冲区的情况,Redis都会进行记录,在客户端执行exec命令时,Redis会拒绝执行该事务(这是2.6.5版本之后的策略。在2.6.5之前的版本中,redis会忽略那些入队失败的命令,只执行那些入队成功的命令)

- 在exec 执行事务时报错
Redis 则采取了完全不同的策略,他会抛开错误的指令,只向下执行正确的指令
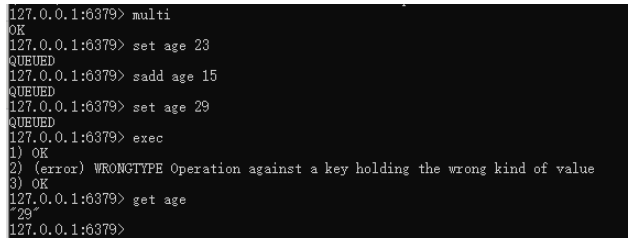
4. Redis不支持回滚
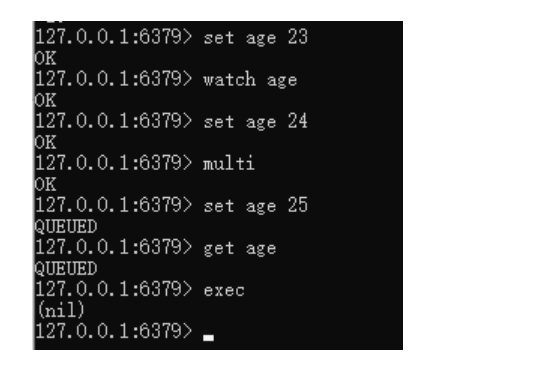
5. Redis的监视策略略 Watch
watch 指令可以实现类似于“乐观锁”的效果,watch在事务为进行exec之前,一直都会对已添加watch的key进行监视,若在multi开启事务后,且在exec执行事务前发现该key被改动,则在执行事务时会返回nil ,表示该事务无法触发
Redis的主从复制
1. 主从复制的目的:解决互联网3高,高可用、高性能、高并发
2. 主从复制的作用:
主:主机 master ; 从: 从机slave
- 读写分离:master写、slave读,提高服务器的读写负载能力
- 负载均衡:基于主从结构,配合读写分离,由slave分担master负载,并根据需求的变化,改变slave的数量,通过多个从节点分担数据读取负载,大大提高Redis服务器并发量与数据吞吐量
- 故障恢复:当master出现问题时,由slave提供服务,实现快速的故障恢复
- 数据冗余:实现数据热备份,是持久化之外的一种数据冗余方式
- 高可用基石:基于主从复制,构建哨兵模式与集群,实现Redis的高可用方案
主从复制的流程
主从复制大致分为3个阶段
(1)建立连接阶段:建立slave到master的连接,使master能够识别slave,并保存slave端口号(2)数据同步阶段
(3)命令传播阶段
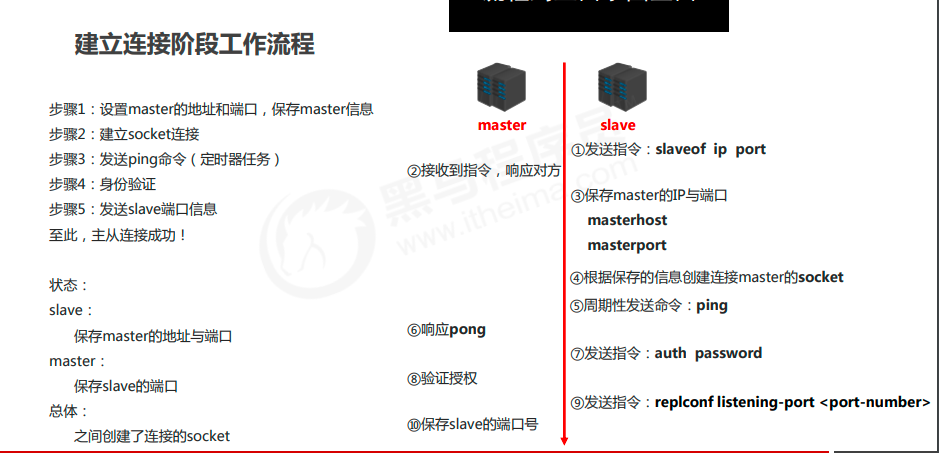
建立连接阶段

 浙公网安备 33010602011771号
浙公网安备 33010602011771号