

目录
一、实验内容和实验任务
1. 实验任务1
任务1-1
使用debug调试程序,首先使用-u进行反汇编,可以看到第19行的地址是000D,因此使用-g D进行断点调试。
问题①
执行完成后可以看到:
DS = 076A
SS = 076B
CS = 076C

问题②
code段地址为X,则data段地址为X-2h,stack段地址为X-1h
由于data段、stack段刚好各分配了16B的单位,而系统为段内存分配都是以16B为单位分配的,由于物理地址 = 段地址 × 16 + 偏移地址,因此相隔16B正好段地址相差1h
任务1-2
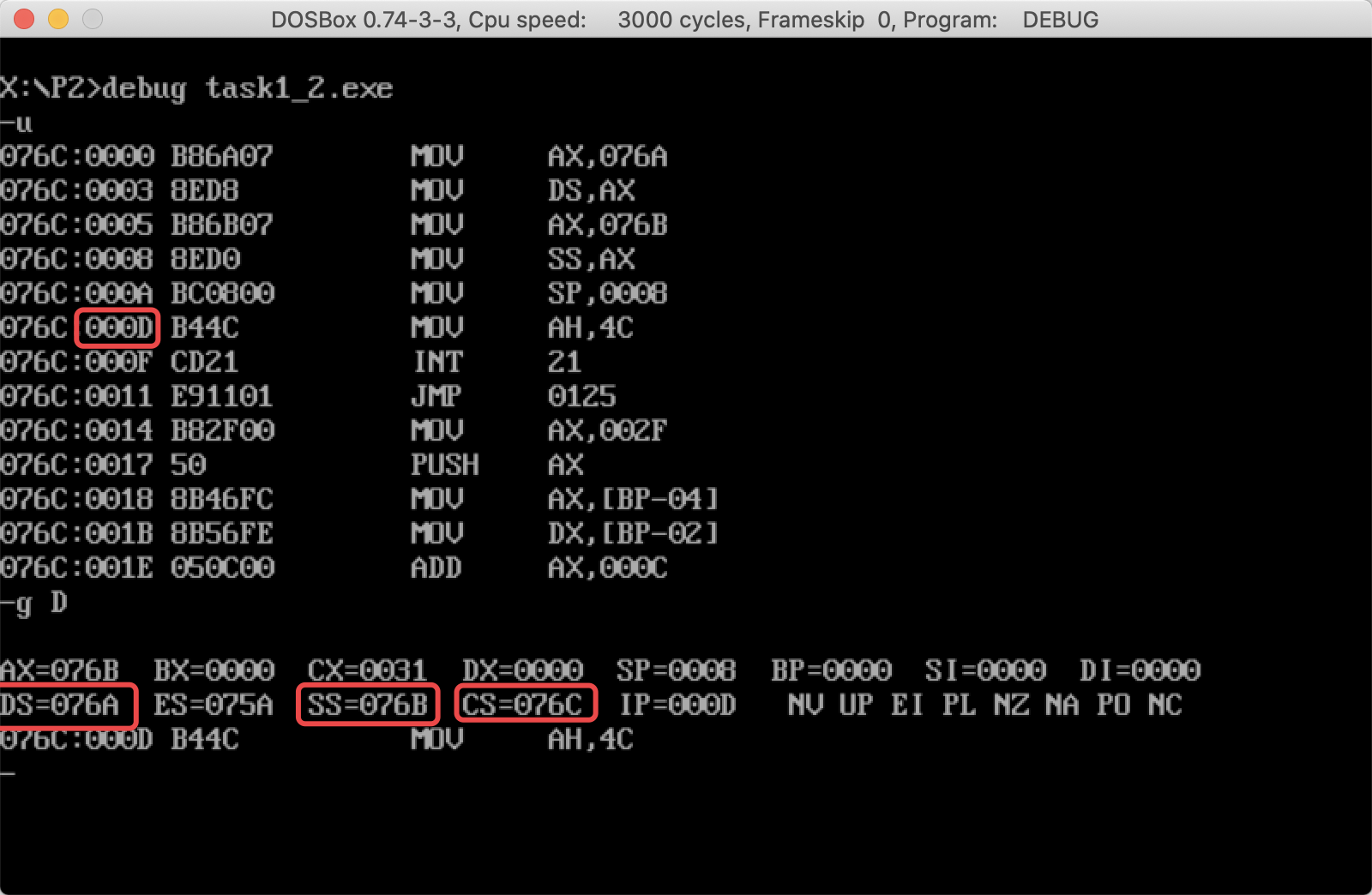
问题①
执行完成后可以看到:
DS = 076A
SS = 076B
CS = 076C
问题②
code段地址为X,则data段地址为X-2h,stack段地址为X-1h
由于data段、stack段刚好各分配了16B的单位,而系统为段内存分配都是以16B为单位分配的,由于物理地址 = 段地址 × 16 + 偏移地址,因此相隔16B正好段地址相差1h
任务1-3
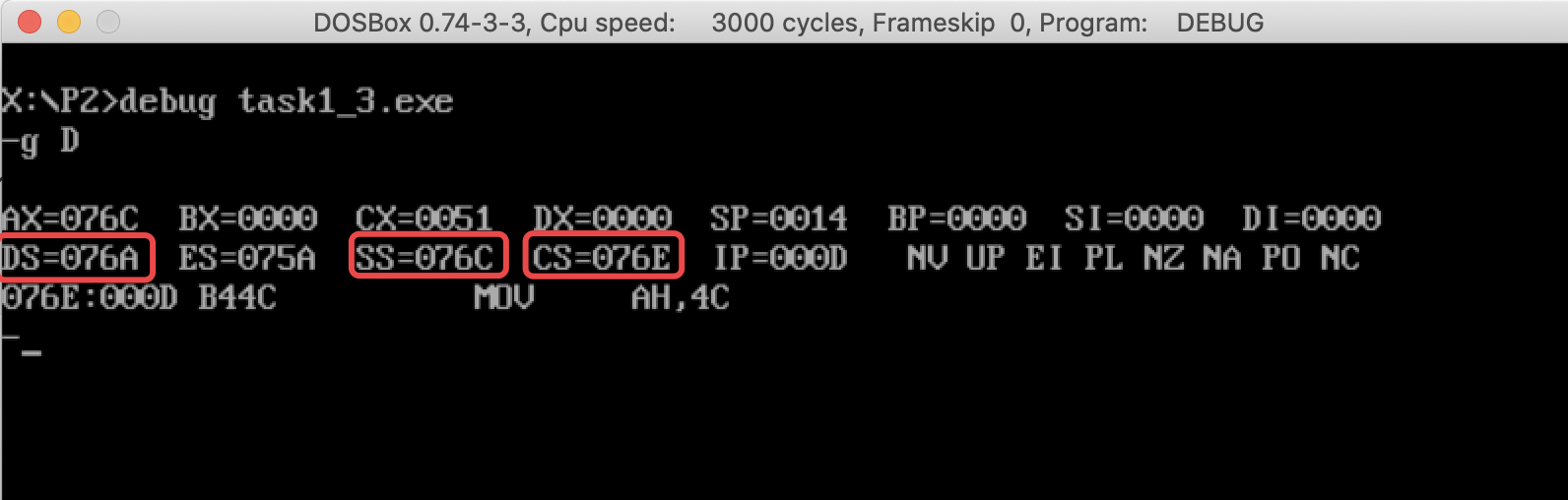
问题①
执行完成后可以看到:
DS = 076A
SS = 076C
CS = 076E
问题②
code段地址为X,则data段地址为X-4h,stack段地址为X-2h
任务1-4

问题①
执行完成后可以看到:
DS = 076C
SS = 076E
CS = 076A
问题②
code段地址为X,则data段地址为X+2h,stack段地址为X+4h
任务1-5
问题①
对如下定义段
xxx segment
db N dup(0)
xxx ends
程序加载后,实际分配给该段的内存空间大小是 16 × [数据长度 / 16] Byte([ ]为向上取整)。
问题②
task1_4.asm仍可以正常运行。
原因:
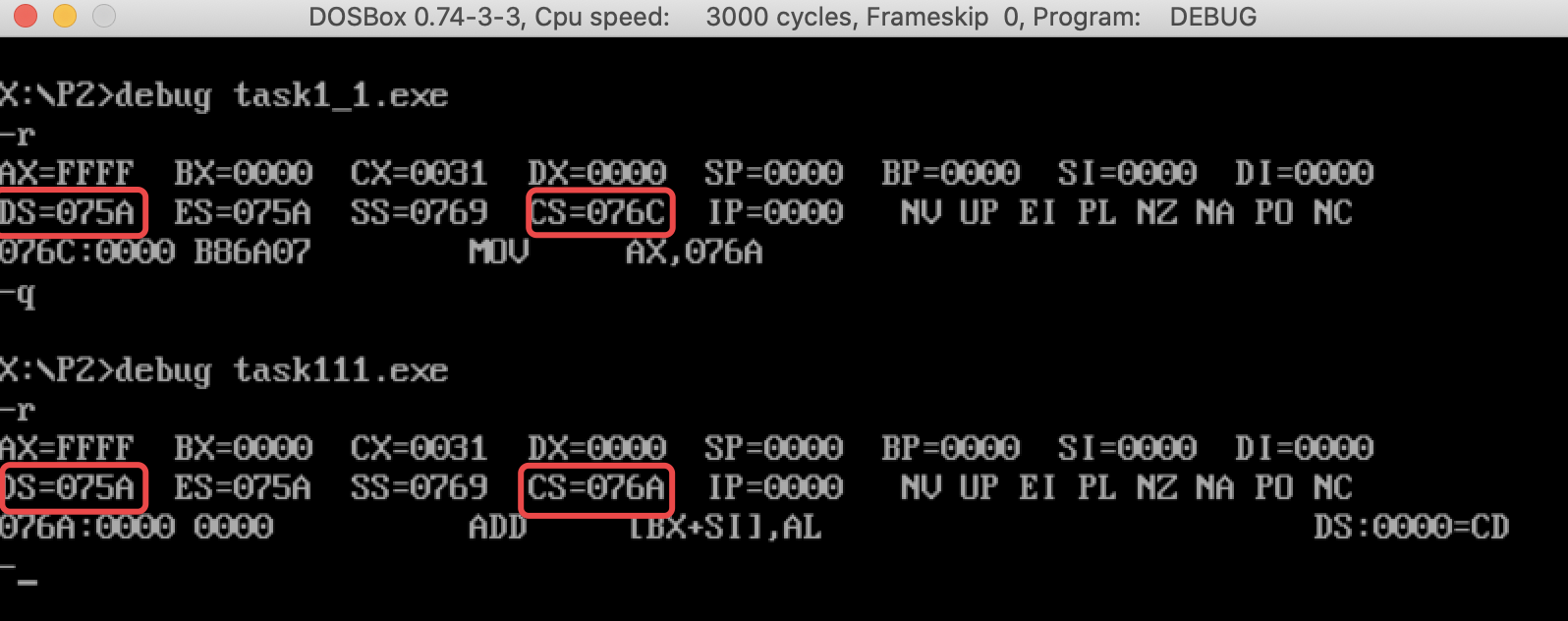
书上说(王爽《汇编语言》第2版 P126-127):
end除了通知编译器程序结束外,还可以通知编译器程序的入口在什么地方。在程序6.2中我们用end指令指明了程序的入口在标号start处。
伪指令end 描述了程序的结束和程序的入口。在编译、连接后,"end start" 指明的程序入口,被转化为一个入口地址,存储在可执行文件的描述信息中。
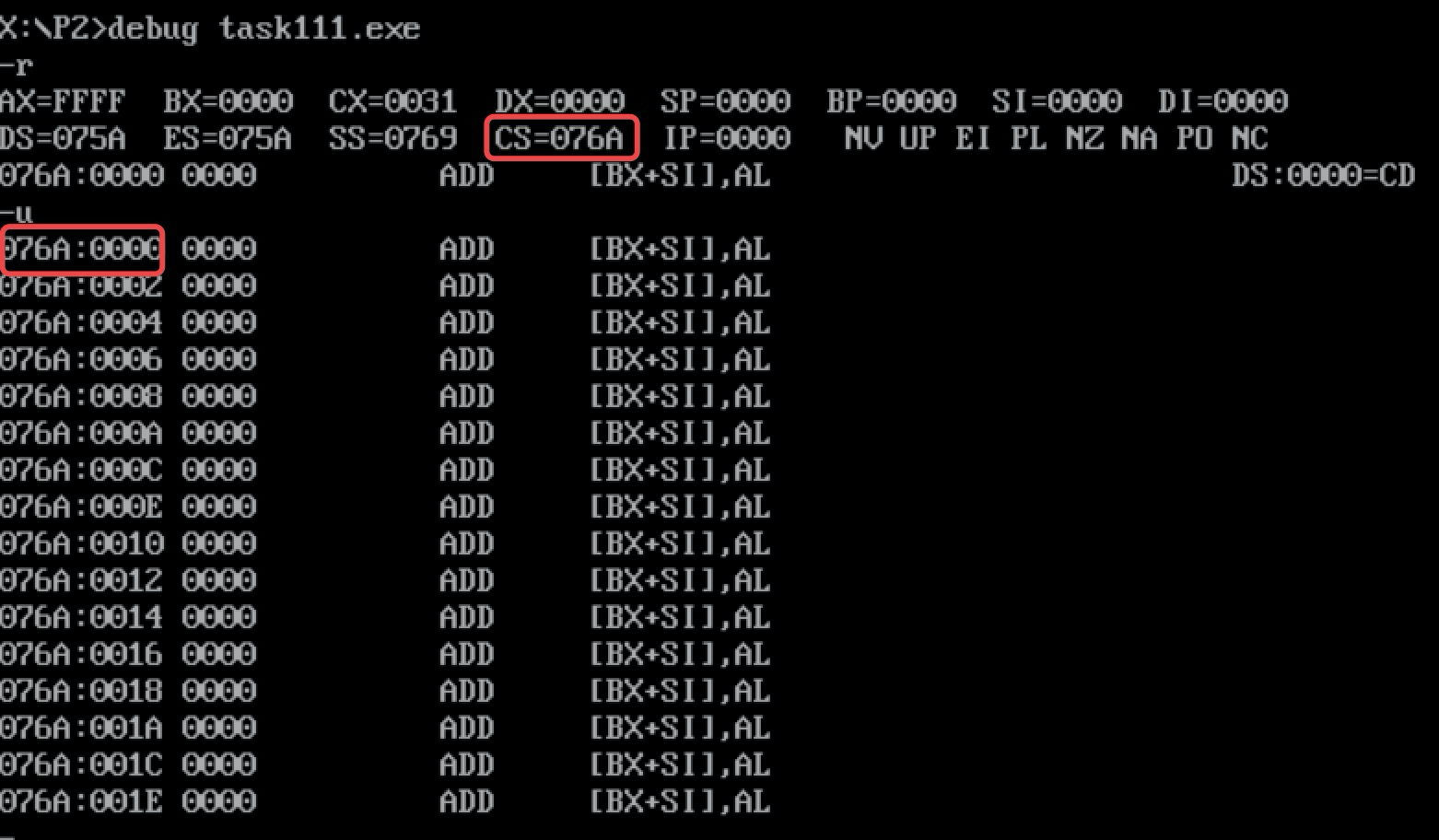
由实验1可知,程序默认DS与CS之间间隔一个PSP区,该区有256Byte,也就是说DS与CS地址默认相差10h。如果没有指出程序开始位置,程序默认从DS+10h处开始运行。上图的task111.exe将end start改成了end,使用-r查看寄存器,可以看到CS的值为076A,而非task1_1.exe中的076C。
使用反汇编进行查看,可以发现CS开始的区域全部为0,没有指令可供执行
任务1总结
- 系统按程序段定义顺序依次分配内存单元
- 程序段分配的内存空间按16Byte的倍数进行分配,如果不满16Byte则分配16Byte,如果超出16Byte则按
16 × [数据长度 / 16] Byte来分配。([ ]为取整) end start除了通知编译器程序结束,也是指出程序的入口地址
如果段中数据位 N 个字节,程序加载后,该段实际占据空间为:(N/16的取整数+1)16个字节,如果 N小于16,那么实际占用16个字节(理解这个小问题);如果N大于16,那么实际占用(N/16的取整数+1)16个字节。
引用:https://blog.csdn.net/freeking101/article/details/99694092
2. 实验任务2
代码
assume cs:code
code segment
start:
mov ax, 0b800h
mov ds, ax
mov bx, 0f00h
mov cx, 50h ; 50h,即80次,每次1个字,160字节
mov ax, 0403h ; 按字写入
s: mov ds:[bx], ax
add bx, 2 ; bx+2才是下一个字的地址
loop s
mov ah, 4ch
int 21h
code ends
end start
分析说明
Line 5Lline 6:0b800h不能直接传入DS,必须通过AX进行中转
Line8和Line 9:由于一共写入160字节,这里按字写入,所以只需要写80次,也就是50h次
Line11:每次bx需要+2,后移两个字节继续写入
运行结果
第一张图:-f b800:0f00 0f9f 03 04执行后的效果
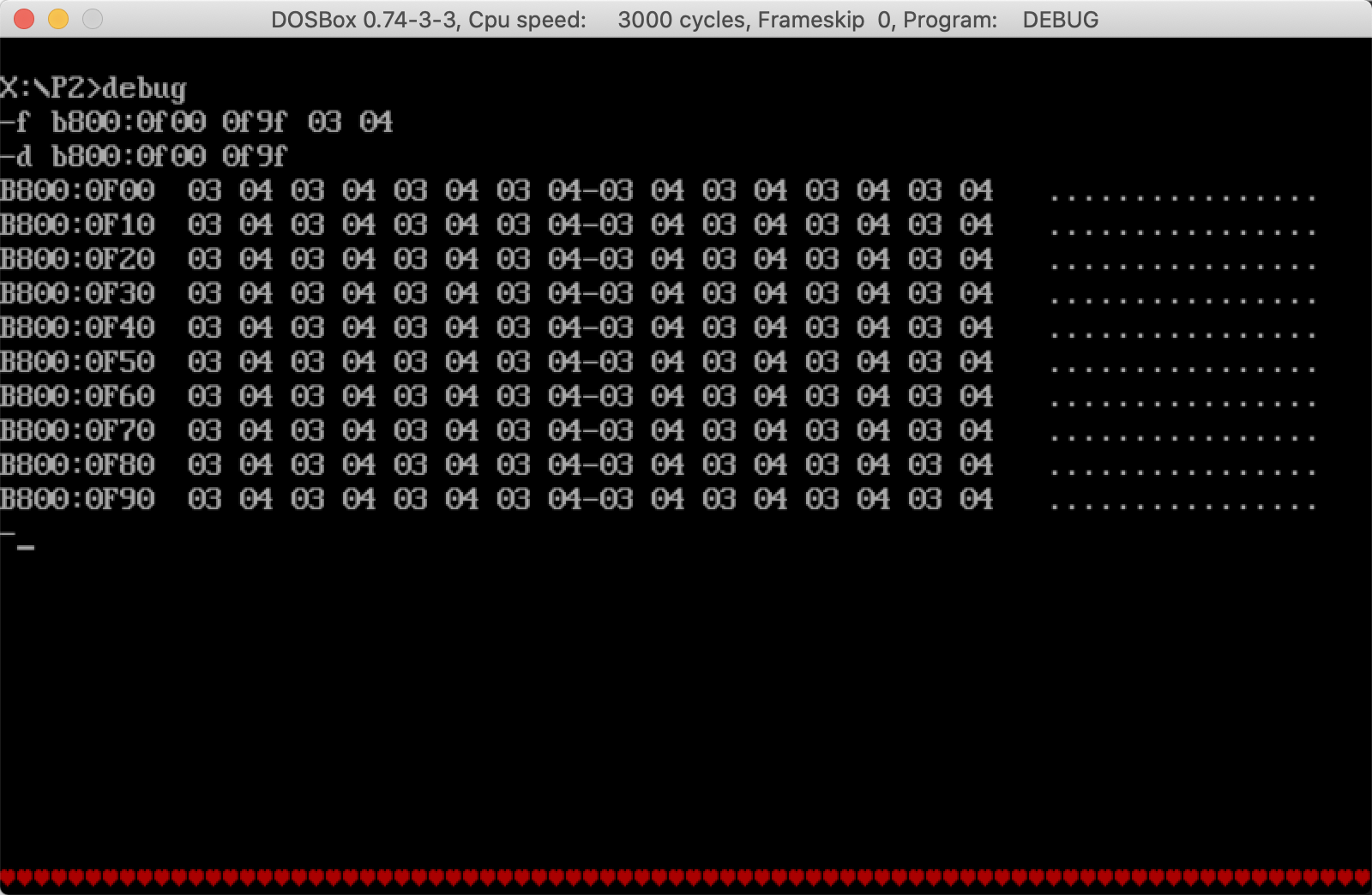
第二张图:task2.exe执行后的效果
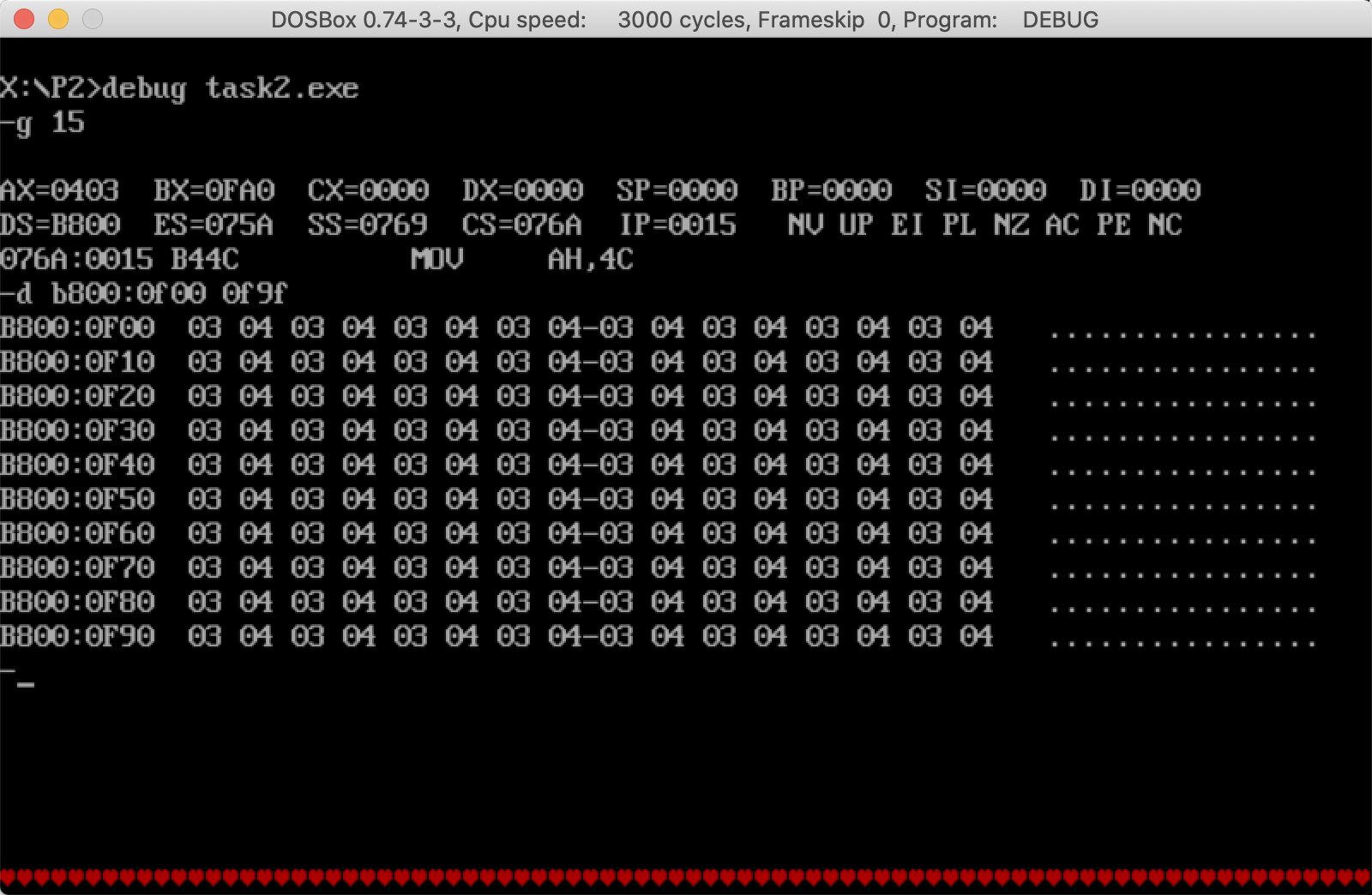
可以看到两个效果完全一致。
3. 实验任务3
代码
assume ds:data1, cs:code
data1 segment
db 50, 48, 50, 50, 0, 48, 49, 0, 48, 49 ; ten numbers
data1 ends
data2 segment
db 0, 0, 0, 0, 47, 0, 0, 47, 0, 0 ; ten numbers
data2 ends
data3 segment
db 16 dup(0)
data3 ends
code segment
start:
mov ax, data1 ; data1作为ds
mov ds, ax
mov bx, 0
mov cx, 0ah ; 循环10次
s: mov ax, ds:[bx] ; 把data1中的数据放进ax
add ax, ds:[bx+10h] ; 把data2中的数据加到ax上
mov ds:[bx+20h], ax ; 把ax数据存入data3
inc bx
loop s
mov ah, 4ch
int 21h
code ends
end start
代码说明
数据段data1:076A:0000-076A:000F
数据段data2:076A:0010-076A:001F
数据段data3:076A:0020-076A:002F
根据上一个实验任务,数据段的分配以16字节为单位,data1和data2虽然只有10字节,但仍会被分配16字节的空间。
对于Line21-22:
三个数据段的地址空间连续,将DS设为data1的起始地址,则data2的起始地址为ds+10h,data3的起始地址为ds+20h
运行结果
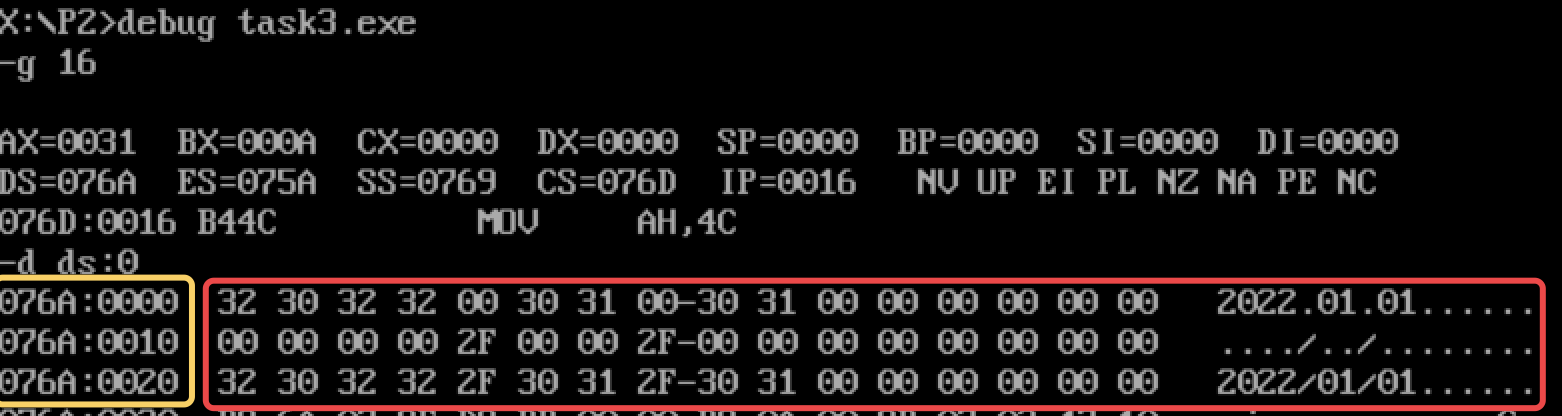
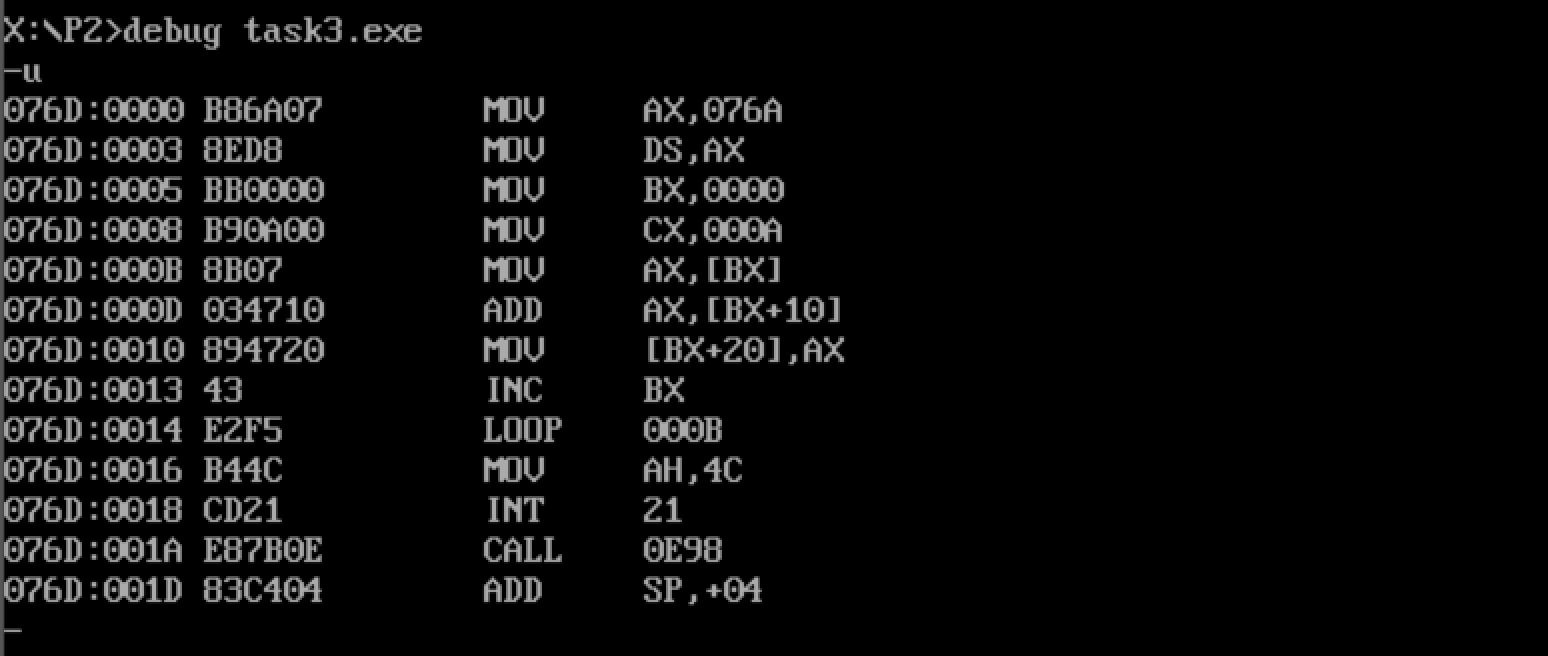
反汇编:
相加前:

相加后:

可以看到data1和data2的数据的确相加存入了data3中。
该部分原理参考:https://www.cnblogs.com/danqing/archive/2011/12/01/2270429.html
4. 实验任务4
代码
assume cs:code, ss:stack
data1 segment
dw 2, 0, 4, 9, 2, 0, 1, 9
data1 ends
data2 segment
dw 8 dup(0)
data2 ends
; 定义了一个栈段
stack segment
dw 8 dup(0)
stack ends
code segment
start:
mov ax, data1
mov ds, ax ; 先把data1作为数据段ds
mov sp, 9 ; 设置栈顶
mov bx, 0
mov cx, 8 ; 循环8次,将data1的数据依次进栈
s1: push ds:[bx]
add bx, 2 ; 由于操作的是字数据(dw),bx每次需要+2
loop s1
mov ax, data2 ; 再把data2作为数据段ds
mov ds, ax
mov bx, 0
mov cx, 8 ; 循环8次,将栈中数据依次出栈,存储data2中
s2: pop ds:[bx]
add bx, 2
loop s2
mov ah, 4ch
int 21h
code ends
end start
运行结果
执行前可以看到:
数据段data1起始地址为:076A:0000
数据段data2起始地址为:076A:0010
data2中全为0

执行后查看076A:0000处开始的内容:

可以看到数据被逆序存放在了076A:0010开始的位置,也就是data2所在位置
程序完成了题目的要求
思路说明
使用了栈段stack用来临时存储数据,将data1中的数据从头到尾依次进栈,然后再将栈中数据弹出,依次存入data2中,完成数据逆序存储
5. 实验任务5
代码
assume cs:code, ds:data
data segment
db 'Nuist'
db 2, 3, 4, 5, 6
data ends
code segment
start:
mov ax, data
mov ds, ax ; ds存放数据段地址
mov ax, 0b800H
mov es, ax ; ex存放显存段地址
mov cx, 5 ; 循环5次
mov si, 0
mov di, 0f00h
s: mov al, [si] ; 把ds段的一个字母放进al
and al, 0dfh ; 字母和0DFh相与
mov es:[di], al ; 把相与的结果放进es[di]
mov al, [5+si] ; 把data段的一个数字移入al
mov es:[di+1], al ; 把数字移到es[di+1]位置
inc si ; si+1
add di, 2 ; di+2(往后移2字节)
loop s
mov ah, 4ch
int 21h
code ends
end start
运行结果
- 原始代码运行结果
可以看到屏幕左下角出现了彩色的NUIST字样
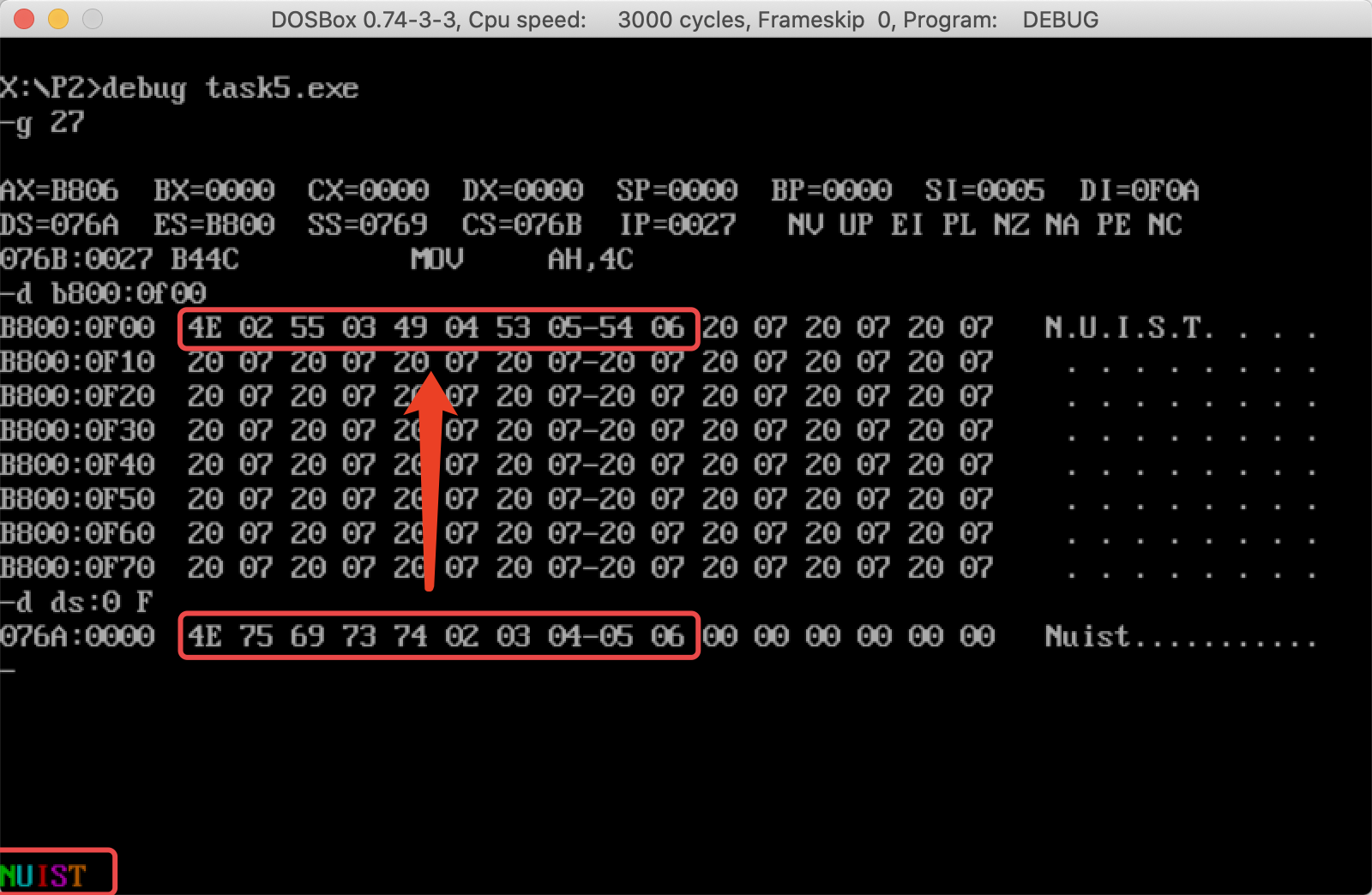
-
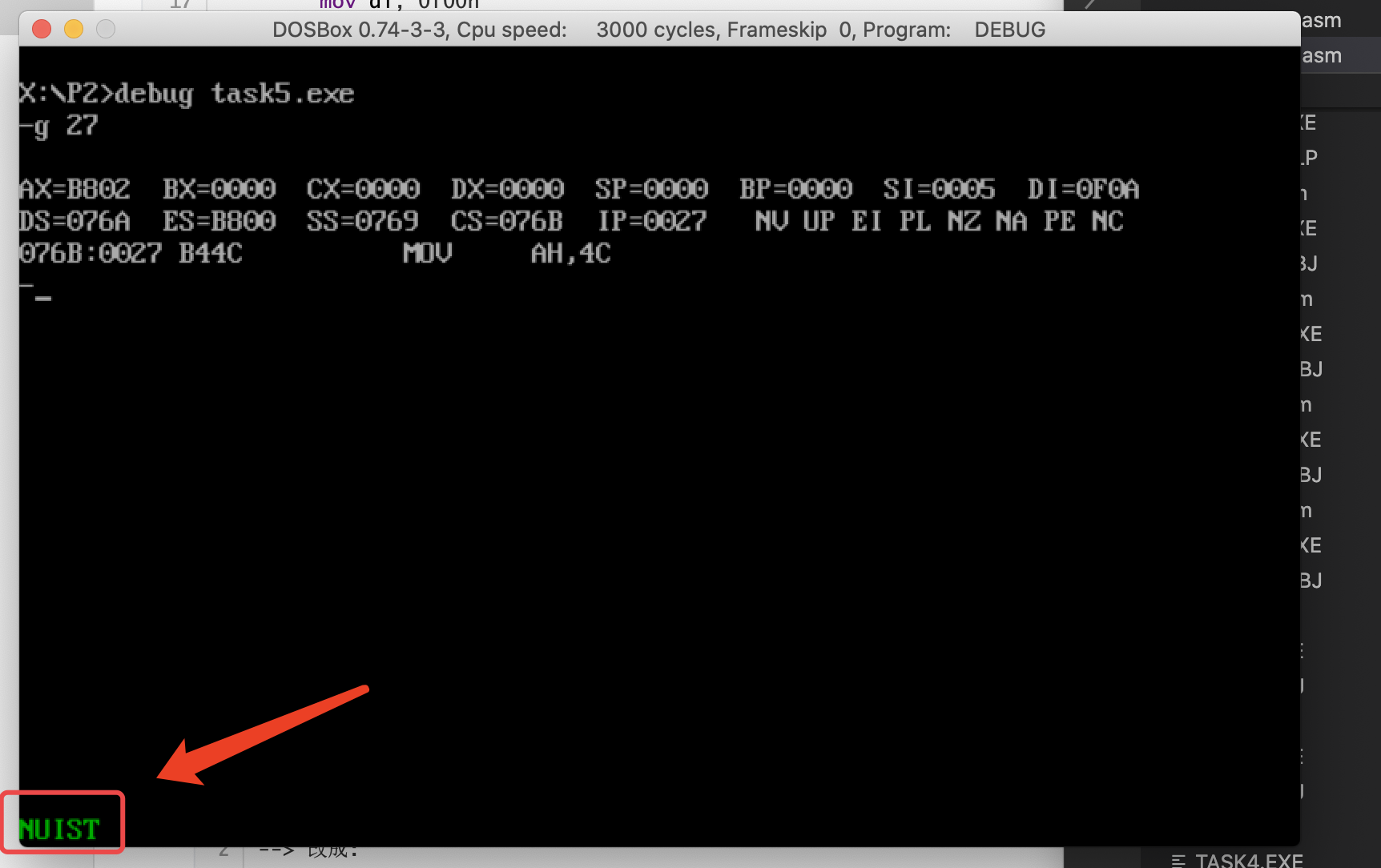
修改line4里5个字节单元的值,重新汇编、链接、运行的结果
(1)将Line 4修改为:
db 5 dup(2)可以看到左下角出现了绿色的”NUIST“字样
![]()
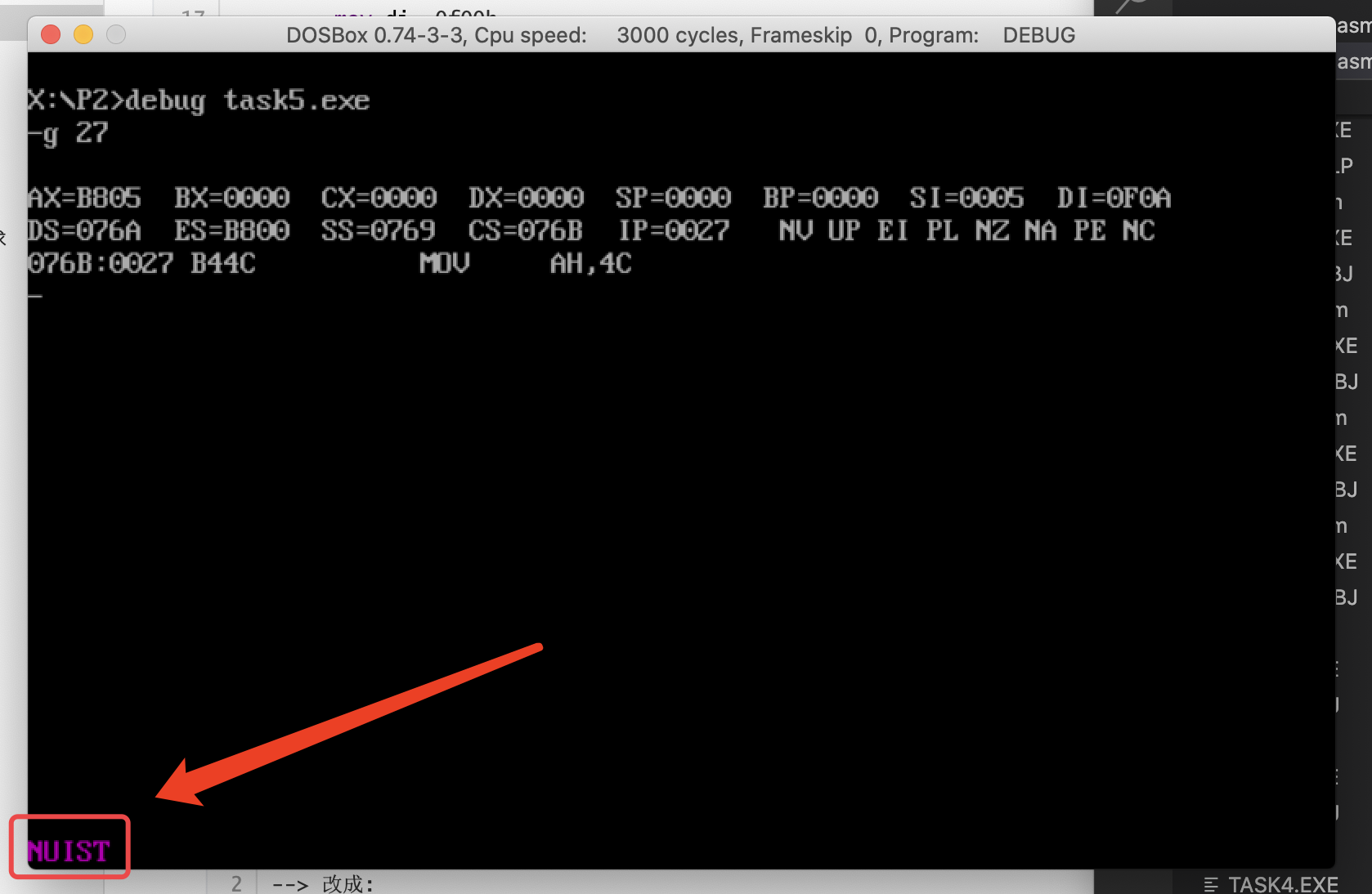
(2)将Line 4改为:
db 5 dup(5)可以看到左下角出现了紫色的”NUIST“字样
![]()
问题&分析
该程序的功能是:将小写字母转换成大写字母,并以不同的颜色打印到屏幕上
- Line 19 的作用:将小写字母转换成大写字母
通过分析可知,0DFh的二进制是:1101 1111
0010 0000
任何数与其相与,从高到低第3位始终为0
由于低4位没有变化,简单起见取高4位进行分析,可以发现,每间隔两个数,会有两个数发生改变,其值会减2,如下表所示。
| 原数字(16进制) | 原数字(2进制) | 新数字(16进制) | 是否改变(减2) |
|---|---|---|---|
| 0 | 0000 | 0 | - |
| 1 | 0001 | 1 | - |
| 2 | 0010 | 0 | 是 |
| 3 | 0011 | 1 | 是 |
| 4 | 0100 | 4 | - |
| 5 | 0101 | 5 | - |
| 6 | 0110 | 4 | 是 |
| 7 | 0111 | 5 | 是 |
| 8 | 1000 | 8 | - |
| 9 | 1001 | 9 | - |
| A | 1010 | 8 | 是 |
| B | 1011 | 9 | 是 |
| C | 1100 | C | - |
| D | 1101 | D | - |
| E | 1110 | C | 是 |
| F | 1111 | D | 是 |
观察ASCII表可知,大写字母的ASCII码二进制表示的高4位为4或5,查阅上表可知4和5在Line 19相与时不会发生改变。
而小写字母的高4位二进制表示为6或7,通过上表可知在Line 19相与时,其高4位的值会减2,变为4或5。对比下表分析可以发现,同一个字母大小写的ASCII码低4位二进制表示是一样的,而高4位的十六进制表示相差2。因此在执行Line 19的相与操作时,大写字母没有变化,而小写字母会变成大写字母。
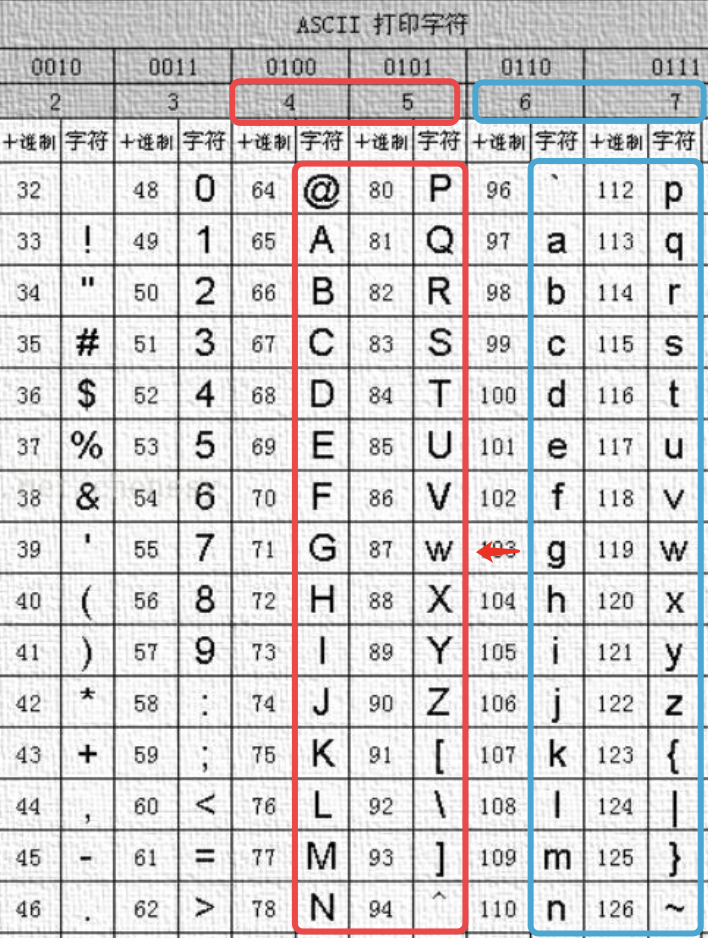
- Line 4的内容的用途:8位色彩代码
由于这边定义的是db也就是字节,1个字节为8位,所以这里的5个数是8位色彩代码,不同的数字对应了不同的色彩编号。但是由于现在的计算机使用的为24位真彩色,其十六进制代码为8位,找不到8位色彩对应的色彩表,所以暂时无法根据代码确定颜色,只能随机尝试。
2021.12.14更新:
当时写的时候没看书,网上也没搜到详细资料,大意了。
Line 4的内容其实包含了四个内容:闪烁(第1位)、背景颜色(第2-4位)、高亮(第5位)、前景颜色(第6-8位)。
详细分析请看《汇编实验3 转移指令跳转原理及其简单应用编程 - 实验任务4》
6. 实验任务6
代码
assume cs:code, ds:data
data segment
db 'Pink Floyd '
db 'JOAN Baez '
db 'NEIL Young '
db 'Joan Lennon '
data ends
code segment
start:
mov ax, data
mov ds, ax
mov ax, data
mov es, ax ; 使用es控制段地址
mov bx, 0 ; 当前字母偏移
mov cx, 4 ; 执行4行
s1: ; 进入外层循环
mov si, cx ; 备份外层循环次数
mov cx, 4 ; 给内层循环次数赋值
s2: ; 进入内层循环
mov al, es:[bx] ; 先把字母放入ax
or al, 20h ; ds:[bx]相与, 大写变小写, 原理参考task5
mov es:[bx], al ; 将转换好的字母放回去
inc bx ; 字母指针后移
loop s2
; 内层循环结束
; 回到外层循环
mov cx, si ; 恢复外层循环的次数
mov bx, 0 ; bx置0, 为下一次循环做准备
mov ax, es ; es不能直接修改, 需要通过ax中转
inc ax ; 移到下一行字符串开头(段地址+1, 偏移16字节)
mov es, ax ; 修改es
loop s1 ; 外层循环结束
mov ah, 4ch
int 21h
code ends
end start
调试和运行结果
通过-u cs:0 2c进行反汇编可以发现,CS:002C是退出语句,因此使用-g 2c进行断点调试

先单步调试到将data地址载入ds,使用-d ds:0查看初始值,可以看到第一个单词中都夹杂着大写字母
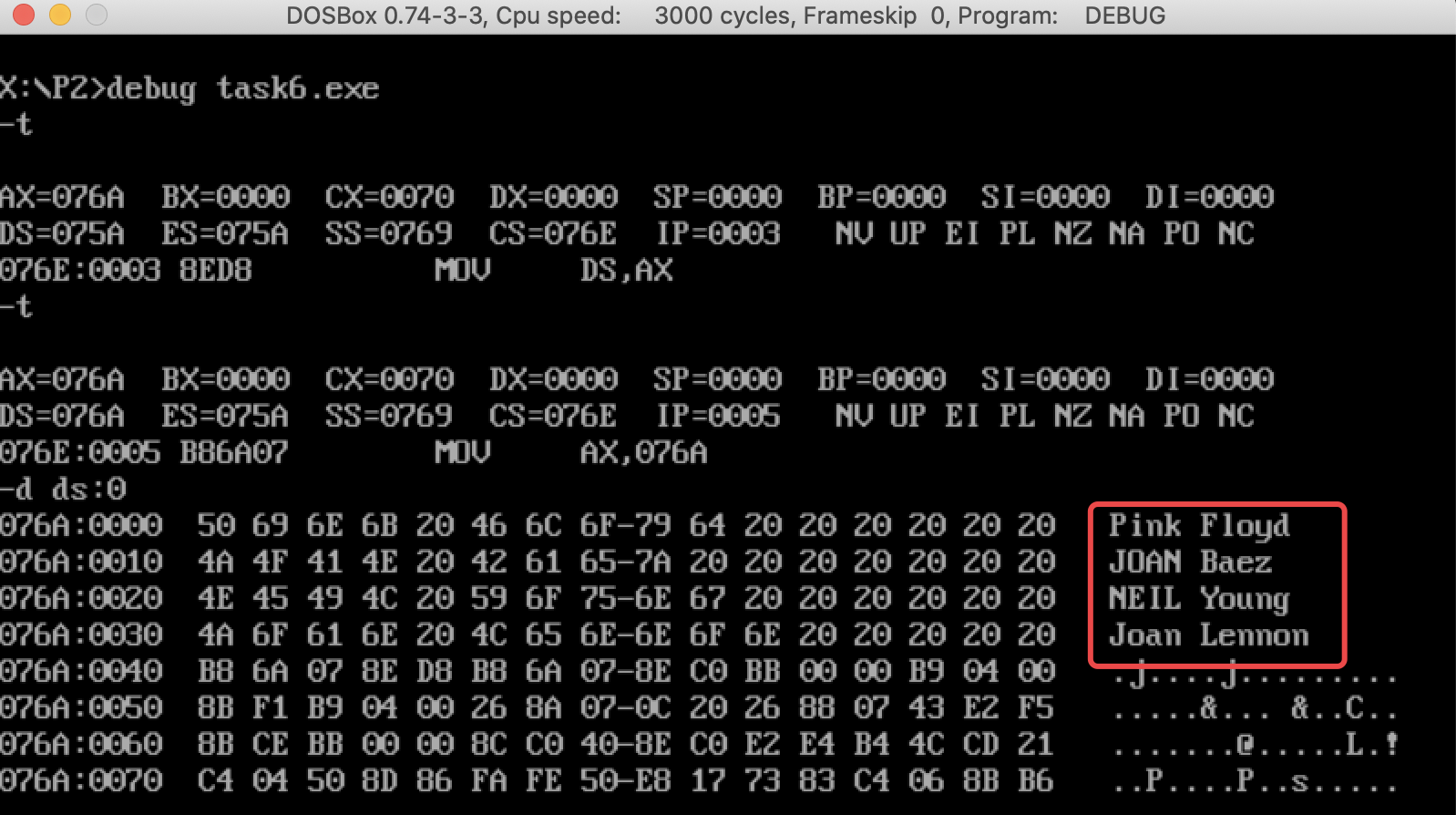
使用-g 2c断点调试运行后,使用-d ds:0查看ds内的值
可以看到第一个单词全部变成了小写,达到了预期结果
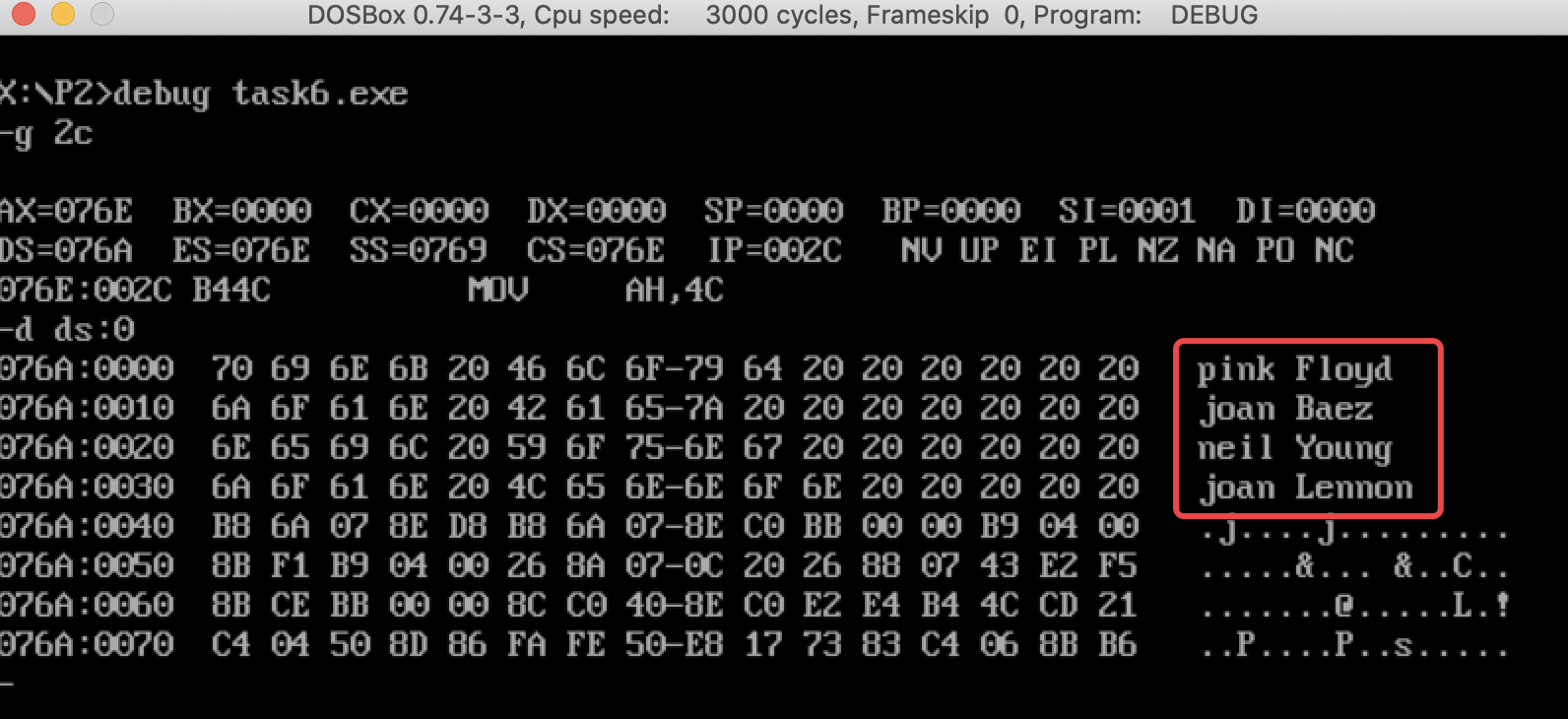
分析
这个程序使用了双重循环,第一层循环控制行数,第二层循环控制每行内的字母
- 字母大小写转换
内循环(第二层)负责将每行前4个字母依次变成小写,原理是参考task5中大小写转换的思路,这里是大写转小写,需要将大写字母十六进制ASCII码的高4位从4或5变成6或7。
task5中是将字母与0DFh相与,将从高到低第3位全部变0,因此本题中大写转小写需要将第3位全部变1。将某一位全部变1的方法是用1去进行或运算。因此本题中,使用字母的ASCII码和20h进行或运算(20h的二进制表示:0010 0000),对应代码中Line 26:or al, 20h
- 双重循环代码编写
实现双重循环,但是只有一个cx用于控制循环次数,因此在外循环进入内循环前需要将外循环的cx值保存起来(对应代码Line 21:mov si, cx),然后在内循环结束后将cx的值恢复回去(对应代码Line 33:mov cx, si)
7. 实验任务7
思路
由于data段中的数据连续,采取从ds开始从头读到尾的按行读入思路进行,es则是按列写入
先把年份依次取出,放在每行首列,然后依次取出5年的收入、5年雇员数,放在每行对应列上,最后对table中每行分别计算人均收入
代码
assume cs:code, ds:data, es:table
data segment
db '1975', '1976', '1977', '1978', '1979' ; 20字节
dd 16, 22, 382, 1356, 2390 ; 5个双字, 20字节
dw 3, 7, 9, 13, 28 ; 5个字, 10字节
data ends
table segment
db 5 dup( 16 dup(' ') ) ; 5行,每行16字节
table ends
code segment
start:
mov ax, data
mov ds, ax
mov ax, table
mov es, ax
; 1.把年份放入每行开头
mov bx, 0 ; table行指针(每行开始地址)
mov si, 0 ; table中的字节指针
mov di, 0 ; data中的字节指针
mov cx, 5 ; 5个年份
year:
; 外循环, 5个年份
mov dx, cx ; 保存cx
mov cx, 4 ; 每个年份4个数字
yearnum:
; 内循环, 每个年份的4个数字
mov al, byte ptr ds:[di] ; 内存之间不能直接转移,需要寄存器中转
mov byte ptr es:[bx][si], al
inc si ; table指针后移
inc di ; data中指针后移
loop yearnum
; 内循环结束, 一个年份放到位
; 继续外循环
mov cx, dx ; 恢复cx
add bx, 10h ; bx移到table下一行开始的位置
mov si, 0 ; si指向table下一行的第一个位置
loop year
; 外循环结束, 5个年份放入表中
; 2.把收入放入每行中
mov bx, 0 ; table第1行
mov si, 5 ; table第6列(收入开始的那一列)
mov cx, 5 ; 5个收入
income:
; 收入是dword, 一次放不了双字, 只能分两个字放过去
mov ax, word ptr ds:[di]
mov word ptr es:[bx][si], ax
add si, 2
add di, 2
mov ax, word ptr ds:[di]
mov word ptr es:[bx][si], ax
add si, 2
add di, 2
add bx, 10h ; table下一行
mov si, 5 ; table下一行的第6列
loop income
; 3.把雇员放入每行
mov bx, 0 ; table第1行
mov si, 0Ah ; table第11列
mov cx, 5 ; 雇员放5次
employee:
; 雇员是单字, 直接放就行
mov ax, word ptr ds:[di]
mov word ptr es:[bx][si], ax
add si, 2
add di, 2
add bx, 10h ; table下一行
mov si, 0Ah ; table下一行第10列
loop employee
; 4.计算人均收入
mov bx, 0 ; table第1行
mov si, 5 ; table第6列,收入那一列开始
mov cx, 5 ; 计算5年的
average:
; 这里注意: 是从低地址依次取出两个字
; 32位被除数低16位放ax, 因此第一次取出的一个字要放在ax
mov ax, word ptr es:[bx][si]
add si, 2
; 32位被除数高16位放dx
mov dx, word ptr es:[bx][si]
add si, 3 ; 需要跳过一个空格
; 除法运算
div word ptr es:[bx][si]
add si, 3 ; 需要跳过一个空格
; 把ax中的商取出放在表中
mov word ptr es:[bx][si], ax
add bx, 10h ; table下一行
mov si, 5 ; table下一行第5列
loop average
mov ah, 4ch
int 21h
code ends
end start
调试运行和运行结果
-
先单步执行Line 15 - Line 18,查看
data和table内的数据可以看到
ds开始的部分载入了data段的数据,es开始的部分前80字节全部为空格(20h),说明data段和table段已经正确载入
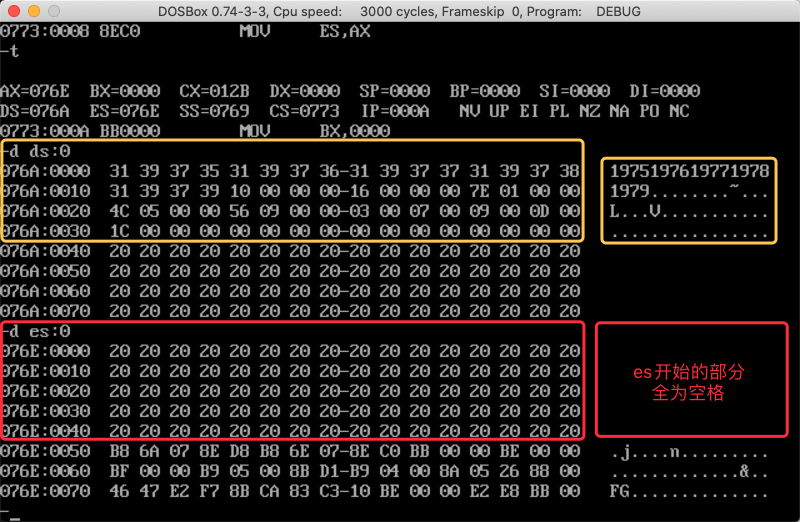
-
在debug中进行反汇编,可以看出程序在
CS:0097位置结束因此使用
-g 97进行断点调试
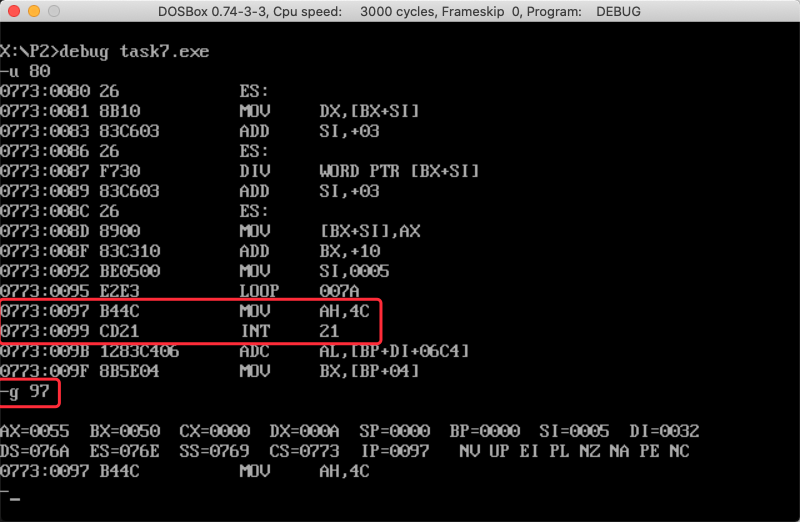
- 运行整个程序后再次查看
data和table内的数据(ds和es开始的内存空间)
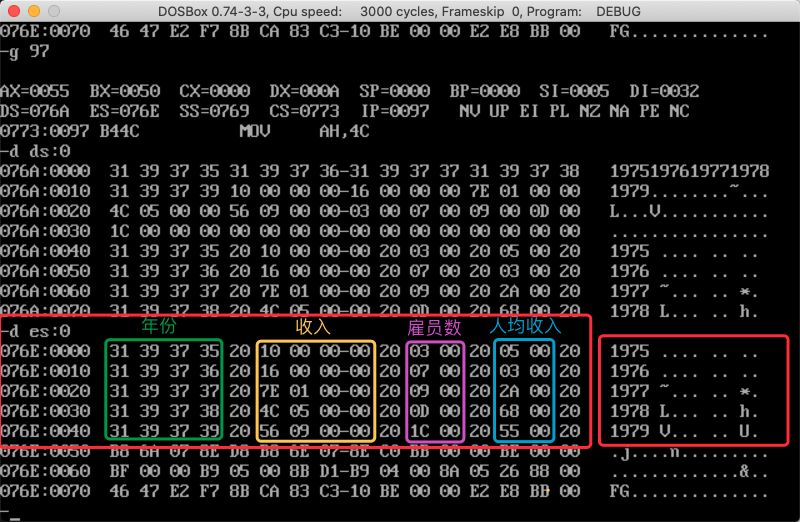
仔细对比ds内的数据,可以看到年份、收入和雇员数已经正确存入表中
- 计算人均收入
手动计算结果:
| 年份 | 收入 | 雇员数 | 人均收入(整数部分) | 人均收入(16进制) |
|---|---|---|---|---|
| 1975 | 16 | 3 | 5 | 05 |
| 1976 | 22 | 7 | 3 | 03 |
| 1977 | 382 | 9 | 42 | 2A |
| 1978 | 1356 | 13 | 104 | 68 |
| 1979 | 2390 | 28 | 85 | 55 |
对比运行结果中的数据,可以发现人均收入计算正确。
至此可以确认,所有数据都已完整、准确存入表中。
二、实验总结
-
重新复习了
mov指令,在编写的时候忘记mov不能用于两个内存数据移动,必须通过寄存器中转 -
在程序中定义的逻辑段内存地址是连续的,在内存中的排列顺序与逻辑段定义顺序一致
如果没有指定程序开始运行的位置,会从第一个逻辑段位置开始执行指令
-
系统按程序段定义顺序依次分配内存单元,程序段分配的内存空间按16B的倍数进行分配,如果不满16B则分配16B,如果超出16B则按
[数据长度 / 16] + 1来分配。([ ]为取整) -
end start除了通知编译器程序结束,也是指出程序的入口地址 -
编写多重循环时,只有
cx可以用于控制循环次数,因此在从外循环进入内循环之前,需要先将cx的值保存到其他寄存器,或是压入栈中,内循环结束退出到外循环时再将cx的值恢复回来 -
8086的显存在存放在显示内容时,以一个字为单位,低字节为打印的字符内容,高字节为8位色彩代码
-
小写字母转大写可以使用
and 16进制字母ASCII码, 0DFh来实现,大写字母转小写可以使用or 16进制字母ASCII码, 20h来实现。 -
最后一个表格实验任务实在是非常繁琐,调试了很久,中间有些错误会导致无限循环,最后调试了半天才得出了正确结果。思路不难,难的是把思路转换成汇编代码。还得多写写,不太熟练,踩了不少坑。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号