第一次个人编程作业
一、PSP表格
(2.1)在开始实现程序之前,在附录提供PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。(3')(2.2)在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块的开发上实际花费的时间。(3') |
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 10 | 30 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 360 |
| · Design Spec | · 生成设计文档 | 15 | 15 |
| · Design Review | · 设计复审 | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 150 | 180 |
| · Coding | · 具体编码 | 300 | 380 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 90 | 120 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 60 | 90 |
| · Size Measurement | · 计算工作量 | 15 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 120 |
| · 合计 | 1000 | 1365 |
二、计算模块接口
(3.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(18') |
3.1.1算法说明及独到之处
在CSDN上搜索敏感词过滤的方法发现一种偏向算法的方式即DFA过滤算法。其思想是基于状态转移来检索敏感词,只需对文本进行一次扫描即可对所有敏感词进行检测。对基于状态转移建立敏感词树的描述大致如下:现以敏感词“你好”、“你好吗”、“软工课”、“软工实践”为例,建立一个敏感词树,如下图所示。
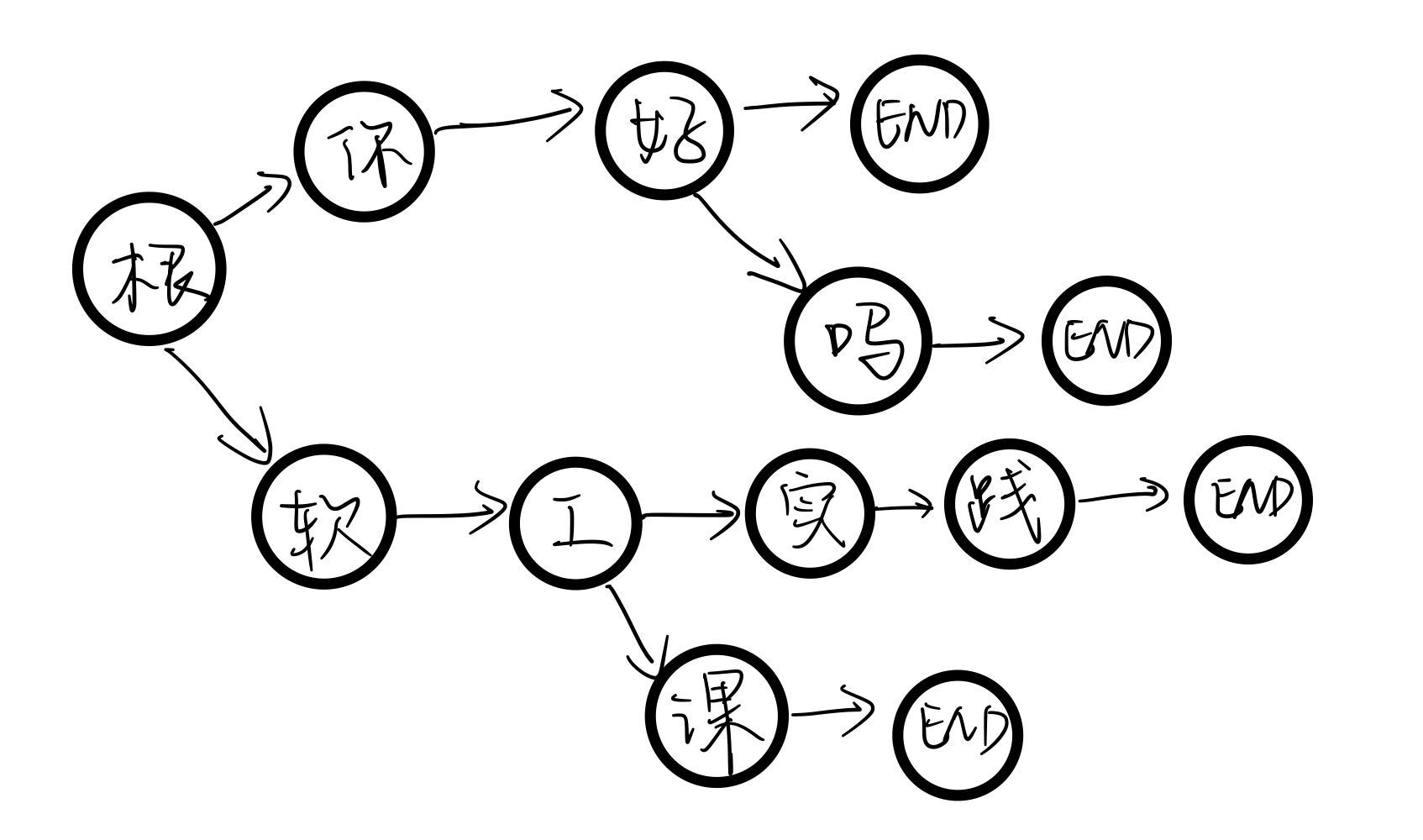
- 状态转移是根据当前状态以及“事件”来决定下一个状态的。一字一字检测时,若检测到的字出现在敏感词树中就命中,再判断下一个字在不在树中,若持续命中则持续向下跟踪,直到最后完全命中,结尾以一个结束符为键来定义。也就说是,完全命中了敏感词,就可以进行记录。由于题目的需求比较丰富,如以敏感词“你好”为例,包括:
-
在“你好”中间插入特殊符号,如字母、数字。这种类型可以定义一个符号集合,包括插入到敏感词间的各种特殊符号,用python写可以直接判断字符是否为字符集合里的特殊字符。
-
谐音替换,如“泥好”;拼音替换“nihao”;拼音首字母代替nh、nhao、nih等;简体与繁体混合;这些与拼音挂钩的类型可以用统一的方式来解决。通过网络资料搜索得知python有一库叫pypinyin,能够实现文字转拼音的操作,因此为解决此类敏感词的识别,敏感词树就需要用拼音字母来建立。而对于输出的正确敏感词,我在代码中建立了一个字典Dictionary[],以敏感词树持续命中到尾的内容(即拼音)为索引在字典中查出对应的敏感词的正确写法。
-
拆分偏旁部首“亻尔女子”。这个部分由于时间和能力都比较有限,暂时还没有解决方法。
-
3.1.2算法的流程大致如下:
-
按行读取敏感词文件,对于一个敏感词,将它的每个字转化为不带声调的拼音,建立该敏感词的[单个字完整拼音,单个字拼音首字母]的嵌套列表,调用函数将其进行排列组合。(例如:敏感词为你好,则形成[[ni,n],[hao,h]]的嵌套列表,经排列组合得到nihao、nih、nhao、nh四种组合,将这四种组合建立敏感词到字典的对应关系,并将这些组合加入到敏感词树上)
-
打开org.txt,按行读取文本,过滤此行敏感词。过滤过程如下:
-
设置一个begin为开始读的位置,初值为0。切出从begin开始的内容,以字为单位个个识别。
-
先将字转为无声调的拼音s,并转化为小写(部分字符为大写英文字母),令p1=begin,判断s[0]是否为特殊字符,此处需要另一个判断条件。由于特殊字符出现于敏感词前面则不在识别的范围内,因此设置标志变量sign1判断是否已经识别出了敏感词的头,若有则跳过该字符并将计步器counter自增1。
-
若s[0]不是特殊字符,则到敏感词树上寻找,找到则持续向下跟踪到尾搜索完毕(此时要把标志sign1复位便于后续再次搜索到新的敏感词头),将begin累加上计步器的值,begin新位置作为p2的值,敏感词数+1,并在字典找到敏感词的正确写法,将输出信息(识别到的敏感词切片为[p1,p2+1])一并添加到列表answer中。若内容不在敏感词树上,利用标志sign2来结束,计步器+1,begin随字的识别向后移动。该单行的过滤返回本行识别到的敏感词数量。
-
-
循环累加每行的敏感词数。设置一个标志sign=0,一旦出现空行sign+1,出现非空行复位,当sign>3时说明文本识别完毕,此时break跳出循环。将敏感词数转化为字符串添加到answer列表。
-
打开ans.txt,先写入total,再从头开始输出敏感词的识别结果。
3.1.3算法用到的类
该算法只定义一个类为DFA,封装了对敏感词的读取、建树(添加)、查找、过滤功能,并实现完整拼音和拼音首字母的排列组合。
3.1.4几个函数及其关系
-
类中封装了以下函数:
-
初始化函数init(self)。
-
敏感词读取函数ReadSensitiveWords(self,words_path)。words_path为敏感词文件路径。该函数按行读取敏感词文件,实现转拼音并形成[单个字完整拼音,单个字拼音首字母]的嵌套列表table再排列组合。
-
排列组合函数Combine(self,table,senword,word_len,count,charString)。table:嵌套列表,senword:敏感词,word_len:敏感词长度,count:已组合到第几个字,charString:组合结果。该函数利用递归实现排列组合,递归出口为count达到该敏感词的长度word_len,建立索引与字典的对应关系。
-
敏感词添加函数AddSensitiveWords(self,charString)。命中向下跟踪,未命中则添加新节点。
-
敏感词过滤函数FilterSensitiveWords(self,linecount,singleLine)。linecount:行数,singleLine:读取的单行内容。对单行敏感词进行过滤,返回单行的敏感词数量。
-
-
关系:敏感词读取函数ReadSensitiveWords需要依赖排列组合函数Combine,敏感词过滤函数FilterSensitiveWords需要使用敏感词添加函数AddSensitiveWords建立起来的敏感词树,也需要Combine函数建立的索引与字典的对应关系。DFA类以过滤函数为主,其他函数为辅实现敏感词过滤。
3.1.5关键函数流程图及程序输出结果、可视化表示
敏感词过滤函数FilterSensitiveWords流程图如下:

程序输出结果和群内文本对比:
由于图中存在敏感词,可能会被管理员删除博客,因此在图上打了码。
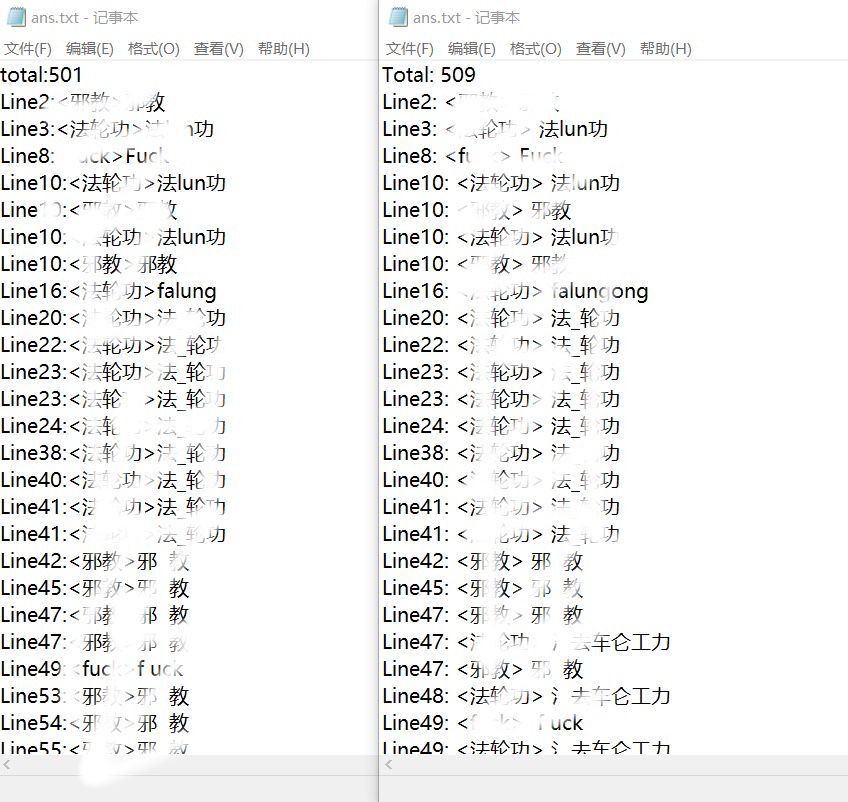
结果统计:

(3.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。(12') |
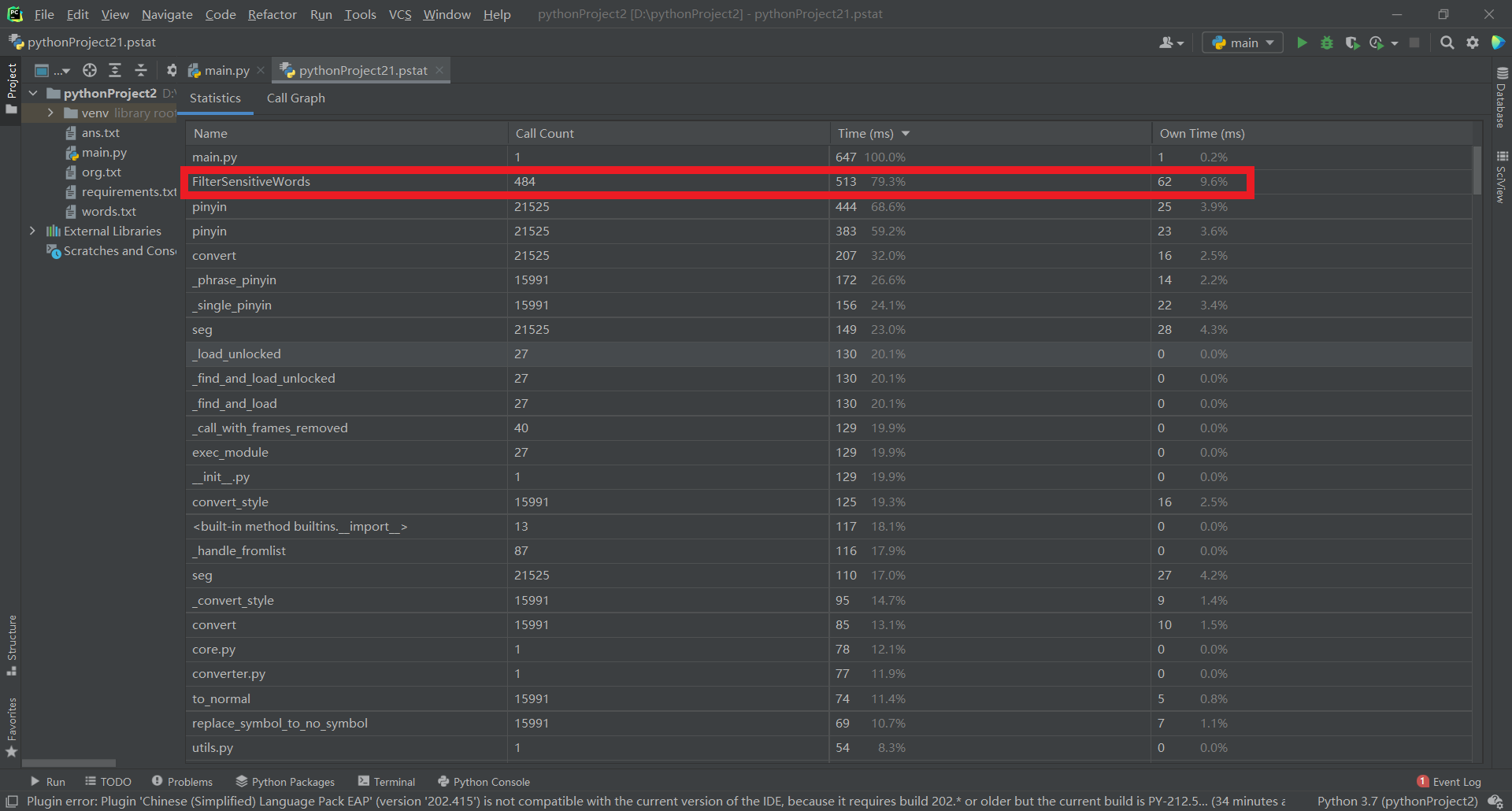
由图可知,程序中消耗最大的函数为敏感词过滤函数FilterSensitiveWords。该函数细节如下:
#过滤敏感词
def FilterSensitiveWords(self,linecount,singleLine,answer):
sen_count = 0
begin = 0
# 从begin的位置开始检测该行
while begin < len(singleLine):
# s1用于存放寻找敏感词的索引
s1 = ""
counter = 0
sign1, sign2 = 0, 0
# 切片获取begin开始的内容
content = singleLine[begin:]
sen_tree = self.senwords_tree
# 对于从begin开始到本行末尾进行循环,i是一个字
for i in content:
# s存单个字的拼音
s = ''
for j,pin in enumerate(pypinyin.pinyin(i,style=pypinyin.NORMAL)):
s += ''.join(pin)
s = s.lower()
# 若已找到了敏感词的头且s[0]内容为特殊符号,则计步器+1,跳过该字符
p1 = begin
if s[0] in SignSet and sign1 == 1 :
counter += 1
continue
for j in s:
# 能在树上找到
if j in sen_tree:
# 将标志sign1置为1(用于后续处理遇到敏感词中间出现符号的情况)
s1 += "".join(j)
sign1 = 1
# 此敏感词搜寻到尾了
if self.delimit in sen_tree[j]:
# 此敏感词搜索完毕,标志复位
sign1 = 0
# begin累加上计步器,开始寻找下一个敏感词
begin += counter
# 将begin的新位置赋值给p2,p1到p2即原文中敏感词的内容
p2 = begin
# 敏感词计数+1
sen_count += 1
# 以s1为索引在字典中搜索出敏感词的正确写法
correct = Dictionary[s1]
# 将该敏感词对应的输出存到列表answer中
answer.append("Line" + str(linecount) + ":<" + correct + ">" + singleLine[p1:p2+1])
sign2 = 1
# 该敏感词搜索还未到尾,则向下跟踪
else:
sen_tree = sen_tree[j]
# 不能在树上找到
else:
sign2 = 1
break
if sign2 == 1:
break
counter += 1
begin += 1
return sen_count,answer
-
需要改进:程序尚未拥有识别拆分偏旁的敏感词的功能。
-
改进思路:实现拆分偏旁,大致思路应该是用一个映射表来表达字和拆分后的字的关系,利用该映射表来识别拆分偏旁的敏感词。但由于时间有限,所以改进思路尚未实践。
(3.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。(12') |
-
单元测试一:
-
测试函数FilterSensitiveWords:测试繁体字、完整拼音、拼音首字母等组合的敏感词。
-
构造测试数据思路:该函数用于过滤敏感词,因此首先到网络上搜索一个短小的文本,在文本中选择几个词作为敏感词,对文本中出现的敏感词进行各种形式的变形,利用assertEqual函数验证敏感词过滤结果。
-
测试代码如下:
import main
import unittest
class MyTestCase(unittest.TestCase):
def test_FilterSensitiveWords(self):
#构造数据
path = "words1.txt"
org = ["小@@白123*猪─连搬了五次家,可如今天还得搬。\n",
"xiaobai猪喜欢搬家吗?不是。是邻居不好?也不是。那究竟是什么原因呢?只怪xb>Z睡觉大弧噜,\n",
" 吵得邻居不安宁。小白珠觉得实在不好意思,才决定再搬一次家。\n",
"半路上,xbaiz看见大象,决定请教大象。大象说:“搬家不是长久之际。\n",
"你的鼻孔太小,所以睡觉da呼l。我建议你去深圳科美医院把鼻孔做大点。\n",
"小白豬心领神会地走了。\n"]
ans = ["Line1:<小白猪>小@@白123*猪","Line2:<小白猪>xiaobai猪","Line2:<小白猪>xb>Z",
"Line2:<打呼噜>大弧噜","Line3:<小白猪>小白珠","Line4:<小白猪>xbaiz","Line5:<打呼噜>da呼l",
"Line6:<小白猪>小白豬"]
f = main.DFA()
f.ReadSensitiveWords(path)
answer = []
for i in range(1,7):
sen_count,answer = f.FilterSensitiveWords(i,org[i-1],answer)
self.assertEqual(ans,answer)
if __name__ == '__main__':
unittest.main()
覆盖率如图所示:

-
单元测试二:
- 构造测试数据思路:使用另一段文本统计敏感词数量,通过比对查看结果是否正确。
测试代码如下:
- 构造测试数据思路:使用另一段文本统计敏感词数量,通过比对查看结果是否正确。
import unittest
import main
class Mytest(unittest.TestCase):
def test_total(self):
# 构造数据
path = "words2.txt"
org = ["小兔子不知道chunfeng的色彩,它跑去问别人。\n",
"它问小猴子,小猴子说:“春 #$风吹到桃花上,桃花变成粉色了,春?f是粉色的。”\n",
"它又去问小草,小草说:“chunf吹到我的身上,我变绿了,c f?是绿色的。”\n",
"它又去问小河,小河说:“春風吹到我身上,我变成碧澄澄的,纯风是碧澄澄。”\n"]
f = main.DFA()
f.ReadSensitiveWords(path)
answer = []
total = 0
for i in range(1, 5):
sen_count, answer = f.FilterSensitiveWords(i, org[i - 1], answer)
total += sen_count
self.assertEqual(total,7)
if __name__ == '__main__':
unittest.main()
覆盖率如图所示:
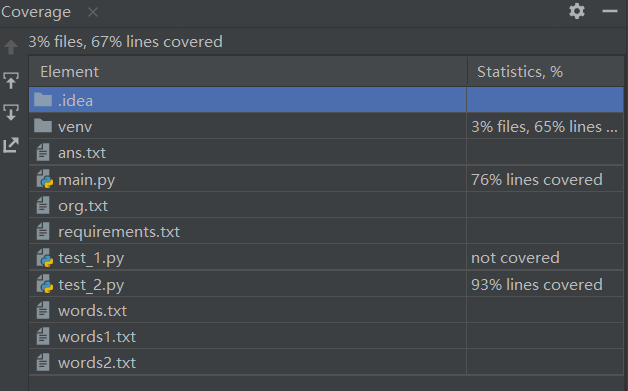
(3.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(6') |
- IO异常处理:
def Test_IOerror(self):
try:
wordsfile = open('words.txt', encoding='utf-8')
except IOError:
print("没有找到文件:'words.txt'")
else:
print("文本读取成功!")
wordsfile.close()
- 参数异常处理:
def test_canshu(self):
if len(sys.argv)!=3:
print("参数发生错误!")
else:
return
三、心得
(4.1)在完成本次作业过程的心得体会(3') |
噢对了debug真的挺烦的,我不明白为什么写了两次的一样的一段代码输出的结果是不一样的,也挺疑惑为什么自己写代码总是这里少个逗号,那里多个双引号,哪里又把英文的双引号写成中文的也没发现。以前只是听说软工实践很可怕,我现在知道了,确实很可怕。我又重新体验了一把不会写代码气哭,看着什么都不会不知从何开始的迷茫感,软工实践坚定了我以后不当程序员的想法,以后一定要去考公呜呜呜呜呜呜呜再也不想天天和代码作伴,坐在电脑前膝盖好酸、眼睛好痛,我好想逃,但是评测组和柯老板会制裁我的。对于我这样在大一大二能不开电脑就不开电脑能不打代码就不打代码的学生,软工实践简直就是在开发潜力,还有,我以为好不容易写完代码写个博客应该不会花多少时间吧,没想到啊博客也是真正的大头。怎么说呢,一开始看似不可能完成的任务最后竟然也尽力做到这样了,那确实是没想到,感觉学习了挺多东西的(虽然很痛苦),但是还是挺有收获的,希望柯老板和评测组多多关爱一下我这个小菜鸡,多给我一点点分。

