精通MySQL 8 知识点归纳
数据库操作
操作数据库
- 创建数据库:这是划分一块空间用力来存储相应数据,这是进行表操作的基础,也是数据库管理的基础
SHOW DATABASES:查看当前所有的数据库
CREATE DATABASE '数据库名字':建立一个数据库
USE '数据库名字':表示进入这个数据库
DROP DATABASE '表名':删除指定数据库
存储引擎
show engines:查看数据库的引擎总类(Mysql:9种)

- 我们了解其中的两种即可
InnoDB:支持事务、适合高并发(行锁)、日志(用于恢复和记录);
MyISAM:占用空间小、速度快、不支持事务的并发性和完整性; - 如何选择:
InnoDB存储引擎支持事务处理,支持外键,同时支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高,要求实现并发控制,那么选择InnoDB存储引擎会有很大的优势。如果需要频繁地进行更新、删除操作的数据库,也可以选择InnoDB存储引擎。因为该类存储引擎可以实现事务的提交(Commit)和回滚(Rollback)。
MyISAM存储引擎的出入数据快,空间和内存使用比较低。如果表主要是用于插入新记录和读出记录,那么选择MyISAM存储引擎能实现处理的高效率。如果应用的完整性、并发性要求很低,也可以选择MyISAM存储引擎。
表操作
表的设计理念
表中能操作的对象包括:列、索引、触发器
- 列:就是指定的字段名;
- 索引:通过指定的数据库表的列建立起来的顺序:就像字典目录,查找时候如果不使用目录就要一个一个找,用了目录就能定位。
- 触发器:在删除,插入,更新事务执行时候自动触发一组命令;
表设计的标准化- 表设计的标准化
- 第一范式:确保每个列的原子性(一个列只能描述一个东西);
- 第二范式:确保每个列都和主键依赖不可分割;
- 第三范式:确保每个列都和主键直接相关而不是间接相关;
- 满足第三必须先满足第二,满足第二必须先满足第一;
表和表的关系
- 一对一
- 一对多
- 多对多
MySQL数据类型
- 整形:根据自己需要选择即可
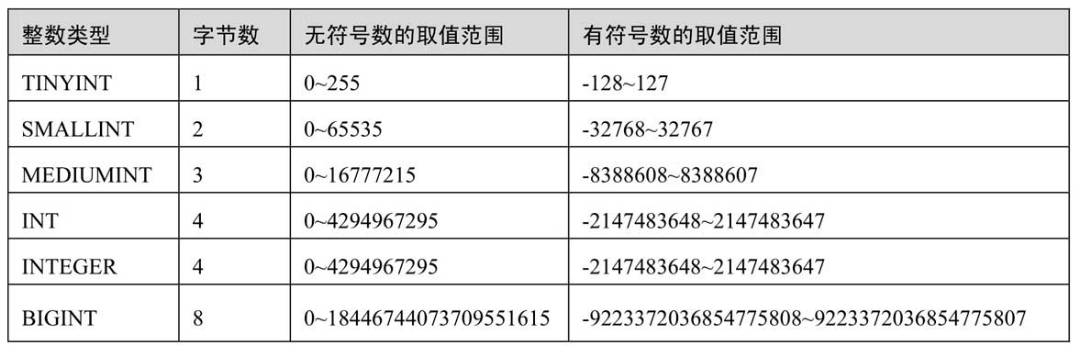
- 浮点
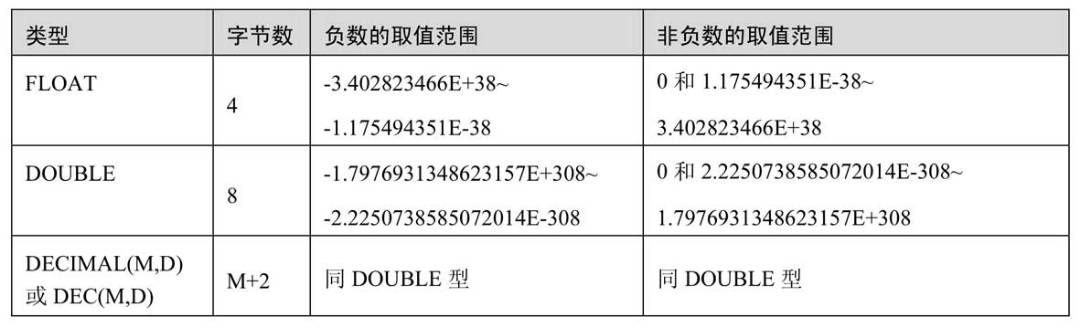
- 时间
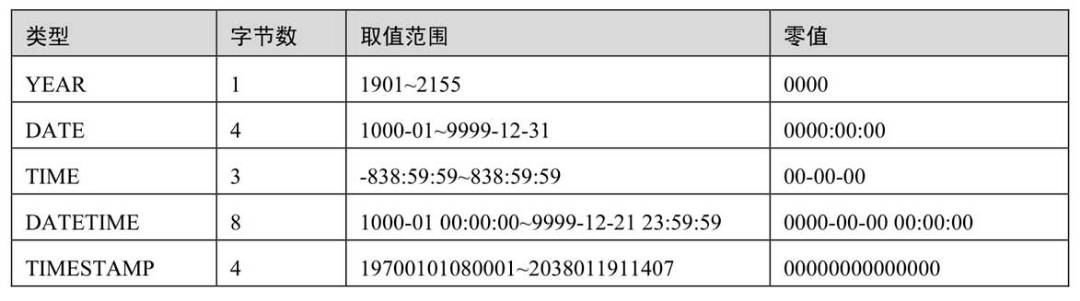
- 字符:char是多少就是多少、varchar会根据传入的长度+1来存储

表操作的语法
- 创建表
CREATE TABLE '表名' ( 字段名 类型 约束条件,(使用,分隔、可以输入多条) ) - 查询表结构
desc 表名字 - 查看创建的语句、
show create table 表名字
- 删除表
drop table '表名字'
- 修改表
alert 关键字 - 修改表名
alter table '表名字' rename '新名字' - 添加表字段
- 添加在最后:
alter table '表名' add '新字段名字' '新字段类型' - 添加在最前:
alter table '表名' add '新字段名字' '新字段类型' first - 在指定字段后面添加:
alter table '表名' add '新字段名字' '新字段类型' after '旧字段名字'
- 修改字段
alter table '表名' change '字段名' '新字段名' '新的字段类型'
表的约束条件
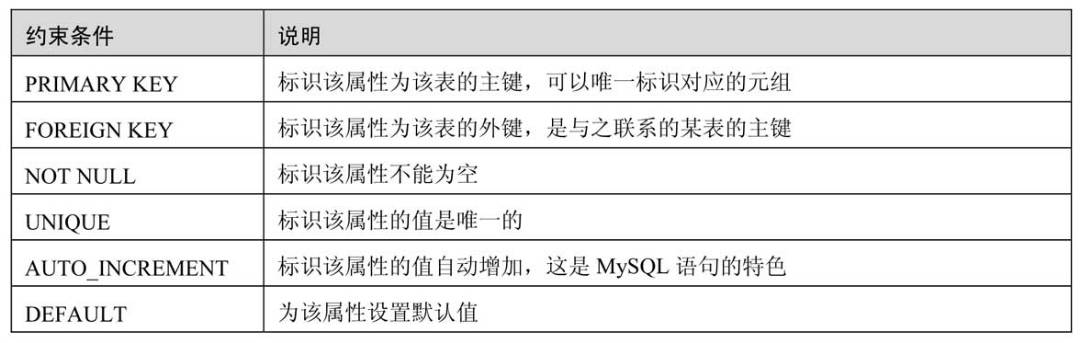
配合:CREATE TABLE '表名' ( 字段名 类型 约束条件(not null 、default '默认值'、unique、 primary key 、auto_increment) constraint '约束名' foreign key (本表的字段名) references '关联表'(关联字段) )
另类写法
- 设置主键:constraint '约束名' primary key (字段名)
- 设置外键:constraint '约束名' foreign key (本表的字段名) references '关联表'(关联字段)
数据操作
- 插入数据
insert into '表名'() values() - 更新数据
update '表名' set '字段名'=? where ? - 删除数据
delete from '表名' where ?
数据查询
-
简单查询:
select 字段名 from '表名' where 条件 group by 【having 条件二】 order by 【asc/desc】 -
Distinct去重:
select distinct 字段名 from 表名 -
In查询:判断是否出现在后面的括号内
select * from '表名' where 字段 in(。。。) -
Between And 查询(只真对数字有效)
select * from '表名' where 字段 between 最小范围 and 最大范围 -
Like 模糊查询(必须使用''包起来)(通配符:_ 和 % 区别就是 一个 和 多个 )
select * from '表名' where 字段 like '%王' -
group by 分组查询:将根据字段分组并且随机去除组里的一条数据,具有不确定性
select * from '表名' group by '字段名
补充:分组查询单独出现并没有任何意义,需要配合函数来使用。
联合查寻
- 内连接(特点:当没有找到连接条件时候,会省略没有的)
- 自连接就是自己跟自己连接
select * from '表1' inno join '表2' on 条件
在关键字后面使用=来实现条件就是等值连接
在关键字后面使用(关系运算符号)就是不等连接
- 外连接
- 左连接:以左表为基本表 left (outer可以省略) join on
- 右连接:以左表为基本表 right(outer可以省略) join on
- 全外连接:左边右边都不能省略:并且去重
- 笛卡尔积连接:左边会跟右表的每一条进行交互cross (outer可以省略) join on

