

机器学习基石6-泛化理论
注:
文章中所有的图片均来自台湾大学林轩田《机器学习基石》课程。
笔记原作者:红色石头
微信公众号:AI有道
上一节课,主要探讨了\(M\)的数值大小对机器学习的影响。如果\(M\)很大,那么就不能保证机器学习有很好的泛化能力,所以问题转换为验证\(M\)有限,最好是按照多项式成长。然后通过引入了成长函数\(m_H(N)\)和dichotomy以及break point的概念,提出2D perceptrons的成长函数\(m_H(N)\)是多项式级别的猜想。这就是本节课将要深入探讨和证明的内容。
一、Restriction of Break Point
回顾一下上节课的内容,四种成长函数与break point的关系:

下面引入一个例子,如果\(k=2\),那么当\(N\)取不同值的时候,计算其成长函数\(m_H(N)\)是多少。很明显,当\(N=1\)时, \(m_H(N)=2\),;当\(N=2\)时,由break point为2可知,任意两点都不能被shattered(shatter的意思是对\(N\)个点,能够分解为\(2^N\)种dichotomies);最大值只能是3;当\(N=3\)时,简单绘图分析可得\(m_H(N)=4\),即最多只有4种dichotomies。
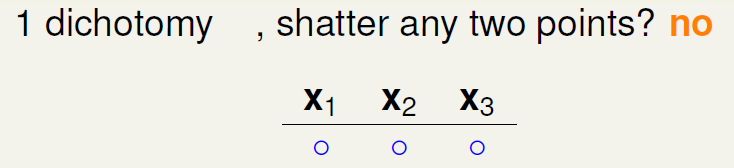
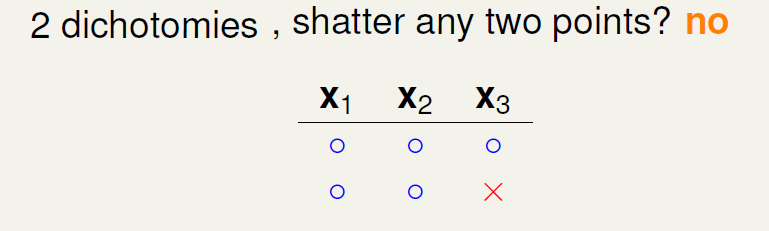

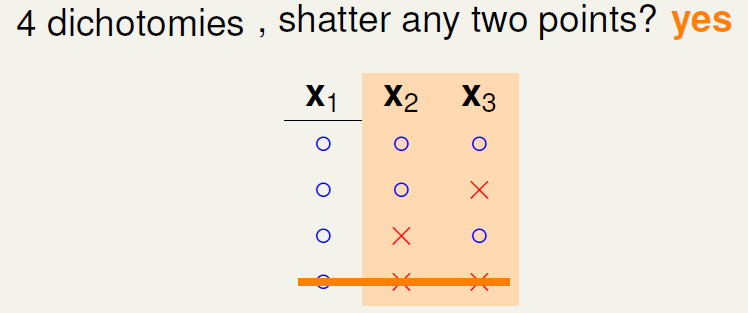

可以发现当\(N>k\)时,break point限制了\(m_H(N)\)值的大小

也就是说影响成长函数\(m_H(N)\)的因素主要有两个:
- 抽样数据集\(N\)
- break point \(k\)
那么,如果给定\(N\)和\(k\),能够证明\(m_H(N)\)的最大值的上界是多项式的,则根据霍夫丁不等式,就能用\(m_H(N)\)代替\(M\),得到机器学习是可行的。所以,证明\(m_H(N)\)的上界是Poly(N),是我们的目标

二、Bounding Function: Basic Cases
现在,引入一个新的函数:bounding function,\(B(N,k)\)。Bound Function指的是当break point为\(k\)的时候,成长函数\(m_H(N)\)可能的最大值。也就是说\(B(N,k)\)是\(m_H(N)\)的上界,对应\(m_H(N)\)最多有多少种dichotomy。那么,我们新的目标就是证明:$$B(N,k)\leq Poly(N)$$
这里值得一提的是,\(B(N,k)\)的引入不考虑是1D postive intrervals问题还是2Dperceptrons问题,而只关心成长函数的上界是多少,从而简化了问题的复杂度。
求解\(B(N,k)\)的过程十分巧妙:
- 当\(k=1\)时,\(B(N,1)\)恒为1
- 当\(N<k\)时,根据break point的定义,容易得到\(B(N,k)=2^N\)
- 当\(N=k\)时,此时\(N\)是第一次出现不能被shatter的值,所以最多只能有\(2^N-1\)个dichotomies,\(B(N,k)=2^N-1\)
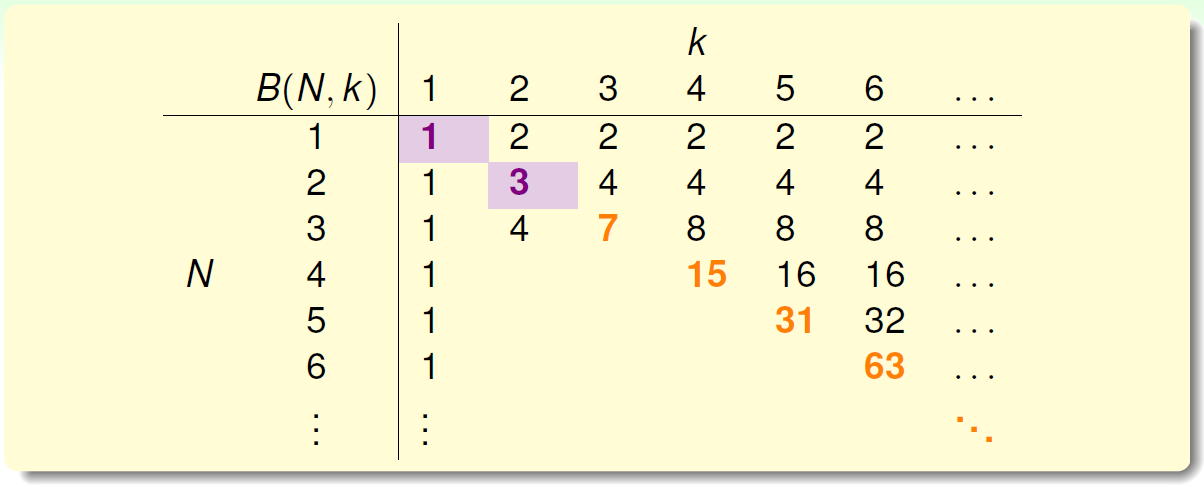
到此,bounding function的表格已经填了一半了,对于最常见的\(N>k\)的情况比较复杂,推导过程下一小节再详细介绍。
三、Bounding Function: Inductive Cases
\(N>k\)的情况较为复杂,下面给出推导过程:
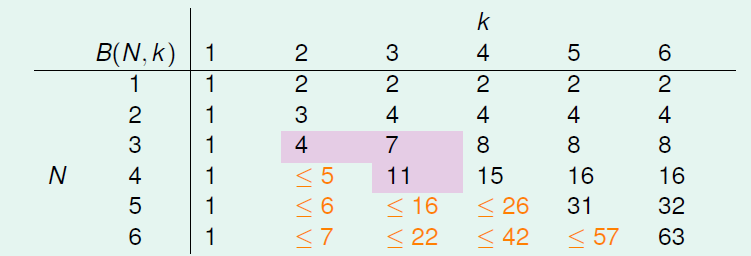
以\(B(4,3)\)为例,首先想着能否构建\(B(4,3)\)与\(B(3,x)\)之间的关系。首先,把\(B(4,3)\)所有情况写下来,共有11组。也就是说再加一种dichotomy,任意三点都能被shattered,11是极限。
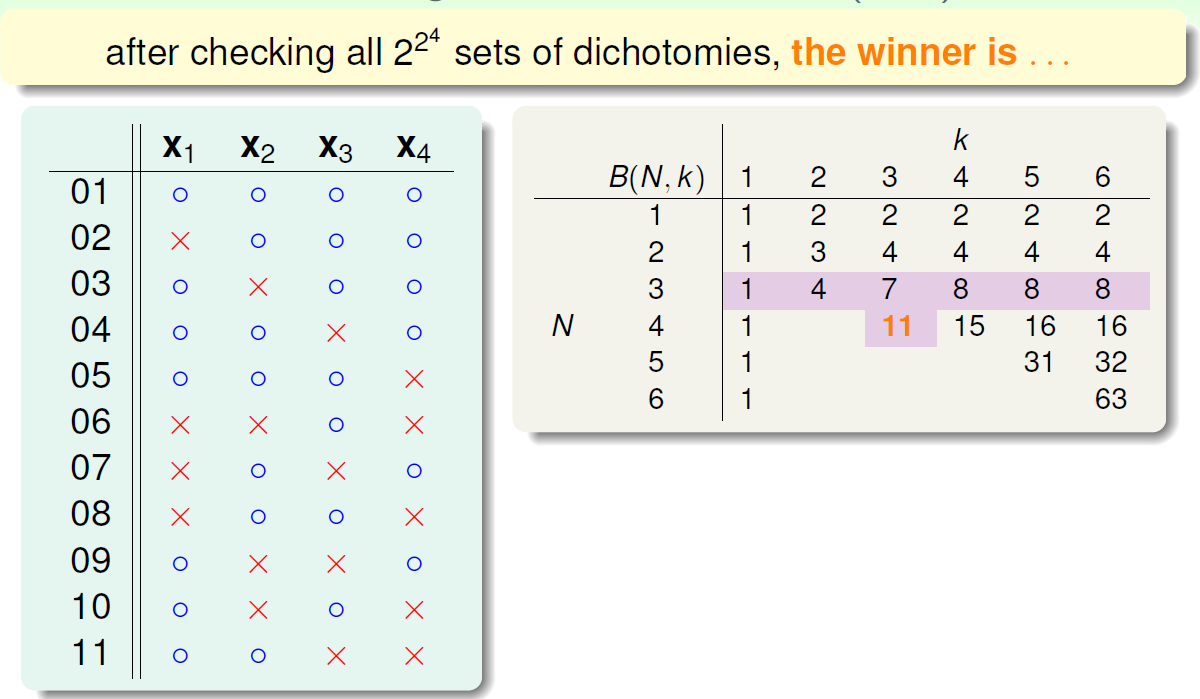
\(B(4,3)\)表示break point 为3,4个点,按二元分类,总共有\(N=2^4\)种,从这\(N=2^4\)种中选取排列组合,共\(C^0_N+C^1_N+...+C^N_N=2^{2^4}\)种选择。
对这11种dichotomy分组,分为两组,分别是orange和purple,orange的特点是,\(X_1\),\(X_2\)和\(X_3\)是一致的,\(X_4\)不同并成对,例如1和5,2和8。purple则是单一的,\(X_1\),\(X_2\),\(X_3\)都不同,例如6,7,9三组。
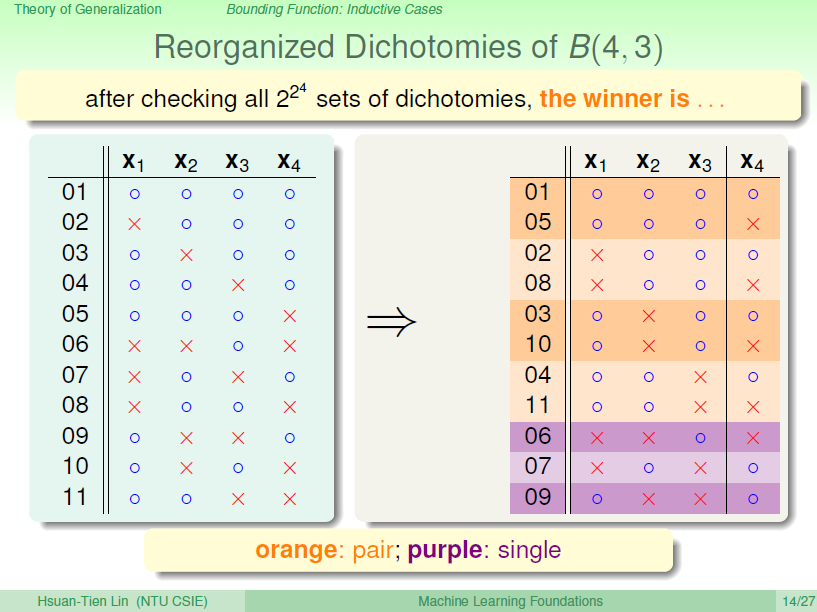
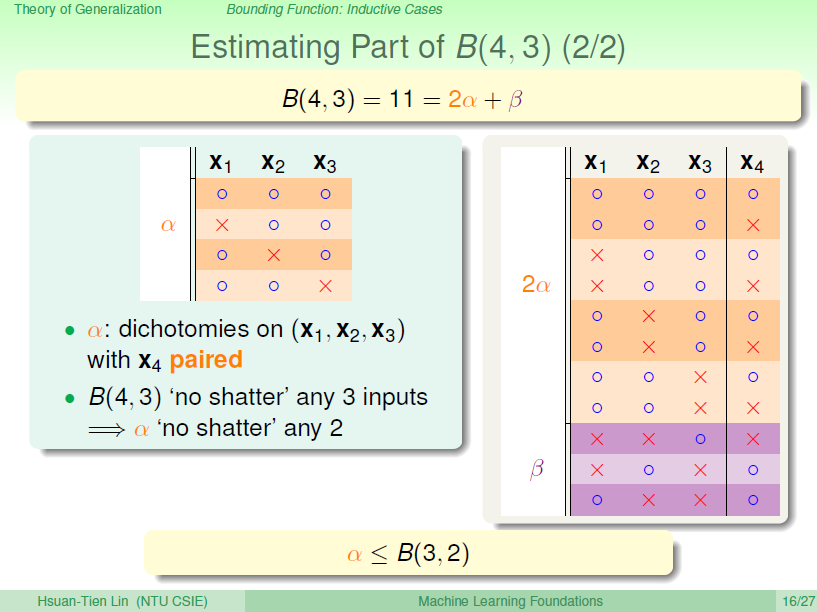
将Orange去掉\(X_4\)后去重得到4个不同的vector并成为\(\alpha\),相应的purple为\(\beta\)。那么\(B(4,3)=2\alpha+\beta\),这个是直接转化。紧接着,由定义,\(B(4,3)\)是不能允许任意三点shatter的,所以由\(\alpha\)和\(\beta\)构成的所有三点组合也不能shatter(alpha经过去重),即\(\alpha+\beta\leq B(3,3)\)。

另一方面,由于\(\alpha\)中\(X_4\)是成对存在的,且是不能被任意三点shatter的,则能推导出\(\alpha\)是不能被任意两点shatter的。这是因为,如果\(\alpha\)能被任意两点shatter,而\(X_4\)又是成对存在的,那么\(X_1\)、\(X_2\)、\(X_3\)、\(X_4\)组成的\(2\alpha\)必然能被三个点shatter。这就违背了条件的设定。这个地方的推导非常巧妙,也解释了为什么会这样分组。此处得到的结论是\(\alpha\leq B(3,2)\)
由此得出\(B(4,3)\)与\(B(3,x)\)的关系为
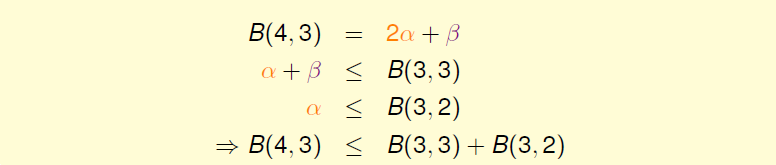
最后得出泛化的公式:

根据推导公式,下表给出\(B(N,k)\)的值
递推,推导出\(B(N,k)\)满足下列不等式
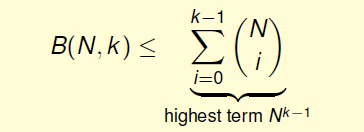
上述不等式的右边\(N\)的最高阶是\(k-1\),也就是说成长函数\(m_H(N)\)的上界\(B(N,k)\)的上界满足多项式分布\(poly(N)\)。
得到了\(m_H(N)\)的上界\(B(N,k)\)的上界满足多项式分布\(poly(N)\)后,回过头来看看之前介绍的几种类型它们的\(m_H(N)\)与break point的关系:
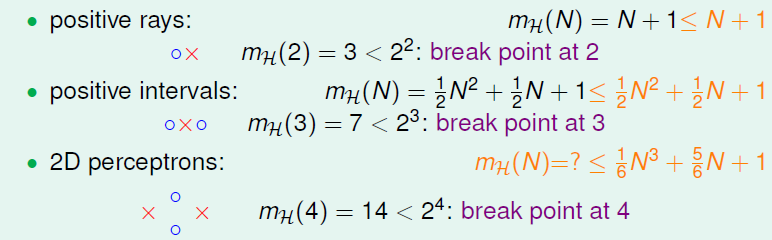
得到的结论是,对于2D perceptrons,break point为\(k=4\),\(m_H(N)\)的上界是\(N^{k-1}\)。推广一下,也就是说,如果能找到一个模型的break point,且是有限大的,那么就能推断出其成长函数\(m_H(N)\)有界。
四、A Pictorial Proof
我们已经知道了成长函数的上界是\(poly(N)\)的,下一步,如果能将\(m_H(N)\)代替\(M\),代入到Hoffding不等式中,就能得到\(E_{out} \approx E_{in}\)的结论:
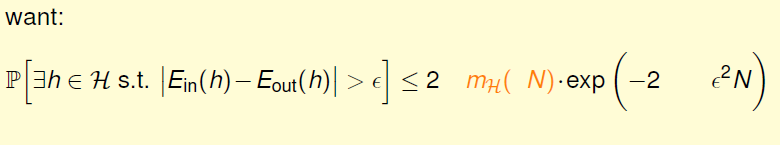
实际上并不是简单的替换就可以了,正确的表达式为:
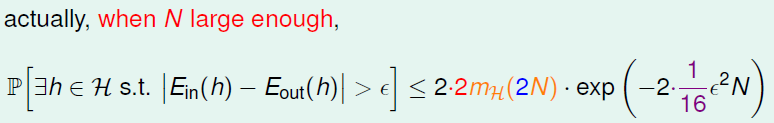
这部分的证明,有待进一步查找资料。
通过引入成长函数\(m_H\), 得到如下一个新的不等式,成为Vapnik-Chervonenkis(VC) bound:
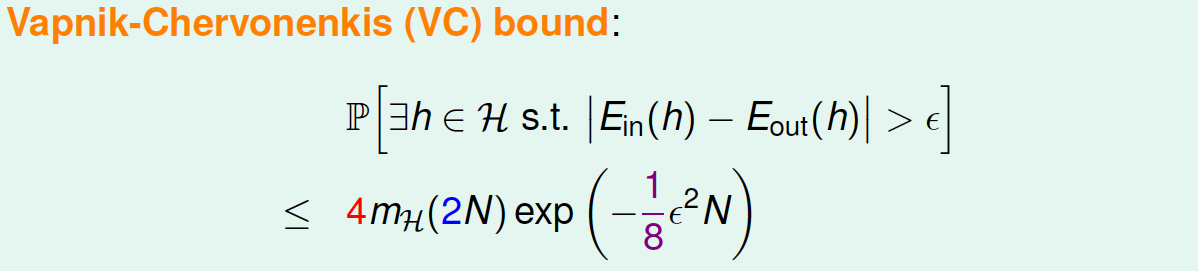
对于2D perceptrons,它的break point是4,那么成长函数\(m_H(N)=O(N^3)\)。所以,我们可以说2D perceptrons是可以进行机器学习的,只要找到hypothesis能让\(E_{in}\approx 0\),就能保证\(E_{in}\approx E_{out}\)。
五、总结
本节课我们主要介绍了只要存在break point,那么其成长函数\(m_H(N)\)就满足\(poly(N)\)。推导过程是先引入\(m_H(N)\)的上界\(B(N,k)\),\(B(N,k)\)的上界是\(N\)的\(k-1\)阶多项式,从而得到\(m_H(N)\)的上界就是\(N\)的\(k-1\)阶多项式。然后,我们通过简单的三步证明,将\(m_H(N)\)代入了Hoffding不等式中,推导出了VapnikChervonenkis(VC) bound,最终证明了只要break point存在,那么机器学习就是可行的。

