

dtb文件上篇博客中已经分析过了,接下来分析一些特殊情况,将dts文件编译成dtb文件之后再用fdtdump反编译出来,对比两个文件看看有什么差异。
用指令fdtdump test.dtb > dump.txt 将test.dtb文件反编译成test.txt文件,fdtdump指令可以加参数的,可以输入fdtdump –h查看支持的参数,如输入fdtdump -sd test.dtb > dump.txt的话生成的dump.txt文件中就会包含很多调试信息。
接下来通过一些案例,对比源文件和反编译后的文件,来了解一些特殊情况是怎么编译的:
注:反编译后的文件包含了文件头信息,为了方便查看,
案例一
原文件:
1 /dts-v1/; 2 / { 3 property = [01 02 03 04]; 4 };
反编译文件:
1 /dts-v1/; 2 / { 3 property = <0x01020304>; 4 };
分析:
原先的property = [01 02 03 04];变成了property = <0x01020304>;其实是一样的。
案例二
原文件:
1 /dts-v1/; 2 / { 3 property = <&label>; 4 5 label: node { 6 7 }; 8 };
反编译文件(偷个懒,在之后的反编译文件中去掉了/des-v1/这一行):
1 / { 2 property = <0x00000001>; 3 node { 4 linux,phandle = <0x00000001>; 5 phandle = <0x00000001>; 6 }; 7 };
分析:
如果属性值中某一项用尖括号包含了,其值引用了某个节点,那么其值变成了一个32位数,被引用的节点会多出linux,phandle和phandle两个属性,这两个属性的值是两个相同的32位数,这个数和引用它的数是相等的。
案例三
原文件:

1 /dts-v1/; 2 / { 3 4 property = <&label1>; 5 property2 = <&label2>; 6 property3 = <&label1>; 7 8 label1: node { 9 10 }; 11 12 label2: node2 { 13 14 }; 15 };
反编译文件:
1 / { 2 property = <0x00000001>; 3 property2 = <0x00000002>; 4 property3 = <0x00000001>; 5 node { 6 linux,phandle = <0x00000001>; 7 phandle = <0x00000001>; 8 }; 9 node2 { 10 linux,phandle = <0x00000002>; 11 phandle = <0x00000002>; 12 }; 13 };
分析:
不同的被引用的节点phandle值会从1开始递增,引用相同的节点其phandle值相等。
案例四
原文件:
1 /dts-v1/; 2 / { 3 4 property = <1>; 5 property2 = <&label>; 6 7 label: node { 8 9 }; 10 };
反编译文件:
1 / { 2 property = <0x00000001>; 3 property2 = <0x00000001>; 4 node { 5 linux,phandle = <0x00000001>; 6 phandle = <0x00000001>; 7 }; 8 };
分析:
这个案例中,property的值就设定为1,property2的值引用了node节点,我以为生成的phandle值会避开1这个值,结果竟然还是1,那这样property和property2两个属性不就没法区分了吗,将原文件改为如下:
1 /dts-v1/; 2 / { 3 4 property = <&label>; 5 property2 = <&label>; 6 7 label: node { 8 9 }; 10 };
反编译出来的文件与 property = <1>;的文件一样,那这样就有问题了呀,内核怎么区分这个属性值是一个引用还是这就是它的值呢?
案例五
原文件:
1 /dts-v1/; 2 / { 3 4 property = &grandson; 5 label: node { 6 child-node { 7 grandson: grandson-node { 8 9 }; 10 }; 11 }; 12 };
反编译文件:
1 / { 2 property = "/node/child-node/grandson-node"; 3 node { 4 child-node { 5 grandson-node { 6 }; 7 }; 8 }; 9 };
分析:
如果某个属性的值直接就引用某个节点(不带尖括号),那么相当于传入的属性值是一个字符串,这个字符串表示的是被引用的节点的路径
案例六
原文件:
1 /dts-v1/; 2 / { 3 4 property = <&label 1 2>; 5 label: node { 6 7 }; 8 };
反编译文件:
1 / { 2 property = <0x00000001 0x6e6f6465 0x00000009>; 3 node { 4 linux,phandle = <0x00000001>; 5 phandle = <0x00000001>; 6 }; 7 };
分析:
这个结果可真是把我吓坏了,我赶紧用winhex打开dtb文件,一看:
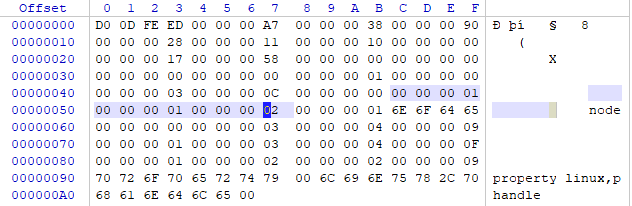
见选中处,发现并没有什么问题,这么说那就是fdtdump工具有问题了,又经过几次测试发现当属性的值是一个32位数组(尖括号里面不止一个数)的时候,fdtfump工具就会出问题。
案例七
原文件:
1 /dts-v1/; 2 / { 3 4 property = <1>; 5 property2 = <2>; 6 label: node { 7 8 }; 9 }; 10 11 / { 12 property2 = "hello"; 13 property3 = <3>; 14 };
反编译文件:
1 / { 2 property = <0x00000001>; 3 property2 = "hello"; 4 property3 = <0x00000003>; 5 node { 6 }; 7 };
分析:
后面写的根节点可以认为是对前面根节点的解释或修改,不同的属性会直接加进去,相同的属性会被重写。同样的也可以对其他节点进行重写,但是一定要在最外层路径上用引用的方式重写,下面列出一些错误的重写方式:
1. 同一节点下有两个相同的子节点
1 /dts-v1/; 2 / { 3 node { 4 5 }; 6 7 node { 8 9 }; 10 };
2. 引用没放在最外层
1 /dts-v1/; 2 / { 3 label:node { 4 5 }; 6 7 &label { 8 property = "hello"; 9 }; 10 };
下面这种写法才是合法的:
1 /dts-v1/; 2 / { 3 label:node { 4 5 }; 6 }; 7 8 &label { 9 property = "hello"; 10 };
反编译结果:
1 / { 2 node { 3 property = "hello"; 4 }; 5 };
案例八
原文件:
1 /dts-v1/; 2 / { 3 node@0 { 4 5 }; 6 };
二进制文件:

节点名带地址的形式编译器并没有将节点名和地址分开处理,而是将它们当成一个整体算作节点名(当这并不意味着节点名加地址没用)。
另外还发现一个现象,就是FDT_NOP这个标签从来都没有出现过。是不是说正常编译器编译的文件中不会带有这个标志。
到这里基本上设备树文件已经算是吃透了,唯一不解的地方就是案例四,接下来要进内核分析一下内核是怎么做的了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 【杂谈】分布式事务——高大上的无用知识?