「图论」树的进阶
拥有 \(n\) 个点和 \(n-1\) 条边的树有什么样的魔力?
魔力强大到可以让 OI 界的无数英雄折腰!!
众所周知,树的进阶就是一场酣畅淋漓的赤石。。。
0x01 虚树
虚树的设计背景的这样的:我们有 \(q\) 次询问,每次询问给定 \(m\) 个特殊点,然后对这些特殊点的整体进行询问,比如询问这些特殊点两两之间的距离之和。
就拿特殊点距离之和当例子,我们发现如果每次询问都在整棵树上进行 DP 是非常低效的,时间复杂度达到了 \(O(nq)\)。
但是我们发现,每次 DP 是肯定有一些点是没有必要进行计算的。于是虚树就出现了,它可以做到只包括那些对最终答案有影响的节点,由于 \(\sum m\) 肯定不会太大,因此虚树的节点个数也不会太多。
那什么才是对答案有影响的节点?
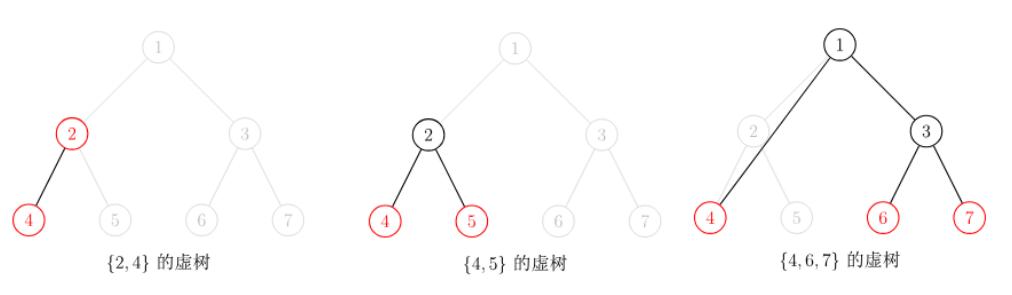
首先这些特殊点肯定算,因为它们的存在正是答案计算的关键。而特殊点之间的 LCA 也是有用的,因为它们可以将特殊点连接起来,形成一个连通块。
另外是一个必须的规定:虚树中祖先后代的关系不能改变。
下面是 oiwiki 上面的图,应该可以比较清晰地解释虚树的含义。
how 构建?
我采用的是二次排序法。我们可以将所有特殊点按照 DFS 序进行排序形成 \(a\) 序列。排序过后,我们将 \(a\) 中相邻两个元素的 LCA 求出来并放到 \(b\) 数组里面。最后把 \(b\) 中重复的元素剔除掉,这样我们就能得到虚树中的节点为 \(a∪b\),不难发现虚树的节点数是特殊点数的 \(2\) 倍左右。
至于建边的过程,我们处理出 \(a∪ b\) 的集合 \(c\),并再次按照 DFS 序排序。然后遍历 \(c\) 数组,每次枚举到相邻元素 \(x,y\) 时,我们求出 \(\text{lca}(x,y)=z\),再连一条 \(y,z\) 之间的边。像这样连接 \(|c|-1\) 次,就能得到我们最终的虚树。
证明就去 oiwiki 看吧,我已经迫不及待讲题了!!
[BalticOI 2017] Railway
\(\text{tag:}\) 虚树 + 差分
这个是我认为最适合给初学者做的题。
我们概况一下题意:有一棵树和 \(m\) 次操作,每次操作给出一些特殊点,我们要找出这些特殊点两两之间的路径的边集,并给集合中所有的边加上 \(1\) 个代价,最后问树上有多少条边满足它最终的代价 \(≥k\),\(k\) 为定值。
我们可以建出每次操作中特殊点的虚树。对于虚树上每一条边,我们发现它代表了一条树上的路径。比如 \((x,y)\) 这条边就代表了原来树上的一条 \(x\) 到 \(y\) 的路径。由此我们可以推断,虚树上每一条边代表的路径的并就是我们要修改的范围。
由于最后的输出是离线的,我们可以使用路径差分去修改每一条路径。
[ABC359G] Sum of Tree Distance
\(\text{tag:}\) 虚树 or 根号分治
这个其实就是讲解时我们举的例子。
因为当 \(a_i≠a_j\) 时,\(f(i,j)=0\),所以我们就只用考虑 \(a_i=a_j\) 的情况。
我们将 \(a_i\) 相同的 \(i\) 提取到对应的 vector 里面,计算答案时就可以枚举一个值 \(x\),分别地计算 \(a_i=x\) 的节点之间的距离之和。我们对这些节点建立虚树,计算的时候,我们也可以不用 DP,直接考虑每条边被计算的次数就行。次数很好求,就是虚树拆掉这条边之后,在两个连通块里的特殊点个数的乘积。
只能说是靠知识点强上 G 题的水题。
不过这题也可以根号分治做,当 \(a_i=x\) 的节点个数 \(\leq \sqrt{n}\) 时就直接暴力,若 \(>\sqrt{n}\) 就直接在整个树上进行统计。时间复杂度 \(O(n\sqrt{n})\)。但是没有虚树的方法高效。
[ABC340G] Leaf Color
\(\text{tag:}\) 虚树 + DP
同样是 G 题,这道题可是要比上面那个有价值一点。
切入点是套路的,我们把 \(a_i=p\) 的所有点的虚树建立出来。
注意到 \(S\) 的导出子图是一棵树,而不是两棵树,所以我们只需要思考一个连通块。钦定 \(1\) 为树根,考虑 DP,设 \(dp_i\) 表示导出子图的根为 \(i\) 的满足条件的 \(S\) 数量。
结合虚树定义,我们知道虚树中有些点并不满足 \(a_i=p\)。由于题目中并未提及树根是哪个节点,上文的 \(1\) 节点树根也只是我们自己钦定的,因此若 \(a_i≠p\),那么它就必须连至少 \(2\) 条边。分类讨论一下:
- \(a_x=p\):则 \(x\) 可以连任意边数。如果 \(x\) 要跟儿子 \(y\) 连边,那么就会产生 \(dp_y\) 的代价。但是 \(x\) 也可以不与 \(y\) 连边,利用乘法原理,我们可以得到:
- \(a_x≠p\):则需要保证 \(x\) 至少连 \(2\) 条边。我们可以容斥,用任意连边的方案数减去连边 \(<2\) 的方案数。任意连边就是上一种情况的计算方法。如果 \(x\) 不连边,方案数为 \(1\),如果 \(x\) 恰好连一条边,方案数为 \(\sum dp_y\),因此得到:
把所有 DP 加起来即可。
[WC2018] 通道
\(\text{tag:}\) 边分治 + 虚树 + 树形DP
省流:给定三个树 \(T_1,T_2,T_3\),要求选出两个数 \(x,y\),使得 \(x,y\) 分别在 \(T_1,T_2,T_3\) 上的距离之和最大,输出这个最大值。
题目非常阴间,乍一看好像没什么思路。
我们考虑对 \(T_1\) 进行边分治。所谓边分治,就是选择一条边 \((x,y)\) 使得断开它之后形成的两个连通块的大小之差最小。然后再递归到剩余的连通块进行新一轮的边分治。
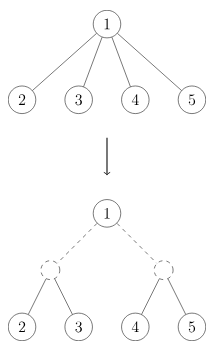
但是菊花图是边分治的克星,我们要想办法处理掉这个勾史。这里就要运用到多叉树转二叉树的知识。对于一个节点 \(x\),如果它的儿子个数 \(\leq 2\),就不管,直接递归下去。否则就新建两个节点作为 \(x\) 的左右儿子 \(l,r\),然后把原来的所有儿子平均地分成两堆,用 \(l,r\) 分别对两堆节点进行连边。
这个时候有人要问了:为什么不直接用淀粉质呢???
这是因为淀粉质对后面的做法不太有利,我们恰恰要利用边分治将一个连通块分成恰好两个连通块的性质。
我们可以把当前分治的连通块的所有点作为特殊点在 \(T_2\) 中建立一棵虚树,然后按照特殊点 \(x\) 是属于断边之后的第一个连通块还是第二个连通块来给 \(x\) 染上相应的颜色,一共只需要染 \(2\) 种颜色。这就是边分治的优势。
我们利用式子来思考一下,设 \(dep_1(x)\) 表示 \(x\) 在 \(T_1\) 中走到分治边的边权之和,\(dep_2(x),dep_3(x)\) 分别表示 \(x\) 在 \(T_2,T_3\) 中走到根节点的边权之和,\(w\) 表示分治边的边权,则有:
我们可以给每个点赋一个新的权值:\(v_x=dep_1(x)+dep_2(x)+dep_3(x)\),接着我们提出 \(w\) 这个已知的值,剩下的我们要求的就是:
鉴于我们已经搞出了 \(T_2\) 的虚树,我们可以考虑枚举 \(x,y\) 在 \(T_2\) 上的 lca,设它为 \(z\),那么我们就能知道 \(dep_2(\text{lca}_2(x,y))\) 了。则我们剩下求的就是:
并且我们要保证 \(x,y\) 在断掉分治边后属于不同的连通块,即 \(x,y\) 在 \(T_2\) 的虚树中染上了不同的颜色。
我们瞪眼法观察这个式子,会发现它和求两点距离的 \(dis_x+dis_y-2dis_{\text{lca}(x,y)}\) 非常像。再结合 \(v_x=dep_1(x)+dep_2(x)+dep_3(x)\) 这个东西,我们能够有一个想法,那就是在 \(T_3\) 中对每个 \(i\) 建一个新点 \(i'\),然后 \(i'\) 向 \(i\) 连一条权值为 \(dep_1(x)+dep_2(x)\) 的边。在这样的转换之后,我们发现上面那个式子就是 \(T_3\) 中 \(x'\) 到 \(y'\) 的距离。
其实这并不是启示你真的去建边,而是启发你从树的直径的角度去思考。有一个结论:在一棵树上,设点集 \(A\) 的所有点之间的最长路径的两端为 \(A_x,A_y\),点集 \(B\) 的所有点之间的最长路径的两端为 \(B_x,B_y\),则一端在 \(A\) 一端在 \(B\) 的最长路径必然是 \(A_x\to B_x,A_x\to B_y,A_y\to B_x,A_y\to B_y\) 这四种情况。
我们考虑 DP。让 \(dp_{i,0/1}\) 储存在 \(T_2\) 的 \(i\) 的子树中所有颜色为 \(0/1\) 的节点,放在 \(T_3\) 上的两两之间的最长路径的两端点。
我们用 \(dp_{son,0/1}\) 去更新 \(dp_{i,0/1}\)。每次更新有三种情况,要么 \(dp_{i,0/1}\) 保持自己的当前值,要么直接取 \(dp_{son,0/1}\),要么选一条横跨 \(i\) 和 \(son\) 的最长路径。前两者已知,第三种情况可以通过合并 \(dp_{i,0/1},dp_{son,0/1}\) 的形式完成,具体方法就是用上面的结论,暴力枚举两个集合要选哪一个端点,然后拼在一起。
对于我们枚举到的 \(T_2\) 中的 \(\text{lca}(x,y)=z\),我们依旧是合并子树,但是注意合并的东西是 \(dp_{i,0},dp_{son,1}\) 或者 \(dp_{i,1},dp_{son,0}\),上述的转移只是同一类型的相互合并。
最后取一个最大值就行了。
0x02 基环树
基环树不是树捏。。
但是如果我们在一棵树上选取一对尚未连边的 \((x,y)\),并且连一条 \(x,y\) 之间的边,那么它就变成了一棵基环树!
也就是说,基环树是一个由 \(n\) 个点 \(n\) 条边构成的一个连通图。
关于基环树,我们可以看作是一个简单环以及若干棵树组成的。利用这个特征,很多基环树问题就可以变为环问题和树上问题,方便我们思考。因此我们需要知道如何找到基环树中的这个简单环。
其实也蛮简单的,直接 DFS 找就行了。
不过还有一种较复杂的方法:我们跑出基环树的任意一个生成树,然后揪出剩余的那条没有算入生成树的边 \((x,y)\),接着我们找到生成树上 \(x\to y\) 的路径,再加上 \((x,y)\) 这条边,就是我们要找的环。这个方法不推荐使用,但是这样的生成树思想有时候可以简化一些问题(这是 yzh 启示我的)。
[IOI2008] Island
\(\text{tag:}\) (树形DP + 单调队列) or (生成树思想 + 树形DP)
题目就是让我们对于一个基环树森林,求出每一个基环树的直径之和。基环树的直径是指这个图中最长的一条路径的长度,路径要满足不重点不重边。
Solution 1
基环树的直径无外乎就是两种情况:不经过环上的边,或者要经过环上的边。
对于前者,我们 DFS 找到基环树中的环,然后断掉环上的所有边,这样就形成了森林,我们对形成的每个树找一遍直径,然后取一个最大值,就是第一种情况的答案。
重点在于后者的求法。我们发现如果断掉环上的所有边,那么之后形成的每个树中,恰好有一点是原来的环上节点,我们对于每个树,钦定这个环上节点 \(x\) 为它的根 \(rt\)。接着,我们求出这棵树上最长的一条路径,满足它的一端为 \(rt\),记 \(f_{rt}\) 表示这条路径的长度。
然后,我们就可以知道如何表示经过环上的边的路径长度了。我们找出环上的任意两个不同点 \(x,y\),记 \(dis_{x,y}\) 表示它们的环上的距离,则一条路径的长度可被表示为 \(f_x+f_y+dis_{x,y}\)。可以根据下图理解,枚举的 \(x=1,y=3\),\(dis_{x,y}=2+4=6\),图中 fixed 的点组成的就是一条表示的最长路径。
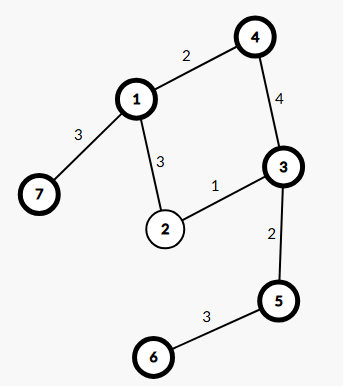
当然,我们也不能暴力枚举 \(x,y\)。结合 \(f_x+f_y+dis_{x,y}\) 这个式子,我们发现最难搞的就是 \(dis_{x,y}\),因为我们 \(x\to y\) 既可以是逆时针走,也可以是顺时针走,因此我们要注意 \(dis_{x,y}\) 到底是哪一种情况。
设环上一共有 \(cnt\) 个点,环的边权和为 \(S\),我们可以破环成链,变成 \(1\to\dots\to cnt\to 1\to \dots \to cnt\),并记录这条链上从第一个点走到第 \(i\) 个点的距离 \(sum_i\),由于链上的下标是有序的,所以走到第 \(i\) 个点就只有一种情况,即按照链的方向走。接着,我们只枚举 \(x\),在 \(x\) 前面的 \(cnt-1\) 个节点中选出一些点 \(y\) 满足 \(sum_x-sum_y≥S-(sum_x-sum_y)\),化简之后就是 \(2sum_x≥S+2sum_y\),因此可选择的 \(y\) 是在同一个区间范围中的。于是我们可以用单调队列去储存这些 \(y\),维护 \(f_y-sum_y\) 的最大值,最后加上 \(f_x+sum_x\) 就行了。
两种情况合起来取最大值就是这棵基环树的直径。再把森林中的每个基环树直径相加即可。
Solution 2
根据开始介绍的生成树思想,我们跑出基环树的一个生成树,那么剩余的那条边就是唯一的,我们设其为 \((u,v)\)。
那么基环树的直径就只有两种情况:不经过 \((u,v)\) 或者经过 \((u,v)\)。明显感觉到了要比 Solution 1 要简单
前者简直是个笑话,我们直接在这棵生成树上求直径就好了。
对于后者,我们把 \((u,v)\) 加进去,形成基环树,就和 Solution 1 有差不多的思路了。但是这样做的优势就在于,我们可以不使用单调队列,因为我们已经确定了环上经过的一条边 \((u,v)\) 是必须经过的,因此我们只需要在环上枚举一条不是 \((u,v)\) 的边 \((p,q)\) 作为分割线,不妨设删掉 \((u,v)\) 和 \((p,q)\) 后 \(p\) 与 \(u\) 相通,\(q\) 与 \(v\) 相通,我们只需要分别查询 \(u\to p\) 和 \(v\to q\) 路径上的 \(f_x+dis_{x,u}\) 最大值以及 \(f_x+dis_{x,v}\) 即可。由于 \(u,v\) 是永远不变的,我们直接维护前缀最大值就行了。
Galaxy Union
\(\text{tag:}\) 前缀和
省流:求基环树上每个点到其余点的最短距离之和。
实际上还是把基环树看成环套树,对于两个环上节点 \(x,y\),如果我们求到了 \(x\to y\) 的最短距离,那么以 \(y\) 为根的子树内的所有节点都可以据此推来。由于只有环上的最短距离需要我们分两种情况思考,因此本题的重点还是在环上。
考虑一个环上节点 \(x\) 到所有不在它的子树内的节点的距离之和 \(up_x\)。设 \(f_i\) 表示 \(i\) 到所有存在于 \(i\) 的子树内的节点的距离之和,\(siz_i\) 表示其子树大小,\(dis_{i,j}\) 表示环上两点之间的距离。则可以得到:
这个式子非常炸裂啊?
我们随机选定一个环上的起点,并记录一个边权的前缀和 \(sum_i\) 以及总边权和 \(S\)。则 \(dis_{x,y}\) 有两种情况:\(sum_y-sum_x\) 或者 \(S-(sum_y-sum_x)\),我们直接将这些 \(y\) 分到两个集合 \(A,B\) 里来表示是前者类型还是后者类型,每次统计完 \(x\) 并移动至新的 \(x\) 时,我们随时交换 \(A,B\) 的元素就行了。
但是怎么统计呢?拿 \(A\) 集合的 \(y\) 举例,我们拆式子:
因此我们要维护两坨前缀和去记录 \(sum_y\times siz_y+f_y\) 和 \(siz_y\)。
\(B\) 集合的 \(y\) 也是一个思路,暴力拆:
同样用前缀和维护。
但是这样有一个非常恶心的地方,就是我们不知道应该是 \(sum_x-sum_y\) 还是 \(sum_y-sum_x\)。我们可以破环成链,在 \([1,cnt]\) 区间内枚举 \(x\),选择的 \(y\) 的区间保持在 \(x\) 之后,这样我们就省去了 \(S\) 这个东西,全部转换为了 \(sum_y-sum_x\)。
这样我们就能求出环上节点的答案了。至于其余的节点,其实非常好求,直接换根 DP 求一个子树内相互之间的距离,然后从环上节点开始向下遍历,更新每个节点到子树外节点的答案即可。
本题磨练细节(悲
「TFOI R1」Ride the Wind and Waves
\(\text{tag:}\) 差分 + DP
夹带私货.jpg
闲话:
好吧这题是我出的,但是我发现当时的数据范围太弱智了。本来只需要求两种距离的祖先,可以 \(O(n)\) 搞定,但我硬是偷懒打的 \(O(nk)\),\(O(n\log k)\) 都不写,原因是为了方便造数据,\(k\) 开的小,\(O(nk)\) 能过,所以小偷了个懒。结果让弱智 \(O(nk)\) 做法过了QAQ。。这里我直接说 \(O(n)\) 做法吧,不然又不知道有多少人没有领略这道题该有的价值。。
选手感言:

如果数据范围更正,那么这题也算是我的得意之作了吧?
正文:
题意没有什么好解释的,挺详细了。
关于内向基环树找环,我们可以不用 DFS,直接 while 找循环节就行了。
又是套路地去看作环套树,我们枚举一个环上节点 \(x\),然后去计算 \(x\) 到其子树外的所有乘风破浪点的浪涛值。
这里其实和上面那道题的思路蛮像的。我们设 \(f_x\) 表示 \(x\) 到其子树内的乘风破浪点的距离之和,然后列出式子:
由于基环树是内向的,所有连 \(dis_{x,y}\) 都不需要考虑更多的情况。直接拆前缀和:
前缀和就行了。不过我之前可能脑子有点抽,硬是写了个环形 DP 出来,有兴趣可以去我的 luogu 题解 Subtask 4 看看。
其实我觉得本题的难点应该在于拆环后同一个树内的两两答案的计算。然而这个就只是和树上问题有关了。
当 \(k\) 很小的时候,我们可以暴力 \(O(nk)\) DP,设 \(dp_{i,j}\) 表示在 \(i\) 的子树内到 \(i\) 的边数 \(≥j\) 的节点,到 \(i\) 的距离之和(要区分边数和距离!),\(siz_{i,j}\) 表示这些节点的数量,再设 \(up_{x,0}\) 表示 \(x\) 的子树之外的节点对 \(x\) 的答案贡献,\(up_{x,1}\) 在 \(x\) 的子树外对 \(x\) 答案有影响的点的数量。
\(dp_{i,j},siz_{i,j}\) 可以 \(O(nk)\) 求。后 \(up_{x,0/1}\) 就稍微复杂一些:
其中 \(fa\) 是 \(x\) 的父亲,\(w\) 是两者之间的边权。虽然看着很复杂,但实际上还是很无脑的。
当 \(k\) 很大时,上面的方法就会挂成 sb 了。。。
我们考虑某个节点对其它节点造成的代价。我的方法是这样的:对于某个节点 \(x\),求出 \(x\) 的子树大小 \(siz_x\) 以及子树内节点到 \(x\) 的距离之和 \(dis_x\)。我们找到 \(x\) 的 \(k-1\) 级祖先 \(y\) 和 \(k\) 级祖先 \(z\),然后考虑 \(\text{Subtree}(x)\) 对 \(\text{Subtree}(z)-\text{Subtree}(y)\) 的节点的影响,即统计一个集合对另一个集合的代价。对于后者的集合我们简写为 \(T\)。
对于一个节点 \(p\in T\),\(\text{Subtree}(x)\) 对 \(p\) 的代价易得为 \(dist_{p,z}\times (dist_{x,z}\times siz_x+dis_x)\)。但是这个式子不方便我们操作,我们记 \(d_i\) 为 \(i\) 到根节点的距离,由于 \(x,z\) 已知,我们记 \(g_z=dist_{x,z}\times siz_x+dis_x\),则原式等于 \((d_p-d_z)\times g=d_p\times g_z-d_z\times g_z\)。如果有多个 \(z\) 对 \(p\) 造成代价,则代价和为:
于是我们发现可以记录 \(g_z\) 和 \(d_z\times g_z\) 的和,而由于我们是对一个范围内的 \(p\) 进行修改,我们可以考虑差分。
可以证明这样做是不重不漏的。
然后就做完了!!!
当时我好像就是子树内的统计想了很久。现在看来依旧觉得这个思路非常惊喜,有价值的啊!
[NOI2012] 迷失游乐园
\(\text{tag:}\) 概率期望 + DP
犹记得是在初三寒假在 pyt 旁边坐了一个 afternoon 独立做出来的。
下文记 \(w(x,y)\) 表示 \((x,y)\) 这条边的边权。我们先考虑树的情况
因为题目告诉我们每一个点都可以作为起点,因此我们可以联想到换根 DP。我们先钦定一个根为 \(1\),然后进行二次扫描。
- 第一次搜索:记录 \(dp_x\) 表示以 \(x\) 为起点,终点在以 \(x\) 为根的子树中的某一个叶子节点上的路径的长度期望。很套路的转移:
-
第二次搜索:记录 \(up_x\) 表示以 \(x\) 为起点,终点在以 \(x\) 为根的子树之外的某一个节点上的路径的长度期望。首先我们可以知道 \(up_1=0\),然后搜索的时候我们可以利用 \(x\) 的 \(up\) 值去更新他的儿子 \(y\) 的答案。
对于 \(up_y\) 的答案,现在我们确定了起点为 \(y\),第二个点是 \(x\),此时第三步可以走到 \(fa_x\),也可以走到 \(x\) 的其他儿子节点一共有 \(1+(son_x-1)=son_x\) 种选择,但是要注意根没有父亲节点,因此 \(1\) 的下一步只有 \(son_x-1\) 种可能。那么我们也不难得到转移:
统计完两种答案之后,我们再对于每一个点 \(x\),求出以它为起点的路径长度期望值 \(P(x)\)。若 \(x=1\),则 \(P(x)=\dfrac{dp_x}{son_x}\),否则就是 \(\dfrac{up_x+dp_x\times son_x}{son_x+1}\)。
求完每一个点的贡献之后,由于开头我们是等概率选择一个起点,因此总的答案就是 \(\begin{aligned}\sum _{i=1}^n \dfrac{P(i)}{n}\end{aligned}\)。
再扩展到基环树。下文设 \(cnt\) 为环的节点个数,\(stk_i\) 表示第 \(i\) 个环上节点。
我们发现依旧可以考虑求出 \(dp\) 和 \(up\)。开始环套树分析,发现 \(dp_x\) 与上文是一致的求法。而对于 \(up_x\),我们只需要求的环上节点的 \(up\) 值,就可以根据上面的式子进行类似的递推了(注意不是完全一致,需要再根据 \(x\) 相邻的点数进行思考,这里不再具体赘述)。
我们先钦定一个环的遍历方向,对于一个环上节点 \(x\),我们发现他的第一步可以是顺时针,也可以是逆时针。记录方向 \(T\) 表示顺时针还是逆时针,假设我们现在走到了环上节点 \(y\) 时(\(y≠ x\)),我们有几种情况去讨论:
-
如果按照 \(T\) 方向走的下一个节点是 \(x\):由于不能走到重复的点(包括起点),此时只能往 \(y\) 的子树方向走。
-
如果按照 \(T\) 方向走的下一个节点不是 \(x\):要么继续往 \(T\) 方向走到下一个节点上,要么往 \(y\) 的子树方向走。
当我们统计 \(up_x\) 时,我们可以枚举另一个环上节点 \(y\),表示此时朝 \(y\) 的子树方向走,即令 \(y\) 为转折点。这样的时间复杂度就是 \(O(cnt^2)\)。
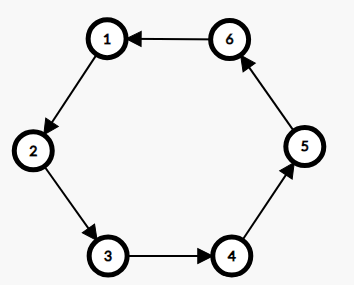
我们其实可以找到其中的递推性。设 \(f_{i,j,T}\) 表示第一步方向为 \(T\),以 \(stk_i\) 为起点,途径 \(stk_j\) 的路径中,\(stk_j\) 往后走的期望长度。说得可能有点模糊,我们拿上图举一个例子:找到以 \(1\) 为起点,并且保证经过了 \(3\) 的所有路径,定义随机变量 \(p\) 表示这些路径中自 \(3\) 开始走到底形成的子路径长度,此时 \(f_{1,3,T}\) 就表示 \(E(p)\)。在上图中,\(p\) 只可能是 \(dist(3,6)\)。由此得出方程:
其中 \(nxt_T(j)\) 表示在 \(T\) 方向上的 \(j\) 的下一个节点。
由于 \(f_{i,j,T}\) 和 \(f_{i,nxt_T(j),T}\) 有关,因此我们可以先从 \(nxt_T(j)=i\) 的 \(j\) 开始,以 \(T\) 的反方向进行更新。若 \(T=0/1\) 分别表示顺时针和逆时针,那最终 \(up_x=\dfrac{f_{x,nxt_0(i),0}+f_{x,nxt_1(i),1}}{2}\)。这是因为 \(x\) 开始是需要选择顺时针或逆时针,每个结果的概率为 \(\dfrac{1}{2}\)。
这样就可以 \(O(cnt^2)\) 求出 \(up_x\) 了,然后再套用树的处理方法更新其他节点即可。
0x03 斯坦纳树
好像是个偏僻的东西,不过挺有意思的,而且很简单。
【模板】最小斯坦纳树
\(\text{tag:}\) 状压 + 最短路
就拿题来说理吧。
省流:给定一个规模很小的点集 \(S\)(\(|S|\leq10\)),要在一张图 \(G\) 中选择一个连通子图 \(G'\),使得 \(S\) 的所有点包含其中,且子图的边权之和最小。
由于边权非负,不难发现最终选出来的连通子图一定是一棵树,我们称这棵树为最小斯坦纳树。
做这道题,很多人可能会想到状压,设 \(dp_{i,S}\) 表示以 \(i\) 为根,包含的节点状态为 \(S\) 的最小斯坦纳树的答案。
然后呢?很多人可能会直接从小到大枚举 \(S\),接着转移 \(dp_{i,S}=\min_{T⊆S}\{dp_{i,T}+dp_{i,S-T}\}\)!其实这是错的!!
???
其实还应该有一种情况 \(dp_{i,S}=dp_{j,S}+w_{i,j}\)。但是这样直接枚举 \(i,j\) 转移就是正确了的吗?很遗憾,依旧不是。因为此时 \(dp_{i,S}\) 和 \(dp_{j,S}\) 都是当前我们枚举的 \(S\) 要统计的答案,我们无法确认到底是谁给谁造成了这样的代价。因此我们要进行松弛操作,即跑一个全源最短路,将 \(dp_{i,S}\) 视为 \(i\) 节点,\(w_{i,j}\) 为边权。每次用堆去找出最小的 \(dp_{i,S}\) 然后去更新 \(dp_{j,S}\)。
最后直接输出答案就行了,非常简单,这就是最小斯坦纳树的求法。
[WC2008] 游览计划
\(\text{tag:}\) 斯坦纳树
省流:从模板题的边权之和变成了点权之和,并且要输出方案。
由于是求点权之和,我们要改一下转移:
这是因为 \(a_i\) 在 \(dp_{i,T}\) 和 \(dp_{i,S-T}\) 中各算了一次,应该减去。
输出方案的话,我们记 \(pre_{i,S}\) 表示 \(dp_{i,S}\) 转移的前驱,我们在 DP 的时候和跑最短路的时候都去更新 \(pre_{i,S}\) 就行了。
0x04 圆方树
我们知道,边双连通分量可以缩成一个点,当一个图中所有的边双连通分量都被缩点后,整张图就会变成一棵树。
但是我们又知道,一个点可以属于多个点双连通分量,所以按理来说点双连通分量不可以直接缩成一个点。
不过我们可以这么做:对一个点双连通分量,我们新建一个节点 \(t\) 用来表示这个点双连通分量,然后将 \(t\) 连向每一个属于这个连通分量的节点 \(i\),这样之后,对于一个连通分量,我们就构造了一个美丽的菊花图。扩展开来,我们给每个连通分量执行一遍上述操作,那整张图会变成什么东西?
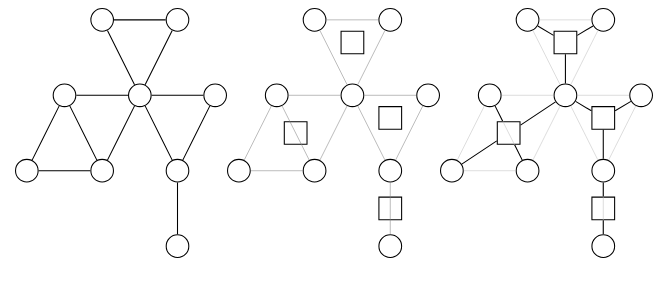
就像上面的图片里一样,所有节点再加上我们新建的节点会形成一棵树!
我们把原图的点看作圆点,新建的点看作方点,我们称这棵树为圆方树。
我们也可以探寻一些性质:如果一个圆点在圆方树上的度数 \(>1\),那么这个点在原图中就是一个割点,因为它的度数就代表包括它的点双个数。此外,由于连通图中的点双个数是 \(<n\) 的,所以最终圆方树的节点个数就是 \(<2n\) 的。
还有一个做难题时常会遇到的结论:我们给圆点赋上 \(-1\) 的点权,给方点赋上与它的度数 \(d_i\) 相等的点权,定义 \(dist_{i,j}\) 表示圆方树上两点间路径上的点权之和,那么对于两个不同的圆点 \(x,y\),它们在原图中的简单路径可能经过的点的个数等于 \(dist_{x,y}+2\),后面的 \(+2\) 是为了加上 \(x,y\) 本身这两个点。换句话说,我们把圆方树上 \(x\to y\) 的路径上的方点提取出来,再把与这些方点相邻的圆点放到一个集合里面,则这个集合就是原图中 \(x,y\) 之间所有简单路径经过的点集之并。
怎么用代码构建一个圆方树?只要你会求点双连通分量,那这个应该也不难吧。
[APIO2018] 铁人两项
\(\text{tag:}\) 圆方树
我们先考虑固定 \(s,f\),然后去找有多少个合法的 \(c\)。我们把这张图的圆方树构造出来,不难联想到上边讲到的那个重要结论(忘记了就再去瞅一眼),给圆点赋值 \(-1\),给方点赋值其对应的点双大小,那么合法的 \(c\) 的个数就是圆方树上 \(s\to f\) 的路径上所有点的权值之和。由于题目强制要求 \(s,c,f\) 互不相同,因为就不用加上 \(s,f\) 这两个点。
因此问题就转换为了求圆方树上任意两个圆点之间的路径点权之和。
我们考虑计算每个节点 \(x\) 对这个答案的贡献。先钦定一个根 \(root\),记 \(a_x\) 表示这个点在圆方树上的点权,\(siz_x\) 表示以这个点为根的子树大小。有一种套路的树上做法,就是一边更新 \(siz_x\),一边统计答案。具体地,我们假设当前枚举的儿子节点为 \(y\),我们考虑把经过 \(x\) 的路径的一端视为 \(y\) 的子树内的某个节点,那么 \(x\) 产生代价的次数就会增加 \(siz_x\times siz_y\),之后我们更新 \(siz_x\) 变为 \(siz_x+siz_y\)。
特殊地,统计完了 \(siz_x\) 之后,我们还要考虑 \(x\) 子树之外的节点,因此 \(x\) 产生代价的次数还要增加 \(siz_x\times (n-siz_x)\)。
这个做法还需要注意 \(\times 2\),因为 \(s,c,f\) 并没有规定什么顺序,如果 \((s,c,f)\) 是一个答案,那么 \((f,c,s)\) 也会是一个答案。
Tourists
\(\text{tag:}\) 圆方树 + 树链剖分 + set
省流:给定一张无向连通图,要求支持两种操作:修改一个点的点权,以及询问 \(x\to y\) 的所有简单路径上点权的最小值。
还是套用那个重要的结论,我们给圆点和方点赋一些权值。圆点的权值就是题目给的权值,方点的权值是与它相邻的所有圆点的点权最小值。因此询问 \(x\to y\) 的简单路径上的点权最小值,就是询问圆方树上 \(x\to y\) 路径上的点权最小值。
但是还有修改操作,如果我们把要修改的点周围所有的方点进行修改,那么很有可能被卡掉。我们考虑更改方点点权的定义,变为它的所有儿子节点的权值最小值。每次修改一个圆点的点权之后,我们就只用修改它的父亲节点的点权,对方点的修改,我们可以使用可重集 multiset 去维护它的所有儿子的点权。
我们发现,对于 \(x\to y\) 的路径上的每一个方点,若它们的父亲节点也都包含在路径上,则答案是没有影响的。也就是说,如果 \(x,y\) 的最近公共祖先是个圆点,那么这次询问的答案不会受到方点权值定义的影响。
唯一可能受到影响的情况就是当 \(x,y\) 的 LCA 是方点的时候。这个时候我们再去找这个方点的父亲节点就行了。
路径查询,单点修改,可以用树链剖分去维护。
STORE - Store-keeper
\(\text{tag:}\) 圆方树 + BFS
先思考暴力做法,我们可以双重 bfs,第一层 bfs 包裹的位置,第二层 bfs 看看当前管理员能否走到包裹的上/下/左/右。
我们发现第一重 bfs 是不可避免,考虑优化第二层 bfs。我们将包裹也视为障碍,则【判断管理员能否走到包裹的上/下/左/右】就是在判断管理员当前格子与包裹的四连通格子是否连通。这是个连通性问题!
因此就能自然地把地图抽象成无向图,把格子视为节点,让它对四连通的非障碍格子连无向边。每次我们把包裹视为一个障碍,就相当于在这个无向图中删掉包裹当前位置所代表的节点,接着整张图可能会分成若干个连通块,我们只需要判断管理员位置对应的节点与目标位置代表的节点是否处在同一个连通块里面。
删点的连通性问题,我们可以考虑建出原图的圆方树。每次删点就是删掉圆方树上的一个圆点,那么剩下的连通块就有两种,一种是被删点的儿子的子树,一种是被删点子树之外的所有点的集合。如果要判断 \(x,y\) 是否在同一个连通块里,我们就可以直接枚举删点后的每一个连通块,判断其是否同时包括 \(x,y\)。
由于是在圆方树上,我们可以计算出每个点的 DFS 序 \(dfn_i\) 以及子树大小 \(siz_i\)。于是对于被删点 \(t\) 的某个儿子 \(s\) 的子树,我们可以 \(O(1)\) 判断 \(dfn_x,dfn_y\) 是否都在 \([dfn_{s},dfn_s+siz_s-1]\) 的范围之内。对于被删点 \(t\) 的子树之外连通块的情况,我们就判断两者的 DFS 序是否都不在 \([dfn_t,dfn_t+siz_t-1]\) 的范围之内。
于是我们用一层 BFS 就能解决这个问题了,时间复杂度是 \(O(nm)\)。
【MX-S1-T3】电动力学
\(\text{tag:}\) 组合数学 + 树形 DP + 圆方树 + 虚树思想
比较难的题目,笔者赛时只做出了树的情况,想到了圆方树但是没能突破。
首先我们来解决一下不辣么复杂的树的情况。
我们要有一个合适的暴力思路:如果我们确定了 \(T\),那么就能进一步找到可以被放入 \(S\) 的元素,设这些元素的个数为 \(sum\),则 \(T\) 这个集合对答案的贡献就是 \(2^{sum}\)。
在一棵树上,如果我们确定了 \(T\) 集合,那么我们就枚举 \(x,y\in T\),将 \(x\to y\) 路径上的所有点都视为可以放入 \(S\) 的元素。想到这里,对虚树有一定敏感程度的童鞋就可以想到,我们把 \(T\) 中的每个点看作特殊点,并构造出它们的虚树 \(\text{tree}\),那么 \(\text{tree}\) 中的所有元素就是所有能够放到 \(S\) 中的元素。证明应该也是比较简单的。
考虑 DP。设 \(dp_i\) 表示 \(T\) 中的节点构成的虚树的根为 \(i\) 的合法 \((S,T)\) 数量。作为虚树的根,\(x\) 可以有两种情况,一种是 \(x\) 本身就是特殊点,另一种就是 \(x\) 不是特殊点。
对于前者,我们可以用任意个儿子去转移。但是瞪眼法无法让我们正确转移。所以我们先通过枚举 \(x\) 的儿子的子树内节点来思考。假设我们在一个儿子的子树内选择了一个点 \(y\),我们发现加上 \(x\) 节点之后,\(x\to y\) 路径上的所有点都可以选入 \(S\),由于 \(y\) 在 \(dp_y\) 中已经考虑过了,所以其余所有点都有选或不选的 \(2\) 种可能。特别注意的是,\(x\) 肯定是可以选在 \(S\) 中的,但是为了防止算重,我们应该在循环外面乘 \(2\)。我们设 \(dep_x\) 表示节点深度,则 \(dp_x\) 的暴力转移为:
于是我们就能想到设 \(g_x\) 表示 \(\sum_{y\in\text{Sub}(x)}2^{dep_y-dep_x}dp_y\) 的值,我们尝试去找到 \(g\) 的递推性:
于是我们的 \(dp_x\) 就能这样转移:
而若 \(x\) 不是特殊点,那么 \(x\) 就必须由至少 \(2\) 个儿子的子树进行转移。我们可以容斥,用上面我们写的 DP 式减去不合法的,我们再加上刚才算出来的 \(x\) 是特殊点的答案,得到最终的 DP 式为:
注意这样的 DP 无法考虑到 \(T\) 为空集的情况,因此我们还需要加上 \(1\)。树的情况就完了。
现在我们在图上思考,由与从 \(T\) 推到 \(S\) 需要思考 \(x\to y\) 可以到达哪些点,是连通性问题。我们考虑圆方树。
这样我们就能大部分照搬树的情况,我们给方点赋值其对应点双的大小减一,圆点赋值为 \(0\),这样我们求 \(x\to y\) 的可达点时,就不用考虑图中的圆点数量了,直接把路径上所有方点的点权相加再加 \(1\) 就行了。但是这个加 \(1\) 很烦,我们把它从指数里面提出去,输出答案的时候再乘 \(2\)。
那就很简单了,还是同样的方法,我们改变每一项的系数,再考虑到方点不可作为特殊点这么一个情况就行了。设 \(a_x\) 表示 \(x\) 的点权,我们得到转移:
- 若 \(x\) 为圆点:
- 若 \(x\) 为方点:
\(g_x\) 的转移对于圆点方点都是一样的:
考虑到我们之前提了个 \(2\) 出去,所以我们把所有 \(dp_i\) 加起来乘个 \(2\),最后加上空集的 \(1\) 种情况就可以了。
[HAOI2018] 反色游戏
\(\text{tag:}\) 组合数学 + 圆方树
都提到删点操作了,就差把圆方树这三个字标在你脸上了。
题目让你对每个 \(i\),输出删掉 \(i\) 这个点之后新的答案。我们放在圆方树上思考,对我们删掉一个点之后,整棵树就会变成若干个连通块,也就是说我们要判断这些连通块是否全部可以满足要求,如果可以,就把他们乘起来。这很有启示作用!我们很有可能要划分子问题。
先来探寻一些结论。我们发现对一条边 \((x,y)\) 进行了操作,如果 \(x,y\) 颜色不同,则这次交换对黑白点数目没有影响,如果 \(x,y\) 同色,那么就是白变黑,黑变白两种情况。不管怎样,黑点白点数目的奇偶性是不会改变的。
利用这个性质,我们可以判断白点的奇偶性是否与总点数一致,即黑点个数为偶数,如果一致,我们尝试去证明它肯定有解:
我们先把 \(G\) 中所有相邻的黑点反转为相邻的白点,但是这样有可能还存在一些落单的黑点,这个时候我们找到这些黑点相邻的任意一个白点,两点进行一次反转,这样的操作就等价于交换两个点。因此我们用这种交换操作把落单的黑点聚在一起,然后同时反转。等所有黑点清理完,我们把操作了奇数次的边视为要操作的边,其余边不管就行了。
因此对于一个连通块,我们要判断其是否有方案,直接判断黑点个数的奇偶性就行了。
但是具体的方案怎么求?
有一个非常牛的思路。我们跑出这个连通块的任意一个生成树,然后假定我们只能操作生成树上的边,不难发现这样操作的话只会有 \(1\) 种方案。但是现在我们随机地选取一些非树边进行操作,然后再在生成树上面进行操作,由于一个连通块中黑点的奇偶性永远不变,所以无论我们怎么操作非树边,在这个生成树操作永远都会恰好有 \(1\) 种方案。因此设 \(G=(V,E)\),这个时候答案就是:\(2^{|E|-|V|+1}\)。
考虑到可能会有多个连通块,我们设 \(cnt\) 为连通块数量,则有:
于是对第 \(i\) 个答案,我们只需要关注断开 \(i\) 之后有解的连通块个数就行了。判断是否有解可以直接用树上子树和去求子树内的黑点数量来判断。
0x05 生成树
这是一个初一就会的东西。但是我们知道它在后期也非常炸裂。
求最小生成树的方法有:Kruskal,Prim,Boruvka。前两者很常用,但是 Boruvka 却显得非常冷门,就连写法都会因题的不同而不同。不过关键时刻 Boruvka 可以成为吊打 Kruskal 和 Prim 的神级存在。所以 Boruvka 到底是个什么算法,我们待会讲例题的时候再解释一下。
另外有一个东西叫做瓶颈生成树,它希望树上的边权最大值尽可能地小。其实它的本质还是最小生成树,因为都是通过按照边权从小到大加入新边,然后连接两个不同的连通块。
瓶颈生成树可以用在一些图的路径问题上。比如要求 \(x\to y\) 的路径,使得路径上的最大值最小。这个时候我们就可以建出原图的瓶颈生成树,然后直接找到生成树上 \(x\to y\) 路径上的最大边权。可以证明这个做法的正确性。有的时候出题人限制的是点权,这个时候我们每条边就取其连接两点的点权最值(一般看情况来考虑是取最大值还是最小值)。
不管怎样,进阶的生成树能够考死你的难点就两种:建模和Boruvka。前者大家应该练过比较多了,后者可能没几个人练过,所以这篇着重是讲 Boruvka 的。
Magic Matrix
\(\text{tag:}\) 瓶颈生成树
精妙的建图题。
前两个限制非常水,小学生都会做,那么难点就是在第三个限制上了。
我们发现 \(\forall i,j,k\in[1,n],a_{i,j}\leq \max\{a_{i,k},a_{j,k}\}\) 这个条件很不舒服,先利用前面 \(a_{i,j}=a_{j,i}\) 的对称性,把它改成 \(a_{i,j}\leq \max\{a_{i,k},a_{k,j}\}\)。但是后面的 \(\max\) 我们还是无法用任何数据结构去维护。考虑一些式子的代换,假设我们已经满足了这个条件,那么就有 \(\forall j,k,l\in[1,n],a_{k,j}\leq\max\{a_{k,l},a_{l,j}\}\),这个就相当于把原来的条件换了个变量,但也启示我们把 \(a_{k,j}\) 给代入原式,则有:
于是两个数的最大值变成了三个数的最大值。以此类推,可以得到:
这个式子应该能够提醒很多 intelligent 的人了。我们考虑建图,对每个 \(i,j\) 建一条 \(i\) 与 \(j\) 之间的边权为 \(a_{i,j}\) 的无向边。则上述式子就相当于 \(a_{i,j}\) 不能大于 \(i\to j\) 的一条路径上的最大值。由于这样的路径有很多条,我们可以只找到最大值最小的 \(i\to j\) 的路径,然后将这个最大值与 \(a_{i,j}\) 进行比较,若 \(a_{i,j}\) 依旧是不大于这个值的,则所有路径的最大权值也都不可能比 \(a_{i,j}\) 小。
因此,我们建出瓶颈生成树(最小生成树),然后找到 \(i\to j\) 路径上的最大值 \(maxx_{i,j}\),与 \(a_{i,j}\) 进行比较,若 \(a_{i,j}>maxx_{i,j}\),那么就是不合法的。由于点数很少,我们可以不使用倍增求 LCA 这个东西,而是直接暴力求出 \(maxx_{i,j}\)。于是这道题就做完了。
[THUPC2022 初赛] 最小公倍树
\(\text{tag:}\) Kruskal
Kruskal 在这里还是更胜一筹啊!
我们知道 \(\text{lcm}(x,y)=\dfrac{x\times y}{\gcd(x,y)}\)。考虑枚举下面的最大公约数 \(d\),来看看通过它连哪些边是可能算入最优解的。
我们任选三个不同的 \(d\) 的倍数 \(ad,bd,cd\) 且 \(a<b<c\),思考怎样使得连通 \(ad,bd,cd\) 的权值和最小。不难发现将 \(ad\) 与后两者连边的方式可以使得答案最小。扩展开来,我们就有一个思路,对于所有的 \(d\),找到最小的一个倍数 \(x\) 使得 \(x\in[L,R]\),然后再找到 \([L,R]\) 中所有的 \(d\) 的倍数,并且都向 \(x\) 进行连边,权值为两者的积除以 \(d\) 的值。由调和级数可以知道差不多会连 \(n\log n\) 条边。
我们不必在乎 \(d\) 到底是不是两个端点的 \(\gcd\),因为 \(d\) 肯定是小于等于两者的 \(\gcd\) 的,那么 \(d\) 作为除数就会产生更大的代价,明显不如选 \(\gcd\) 的这条边,因此它肯定不会被计入答案。
跑一遍 Kruskal 就行了。
Xor-MST
\(\text{tag:}\) Boruvka + 字典树
Boruvka 板板题。
Boruvka 对 \(G=(V,E)\) 跑一遍最小生成树的时间复杂度为 \(O(m\log n)\)。它采用的也是合并连通块的方法。我们设开始的所有节点都没有连边,此时找到一些边 \((x,y)\) 满足 \(x,y\) 当前不在一个连通块当中,我们称这些边为可选边。接着对于每一个连通块 \(T_i\),我们找到权值最小的一条连接 \(T_i\) 与另一个连通块 \(T_j\) 的可选边,然后合并 \(T_i,T_j\)。我们反复执行上述操作,由于每次都至少会将 \(2\) 个连通块合并为 \(1\) 个连通块,因此我们执行的次数不超过 \(\log n\)。每次还要枚举每一条边,因此时间复杂度为 \(O(m\log n)\)。
Boruvka 通常用来解决这样一个问题:求出一个完全图的最小生成树,其中 \(i,j\) 连边的权值为 \(f(i,j)\)。\(f(i,j)\) 是一个同时和 \(i,j\) 有关的式子。
有的时候,我们找到一个连通块的对外连边并不一定要枚举 \(m\) 条边,我们可以用一些数据结构之类的东西找到某个节点 \(x\) 的对外连边 \((x,y)\) 使得 \(f(x,y)\) 最小化,且 \(x,y\) 不在一个连通块(可以理解为染色不同的节点),我们记这个 \(y\) 为 \(t_x\)。找到了每个节点的 \(t_x\) 之后,我们再统一对连通块进行合并。
在这里 \(f(i,j)\) 就是 \(a_i \oplus a_j\)。由于边数太多,我们肯定不能直接枚举每一条边,于是我们就考虑每个点的向外连边。
我们枚举当前点 \(i\),为了找到一个 \(j\) 使得 \(a_i\oplus a_j\) 最小,不难想到使用字典树这个东西。于是我们把每一个 \(a\) 都整齐插入字典树,也就是说我们要在在位数不足的 \(a\) 前面补上若干个 \(0\),然后把它们从高位到低位地插入进去。如果我们当前枚举到了 \(a_i\) 要找另一个 \(a_j\),就可以贪心地在字典树上 DFS。具体来讲就是从高位开始尽可能地与 \(a_i\) 当前位上的数字不同,这个应该很多人都知道怎么 DFS。
但是我们还要注意 \(i,j\) 不属于同一个连通块的限制。其实可以将其转为染色问题。对于当前的连通情况,我们把同一个连通块的节点标上同样的颜色,接着我们从字典树根节点开始向下遍历。设 \(flag_x\) 表示经过字典树上 \(x\) 节点的所有 \(a_i\) 是否颜色相同,相同为 \(1\) 否则为 \(0\),\(col_x\) 表示在 \(flag_x=1\) 的前提下,经过 \(x\) 节点的 \(a_i\) 所染的颜色。
可以通过 \(x\) 的左右儿子转移得到 \(flag_x\) 和 \(col_x\)。如果两个儿子有一个的 \(flag\) 为 \(0\),或者两个儿子的 \(col\) 不同,那么 \(flag_x\) 就是 \(0\)。否则直接继承儿子的 \(col\) 就好了。
于是在查询 \(a_i\) 的时候,对于当前 DFS 到的节点 \(x\),我们当然是先考虑当前位不与 \(a_i\) 相同的情况,但是如果其对应方向的儿子的 \(flag\) 为 \(1\) 且 \(col\) 与 \(a_i\) 的颜色相同,那么只能朝另一个方向搜索了,因为刚才那么走只会走到同一个连通块的 \(a_j\)。可以证明这样的搜索使得每一个 \(a_i\) 一定可以搜到一个合法的 \(a_j\)。
最后我们合并连通块就行了。执行操作次数为 \(\log n\),每次操作中更新字典树的 \(flag,col\) 的时间复杂度为 \(O(n\log V)\),给所有 \(a_i\) 找向外边也是 \(O(n\log V)\),因此时间复杂度为 \(O(n\log n\log V)\)。
Tree MST
\(\text{tag:}\) Boruvka + 树形DP
完全图 MST 显然先考虑 Boruvka。
现在 \(f(i,j)\) 变成 \(w_i+w_j+dis_{i,j}\)。在一棵树上,求一条路径 \(x\to y\) 的边权之和加上两个端点的点权,其实可以换个思路,给每个 \(i\) 建虚点 \(i'\),\(i'\) 向 \(i\) 连一条权值为 \(w_i\) 的边,则上面的问题就是求 \(x'\to y'\) 的路径权值之和。所以我们的 \(f(i,j)\) 就相当于 \(dis_{i',j'}\)。
结合染色的思路,我们在每一轮合并的时候,给当前每个连通块的节点染色。因此对于每一个 \(x'\),我们要找到的就是树上距离 \(x'\) 最近的与它不同色的节点。我们可以设 \(dp_x,f_x\) 分别表示与 \(x\) 距离最小和次小的节点,并且强制规定 \(dp_x,f_x\) 不同色。
怎么强制规定?对 \(dp_x\) 我们可以直接取最优的那个节点,但是对 \(f_x\) 我们要规定它的颜色和当前 \(dp_x\) 不一样。举个例子,\(y\) 是一个比当前 \(dp_x\) 更优的节点,但是 \(y\) 和 \(dp_x\) 颜色相同,这个时候我们就只能更新 \(dp_x\) 为 \(y\),\(f_x\) 不可以继承 \(dp_x\) 原来的节点。当然,如果 \(y\) 和 \(dp_x\) 颜色不同,我们就允许 \(f_x\) 继承 \(dp_x\)。
考虑到这是个树上的问题,我们可以换根来做。换根不难,但是合并稍微烦一些。我们可以这样做,把当前我们要更新的状态 \((dp_x,f_x)\) 和我们枚举的用来转移的状态 \((dp_y,f_y)\) 塞到一个大小为 \(4\) 的数组里面,然后按照它们到 \(x\) 的距离从小到大进行排序,排完序之后,\(dp_x\) 更新为数组第一个元素,\(f_x\) 就找后面的第一个不与 \(dp_x\) 颜色相同的元素就行了。
最后找 \(x\) 的向外边时,我们先考虑 \(dp_x\),如果颜色相同就再去考虑 \(f_x\),由于我们强制规定了两者颜色,因此 \(dp_x,f_x\) 中一定有一个是 \(x\) 向外边连接的节点。
听说有淀粉质做法,是 \(O(n\log^2n)\) 的。不过我们的 Boruvka,内部的 DP 都是 \(O(n)\) 的,带了 \(4\) 个数排序的常数 \(8\),总时间复杂度为 \(O(8n\log n)\),非常不错的解法!
0x06 Kruskal 重构树
我们都知道 Kruskal !!!但是Kruskal 重构树是个什么东西?
我们按照 Kruskal 求最小生成树的顺序加入一条边 \((x,y,w)\),若 \(x,y\) 分别属于不同的连通块,那么我们就新建一个虚点 \(p\),并给 \(p\) 赋上 \(w\) 的点权,接着让 \(p\) 分别与 \(x,y\) 所在连通块的根节点进行连边,然后令 \(p\) 为合并后的新连通块的根节点。如此反复建边,最后得到的图一定是一棵树,我们称这棵树为 Kruskal 重构树。由于 \([1,n]\) 这些原来图上就有的点没有点权,我们给它们赋值为极小值就行了。
一般我们的科学家们不会随随便便搞出一些莫名其妙的东西,所以 Kruskal 必定有些性质是值得利用的。设 Kruskal 重构树的根为 \(root\),我们考虑树上某个节点 \(x\) 的子树 \(\text{Sub}(x)\),不难发现 \(\text{Sub}(x)\) 所有节点的点权都不大于 \(x\) 的点权。
由此可以得到一个非常有意思的结论:原图中两个点 \(x,y\) 之间的所有简单路径上最大边权的最小值与 Kruskal 重构树上 \(\text{lca}(x,y)\) 的点权相等。
还有一个基础的性质:原图中每一个点都是 Kruskal 重构树上的一个叶子节点。
更多的东西需要借助一些题目来理解。
[NOI2018] 归程
\(\text{tag:}\) Kruskal 重构树 + 最短路
入门板子题。
容易想到是要确定一个从起点 \(v\) 驾驶汽车可以到达的节点集合 \(S\),然后在 \(S\) 中求出一个点使得它与 \(1\) 号点的距离最短。但是怎么确定 \(S\) 呢。
考虑一下如何判定 \(x\in S\) 是否成立。通过基础的贪心可以想到,\(x\in S\) 的充分必要条件是存在一条 \(v\to x\) 的简单路径 \(P\) 使得 \(P\) 上所有边的海拔均大于当前的水位线。这里不难想到瓶颈路,我们让 \(P\) 满足最小边权最大,然后用这个最大的最小边权与水位线比大小就行了。于是就能想到构造最大生成树。
但是 \(|S|\) 可能很大,直接 Kruskal 然后暴力找显然是不够优秀的。我们考虑搞一个最大生成树的 Kruskal 重构树。结合一下它的性质,我们可以知道 \(x\to y\) 的所有路径中最大的最小边权为 \(\text{lca}(x,y)\) 的点权。
这样就比较明显了,我们找到一个起始点 \(v\) 在重构树上的祖先 \(t\),若 \(t\) 的点权大于水位线的值,则 \(\text{Sub}(t)\) 的所有节点都可以作为 \(S\) 中的元素。但是其中明明有些节点与 \(v\) 的最近公共祖先不是 \(t\),那为什么我们可以把它们放进 \(S\) 中呢?因为这些节点与 \(v\) 的 lca 只可能属于 \(\text{Sub}(t)\),因此这个 lca 的点权必定大于 \(t\),也必定大于水位线。
于是就有了一个做法,我们找到最浅的一个 \(v\) 的祖先 \(t\) 满足 \(t\) 的点权大于水位线,然后在 \(\text{Sub}(t)\) 的所有叶子节点中找到离 \(1\) 最近的节点。我们可以预处理每一个点到 \(1\) 的最短路 \(dis_i\),让其作为重构树中 \(i\) 的权值。这样我们只需要查询 \(\text{Sub}(t)\) 的叶子节点的最小权值就行了。DP 预处理一下每个节点的答案即可。
[IOI2018] werewolf 狼人
\(\text{tag:}\) Kruskal 重构树 + 主席树
将原题直接翻译的省流:在一个图上询问 \(q\) 次,每次给出 \((s,t,L,R)\),问是否存在一条 \(s\to t\) 的有向路径使得存在一种将路径分为三段的方法,满足包含 \(s\) 的那一段节点编号均 \(≥ L\),包含 \(t\) 的那一段节点编号均 \(\leq R\),中间剩余那一段的节点编号均在 \([L,R]\) 中。
思路还不够清晰,我们再简化一下:找到一个编号在 \([L,R]\) 中间的节点 \(mid\),使得存在一条 \(s\to mid\) 的路径满足路径上所有节点的编号 \(≥L\),且存在一条 \(mid\to t\) 的路径满足路径上所有节点的编号 \(\leq R\)。
我们考虑给原图的每一条边 \((x,y)\) 赋上与 \(\min(x,y)\) 相等的边权,然后建出其最大生成树的 Kruskal 重构树 \(T_1\),我们发现一个节点 \(x\) 的 \(\text{Sub}(x)\) 内的所有叶子节点的编号都大于等于 \(x\) 的点权。这启示我们找到 \(s\) 的最浅的一个祖先 \(anc_x\) 满足其点权大于等于 \(L\),于是 \(\text{Sub(t)}\) 中的所有元素都有可能是我们要选择的 \(mid\),因为存在一条满足条件的 \(s\) 到它们的路径。
同理,把边权改为 \(\max(x,y)\),然后跑出最小生成树的重构树 \(T_2\),这样我们就能找到另一批可能被选择的 \(mid\) 节点。这些节点都在 \(t\) 的一个祖先 \(anc_t\) 的子树之中。
由于 \(mid\) 必须同时存在于 \(\text{Sub}(anc_s)\) 和 \(\text{Sub}(anc_t)\) 中,所以问题就变成了判断这两个集合是否存在交集。我们考虑找到每一个点 \(x\) 在 \(T_1,T_2\) 中的 DFS 序,设其为 \(dfn_1(x)\) 和 \(dfn_2(x)\),以及它们的子树大小 \(siz_1(x),siz_2(x)\)。
然后我们建立一个平面直角坐标系,点 \(x\) 在上面的坐标为 \((dfn_1(x),dfn_2(x))\)。最后问题就变成了询问有多少个点满足其 \(x\) 坐标在 \([dfn_1(anc_s),dfn_1(anc_s)+siz_1(anc_s)-1]\) 范围内且 \(y\) 坐标在 \([dfn_2(anc_t),dfn_2(anc_t)+siz_2(anc_t)-1]\) 范围内。实际上就是询问一个矩形内的点数,二维数点问题!直接主席树维护。
注意各种细节!
Graph and Queries
\(\text{tag:}\) Kruskal 重构树 + 线段树
不知道重构树的小白都可以通过这道题自己 yy 出重构树的概念。
首先可以发现有些边删掉之后并不影响连通性。由于题目中讲到每条边最多只会被删一次,所以我们给每一条边赋上一个与它被删除的时间相等的权值,如果一条边全程不会被删除,则权值为极大值,然后我们跑出一个最大生成树,则这些树边才是我们应该考虑的边(废话?)。
每一条边被删除后会将当前连通块分为两个连通块,然后它们以后也有可能分成两个连通块,子子孙孙无穷尽也。这样的分支可以想象成一个二叉树,则某个连通块的信息就是一个子树的信息,于是就可以树上维护了。为了达成这样的优化效果,我们可以利用上面的生成树,跑出对应的 Kruskal 重构树,每次删边就等于在重构树上删点,并且由于我们是按照删除时间排序的,因此每次删掉的点都会是某个连通块的根节点。
我们考虑维护某个点所在连通块的根节点 \(bel_i\)。当某个点 \(x\) 被删除后,我们把属于 \(ls(x)\) 子树的节点的 \(bel\) 修改为 \(ls(x)\),属于 \(rs(x)\) 子树的节点的 \(bel\) 修改为 \(rs(x)\)。则当前状态下的 \(x\) 所在连通块的节点就是 \(\text{Sub}(bel_x)\) 内的所有点。因此最小值也可以方便地维护了,直接转换为 DFS 序对应的线段树,然后在固定区间内查询区间最小值。
本题要是想到了重构树就会很简单了。这个思路过程很有意思,我在上面标黑了一下,可以自行查看,这个思路过程你甚至不需要知道重构树这个概念就能够驾驭并且写出对应的代码!!
Clusterization Counting
\(\text{tag:}\) Kruskal 重构树 + DP + NTT
警示后人:没事不要写 FFT,有时候要寄......
题解区好像没有找到 NTT 做法??那我水一个。。。
由于题目规定了边权是互不相同的,因此我们可以考虑按照边权从小到大枚举每一条边 \((x,y)\),若当前 \(x,y\) 属于同一个连通块并且加入 \((x,y)\) 这条边之后整个连通块变成了一个完全图,那么新的这个连通块就可以分为一组,因为我们规定了边权从小到大,后面的向外边必然是边权更大的。
要对 Kruskal 过程中每一个连通块进行考虑,可以把对应的重构树建出来,对于树上的一个节点 \(x\),如果 \(\text{Sub}(x)\) 的所有叶子节点可以恰好分到一组,那么我们就给 \(x\) 打个标记。
然后就可以转换,问题就变成了在重构树上被标记的节点中选出 \(k\) 个,满足它们两两之间没有祖先关系,且每个叶子节点都有一个被选出来的祖先。
考虑 DP。设 \(dp_{i,j}\) 表示在 \(\text{Sub}(i)\) 中选出 \(j\) 个被标记过的节点的合法方案数,\(l,r\) 分别为 \(i\) 的左右儿子。则有:
暴力 DP 是 \(O(n^3)\),无法承受。
观察这个式子,发现是个卷积。于是我们可以用 NTT 去优化这个 DP。如果用 FFT 的话可能会有一些炸裂的精度问题,不推荐使用!!!
[SDOI2019] 世界地图
\(\text{tag:}\) Kruskal 重构树 + 虚树
非常炸裂的一道好题,当时山东省选好像只有 \(1\) 个人做对??
首先我们会有一个比较明显的思路,就是预处理前缀和后缀的 MST,然后考虑在两个连通块之间的边,重新把两个连通块整理为一个 MST,也就是一个合并操作。我们还发现在前缀的处理中,我们要从 \([1,i-1]\) 列的 MST 转化到 \([1,i]\) 列的 MST,其实就相当于合并 \([1,i-1]\) 和 \([i,i]\) 两个不同的 MST。后缀的处理也是同样的思路。因此我们只要知道如何执行合并操作就能搞定这道题。
我们回忆一下次小生成树,它的过程是依次加非树边 \((u,v)\),每次加边都找到 \(u,v\) 在最小生成树上的路径中边权最小的那条边,然后拆掉它,用 \((u,v)\) 作为代替。我们这里也能够有一个相似的思路,我们考虑依次把连接两个连通块的边加入图中,对于当前要加的边 \((u,v,w)\),如果我们现在的 MST 中 \(u\to v\) 的路径上的最大边权 \(l\) 满足 \(l>w\),那么 \(w\) 就可以替换掉 \(l\),从而形成新的 MST。
假设我们要合并 \([x,y]\) 和 \([y+1,z]\) 这两个连通块,我们要加的边就是 \((i,y)-(i,y+1)\)。脑袋里模拟一下加边过程,不难发现除了加的第一条边之外,对于每一条边 \((i,y)-(i,y+1)\),我们在当前 MST 中寻找到的它们之间的路径是可以分为 \(3\) 个部分的。这 \(3\) 个部分分别是 \((i,y)\to (j,y)\),\((j,y)\to (j,y+1)\),\((j,y+1)\to (i,y+1)\)。现在我们要找到这条路径中的最大边权 \(w_{max}\),那么我们就可以分别在 \(3\) 个部分查找最大边权 \(w_1,w_2,w_3\),显然有 \(w_{max}=\max(w_1,w_2,w_3)\)。
这个想法是很有启示作用的。我们任选第 \(y\) 列中的两个位置 \((i,y),(j,y)\),则它们在 \([x,y]\) 这一部分的 MST 中的路径上最大边权就有可能成为合并过程中删掉的边。同理,我们在 \([y+1,z]\) 的 MST 中也找出所有 \((i,y+1)\to (j,y+1)\) 路径上的最大边权,则它们都有可能成为被删边。最后,考虑到上一段提到的第 \(2\) 部分,我们枚举的可能的加边也都有可能成为被删的边。
由此不难想到,我们最终合并出来的 \([x,z]\) 连通块中一定会保留上述有可能被删除的边的最小的若干条。我们考虑建图,对于 \((i,y),(j,y)\) 或者 \((i,y+1),(j,y+1)\),我们对两者建一条边,边权为 \([x,y]\) 或 \([y+1,z]\) 的 MST 上两者路径的最大边权。对于 \((i,y),(i,y+1)\),我们就使用它们在原图上的边权。接着跑一遍 Kruskal,把最小的 \(2n-1\) 条边留下来,其余的就全部删掉。
那么对于 \([1,l_i]\) 和 \([r_i,m]\) 的合并,我们要加 \((x,m)-(x,1)\) 的边,按照上面的思路跑 Kruskal。对于前缀 MST 和后缀 MST 的处理,自然也是简单的合并。
不过这样的合并有一个缺点,那就是我们每次暴力建边是 \(O(n^2)\) 级别的。我们可以对于每个连通块,维护连通右侧点或左侧点的边权最小的 \(n-1\) 条边,不难知道只有这 \(n-1\) 条边才可能成为合并中被留下来的边。由于这些点都是确定的,我们考虑在它们所在的 MST 的 Kruskal 重构树中建立虚树,那么虚树上的每一个 LCA 都代表了一条边,这个时候 LCA 的个数是 \(O(n)\) 级别的,我们把 \(n\) 个边界点按照 DFS 序排序,然后对于相邻的点,求出两者的 LCA 代表的边 \((u,v)\),最后求出的 \(n-1\) 条边就是我们需要找到的边。
但是每次都暴力建 Kruskal 重构树还是不行的(什么东西啊??)。对于当前处理完的合并,我们是对 \(2n\) 个点跑 Kruskal,我们不妨就在这次的 Kruskal 中建树,然后处理所有 \([i,y+1]\) 在这个 Kruskal 重构树的虚树中的 LCA。可以证明这样的做法的正确性。
考虑到对于一个前缀 MST,我们在每一个询问中会使用到第一列的所有点,所以我们在处理前缀的时候就顺便把第 \(1\) 列的点放进去,参与 Kruskal 和建立虚树的过程,然后对每个 \([1,i]\) 前缀求出此时第 \(1\) 列的点两两之间在虚树上的 LCA,找到对应的 \(n-1\) 条边。这样在询问的时候就能直接调用了。
按照最开始的思路进行合并就能过了。总时间复杂度 \(O(nm\log n + nq\log n)\)。
0x07 最短路径树
偶尔有用的好东西。
最短路径树(\(\text{Shortest Path Tree}\),简称 \(\text{SPT}\))的定义很简单,就是把 \([1,n]\) 的所有点到某个特定节点 \(rt\) 的最短路径放在一个边集 \(E\) 当中,这个 \(E\) 最后会变成一棵树 \(T\) 的边集,我们把 \(T\) 叫作以 \(rt\) 为根的一个最短路径树。
有的时候出题人会魔改出一些神奇的最短路问题,于是我们就会考虑使用最短路径树去简化一些莫名其妙的图问题,将其转换为树上问题!
具体的 skill 就放在例题里面讲吧。
Edge Deletion
\(\text{tag:}\) 最短路径树
很明显的思路:先删掉一些对每个 \(dis_i\) 没有影响的边。这些边就是不属于原图的 SPT 的所有边。
删完之后如果还需要删,我们就要去删掉一些影响最小的边。贪心地想,每次都删掉最深层的边一定只会最多影响到 \(1\) 个节点的 \(dis\)。要说具体的实现方式的话,我们可以把边的 DFS 序给搞出来,然后按照 DFS 序从大到小的顺序删边。这样就能保证每次删掉的边只会影响到 \(1\) 个节点。
还是比较基础的题,小学生都会做。
Berland and the Shortest Paths
\(\text{tag:}\) 最短路径树
也是板题。
首先我们要找到 \(n-1\) 条边使得 \(1\to i\) 的距离 \(dis_i\) 的和尽可能小。根据定义可知,这 \(n-1\) 条边就是最短路径树上的边。
剩下的问题就是求出方案。由于边权为 \(1\),我们可以使用 bfs 跑一遍最短路。中途如果遇见了可以作为 \(x\) 在最短路径树上的父亲 \(y\),即 \(dis_x=dis_y+1\),那么就把 \((x,y)\) 纳入可能被选择的边集。同时,我们记录 \(cnt_x\) 表示可以作为 \(fa_x\) 的点的数量。
最后判断总方案数是否 \(\leq k\) 的时候,我们就直接计算 \(\prod_{1\leq i\leq n}cnt_i\) 的值就可以了。具体要输出方案的话,其实就相当于对于每个 \(i\) 在 \(cnt_i\) 中任选一条边,由于 \(k\times m\leq 10^6\),我们输出的每次方案可以直接通过 DFS 得到。
[USACO09JAN] Safe Travel G
\(\text{tag:}\) 最短路径树 + 并查集 + LCA
真心的最短路径树好题,很有意思,有趣的树论题我心动了!!!
设 \(dis(i)\) 表示原图上 \(i\to 1\) 的最短路。
我们知道每个点不能经过的那一条边和它的最短路径有关,因此可以想到建出这张图上所有节点到 \(1\) 的最短路径树。由于题目规定了最短路的唯一性,则某个点 \(x\) 不能经过的边只会是 \(x\) 到它在 SPT 上的父亲 \(fa\) 的那一条边 \((fa,x)\)。
接着我们就要思考 \(x\) 可以通过什么途径再次到达 \(1\) 点。我们发现断掉 \((fa,x)\) 这条边之后,只有 \(\text{Sub}(x)\) 这一块的点到 \(1\) 的最短路径会发生改变,那我们首先可以找到另一个点 \(y\) 满足 \(x,y\) 有连边,\(y≠fa\) 并且 \(y\notin \text{Sub}(x)\),这样我们就可以直接从 \(x\) 走到 \(y\) 然后再走一遍 \(y\to 1\) 的最短路。
还有一种情况,我们可以在 SPT 上借助树边从 \(x\) 走到 \(\text{Sub(x)}\) 中的任意一个节点 \(y\),可以证明在树边上走的权值就是 \(x\to y\) 的最短路,因为如果这个条件不成立那么整棵 SPT 也就与定义矛盾了。到达 \(y\) 之后,我们设 \(dis'(y)\) 表示断边后 \(y\to 1\) 的最短路并且这个路径不经过 \(y\) 的后代,则接下来我们只需要花 \(dis'(y)\) 的代价就行了,于是问题就变成了找 \(dis'(y)\) 的值。
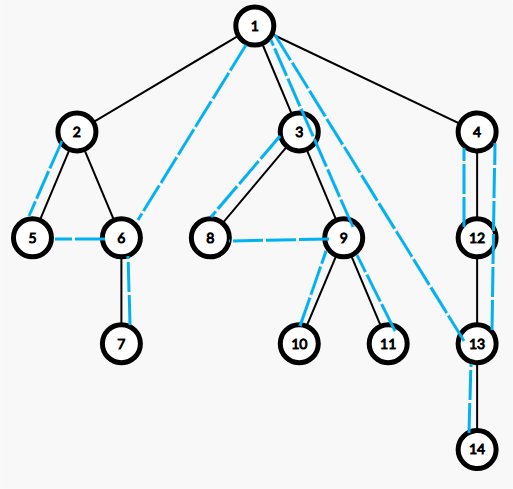
考虑非树边的应用,我们不难发现对于一条非树边 \((u,v,w)\),若在 SPT 上 \(u,v\) 之中恰有 \(1\) 个在 \(\text{Sub}(x)\) 中,不妨设 \(u\) 为这个点,则 \(dis'(u)\) 可以是 \(dis(v)+w\)。假设 \(x=4\),下图的非树边 \((3,6)\) 满足上面的条件,可以结合一下思考 \(dis'(3)\)。
但是如果 \(u,v\) 都是在断边后的 \(\text{Sub}(x)\) 之内,那么 \(u,v\) 不能相互产生影响,因为 \(dis(u),dis(v)\) 都会无效。比如上图中,假设我们删掉了 \((2,4)\),那么 \(\text{Sub}(4)\) 内 \((6,8)\) 这条非树边就是没有用的。当然,如果 \(u,v\) 都不在 \(x\) 子树内,那就根本不用考虑了。
简单来说,对于非树边 \((u,v,w)\),我们求出 \(\text{lca}(u,v)\) 为 \(t\),当断掉的边在 SPT 中 \(u\to t\) 的路径上时,\(dis'(u)\) 就可以是 \(dis(v)+w\),同理如果在 SPT 中 \(v\to t\) 的路径上时,\(dis'(v)\) 就可以是 \(dis(u)+w\)。这也就代表着,\(u,v\) 会对它们对应的到 \(t\) 的路径上点的答案产生影响。比如上图中对于 \((6,8)\),\(8\) 能对 \(5\) 点的答案产生影响。
很明显,\(x\) 借助 \(y\) 到达 \(1\) 的代价为 \(dis(y)-dis(x)+dis'(y)\)。我们可以把每一条非树边 \((u,v,w)\) 按照 \(dis(u)+dis(v)+w\) 从小到大的顺序排序,接着从前往后枚举边,分别统计 \(u,v\) 对 \(u\to t\) 或 \(v\to t\) 这一段上面的点的代价,即 \(dis(u)+dis(v)+w-dis(x)\)。由于我们已经排序了,所以每个点只会被修改一次。于是我们就用并查集把已经修改过的点合并到一个连通块里面,从 \(u,v\) 向上的每次跳点中,我们直接跳到当前连通块中最浅的节点的父亲就行了。
如果一个点没有被修改过,那么答案就是 -1。
这道图上的树论问题就这么做完辣!!
0x08 点分树
大家应该都知道淀粉质(点分治)吧?
点分树呢就是从这个玩意延伸来的一个数据结构。所以点分树应该可以叫做淀粉树。
那么点分树是怎么延伸过来的呢。我们在进行分治的时候,每一次都会找到相应连通块的重心。对于一个连通块 \(S\) 的重心 \(x\),我们拆掉它,那么 \(S\) 就会分成若干个连通块,在这些连通块中,我们再求出对应的重心并存入集合 \(T\),那么在点分树中,\(x\) 的儿子的集合就是 \(T\)。形成的树大概就是下面这样(黑色实线为原树,蓝色虚线为点分树):
我们发现如此构树之后,树的深度最大为 \(\log n\),这是个好的性质。这意味着有些暴力跑祖先的操作是被允许的。
此外,对于两个节点 \(x,y\),我们求出两者的最近公共祖先 \(z\),有一个性质:原树上 \(x\to y\) 的路径必然经过 \(z\)。这是显然的,因为点分治的时候 \(z\) 把 \(x,y\) 分到了两个不同的连通块,若 \(z\) 不在 \(x\to y\) 的路径上,那么 \(x,y\) 是不可能分开的。由此得到另一个结论,设 \(dist(i,j)\) 表示原树上 \(i,j\) 的距离,则 \(dist(x,y)=dist(z,x)+dist(z,y)\)。
这个性质可以拿来求 \(x\) 到所有点的距离之和,我们只需要在点分树上枚举 \(x,y\) 的祖先 \(z\),预处理出子树内的点数 \(siz\) 以及所有点到子树根节点的距离之和 \(sum\),这样我们就可以得到 \(\text{lca}(x,y)=z\) 的所有 \(y\) 到 \(x\) 的距离之和。
有人就会问了:欸 shaber 吧,明明换根求就好了,偏要搞什么淀粉树!
莫急,具体的应用就放在例题里面讲。
【模板】点分树 | 震波
\(\text{tag:}\) 点分树 + 树状数组
问题是求和距离有关的东西,又涉及到了修改操作,所以考虑点分树。
我们建出点分树之后,思考如何在不涉及修改操作的前提下完成每一次询问。对于每次询问的 \(x\),我们可以枚举 \(\text{lca}(x,y)=z\),则问题就是求:
我们找到 \(x\) 的一个祖先 \(s\) 且 \(fa_s=z\),那么答案就是 \(\text{Sub}(z)-\text{Sub}(s)\) 中所有满足 \(dist(y,z)\leq k-dist(x,z)\) 的 \(y\) 的权值之和。
考虑树状数组,给每个 \(z\) 维护 \(\text{Sub(z)}\) 中 \(dist(y,z)\leq i\) 的节点权值之和。由于 \(\text{Sub}(z)\) 在原树上的连通块以 \(z\) 为重心,所以在这个范围之内 \(dist(y,z)\) 是不会超过 \(siz_z\) 的,又因为点分树的深度为 \(\log n\),所以 \(\sum_{i=1}^n siz_i\) 是 \(O(n\log n)\) 级别的,用 vector 储存树状数组完全是可以存下的。
但是我们的答案求的是 \(\text{Sub}(z)-\text{Sub}(s)\) 这一个范围内的点,我们考虑再开一个树状数组,给每个 \(z\) 维护 \(\text{Sub}(z)\) 中 \(dist(y,fa_z)\leq i\) 的节点权值之和。每次查询的时候直接减一下就好了。
那么修改操作怎么办?我们在两个树状数组中进行相应的修改,由于 \(dist(y,z)\) 全程是不会被修改的,我们只需要在对应位置加上修改的变化量 \(\Delta val_x\) 就行了。
[HNOI2015] 开店
\(\text{tag:}\) 点分树 + 前缀和 + 二分
强制在线?树上询问?没有修改?距离之和?点分树!
我们先建出点分树,然后对于每次询问,我们肯定是枚举 \(x\) 的祖先 \(z\) 然后计算走到另一批儿子的子树的代价之和。从暴力入手,我们枚举另一批儿子子树中的节点 \(y\),则两者距离为 \(dist(x,z)+dist(y,z)\)。设枚举范围内 \(a_y\in [L,R]\) 的 \(y\) 的个数为 \(m\),这 \(m\) 个 \(y\) 的 \(dist(y,z)\) 之和为 \(sum\),则对于中转点 \(z\) 的代价就是 \(dist(x,z)\times m+sum\)。因此我们只需要查询 \(m,sum\) 的值就可以了。
首先要想以下怎么解决 \(a_y\in [L,R]\) 的限制。我们知道在点分树上 \(\sum_{1\leq x\leq n} |\text{Sub}(x)|\) 是 \(O(n\log n)\) 级别的,所以我们可以用 vector 把每个节点 \(x\) 的子树内的所有 \(a_y\) 记录下来,并从小到大排序。这样就能通过二分左右端点确定 \([L,R]\) 范围内的 \(y\) 的个数了,设这个数为 \(s_x\)。在计算 \(m\) 的时候,我们用 \(s_z\) 减去包含了 \(x\) 的儿子的 \(s\) 就可以了。
而对于 \(sum\) 的计算,我们可以对 vector 内每个 \(a_y\) 标注上对应的 \(dist(y,z)\),由于 \(a_y\) 已经排序了,所以我们可以直接记录 \(dist(y,z)\) 的前缀和。计算 \(sum\) 的时候,还是考虑容斥,我们另外记录 \(dist(y,fa_z)\) 的前缀和,然后按照模板那样类似的处理就行了。
由于没有修改操作,我们不需要用树状数组。总时间复杂度是 \(O(n\log^2n+q\log^2n)\)。
[ZJOI2015] 幻想乡战略游戏
\(\text{tag:}\) 点分树 + 树论
这是一个树上选最优点的题,我们有时候会用到相关的一个 Trick:设 \(f(i)\) 为选择 \(i\) 的代价,若要选择最优点 \(x\) 使得 \(f(x)\) 最小,则可以随机钦定一个点 \(x\) 为当前最优点,然后对于相邻节点 \(y\) 思考什么时候 \(f(y)<f(x)\)。 把这个 \(f(y)<f(x)\) 的条件弄出来,可以延伸出一些有意思的结论。
比如这道题,我们设 \(f(x)\) 为选择 \(x\) 时的答案。我们钦定 \(x\) 为树根,设 \(sum_x\) 为 \(\text{Sub}(x)\) 中的点权之和,对于 \(x\) 的某个儿子节点 \(s\),我们要让 \(f(x)>f(s)\),则需要满足 \(f(x)-f(s)>0\),考虑把这个差值表示出来,则有 \(val_{x,s}\times sum_s-val_{x,s}\times (sum_x-sum_s)>0\)。由于边权为正数,所以化简可得 \(sum_s>\dfrac{sum_x}{2}\),我们发现此时 \(sum_s\) 超过了 \(sum_x\) 的一半,这就说明在 \(x\) 的相邻节点中最多只有 \(1\) 个会比 \(x\) 更优。记之为结论 \(A\)。
因此这道题就有一个暴力的思路:对于上一次选到的最优点 \(x\),如果此时 \(x\) 的相邻节点中有更优的,就 DFS 到它的位置,如果它的周围还有更优的,那就一直 DFS 下去,直到当前点 \(t\) 的周围不再有任何更优的点。
不过上面那个暴力的正确性不能用最开始那个结论严谨地证明。因为 \(f(s)\not< f(x)\) 并不代表 \(s\) 周围的点 \(t\) 就一定比 \(x\) 更劣,而我们上面的暴力是直接由于 \(f(s)\not< f(x)\) 就省掉了 \(s\) 之后地点地判断。其他的题解大部分都没有提到这个,所以他们都不严谨!!
但是我们依旧可以去证明一下:设 \(s\) 的相邻节点为 \(t\),我们拿 \(f(s),f(t)\) 作个差:
若有 \(f(s)\not< f(x)\),则有 \(2\times sum_s<sum_x\),考虑到 \(sum_t<sum_s\),所以有 \(2\times sum_t<sum_x\),代入上式可得 \(f(s)-f(t)<0\)。整理可得 \(f(x)-f(s)+f(s)-f(t)=f(x)-f(t)<0\),即 \(f(x)<f(t)\)。所以,钦定 \(x\) 为根,对于 \(x\) 的相邻节点 \(s\),若 \(s\) 劣于 \(x\),那么 \(\text{Sub}(s)\) 的所有节点都劣于 \(x\)。记之为结论 \(B\)。
由结论 \(B\) 我们还可以推到另一个结论 \(C\),对于两个节点 \(x,y\),若 \(y\in \text{Sub}(x)\) 且 \(y\) 优于 \(x\),则 \(x\to y\) 路径上除了 \(x\) 的节点都优于 \(x\)。利用刚才的结论 \(B\) 反证一下就可以了。
有了这些结论的支持,我们就能够保证上面暴力的正确性。
现在要优化暴力,我们考虑它的劣势是什么。我们发现从 \(x\) 一直跳到尽头的最劣情况是树的直径,也就是说暴力跳是 \(O(n)\) 级别的。遇到这种时间复杂度是跟一条链的长度有关的情况,我们可以考虑转换为点分树上的求解,因为点分树的直径长度为 \(O(\log n)\) 级别的。
我们先假定点分树的树根 \(rt\) 为当前最优点,接着我们在原树上枚举 \(rt\) 的相邻节点 \(s\),若 \(s\) 优于 \(rt\),我们就找到 \(rt\) 在点分树上的儿子 \(son\) 使得 \(son\) 在点分树上的 \(\text{Sub}(son)\) 中包含 \(s\),然后跳到 \(son\) 并钦定它为当前最优点,继续重复以上操作,直到它的儿子都列于当前最优点。这样的做法正确性也比较好证,结合一下结论 \(C\),对于一个连通块 \(S\),设其根为 \(x\),若 \(S\) 内存在其余的点 \(y\) 使得 \(f(y)<f(x)\),则 \(x\) 必然存在一个儿子 \(s\) 使得 \(f(s)<f(x)\),我们上面的操作就是不断寻找这个 \(s\),如果找不到,那么由结论 \(B\) 可知 \(x\) 就是最优点。
我觉得题解很多都没有讲得太透,所以这里写得比较多,见谅。。
因此,现在唯一得问题就是如何在带修的情况下快速求出 \(f(x)\)。其实我们可以就在点分树上求 \(f(x)\),套路地枚举 \(x\) 的每一个祖先 \(z\) 并设为中转点,然后跑到 \(z\) 的其余子树中统计所有代价。具体地,在点分树上,设 \(sum_i\) 表示 \(\text{Sub}(i)\) 内的点权之和,\(g_i\) 表示 \(\sum_{y\in \text{Sub}(i)}a_y\times dist(y,i)\),\(h_i\) 表示 \(\sum_{y\in \text{Sub}(i)}a_y\times dist(y,fa_i)\),则:
每次修改就暴力跳 \(x\) 的祖先挨个修改就可以了。但是注意:由于 \(dist(x,y)\) 最劣为 \(\log n\),并且我们在寻找最优点的过程中会反复调用 \(f(x)\),那么朴素情况下求一次 \(f(x)\) 的时间为 \(O(\log^2n)\),但是我们还套了一个点分树,所以每次寻找就是 \(O(\log^3n)\)。我们考虑预处理出每个点 \(x\) 到它的每一个祖先的距离,这样的距离一共要求 \(O(n\log n)\) 次,预处理时间复杂度为 \(O(n\log^2n)\),但是调用 \(f(x)\) 的时间复杂度就会变为单只 \(\log\)。
总时间复杂度 \(O(n\log^2n+q\log^2n)\)。
Iqea
\(\text{tag:}\) 图论建模 + 点分树 + 树状数组 + bfs
闲话(小剧场)
第一眼:好像秒了 *3400 的黑题???
再看一眼就会爆炸:真的爆炸了,有个东西不会求啊!?
再看几眼:扣扣脑壳,用必可的画板画了画 ,玩上瘾了嘿?? 好像有所眉目?!
重审题目:这也没看错啊?难道真是哲个样子??
自信开打:我现在无敌啦,我将要成为一个速切 *3400 的神牛!!
隔了一个晚上以及上午不知道是多久:写完了但是样例挂成 joker 了?我是 shaber。。。
除开下午 Futa 学长的讲课,又到了晚上:哎我超!过样例力!交交交交交!!!!
交完之后奇妙的 TLE on test 6 以及无限的 despair 席卷:MoDerate 破防了难绷!!劳资不玩了。。
打开题解:嗯,思路惊奇地没问题!嗯,实现手段和维护方式也几乎一样,牛逼。。但是 alex_wei 说也被卡常了,他好心的摆出一堆优化策略。。嗯,\(O(n\log n+q\log^2n)\) 要拖着巨大的常数卡过 \(n=q=3\times 10^5\),嗯,沉思 + 摆烂 + 1s 憨笑 + Ctrl 三连招 + Ctrl Z 人间清醒 + 手动爆改 + 猛然发现重了很多倍的双向边 = 不知道搞了多久终于 c 过去的 AC 记录。。。。
做了一道好题,人也升华得啥都不剩了。。。

正文
本题的第一个难点在于建图。
题目给了一个限制:保证这些长条连通且二维网格的剩余部分也连通,前面那个连通可以理解,但是后面那个二维网格的剩余部分也连通貌似有点匪夷所思?其实仔细想一下也不难发现一个结论:数据给的四连通图中不会存在中间留有空白的环,如果真的有环,那也只是个实心的方块。
然后我就想到了一个貌似见过的建模思路,就是把每一行的格子拎出来,将相邻的若干个方格缩成一个点,这样每一行就是若干个代表了连通块的节点。然后对于纵列,如果两个方格 \(x,y\) 相邻,我们就把 \(x,y\) 所在的横行连通块相互连边。这有可能出现重边,我们把它们去重一下,最后就会得到一棵连通的树 \(T\)。
我印象中的确见过这个,好像当时很多人都做过的,我能做出来全靠这个记忆力啊 (lll¬ω¬) 。。
再回到题目,看看我们是否会用到建出来的 \(T\)。我们发现这种加点 + 询问最近点的题目就很像是点分树的题会干出来的。下文设 \(b(u)\) 表示 \(u\) 所在的缩点的编号。
依旧是考虑对于确定的点的状态来思考怎么解决询问。我们可以在 \(T\) 的点分树上考虑,对于要查询的点 \(u\),我们套路地枚举 \(b(u)\) 与其余点所在的缩点 \(b(v)\) 的最近公共祖先 \(z\),此时要做的就是在 \(z\) 的不包含 \(b(u)\) 的子树里找 \(b(v)\),又在 \(b(v)\) 代表的连通块中找到对应的 \(v\) 使得 \(dist(u,v)\) 最小。
这里要解决一个比较重要的问题,怎么查询任意两点 \(u,v\) 之间的最短距离?由于我们的点代表的是一个横行的连通块,我们无法直接通过 \(T\) 的形态来解决。因此把点重新拆成横行的连通块是必需的操作。我们可以发现 \(u\to v\) 是分成了三个部分的,第一部分是 \(u\) 走到 \(z\) 这个连通块的最短路径,第二部分是在 \(z\) 上走的一段距离,第三部分是从当前位置到 \(v\) 的最短路。如图(毛的一张图):
所以我们能够得到一个思路:设 \(f(u,z)\) 表示 \(u\) 走到 \(z\) 连通块的最短路长度,\(g(u,z)\) 表示 \(u\) 通过最短路走到 \(z\) 连通块的第一个位置的下标。则 \(u\to v\) 的最短路可以被表示为 \(f(u,z)+|g(u,z)-g(v,z)|+f(v,z)\)。但是怎么求 \(f(u,z),g(u,z)\) 呢?
我们再借助一下点分树这个东西,即使是在点分树上将缩的点全部拆成大的连通块,它的性质也是大差不差的。对于某个方格 \(u\),我们只需要走到 \(b(u)\) 在点分树上的祖先就行了,因为我们可以把它们当作中转的 \(z\) 连通块。考虑到路径的双向性,我们的第一部分路径可以倒过来看,则第一,三部分的路径都是 \(g(z,u/v)\to u/v\)。又因为 \(z\) 在点分树上的 \(\text{Sub}(z)\) 是原树 \(T\) 上的一个连通块,于是,我们就能想到对于某个连通块 \(z\),我们让 \(b(u)=z\) 的所有 \(u\) 作为起点,跑一遍 bfs,如果当前点 \(v\) 的所在缩点 \(b(v)\) 不在 \(\text{Sub}(z)\) 范围中,那么就直接跳过。这样就能统计到 \(f(u,z),g(u,z)\)。
求到这些重要的信息之后,再思考如何统计答案。我们发现 \(|g(u,z)-g(v,z)|\) 这个绝对值很烦,于是我们就暴力拆。由于我们给定了初始点 \(x\),所以只需要考虑 \(g(v,z)\) 与 \(g(x,z)\) 的大小关系。
感觉和模板题的思路很像啊!我们开两个树状数组,对每个 \(z\) 储存 \(g(u,z)=i\) 的所有点中的 \(f(u,z)-g(u,z)\) 最小值,以及 \(g(u,z)=i\) 的所有点中的 \(f(u,z)+g(u,z)\) 最小值。查询的时候直接查第一个树状数组的 \(\leq g(x,z)\) 的前缀最小值,以及第二个树状数组的 \(≥g(x,z)\) 的后缀最小值就行了。但是这样查询可能会查到与 \(x\) 在同一个 \(z\) 的儿子子树中的节点,不过这个时候查到它们一定是不优的,因为对它们而言,比 \(z\) 更优的解就在 \(z\) 的儿子里面,就算查了也不影响答案。
写起来挺恶心的,坚持亿会儿就能挺过去了。
0x09 树的直径
鉴于前面的几个章节都是在讲一些奇形怪状的树,这里就来讲一下非常离谱的树论。
众所周知,树的直径属于一个实用的树论技巧。它被使用的时候通常会是一种特定的情形,那就是一个点 \(x\) 到其余所有点的最长距离 \(dis_x\)。
有一个结论:这个最长距离对应的路径端点,一个是 \(x\) 本身,另一个就是树的直径的某个端点。证明也比较基础,反证就行了。我们脑子里必须要装着这个知识点,因为它看似显然,实则做题的时候可能会突然反应不过来(亲身体验)。
而树的直径的求法呢,可以使用子树合并类 DP,也可以使用两遍 DFS。如果你需要求直径的两端点的话,我还是比较推荐使用后者。
Weighed Tree Radius
\(\text{tag:}\) 树的直径 + 线段树
wy 学长讲的一道题,当时想的时候差个线段树维护直径,然而我不会。wy 学长讲完之后突然发现那个结论是我前不久写 part 1 的时候提到的结论,没想到用到线段树上面来了。我脑子为什么这么不好使QAQAQAQAQ!!
首先有个比较常见的树上 Trick:对于一条路径若要求边权之和加上端点点权,可以给端点 \(i\) 开一个虚点 \(i'\),两者之间连一条权值为 \(i\) 的点权的边,这样就转换为了纯边权问题。
这道题也是如此,我们要开 \(n\) 个虚点。
那么题目中的偏心距就是个 joker 了,本质上就是某个点到其余点的最长距离,结合直径的性质,我们知道任意一点 \(x\) 的偏心距所对应的路径必然经过直径一端点。而要求所有点中的最小偏心距,不难想到把直径给折半,也就是取直径的中间点。这个中间点要使得两侧的边权和之差尽可能小。
How to find?我们找到直径的两端 \(l,r\),先讨论分别与 \(l,r\) 相邻的点 \(l',r'\),如果 \(dis(l,l')\leq dis(l',r)\) 且 \(dis(l,r')≥dis(r,r')\),由于 \(l'\to r'\) 这一段路径上的边权都是 \(1\),我们就直接求出直径长度 \(d\),此时的答案就是 \(\dfrac{d}{2}\)。反之,则选择 \(l'\) 或者 \(r'\),然后直接计算答案。至于 \(l',r'\) 的求法,我们知道直径两端一定都是虚点,所以我们的 \(l',r'\) 就是对应的实点。
所以我们这道题的本质就是维护直径的两端点以便寻找这个中间点。
由于存在修改操作,我们看看能不能用线段树维护。直接搬结论吧:
在一棵树上,设点集 \(A\) 的所有点之间的最长路径的两端为 \(A_x,A_y\),点集 \(B\) 的所有点之间的最长路径的两端为 \(B_x,B_y\),则一端在 \(A\) 一端在 \(B\) 的最长路径必然是 \(A_x\to B_x,A_x\to B_y,A_y\to B_x,A_y\to B_y\) 这四种情况。
考虑将这个结论放到线段树的左右儿子合并操作里面,我们线段树上的每个节点维护编号 \(\in[l,r]\) 的节点组成的虚树的直径端点,子树合并的时候直接枚举这四种情况或者直接继承左右儿子的答案就行了。每次修改 \(x\) 的点权的时候,我们发现受到影响的线段树节点只有包含 \(x'\) 的节点,单点修改一下 \(x'\) 这个位置即可。
我们发现求 LCA 的次数可能比较多,会有 TLE 的风险(其实是因为我 TLE 了),所以我们可以使用 \(O(1)\) 求 LCA 的黑科技,这样就跑得飞快。
Tree Generator™
\(\text{tag:}\) 树的直径 + 线段树 + 括号序列
树的直径还可以当作括号序列然后用线段树维护!
先解释一下如何把一棵树转换为一个括号序列。我们先开一个储存左右括号的栈,接着从树的根节点开始向下 DFS,每次 DFS 到节点 \(x\) 的时候,就往栈顶放一个 \(\texttt{(}\),等到 \(\text{Sub}(x)\) 内所有节点都被遍历过之后,我们再往栈顶放一个 \(\texttt{)}\)。特别要注意遍历到根节点时不用加任何括号。这道题也很好心地帮我们画出了几个示例。
对于这个括号序列 \(S\),有一个结论:我们找出一个子串 \(t\) 使得将 \(t\) 内所有匹配的括号全部删掉之后剩余的字符数量最大,那么 \(S\) 所对应的树的直径就是这个最大的剩余字符数量。
就拿题目里的括号序列举例。对于第三张图,我们有括号序列 \(\texttt{()(()())}\),我们选取 \([2,4]\) 这个子串 \(\texttt{)((}\),由于没有匹配的括号,所以剩余的字符数就是 \(3\),也就是这棵树的直径。而对于 \([3,6]\) 这个子串 \(\texttt{(()(}\),我们发现中间两个括号可以匹配,于是就删掉它们俩,最后就剩下了 \(2\) 个字符,这是不优的。

其实可以发现它的规律,对于一对匹配的括号 \((S_l,S_r)\),我们发现 \(S\) 的 \([l,r]\) 子串代表的就是一个子树,\((S_l,S_r)\) 就是这个子树的根节点。因此上面的结论就可以根据这个规律推理出来,应该不是很难。
现在题目涉及了修改操作,我们考虑用线段树去维护这个括号序列。对于当前区间 \([l,r]\),我们的答案要么从 \([l,mid]\) 取,要么从 \([mid+1,r]\) 取,要么就算跨区间的最优答案。
首先我们要明确一个性质:对于一个删掉了所有匹配括号的括号序列 \(S\),它一定是由若干个 \(\texttt{)}\) 后面紧接着加上若干个 \(\texttt{(}\) 所构成的序列,反证即可。
由此我们可以得到计算跨区间答案的公式。设这个跨区间的子串区间为 \([L,mid]∪[mid+1,R]\),\([L,mid]\) 中最后剩余的左右括号数分别为 \(l_1,r_1\),\([mid+1,R]\) 中最后剩余的左右括号数分别为 \(l_2,r_2\),考虑到衔接部分 \(l_1,r_2\) 的相互抵消,则有:\(r_1+|l_1-r_2|+l_2\)。例如 \(\texttt{))(}+\texttt{)))((}\),我们的 \(l_1,r_2\) 相互抵消就剩下了 \(|1-3|=2\),结合起来理解应该会方便一些。
拆掉绝对值,则原式有两种情况:\((l_1+r_1)+(l_2-r_2)\) 或 \((-l_1+r_1)+(l_2+r_2)\)。这启示我们去维护一段区间的前缀 \(l_2-r_2,l_2+r_2\) 的最大值和后缀 \(l_1+r_1,-l_1+r_1\) 的最大值。由于最后求的也是最大值,所以就算绝对值内的式子拆反了也不会有影响。
这些前缀和后缀的维护可能也会跨区间,所以我们还需要维护每段区间整体删掉匹配括号后剩下的 \(\texttt{(}\) 和 \(\texttt{)}\) 数量。以上的元素合并都需要考虑衔接处的抵消作用。
如果具体的维护有问题的话,还请看其它的题解,这些都是数据结构带师的内容,我作为一个讲「树」的就不再详细讨论了。
[ARC108F] Paint Tree
\(\text{tag:}\) 树的直径 + 前缀和 + 容斥 + 树论
挺有意思的树论题,花了 1h+ 就能做出来了(悲
结合树的直径的基础结论,我们可以知道:每一种染色方案的权值所对应的那条最优路径必定经过直径的某个端点。因此我们要关注直径两端点 \(l,r\) 的染色情况。不难发现如果 \(l,r\) 颜色相同,那么当前染色方案的权值必定是直径长度。而如果 \(l,r\) 异色,那就要进行一些推导了。
看到 \(n\leq 2\times 10^5\) 的范围,我们可以联想到每一种方案的权值必然不会超过 \(2\times 10^5\),因此我们考虑枚举每一个权值对答案的影响次数。
注意到一些较小的权值不会产生贡献,我们可以去找一下枚举的下界是多少。对于一个点 \(x\) 和一个权值 \(w\),如果 \(dis(l,x)>w\) 并且 \(dis(x,r)>w\),我们发现为了满足最终权值为 \(w\),我们不得不让 \(l,x\) 异色同时让 \(r,x\) 异色,可我们现在讨论的是 \(l,r\) 异色的情况,那么 \(x\) 无论怎么染色都不符合条件。因此我们的权值下界就是 \(\max\{\min(dis(x,l),dis(x,r))\}\)。
再去考虑一下每个权值 \(w\) 会被算多少次。首先要保证不存在 \(l\) 的同色点 \(x\) 使得 \(dis(l,x)>w\) 且不存在 \(r\) 的同色点 \(x\) 使得 \(dis(x,r)>w\)。我们可以预处理 \(l,r\) 的 \(sum_{l/r}(i)\) 表示到 \(l,r\) 的距离 \(≥i\) 的节点数量,那么就有 \(sum_l(w+1)\) 个点要与 \(l\) 异色,同理有 \(sum_r(w+1)\) 个点要与 \(r\) 异色。由于我们规定了 \(w\) 的下界,那么这 \(sum_l(w+1)\) 和 \(sum_r(w+1)\) 中包括的点绝不可能有重复的。因为若存在重复的点 \(x\),那么就有 \(dis(l,x)>w\) 且 \(dis(x,r)>w\),与 \(w\) 的下界定义不符。于是我们就能知道有 \(sum_l(w+1)+sum_r(w+1)\) 个点的颜色与 \(l,r\) 的颜色是对应的,即我们确定了 \(l,r\) 的颜色就能确定这些点的颜色。
其次我们要保证存在一个点 \(x\) 使得 \(dis(l,x)=w\) 或 \(dis(x,r)=w\)。为方便表示,下文先规定 \(l,r\) 已经染色。考虑容斥。对于总方案,在除开确定的点之后,剩下的点可以任意染色,记 \(m=n-sum_l(w+1)-sum_r(w+1)\),因此总方案数为 \(2^m\)。而对于不合法的方案,我们发现这主要取决于到 \(l,r\) 的距离恰为 \(w\) 的点。我们需要满足这些点中至少有一个 \(x\) 满足 \(dis(x,l)=w\) 且 \(x,l\) 同色,或者 \(dis(x,r)=w\) 且 \(x,r\) 同色。
我们把 \(dis(l,x)=w\) 的 \(x\) 放到集合 \(A\),\(dis(x,r)=w\) 的 \(x\) 放到集合 \(B\),则不合法的方案数显然为 \(2^{m-|A∪B|}\)。不过我们可以发现只有当 \(w\) 刚好取到下界的时候 \(A,B\) 才可能出现交集。因为若出现一个 \(x\) 满足 \(x\in A\) 且 \(x\in B\),那么就有 \(dis(l,x)=dis(x,r)=w\),根据下界 \(down\) 的定义有 \(down≥dis(l,x)=w\),又考虑到 \(w≥down\),因此 \(w=down\) 时才会存在这么一个 \(x\)。进一步地,对于大于 \(down\) 的 \(w\),不合法的方案数我们直接算作 \(2^{n-sum_l(w)-sum_r(w)}\);对于等于 \(down\) 的 \(w\),我们暴力算一次 \(|A∪B|\) 就可以了。
还有一种特殊情况,那就是 \(w\) 等于直径长度时,由于 \(l,r\) 规定为异色,那么此时就可能不会再有新的方案。而如果真的存在方案的话,我们要注意总方案数为 \(2^{n-2}\),你直接用上面的总方案数的求法会变成 \(2^n\)。此外我们还要特判菊花图的情况,因为它满足 \(down\) 恰好等于直径长度,像我们上面那么算就会出错,此时直接特判整个问题的答案为 \(2^n\)。
为数不多的让我感到非常佩服的一道树论题!!
珍しい都市 (Unique Cities)
\(\text{tag:}\) 树的直径 + 树链剖分 + 树论
先从暴力入手,我们钦定当前点 \(x\) 为根,如果一个 \(y\) 是对于 \(x\) 的一个独特城市,那么必然有 \(\forall z \notin \text{Sub}(y),dep_z<dep_y\)。由此我们可以看出,\(y\) 一定是在从 \(x\) 开始的一条最长链上的节点。
而因为从 \(x\) 开始的最长链的一端必然经过直径的某一端。所以我们可以依次钦定直径的两端为树根,然后考虑如何更新每个节点的答案。
我们可以记录一个栈,来统计 \(x\) 到根的路径上对于 \(x\) 的独特城市。我们发现一个节点 \(x\) 与它的父亲 \(fa_x\) 的独特城市有部分相似,所以我们可以从根开始向下 DFS。每次要遍历到儿子 \(s\in \text{Son}(x)\)的时候,我们就要把 \(x\) 放到栈顶,然后考虑到其余的儿子 \(s'\) 的影响,因为对于 \(s\) 来说,\(s'\notin \text{Sub}(s)\)。因此,我们可以找到所有 \(s'\in \text{Son}(x)\wedge s'\not= s\),计算它们向自己的子树走的最大距离 \(maxx_{s'}\) 并比较出所有 \(maxx_{s'}\) 的最大值 \(dis\)。那么对于当前的栈,如果存在一个元素 \(t\) 满足 \(dist(s,t)\leq dis+2\),则必须把 \(t\) 弹出栈,等到 \(\text{Sub}(s)\) 的答案统计完之后,我们再将栈还原成原来的状态。
不过这么做有一个劣势,由于我们要对每个儿子的子树进行处理,如果我们每次都弹栈然后将元素还原回去,那么就无法保证时间复杂度,因为某些元素可能会被弹出很多次,也会被还原很多次。
其实我们不难发现,当我们处理 \(x\) 的儿子 \(s\) 的时候, 我们用到的 \(dis\) 只会有两种可能,那就是所有儿子中 \(maxx_i\) 的最大值 \(m_1\) 和次大值 \(m_2\),这个就和换根 DP 求 \(x\) 开始的最长链是一个思路。我们考虑对整棵树进行长链剖分,每次处理 \(x\) 的儿子的时候优先处理重儿子 \(p_x\),那么我们就要将栈中所有满足 \(dist(p_x,t)\leq m_2+2\) 的元素 \(t\) 弹出栈。处理完 \(p_x\) 之后,我们要弹出 \(dist(s,t)\leq m_1+2\) 的 \(t\),由于 \(m_1≥m_2\),所以我们在处理 \(p_x\) 时弹出的元素就不需要还原回来,此时直接弹出剩余满足条件的 \(t\) 就行了。
当然,如果要得到 \(x\) 的答案,我们在加入元素和弹出元素的时候就要结合一个桶来判断这个元素在栈中的出现次数。当 \(x\) 的所有后代全部处理完之后,我们得到的栈的大小就是 \(x\) 的答案。为什么要处理完后代才能统计?因为子树内的点也有可能影响到栈内元素。
但是要注意,当一个点 \(x\) 的答案统计之后,我们要检查栈里面是否有 \(fa_x\),如果有就必须把它弹出去,否则会对 \(fa_x\) 的答案造成影响。
我们把直径两端为根的两种情况比一个最大值就是最后输出的答案了。
0x0a 长链剖分优化 DP
这个也算是个离谱的科技产品了。
在看本章节之前请务必了解长链剖分的概念(既然你愿意看这篇 blog,那么你也应该对它有了解吧...)。
在某些特定的场合,长链剖分是可以优化 DP 的。比如在某种连 DP 数组都开不下的时候,我们就可以考虑能否用长链剖分去优化。也就是说,长链剖分可以在时间复杂度和空间复杂度上同时优化 DP。
不过大多时候,长链剖分优化 DP 还是在它跟点与点之间的距离有关的时候才会大展身手。
Dominant Indices
\(\text{tag:}\) 长链剖分优化 DP
朴素的 DP 应该都想得到。设 \(dp_{i,j}\) 表示题中给的 \(d(i,j)\),我们有转移:
特殊地,有 \(dp_{i,0}=1\)。
但是如果树退化成一条链,那么这个 DP 就是个不折不扣的 joker 了,存都存不下啊。
我们试想一下,如果一个点只有一个儿子,那么我们是不是可以直接把儿子的 DP 数组搬过来,然后将下标整体增加 \(1\) 位?这种情况我们可以用 vector 储存 DP 数组,每次搬儿子的 vector 的时候就直接 swap(vector 是可以直接 swap 的,它不是暴力交换元素,而是直接交换内部数据结构,反正很 \(O(1)\) 就对了)。由于 vector 不支持 push_front 的操作,我们可以直接存 reverse 之后的 DP 数组,这样添加 \(dp_{i,0}\) 就变成了 push_back 操作了。
借助这个思路,我们考虑长链剖分,把每个点 \(i\) 的重儿子 \(s_i\) 求出来。每次对 \(i\) 进行 DP 的时候,我们把 \(s_i\) 的 vector 转移给 \(i\),而对于其余的儿子节点,我们就直接暴力更新 \(dp_{i,j}\)。
然后你惊奇地发现你通过了这道题!

肿么肥四????
我相信 \(90\%\) 的人一开始都和我一样懵 B,觉得这个玩意就是在搞笑,它应该是个 joker 才对啊!?这什么川普一边掀起波澜一边拐卖熊大一边啜饮海飞丝的东非大放P。
不过这个复杂度还真的可以证明,它甚至被证明出来了是个 \(O(n)\) 的解法!我们知道每一条长链的长度之和为 \(n\),抛开转移重儿子这一步的 \(O(1)\) 不谈,我们发现其余要合并的儿子都是它所在长链的顶点。而对于这些儿子来说,它们都格各自只有 \(1\) 个父亲会拿它们去合并。这样就能说明,每条长链恰好会被合并一次,把它们的长度加起来就是 \(O(n)\)。空间复杂度也是类似的证明方法。
发明长链剖分优化 DP 的人可真是个天才!!!
[POI2014] HOT-Hotels 加强版
\(\text{tag:}\) 长链剖分优化 DP
个人认为是一道非常有思维难度的一个 DP。
先思考合法的 \((x,y,z)\) 可能会有哪些情况。不妨设 \(dep_x\leq dep_y\leq dep_z\),则有 \(2\) 种情况:\(\text{lca}(y,z)\not= x\wedge x\notin \text{Sub}(\text{lca}(y,z))\) 或者 \(x,y,z\) 两两之间的 LCA 相同。
由此可知,如果要进行正确的 DP,就必须关注到 \(\text{lca}(y,z)\) 的信息。至于第 \(2\) 种情况,我们就要记录相应的点的深度。
随便钦定一个点作为树根,设 \(dp_{i,j}\) 表示 \(\text{Sub}(i)\) 中 \(dist(i,x)=j\) 的 \(x\) 数量,\(f_{i,j}\) 表示 \(\text{Sub}(i)\) 中 \(dist(x,\text{lca}(x,y))=dist(y,\text{lca}(x,y))=dist(\text{lca}(x,y),i)+j\) 的 \((x,y)\) 的数量。解释一下为什么 \(j\) 的含义不能是 \(dist(\text{lca}(x,y),i)=j\),因为这个样子我们就要枚举每一个 \(j\) 进行统计,答案统计是没有办法耍猫腻的,于是你的复杂度就定死了,无法进行优化。而上面 \(f_{i,j}\) 的定义就很简洁,它对答案的贡献只会是 \(f_{i,0}\)。
说到答案的贡献,我们思考答案由什么东西构成,首先是 \(x\) 作为 \(\text{lca}(y,z)\) 的某个祖先的情况,也就是 \(f_{i,0}\)。其余的情况,就是对于某个 \(f_{i,j}\),我们在 \(i\) 的其余子树中把 \(dist(x,\text{lca}(y,z))\) 差的 \(j\) 给补上来,那么代价就是 \(dp_{p,j-1}\times f_{q,j+1}\),其中 \(p,q\) 为当前枚举的点 \(i\) 的任意两个不同的儿子。
设 \(dis_i\) 表示 \(i\) 向下走的最远距离,那么答案的组成就是:
接下来考虑如何转移。结合树上三点可能的分布可以得到:
我们发现上面的转移会涉及任选 \(2\) 点,我们直接用子树合并的技巧转移就可以了。
不过 \(O(n^2)\) 无法通过这道题,我们发现 \(dp_{i,j},f_{i,j}\) 的状态设计都和距离有关,因此考虑长链剖分优化 DP 策略。我们直接 \(i\) 的重儿子的两个 DP 数组转移给 \(i\),剩余的儿子就直接暴力用上式进行转移。时间复杂度的证明就是模板题的方法。
[WC2010] 重建计划
\(\text{tag:}\) 分数规划 + 长链剖分优化 DP + 线段树
根据要求的答案,我们知道它需要分数规划一下,也就是二分最后的答案,对于当前的 \(mid\),如果 \(mid\) 是一个合法的答案,那么就有:
我们把边权全部改为 \(v(e)-mid\),然后判断能否找出一个权值之和非负的一个长度在 \([L,R]\) 范围内的路径。
考虑暴力 DP。随机钦定一个树根,我们设 \(dp_{i,j}\) 表示以 \(i\) 为一端,另一端在 \(\text{Sub}(i)\) 内的边数为 \(j\) 的路径的最大边权之和。要统计经过 \(i\) 的链的最大边权之和时,我们就采取子树合并大法,用当前的 \(dp_{i,j}\) 加上当前枚举的儿子 \(s\) 的 \(dp_{s,k}\) 就能得到长度为 \(j+k+1\) 的经过 \(i\) 的最长链。\(dp_{i,j}\) 的转移也很简单:
对于当前枚举到的 \(dp_{s,j}\),我们要找一条边数在 \([L,R]\) 之间的路径,那么我们就在已经转移完的部分中找到长度在 \([L-j-1,R-j-1]\) 之中的路径边权之和最大值。当然这个区间范围可能会出现负数,把区间的边界与对应的极值取一个最大或最小值就可以了。
但是 \(O(n^2)\) 很难受,考虑长链剖分,对于 \(x\) 的重儿子 \(t\),我们把它的 DP 数组向后移动一位然后全局加上 \(val_{x,t}\),这样就能得到继承之后的 DP 数组。接着暴力跑其余儿子节点的转移。
不过这个查询很烦,加上每次子树合并之后的修改操作,我们可以考虑一下线段树。每次先遍历重儿子 \(t\) 的时候,我们用线段树对每一个 \(j\) 位置储存 \(dep_i-dep_t=j\) 的 \(dist(i,t)\) 最大值(\(dist(i,j)\) 表示的是边权之和)。当我们遍历完 \(\text{Sub}(t)\) 要回溯的时候,我们就把 \(val(x,t)\) 的权值给每个位置都加上去,这样就把 \(t\) 对应的线段树嫁接到了 \(x\) 对应的线段树上面了。注意这个步骤中,由于 \(x\) 对应的线段树能够维护的位置比 \(t\) 多了一个(也就是多了一层深度),我们要先把这一位加上去,然后执行区间修改。
在子树合并的过程中,如果要查询一段区间上的最值,我们直接区间查询。如果 \(dp_{i,j}\) 更新到了更大的值,我们就在线段树上给 \(j\) 位置进行一次单点修改。
当我们把所有答案都统计完之后,就看看统计得到的最大边权之和是否非负,如果是非负的,那么当前的 \(mid\) 就可行。
写起来可能比较复杂,有耐心就行了。
总时间复杂度 \(O(n\log n\log V)\)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号