【论文阅读】Diverse Image-to-Image Translation via Disentangled Representations(ECCV2018 oral)

目录
- 相关链接
- 方法亮点
- 相关工作
- 方法细节
- 实验结果
- 总结与收获
- 参考文献
相关链接:
论文:https://arxiv.org/abs/1808.00948
代码:https://github.com/HsinYingLee/DRIT
方法亮点:
- 提出一个内容判别器,用于判断编码器生成的图片内容性质是否一样的。
相关工作:
- 文章的提出主要是解决了unpaired-data 的图像翻译问题。目前大多数的解决方法都是基于CycleGAN,本文也不例外。
与CycleGAN较为不同的是本文借鉴了infoGAN的思想,将一张图片看成主要是由内容(content)和特性(Attribute)两部分组成, 用两个Enconder分别去学这两种特征。
这篇文章和去年2017年BMVC上的工作GeneGAN也很相似,GeneGAN 使用了一个Encoder将一张图片编码成前景和背景两个部分,前景信息可能是眼镜,微笑等等,通过前景的转换,可以得到同一个人不同风格,比如从微笑-》不笑。

- 模式崩溃问题目前还没有得到很好的解决,受到该问题的影响,输入随机噪声不能够使GAN生成的多样。
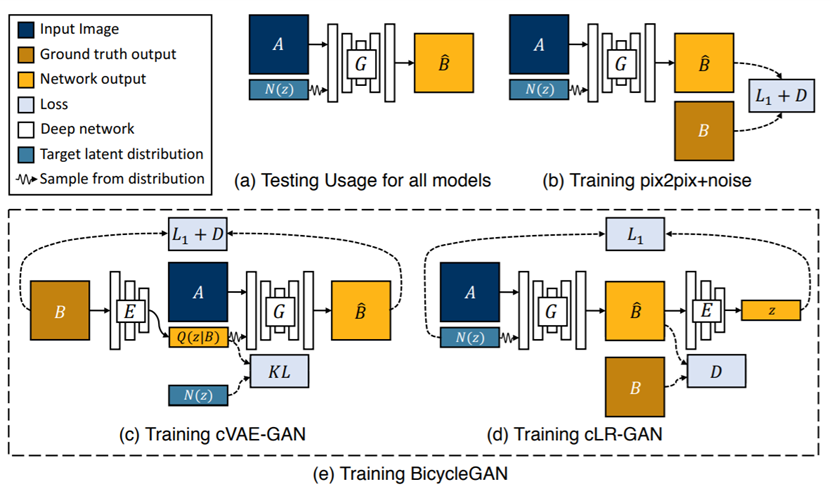
为了解决上述问题,本文参考了BicycleGAN,对输入噪声进行了约束。(如下图:)
方法细节:
文章工作:

如上图所示,本文可以实现两种类型的风格转换,左图:给定输入,和服从正态分布的随机噪声,即可得到风格转换图;右图:给定两张输入,通过编码器分别获得两张图片的Attribute,通过交换Attribute进行风格转换,我们把其中一张输入作为Guide,也就是只提供Attribute特征(右图Attribute列)。
方法架构:
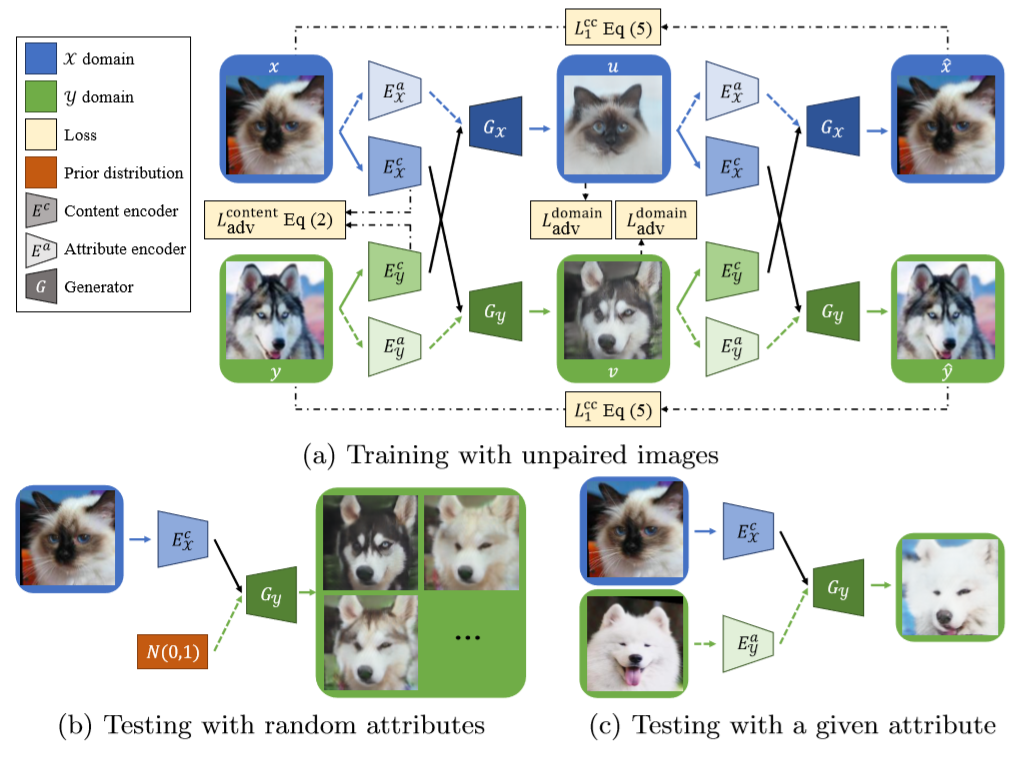
从上图来看,这篇论文的网络结构还是比较复杂的,由4个编码器,2个生成器,2个判别器,1个内容判别器组成的。4个编码器用来学两种不同风格图像的内容和特征,2个生成器分别用于学两种不同风格的图片,2个判别器就用来判别器这两个生成器生成的结果是否足够“逼真”。
作者基于这样的一个假设:不同风格类型图片的内容由于不包含特征信息(理想情况下),应该是不可区分的。在这个前提下,作者提出了两个策略:
- weight-sharing: 两个内容编码器的最后一层网络参数共享,保证两个内容分布一致;两个生成器的第一层网络参数共享;
- content discrimination: 判别器无法区分Ec(x)或Ec(y)是哪一类;损失函数如下:

总体损失函数:

其中 即上文提到的内容判别器损失
即上文提到的内容判别器损失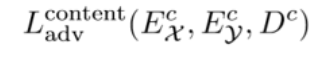 ;
;
循环损失: ,即x经过生成器Gy得到x',再经过Gx得到x'',此时x和x''应该是相同的。
,即x经过生成器Gy得到x',再经过Gx得到x'',此时x和x''应该是相同的。
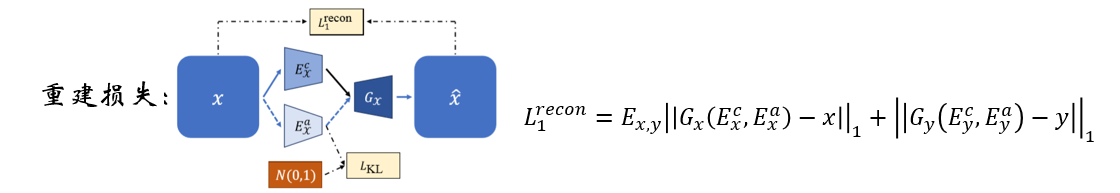

实验结果:


winter->summer实验,上述结果图中可以看出我们的方法生成的比其他的方法生成的图片更加自然逼真。

该实验主要是比较不同方法生成的图片的真实性。实验数据:winter->summer translation on the Yosemite dataset。Fig.9左侧结果图实验设置为判断一对图片中,询问观测者哪张图片更真实一点。这一对图片怎么采集的呢?一张是来自我们方法生成的图片,另外一张则是来自其他不同生成方法的结果图。Fig.9右侧结果图实验设置为判断一对图片中,询问观测者哪张图片更真实一点。这一对图片怎么采集的呢?一张是来自真实图片,另外一张则是来自不同生成方法的结果图。遗憾的是文章中并没有明确地提到该次实验的观测者数量,判断图片是否为整个数据集。这是比较存疑的一个实验。
从这个结果来看,生成图像的真实性比cycleGAN还要低的多。

表2的第一行和第二行结果可以明显的看出本文提出的内容判别器对生成结果的多样性有很大的提升。
表3想表达的是BicycleGAN需要成对的数据集,对数据集的要求比较高,而我们的方法不需要成对的数据集效果却能和BicycleGAN旗鼓相当。


上述的实验,主要是想通过分类准确率这个评价指标来判断我们生成结果的质量。分别用上述的方法训练,得到图片用来训练分类器,只用用同一个测试集来衡量该分类器的分类效果,分类效果好说明生成的图片较好。从表中可以看出本文的方法在这两个数据集上的生成效果都能较好的保留source的内容信息。

作者说图7中证明了提出的方法的生成器学习的是图像的分布,而不是简单的记忆训练集中的图像,但是个人觉得这个解释不够清晰。大胆的猜测,上图中非红色框内为本文生成的图片,作为guide 的Attribute是两张Attribute图片经过Encoder 学习到的特征进行插值得到的。
总结与收获
这篇文章的最大特点在于提出了一个内容判别器,用于约束两个数据集的内容特征;但是本文的网络数量较多,训练起来,速度会受到一定影响,网络也比较复杂,对GPU有一定的要求。并且本文的生成图像在真实性上比CycleGAN还差。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号