Res2net:多尺度骨干网络结构
《Res2Net: A New Multi-scale Backbone Architecture》
来自:南开大学程明明组
论文:https://arxiv.org/abs/1904.01169
>多尺度的信息
首先一张图片里物体可能有不同的大小,例如沙发和杯子就是不同大小的,第二,必要的上下文信息可能所占的面积要大于物体本身。例如,我们需要根据大桌子的信息来更好的确定桌上的是个杯子或是笔筒。第三点,对细精度分类和语义分割,理解局部,观察不同尺度下的信息是有必要的。

Alexnet按顺序堆叠卷积并得到比传统方法取得显著的效果。然而,由于网络深度和卷积核大小的限制,alexnet只有很小的感受野。
VGGnet增加了网络深度并使用更小的卷积核。更深的网络结构可以扩大感受野,从更大的尺度提取特征。通过堆叠更多大卷积核的层,是一种更容易扩大感受野的方法。VGG比Alexnet有更少的参数更强的表达能力。但是都是线性堆叠卷积,只能表达不灵活的感受野。
Googlenet采用并行的不同尺度的卷积来增强多尺度的表达能力。但是有受限于计算资源。因此多尺度表征的策略任然没能更大范围的感受野。
Resnet引入短连接,因此在有更深的网络结构的同时缓解了梯度消失的问题。特征提取的过程,短连接让不同的不同卷积相结合。类似的,densenet里的密集连接也使得网络能够处理一个很大范围的尺度。

残差块里头又有残差连接,所以取名res2net
>Res2Net的bottleneck模块
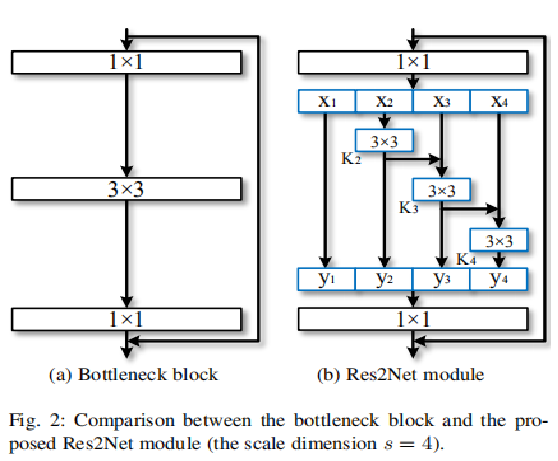
yi表示Ki()的输出。 子特征xi和Ki-1()的输出加在一起,然后送入Ki()。 所有的分块拼接后在送入1*1的卷积。分块在拼接的策略能增强卷积更有效处理特征。 为了在增加s的同时减少参数,我们不对x1进行卷积。更大的s一般对应更强的多尺度的表达能力。(这样子y1,y2,y3,y4就拥有不同尺度的特征)
>Res2Net + 其他模块
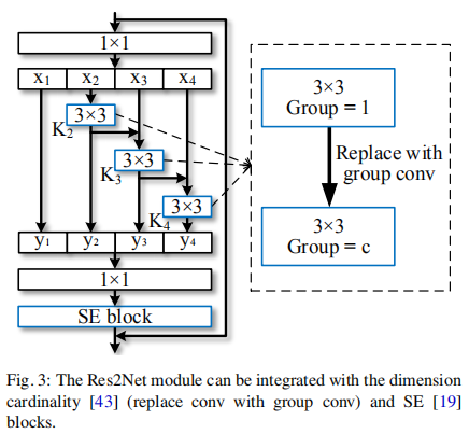
1、中间的3x3卷积可以替换成c组卷积操作。 (ResNeXt)
2、实验也说明了能够通过SE进一步提高效果
>实验设置:
1、框架:都是用pytorch (代码还未开源)
2、在imagenet数据集上SGD,
3、weightdecay设为0.0001,momentum设为0.9,初始学习率是0.1, 每隔30个epoch*0.1.每个模型都是训练100个epoch;
4、环境:4 Titan Xp GPUs
>实验结果
ImageNet上的实验:
Table1,table2 res2net在image上top-1和top-5都有1~2%的提升。
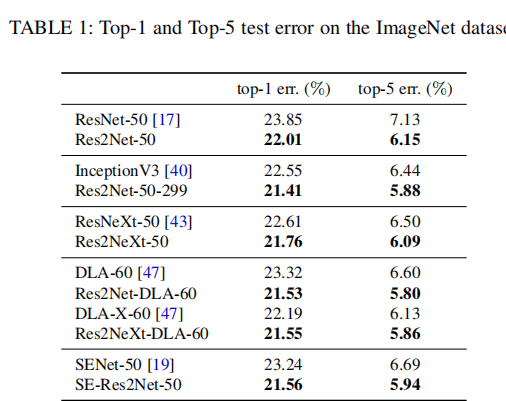
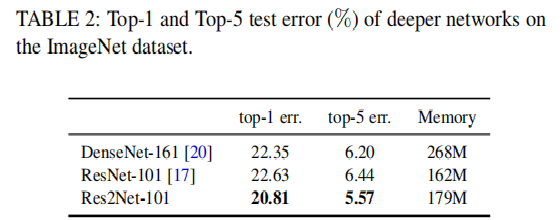
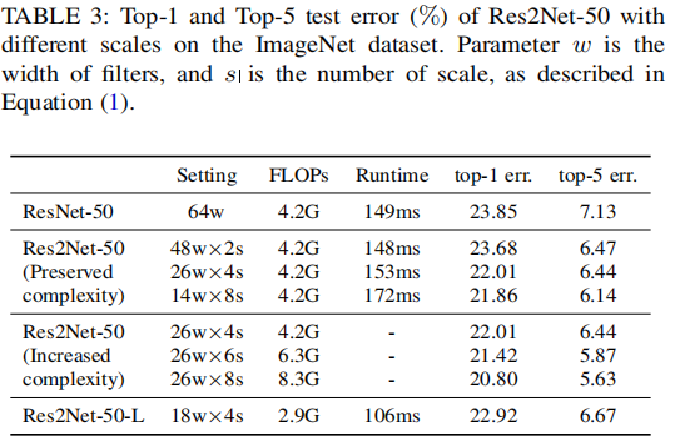
Table3 验证尺度的有效性, 保持计算复杂度,随着尺度增加精度不断提升。 Res2Net-50在ImageNet数据集不同规模测试错误率结果。其中参数w为卷积宽度(通道数吧),s为scale
不同模块组合的对照结果()
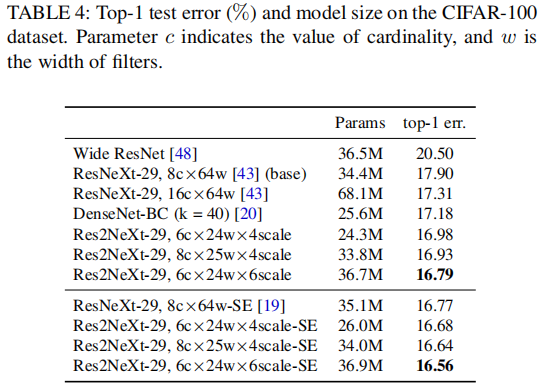
不同维度的对照试验(cifar100上的实验)
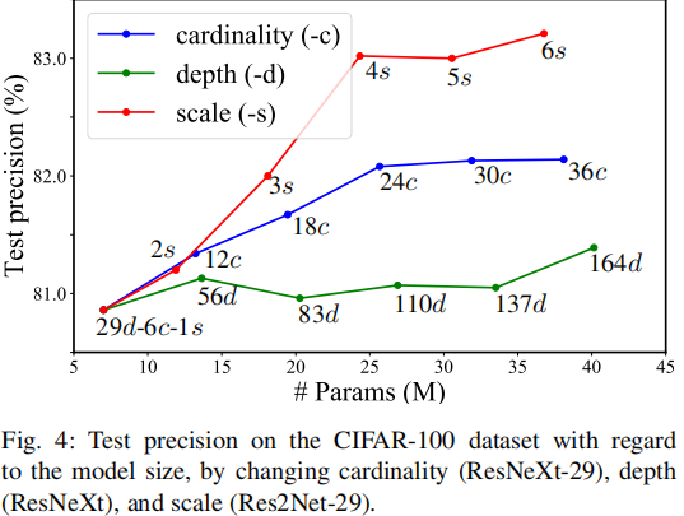
c是基数维度(参照ResNeXt)
可以看到网络深度提升效果较差
(1)s=2的的地方比增加基数的效果差, 在s=2时只能通过增加1*1卷积来增加模型性能。
(2)s=5,6效果提升有限。 因为cifar100图片大小32*32没有很多尺度(那在imagenet上呢?)。
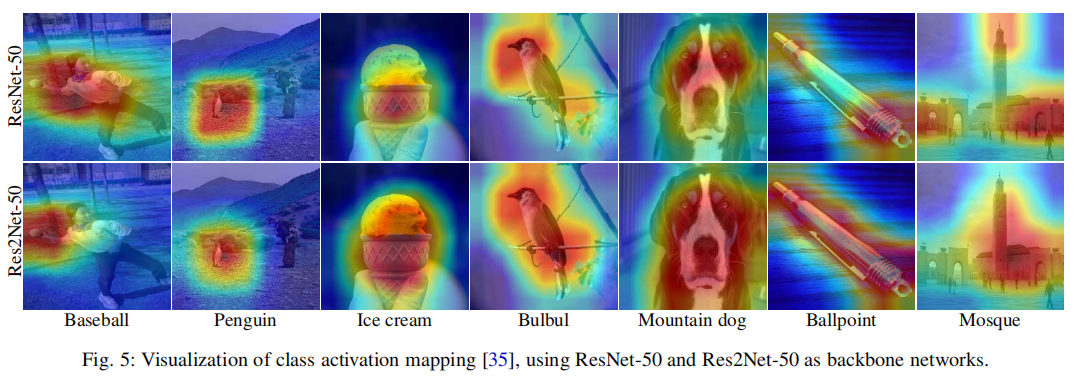
类别响应图Class activation mapping
响应图更集中在小目标上。 中等大小的物体上,两者效果差不多。 大的物体上res2net就响应图包含整个物体。
下面的实验都是将backbone换成res2net
1)目标检测应用
Faster -Rcnn: ResNet-50 vs. Res2Net-50进行对比。小目标 中目标 大目标:都有提升 voc & coco 数据集上 AP 都有2%的提升
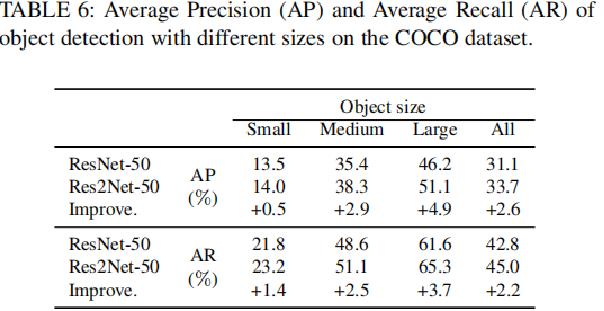
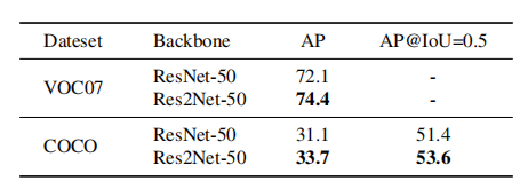
2)语义分割应用
数据集:PASCAL VOC12 10582 训练图片 and 1449验证图片
实验方法: Deeplab v3+
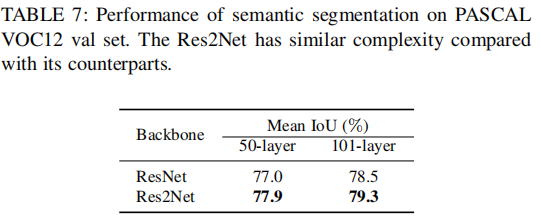

3)实例分割
数据集:coco
Mask-RCNN上:resnet-50 vs res2net-50
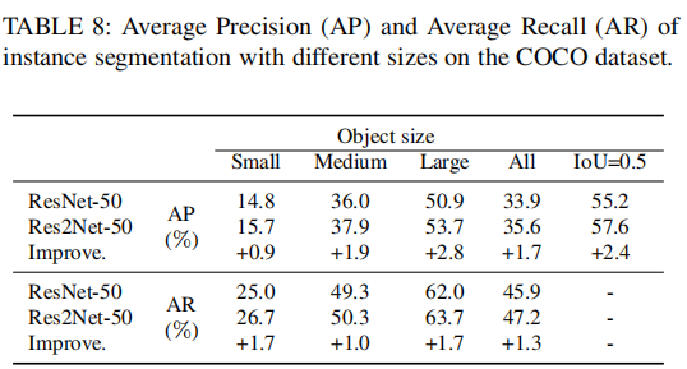
4)显著性检测(Salient Object Detection)
ResNet-50 和Res2Net-50的显著目标检测结果对比



 浙公网安备 33010602011771号
浙公网安备 33010602011771号