

pandas chunsize 以及chunk使用
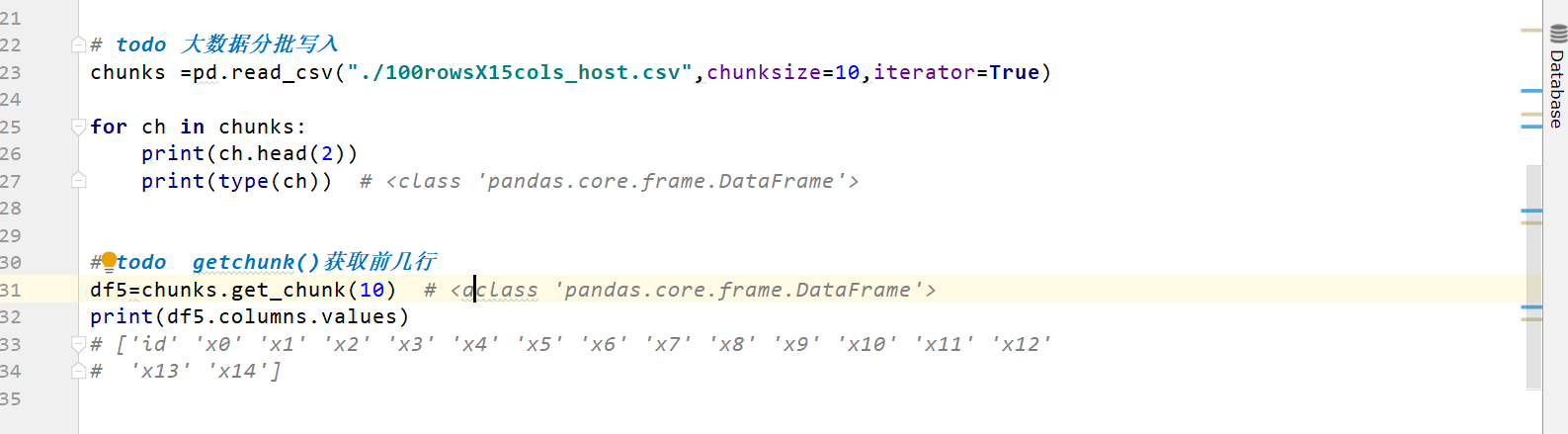
这么大数据量,小的内存,还一定要用python/pandas的话可以考虑使用迭代器,在读取csv时指定参数data_iter = pd.read_csv(file_path, iterator=True),然后指定df = data_iter.get_chunk(n)将指定的n行数据加载到内存进行处理或者可以指定chunks = pd.read_csv(file_path, chunksize=m)将数据切分,然后通过for chunk in chunks迭代处理数据。当然这么做的前提是要明确最终需要的计算结果怎么通过分块的结果聚合起来,比如求均值可以求每个分块的和然后记录行数,求value_counts()可以使用Series.add方法进行迭代等。这么做可以保证内存稳定在一定的范围,但是速度上肯定会受限。如果要进行数据建模,用到scikit-learn之类的16G内存真的太吃紧了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号