
【逆向】Base64编码解码及逆向识别
序言
Base64编码解码原理相关内容,可以参考之前写的文章。
示例代码
注意:该示例代码仅为Base64编码实现的其中一种,实际分析样本的Base64编码实现并不一定与此代码相同,读者应重点理解其原理部分,而忽略其实现形式的不同。


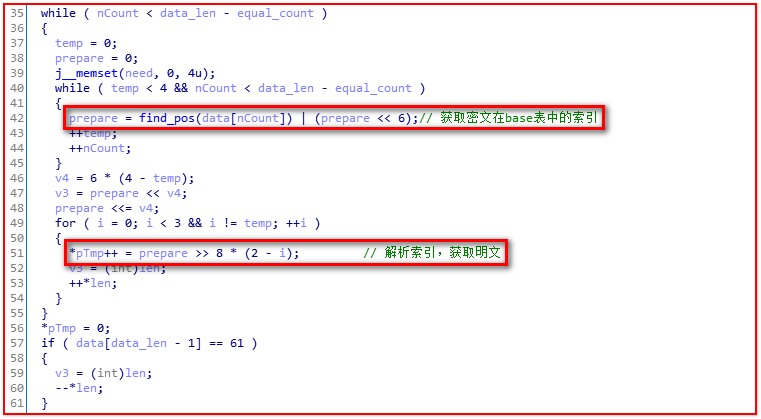
1 // Base64.cpp : 定义控制台应用程序的入口点。 2 // 3 4 #include "stdafx.h" 5 #include <stdio.h> 6 #include "string.h" 7 #include "stdlib.h" 8 9 static char find_pos(char ch); 10 char *base64_encode(const char* data, int data_len, int *len); 11 char *base64_decode(const char* data, int data_len, int *len); 12 const char base[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="; 13 14 //======获取BASE64编码索引 15 static char find_pos(char ch) 16 { 17 //the last position (the only) in base[] 18 char *ptr = (char*)strrchr(base, ch); 19 return (ptr - base); 20 } 21 22 //======BASE64编码 23 char *base64_encode(const char* data, int data_len, int *len) 24 { 25 int prepare = 0; 26 int ret_len; 27 *len = 0; 28 int temp = 0; 29 30 int nCount = 0; 31 char chArr[4]; 32 33 char *pRet = NULL; 34 char *pTmp = NULL; 35 36 //计算编码后字符长度 37 ret_len = data_len / 3; 38 temp = data_len % 3; 39 if (temp > 0) 40 { 41 ret_len += 1; 42 } 43 44 //申请返回数据缓冲区 45 ret_len = ret_len * 4 + 1; 46 pRet = (char *)malloc(ret_len); 47 if (pRet == NULL) 48 { 49 printf("No enough memory"); 50 exit(0); 51 } 52 memset(pRet, 0, ret_len); 53 pTmp = pRet; 54 55 //处理所有待编码数据 56 while (nCount < data_len) 57 { 58 temp = 0; 59 prepare = 0; 60 memset(chArr, 0, 4); 61 62 //3个字节一组,保存每个字节二进制位 63 while (temp < 3) 64 { 65 if (nCount >= data_len) 66 { 67 break; 68 } 69 prepare = ((prepare << 8) | (data[nCount] & 0xFF)); 70 nCount++; 71 temp++; 72 } 73 //确保每个字节数据以24比特位排列 74 prepare = (prepare << ((3 - temp) * 8)); 75 76 //获取base表索引及编码字符 77 for (int i = 0; i < 4; i++) 78 { 79 //最后一位或两位用'='填充 80 if (temp < i) 81 { 82 chArr[i] = 0x40; 83 } 84 else 85 { 86 //获取base表索引 87 chArr[i] = (prepare >> ((3 - i) * 6)) & 0x3F; 88 } 89 //通过索引获取对应编码字符 90 *pTmp = base[chArr[i]]; 91 pTmp++; 92 (*len)++; 93 } 94 } 95 96 *pTmp = 0x00; 97 return pRet; 98 } 99 100 //======BASE64解码 101 char *base64_decode(const char *data, int data_len, int *len) 102 { 103 *len = 0; 104 char need[3]; 105 int temp = 0; 106 int nCount = 0; 107 int prepare = 0; 108 int equal_count = 0; 109 int ret_len = (data_len / 4) * 3 + 1; 110 111 char *pRet = NULL; 112 char *pTmp = NULL; 113 114 //判断结尾有多少个通配符‘=’ 115 if (*(data + data_len - 1) == '=') 116 { 117 equal_count += 1; 118 } 119 if (*(data + data_len - 2) == '=') 120 { 121 equal_count += 1; 122 } 123 124 //申请缓冲区 125 pRet = (char *)malloc(ret_len); 126 if (pRet == NULL) 127 { 128 printf("No enough memory.n"); 129 exit(0); 130 } 131 memset(pRet, 0, ret_len); 132 pTmp = pRet; 133 134 //解码数据(‘=’除外) 135 while (nCount < (data_len - equal_count)) 136 { 137 temp = 0; 138 prepare = 0; 139 memset(need, 0, 4); 140 141 //4个字节一组,获取每个字符在base表中的下标索引(‘=’除外) 142 while (temp < 4) 143 { 144 if (nCount >= (data_len - equal_count)) 145 { 146 break; 147 } 148 prepare = (prepare << 6) | (find_pos(data[nCount])); 149 temp++; 150 nCount++; 151 } 152 //将每个索引按24比特位进行排列 153 prepare = prepare << ((4 - temp) * 6); 154 155 //获取编码前字符 156 for (int i = 0; i<3; i++) 157 { 158 if (i == temp) 159 { 160 break; 161 } 162 *pTmp = (char)((prepare >> ((2 - i) * 8)) & 0xFF); 163 pTmp++; 164 (*len)++; 165 } 166 } 167 *pTmp = 0x00; 168 if (data[data_len - 1] == '=') 169 { 170 (*len)--; 171 } 172 173 return pRet; 174 } 175 176 //======Main 177 int _tmain(int argc, _TCHAR* argv[]) 178 { 179 int len1, len2, len3; 180 char *former = "A"; 181 len3 = strlen(former); 182 183 //编码 184 char *after = base64_encode(former, len3, &len1); 185 printf("enCode=%s nLen=%d\n", after,len1); 186 187 //解码 188 former = base64_decode(after, len1, &len2); 189 printf("enCode=%s nLen=%d\n", former, len2); 190 191 return 0; 192 }
逆向识别
1、编码识别

2、解码识别
总结
1、识别代码中的“=”通配符
2、识别Base编码表,静态编码表可以在IDA“string”窗口查看,有些动态拼接的则需要手动识别
3、识别代码中对数据的左移右移操作
4、最主要的是理解编码解码原理,比如编码时通常都会用3个字节一组来处理比特位数据,这些特征都可以用来分析识别

 浙公网安备 33010602011771号
浙公网安备 33010602011771号