
UML语言解析——oo第四单元总结
第一章 四单元架构总结
直接分析第三次作业架构。架构如下(为方便起见,省略工厂类,主类,UserApi):
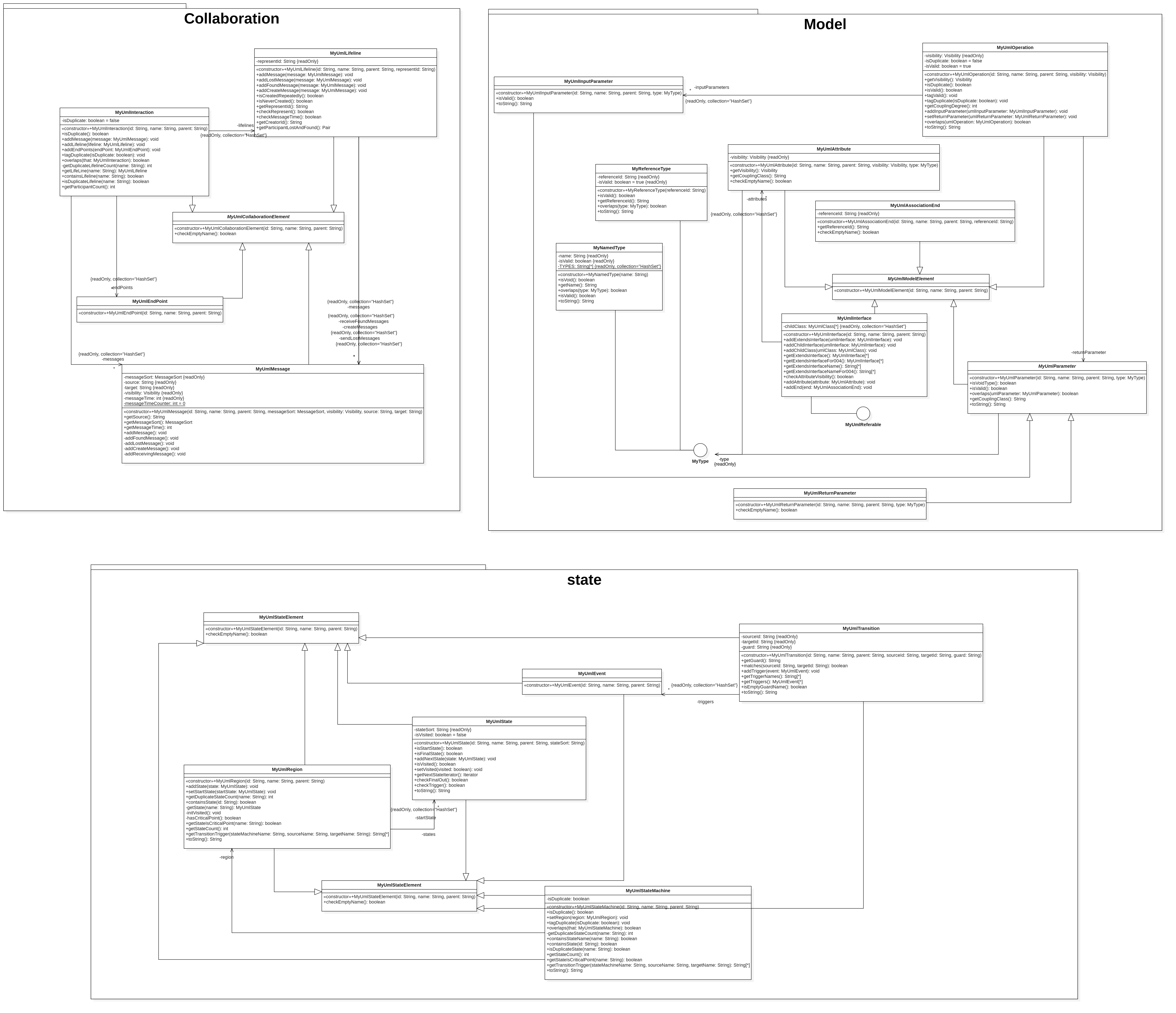
本单元要求实现UML解析器,其中输入元素是官方包中一个个的UmlElement与查询指令,输出是查询指令结果。第一次作业要求实现类图的查询,第二次作业新增实现顺序图查询,第三次作业增加了UML图异常检测。
根据同学们反映的情况,主流架构有两种。一是直接利用官方包的类,二是自己为每个UML元素新建自己的类。我采用了第二种架构,原因是官方UML元素中无法新增自己的属性与方法,并且包含了json文件的阅读方法,不简洁。到了第三次作业,我的架构形成了三个package,分别是Model,Collaboration,State,分别对应类图,顺序图,状态图。从架图上看,三个包中的类几乎没有耦合,这是因为UML图中这三类图本身具有独立性。
我的所有UML元素均继承自MyUmlElement,这是因为每个UML元素都有id,parent_id,name三个属性。在第三次作业中,我还为每个包增加了一个父类。具体地,Model中所有元素(除MyType,MyReference,MyNamedType)都继承自MyUmlModelElement,Collaboration中每个元素都继承自MyUmlCollaborationElement,State包中每个元素都继承自MyUmlStateElement,而MyUmlModelElement,MyUmlCollaborationElement,MyUmlStateElement都继承自MyUmlElement。这样设计可以分别归纳各类UML图元素的共性。
三次作业中需要算法的指令是关键状态判定与循环继承检测,前者是简单的DFS,后者是更复杂的DFS。对于后者,我在网上看到了Johnson算法,但是由于自身能力有限,看了接近一天还是无法理解其中的高深奥义。不过通过对Johnson算法的学习,我倒是了解了简单版的环检测算法,Johnson算法只是降低了简单版算法的时间复杂度。
我在本单元的作业采用了单例模式。我有个MyIdSet,用于存放所有MyUmlElement,以及提供查询方法。这个类是单例的,大大降低了类之间的耦合度。
我还采用了工厂模式。在UserApi的构造方法中,我调用工厂接口,将官方UmlElement传入,在工厂中构造出自己的MyUmlElement,并将其放入MyIdSet。由于UmlElent元素众多,因此Factory中不可避免地涉及到大量if-else,但是这些UserApi只会看到一个简介的Factory接口。
第二章 oo理解
在寒假我便开始预习oo,当时我认为oo的思想是将数据与方法整合到一起。当时我写C语言时便有意识地使用结构体。我写了一个计算GPA的C程序,对每个学科的学分与分数,我没有用二维数组存放,而是用结构体存放。
到了pre,课程组要求所有属性都是private的,我初步理解了面向对象的封装思想(encapsulation)。
到了第一单元,我深刻体会到了面向对象多态的好处。多态很好地适应了表达式expression,term,factor,base递归的定义。我在base处采用多态,base既可以是expression,也可以是simple base,实现了expression-term-factor-base-……的有序递归。
到了第二单元,我理解了发送消息与函数调用的关系。在协作图中,发送消息就是调用消息接收者的方法。这一点在多线程中尤为明显。在寒假,我看《Java编程思想》时就遇到了类似表述,一直不理解,到第二单元终于理解了。
到了第三单元,我学习到了规格化设计。其中一点我受益颇深,就是对象状态时时刻刻都正确是程序正确的必要条件。为此我们需要引入状态检测方法repOK()来检查不变式。这个方法类似assert(),但是assert()只检查方法的局部范围,而repOK()检查整个对象状态。
到了第四单元,由于作业比较简单,我着重培养了自己的架构思维。从第一章的分析可见,我的架构耦合度低,可扩展性好,继承实现用得很巧妙,避免了大量if-else;同时我采用了单例模式,工厂模式等设计模式。
在第四单元我进一步理解了对象是数据与方法的集合。与C语言struct的用法类似,我在一个方法中定义了方法内部类,以实现数据整合与特定方法可见的全部变量,这是Java语法与面向对象思维的升华。
方法代码如下:
private HashSet<String> checkForUmlInterface003() {
class VertexState {
private boolean visited = false;
private boolean blocked = false;
public boolean canVisit() {
return !visited && !blocked;
}
}
class Dfs {
private final HashSet<String> resultIds = new HashSet<>();
private final Stack<MyUmlInterface> path = new Stack<>();
private final HashMap<MyUmlInterface, VertexState> vertices = new HashMap<>();
private MyUmlInterface root;
public void dfs(MyUmlInterface currentPoint) {
for (MyUmlInterface neighbor : currentPoint.getExtendsInterface()) {
if (neighbor.equals(root)) {
for (MyUmlInterface pathPoint : path) {
resultIds.add(pathPoint.getId());
}
} else if (vertices.get(neighbor).canVisit()) {
vertices.get(neighbor).blocked = true;
path.push(neighbor);
dfs(neighbor);
}
}
path.pop();
vertices.get(currentPoint).blocked = false;
}
public HashSet<String> calculate() {
for (MyUmlElement element : elements.values()) {
if (element instanceof MyUmlInterface) {
vertices.put((MyUmlInterface) element, new VertexState());
}
}
for (MyUmlInterface root : vertices.keySet()) {
this.root = root;
vertices.get(root).blocked = true;
path.push(root);
dfs(root);
vertices.get(root).visited = true;
}
return resultIds;
}
}
return new Dfs().calculate();
}
其中VertexState类记录了节点(MyUmlInterface)的状态,这样可以避免在MyUmlInterface中定义节点状态。Dfs用于提取图中的环,可以实现递归调用的dfs()方法共享全局变量,避免把全局变量定义在普通的类(MyIdSet)中。二者都是在第三单元基础上的进步。
第三章 测试演进
第一单元我的测试水平承接了上学期计算机组成的测试水平。我用C语言生成数据,用python的sympy库检查,数据生成逻辑与检查逻辑都很简单。我的收获有以下三点:
-
学会了sympy库函数的使用
-
评测机中设置可以调节的参数,控制数据生成规模
-
学会了在命令行使用javac编译.java程序,使用java运行.class文件
第二单元我用C++写了数据生成器与结果检查器。这一单元我的测试收获有:
-
巩固了C++语法
-
学会了使用Windows的bat脚本,大大方便了命令行评测
-
学会了打jar包,这比javac+java命令方便,并且节省时间
但是第二单元可惜的是,我只在第一次作业编写了评测机,后两次作业我嫌评测机的数据检查逻辑太麻烦了,抱着侥幸心理过了中测就没管了。结果第二次作业只有88分,第三次作业只有61分。
第三单元我被电梯最有一次作业的61分吓处心理阴影了,开始重视测试。第三单元数据生成简单,并且答案是唯一的。因此我自己写了C++数据生成器,然后用别人的jar包对拍。第三单元作业我只有第三次作业的dijkstra错了,并且这不是评测机能找到的错。
第三单元测试的收获有:
-
学会了bat脚本的进阶用法,如if,goto语句,能够一键100组数据,挂在后台运行,大大提高了效率
-
学会了部分C++STL容器,如vector,string,map的部分用法。
-
学会了模块化测试,我针对作业的每个功能要求,例如dijkstra,message,group都分别生成了数据,针对性大大增强。
-
学会了查看评测机数据生成质量,例如用专门的程序检测异常覆盖程度,进而调整评测逻辑。
-
意识到自己造边界数据的重要性。dijkstra的错误来自一字长蛇阵图没有被考虑到。事实上评测机很难通过随机生成数据构造如此特殊的图。
第四单元我的测试水平上了一个台阶:
-
C++水平再上台阶。我本次用C++面向对象的方式构造了数据,内含C++的继承,大量STL容器的使用,引用与指针的使用,return by value与return by reference的选择,new对象与栈空间对象的选择
-
第一次与其他人合作开发评测机。我只负责顺序图的数据生成,其他人负责类图,状态图数据的生成,对拍器搭建以及数据质量反馈的工作
-
学会了bat字符串的用法,能够通过bat脚本获取程序运行时间(只能精确到小数点后2位,因为bat不支持浮点数)
-
学会了在bat中调用其他bat的用法
-
学会了C/C++在控制台输出彩色内容
第四章 课程收获
-
学会了Markdown的使用
-
锻炼了presentation与PPT能力,在第一单元研讨课进行了27分钟的分享
-
重视测试,这是第二单元第三次作业61分的教训
-
合作,第四单元仅仅顺序图的数据生成器就达到了412行C++,类图+状态图更是达到了1200行python之巨,一个人干太难了
-
UML图:
-
超越了UML类图,例如UML顺序图,UML状态图
-
学会了UML图的结构,其中每个元素都是一个UML对象,以及UMLAssotiion,UMLAssociationEnd的含义
-
学会了画漂亮的UML图,例如ctrl+l快捷键将UML类如的线变成竖直与水平的,学会了画包图(上面的图就是)
-
-
重视架构,架构架得好,头发掉得少,第一单元我没有重构,就是因为第一单元架构很好
-
算法:
-
重温dijkstra,prim算法,还是堆优化的算法,实现数据结构课程的超越
-
重温堆,自己手动搭建了堆
-
学会了递归下降算法
-
学会了提取有向图所有环路的简单版算法
-
学会了并查集
-
第五章 课程建议
-
提高互测分值比例,不然大家到后期因为学业压力都不愿意互测了。
-
三单元的作业可以新增图论算法的指令,减少对算法要求不高的指令。目前第三单元考察了图的并查集,最短路径,最小生成树算法,其实还可以考察图的割点,环路等算法,这样可以提高我们的算法能力,同时不耽误JML的学习。第三单元是最简单的单元,是训练算法的好时机。
-
当提交不了hack数据时,显示数据不合法的原因。当前hack数据提交不上去时,只会说数据不合法,并不能知道具体不合法的原因。
-
希望前几次上机实验不要局限于黑盒测试,而是像后几次上机一样,按照空给分。上机实验通常就10多个空,有时候一个空错误就会导致黑盒数据点全错,这样扣完分数的话其实不太合理。如果按照空给分不太方便,希望对于错了很多个数据点的同学,老师助教们能手动查一下同学们填写的空。

