
C++初始化列表各情况分析
今天回顾了下C++初始化列表的知识,接下来我对这一知识作一总结。
我们在定义了一个类的时候,需要对类的成员进行初始化。关于初始化,有两种方法,一种在初始化列表中进行,另一种就是在构造函数中进行,对于这两种情况,各有各的使用场合,接下来先说说在什么情况下优先使用初始化列表。
第一种情况:当类中含有引用时,必须要在初始化列表中对数据成员进行绑定。
如下代码所示:
1 #include<iostream> 2 using namespace std; 3 class Base 4 { 5 private: 6 int &data; 7 public: 8 Base(int &temp):data(temp) 9 {} 10 //Base(int &temp) {data=temp;} 11 };
分析:
类的构造过程是在初始化列表中进行的,对应于第八行,到了第九行,其实构造就已经结束了,换句话说也就是Base这个对象已经产生了,接下来如果写data=temp就是赋值的行为了,但是对于引用来说,必须在对象进行创建的时候进行绑定,所以,他初始化的机会仅有一次,那就是在初始化列表中。
第二种情况,有常量类型的数据成员时,必须在初始化列表中进行初始化,如下图:
1 #include<iostream> 2 using namespace std; 3 class Base 4 { 5 private: 6 const int data; 7 public: 8 Base(int &temp):data(temp){} 9 };
第三种情况:类Derive继承了类Base,而在类Base中,含有带参数的构造函数,那么在类Derive中,必须在初始化列表中显示的调用类Base的构造函数,如下代码:
1 #include<iostream> 2 using namespace std; 3 class Base 4 { 5 public: 6 Base(int x){} 7 }; 8 class Derive:public Base 9 { 10 public: 11 Derive():Base(4) 12 {} 13 };
对于这种情况说明一下,在第11行的时候,如果基类Base的构造函数有默认的话,那么改行如果不显示调用基类Base的构造函数,编译器也会为其合成一个出来,只是参数是默认的而已,如果想要自己定义的数据,还是必须显示的调用才行,如下代码:
1 #include<iostream> 2 using namespace std; 3 class Base 4 { 5 public: 6 Base(int x=0){} 7 }; 8 class Derive:public Base 9 { 10 public: 11 Derive() /*:Base(4)*/ 12 {} 13 };
第四种情况:当一个类A中含有另外一个类B,且另外一个类B含有带参数的构造函数,那么该类A要在初始化列表中对类B进行显示的构造。(和第三种情况类似,只是一个包含,一个继承)。
1 #include<iostream> 2 using namespace std; 3 class Base 4 { 5 private: 6 int data; 7 public: 8 Base(int temp):data(temp){} 9 }; 10 class Derive 11 { 12 private: 13 Base b; 14 public: 15 Derive(int x):b(x) {} 16 };
接下来分析一下为什么要这么做,他有什么好处,请看以下代码:
1 #include<iostream> 2 using namespace std; 3 class Base 4 { 5 public: 6 Base(int temp = 0) 7 { 8 cout << "调用了构造函数:" << this << endl; 9 } 10 Base(const Base& another) 11 { 12 cout << this<<"调用了拷贝构造函数:" << &another << endl; 13 } 14 Base& operator=(const Base& another) 15 { 16 cout << this<<"调用了拷贝赋值运算符:" << &another << endl; 17 return *this; 18 } 19 ~Base() 20 { 21 cout << "调用了析构函数" << endl; 22 } 23 }; 24 class Derive 25 { 26 private: 27 Base b; 28 public: 29 Derive(int x=0) 30 { 31 b=x; 32 } 33 }; 34 int main() 35 { 36 Derive d; 37 return 0; 38 }
输出:
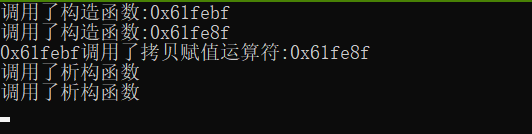
如果在初始化列表中对对象进行初始化,如下代码:
#include<iostream> using namespace std; class Base { public: Base(int temp = 0) { cout << "调用了构造函数:" << this << endl; } Base(const Base& another) { cout << this<<"调用了拷贝构造函数:" << &another << endl; } Base& operator=(const Base& another) { cout << this<<"调用了拷贝赋值运算符:" << &another << endl; return *this; } ~Base() { cout << "调用了析构函数" << endl; } }; class Derive { private: Base b; public: Derive(int x=0):b(x){} }; int main() { Derive d; return 0; }
输出: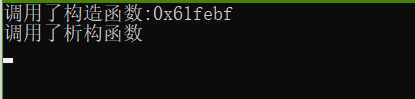
为什么性能相差如此之大?编译器为我们做了什么?
分析:
1 class Derive 2 { 3 private: 4 Base b; 5 public: 6 Derive(int x=0) 7 { 8 b=x; 9 } 10 };
第六行是一个初始化列表,前面说过,类的定义是在这里完成的,如果有默认,自己不显示调用,编译器也会主动为我们调用。这就是第六行的作用,所以不管我们掉不调用,都会有构造函数生成,
接下来到了函数体里面,这个对象就已经存在了,如果对这个对象进行操作,那就不是刚开始的初始化了。这里b=x,b在第六行已经创建好了,因为类Base中含有一个参数的构造函数,所以x会被隐式的转化,因此接下来调用还是构造函数,接下来就是赋值行为了,调用了赋值运算符。相比于在初始化列表中对对象进行初始化,在这里前者效率体现的淋漓尽致。
所以含有类成员时, 尽量能在初始化列表中初始化的都在初始化列表中进行。
但是对于一些基础类型,在效率上相差不大,两种方法都可以,但还是建议在初始化列表中进行,显得高端大气,上档次。
初始化列表也不是在任何情况下都是最好的,比如,请看一下代码:
#include<iostream> using namespace std; class Derive { private: int x; int y; public: Derive(int data):y(data),x(y){ cout<<"x:"<<x<<endl; cout<<"y:"<<y<<endl; } }; int main() { Derive d(3); return 0; }
如果运行的话,得到的值可能与你想要的相差甚远,运行效果如下:

原因分析:
初始化列表中对象构造的顺序也是有讲究的,他是依据类数据成员定义的顺序,并不是依据初始化列表中的顺序,上面类成员数据的顺序是先x再y,但是初始化列表中是先y后x,所以最后得出的数据可能并不是我们所期望的。
