


Python核心编程——正则表达式
本篇博客都是我认真读之后写的,有些地方和书上的语句一样……
1、简介
正则表达式为高级的文本模式匹配、抽取、与/或文本形式的搜索和替换功能提供了基础。简单地说,正则表达式(简称regex)是一些由字符和特殊符号组成的字符串,他们描述了模式的重复或者表述多个字符,于是正则表达式能按照某种模式匹配一系列有相似特征的字符串。换句话说,他们能匹配多个字符串……一种只能匹配一个字符串的正则表达式模式是很乏味并且毫无作用的,不是吗?
Python通过标准库中的re模块来支持正则表达式。
2、特殊符号和字符
以下是最常见的特殊符号和字符,即所谓的元字符,正式它给予正则表达式强大的功能和灵活性。


3、使用择一匹配符号匹配多个正则表达式模式
表示择一匹配的符(|)管道符 ,键盘上的竖线,表示一个“从多个模式中选择其一”’的操作。用于分割不同的表达式。个人理解
n选一比如bat|bet|bit选择其中一个。
4、匹配任意单个字符
点号或者句点(.)符号匹配除了换行符以外的所有字符,无论字母、数字、空格、可打印字符、不可打印字符,还是一个符号,
使用点号都能够匹配。当我们需要匹配点号的时候只需要转义一下,例如“\.”
当我们想要匹配换行符的时候,就需要使用Python给我们提供的标记【S或者DOTALL】

5、从字符串起始或者结尾或者单词的边界开始匹配
如果要匹配字符串的开始位置就需要使用脱字符(^)或者特殊字符“\A”。后者主要用于那些没有脱字符的键盘。同样$符号或者
“\Z”将用于匹配字符串的结尾。

如果想要匹配特殊字符中的任意一个就需要使用转义字符。比如匹配美元符号结尾的字符串:“.*\$$”
特殊字符\b 和\B 用于匹配字符边界。二者的区别主要是 \b 用于匹配一个单词的边界,也就是一匹配的字符串作为开始。当两个
\b...\b时就会仅仅匹配字符串的内容而不强调必须以字符串开头。\B则是匹配包含字符串但是不以字符串作为起始的字符串。

6、创建字符集
某些时候我们想要匹配一些特定的字符这个时候“.”就不起作用了,因此创造了方括号([ ])。该正则表达式能够匹配一对方括号
中包含的任意一个字符。此时方括号中的每一个字符都是独立的。

对于单个字符的正则表达式,择一匹配和字符集是等效的(没闹清楚,还在想)关于匹配‘ab’且后边跟着‘cd’的匹配为什么是“ab|cd”
7、限定范围或否定
除了单个字符以外,字符集还支持匹配制定字符范围。方括号中两个符号中间用连字符(-)链接,用于指定一个字符的范围。例如:
A-Z表示大写字母A-Z,0-9表示匹配数字0-9。如果脱字符(^)在方括号中表示不匹配括号中的任意一个字符。

8、使用闭包操作符实现存在性和频数匹配(?,+,*,{})
?表示前面的字符出现1次或者0次(如果?跟在任何使用闭包操作符的后面,则表示该操作符匹配尽可能少的次数)
+表示前面的字符出现1次或者多次
*表示前面的字符出现0次或者多次
{}里面或者是单个值或者是一堆逗号分割开的值。比如{N}表示匹配前面的正则表达式N次,{M,N}则是匹配M到N次
默认正则表达式是匹配尽可能多的字符,但是?可以让正则表达式尽可能的减少匹配的字符,留下更多的字符给后面的模式。
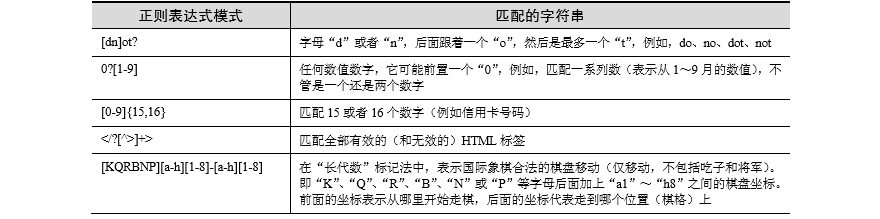
9、表示字符集的特殊字符
\d表示匹配任何十进制数字
\w表示匹配全部字母数字
\s表示匹配空格字符。
这些特殊字符的大写版本表示不匹配。

10.使用圆括号指定分组
使用圆括号对我们已经匹配的特定字符串或者子字符串进行提取。
当时用正则表达式时,一对圆括号实现以下任意一个功能:
1.对正则表达式进行分组
2.匹配子组
以下是书中的原话,看的有点乱,总感觉中文语法有问题……
关于为何想要对正则表达式进行分组的一个很好的示例是:当有两个不同的正则表达式 而且想用它们来比较同一个字符串时。另一
个原因是对正则表达式进行分组可以在整个正则 表达式中使用重复操作符(而不是一个单独的字符或者字符集)。 使用圆括号进行分组
的一个副作用就是,匹配模式的子字符串可以保存起来供后续使用。 这些子组能够被同一次的匹配或者搜索重复调用,或者提取出来用
于后续处理。1.3.9 节的结 尾将给出一些提取子组的示例。 为什么匹配子组这么重要呢?主要原因是在很多时候除了进行匹配操作以外,
我们还想 要提取所匹配的模式。例如,如果决定匹配模式\w+-\d+,但是想要分别保存第一部分的字母 和第二部分的数字,该如何实现?
我们可能想要这样做的原因是,对于任何成功的匹配,我 们可能想要看到这些匹配正则表达式模式的字符串究竟是什么。 如果为两个子
模式都加上圆括号,例如(\w+)-(\d+),然后就能够分别访问每一个匹配 子组。我们更倾向于使用子组,这是因为择一匹配通过编写代码来
判断是否匹配,然后执行另一个单独的程序(该程序也需要另行创建)来解析整个匹配仅仅用于提取两个部 分。为什么不让 Python 自己
实现呢?这是 re 模块支持的一个特性,所以为什么非要重蹈 覆辙呢?

11、正则表达式扩展表示
以问号作为开始,通常用于在判断匹配前提供标记,实现 一个前视或者后视匹配。只有(?P<name>)会创建一个分组,其余的都不会。

其实我总感觉这本书的中文翻译的语法有问题……
有些地方真的不合乎语法啊……
但是谁让我英文不好看不懂英文版……
唉……
接下来就是正则表达式在Python中的实现了,啦啦啦……
正则表达式re模块方法如下:
截图

1、匹配对象以及group()和groups()方法
匹配对象是re.match()和re.search()方法返回的对象。主要有两个方法:
group():返回整个匹配对象根据要求返回特定子组
groups():仅返回一个包含唯一或者全部子组的元组,当group()返回整个匹配时groups()返回一个空元组
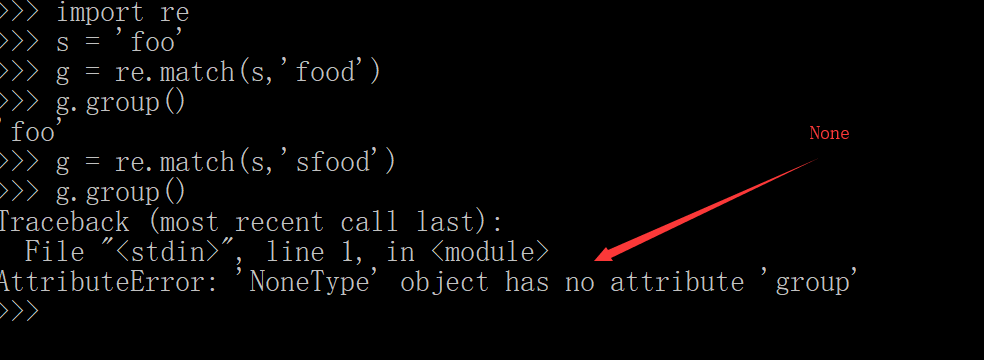
2.re,match()方法匹配字符串
match()方法从字符串的起始部分开始匹配。如果成功就返回一个匹配对象,否则返回none。用group()方法获得返回的匹配对象。
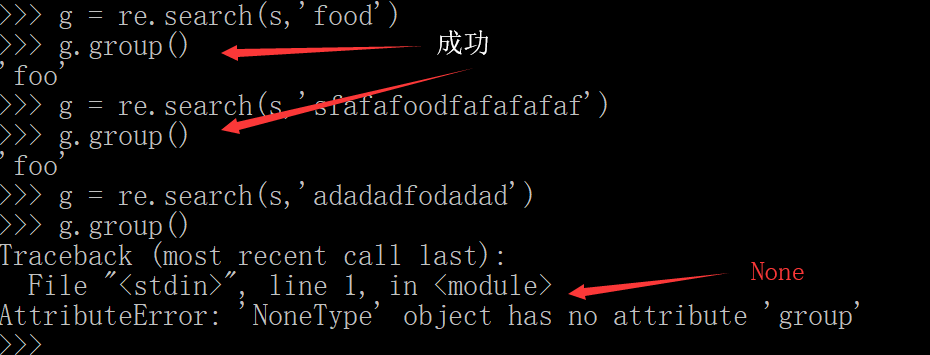
3、使用search()方法在一个字符串中查找
search的工作方式与match相同,只不过search会用他的字符串参数,在任意位置对给定的正则表达式搜索第一次出现的皮匹配情况。如果
搜索成功就返回一个匹配
对象,如果搜索失败就返回None
4、group()和groups()方法的使用
group()方法显示所有的匹配部分,但也能用于获取各个匹配的子组。
groups()方法获取一个包含所有匹配字符串的元组
import re
m = re.match("(\w\w\w)-(\d\d\d)",'abc-123')
print('m.group()-->',m.group())
print('m.group(1)-->',m.group(1))
print('m.group(2)-->',m.group(2))
print('m.groups()-->',m.groups())
m.group()--> abc-123
m.group(1)--> abc
m.group(2)--> 123
m.groups()--> ('abc', '123')
match.groupdict()返回一个字典,key是分组的名字,值为对应的分组匹配串。如果分组没有匹配,值为default,用法与match.groups()相同.例如:


1 regex = re.compile(r'(?P<first>hello)~(?P<second>world)-?(?P<name>\w+)?') 2 match = regex.search('hello~world') 3 match.groupdict() # name没有匹配对应的值为None 4 {'first': 'hello', 'name': None, 'second': 'world'}
5、使用findall() 和 finditer()查找每一次出现的位置
findall():查询字符串中某个正则表达式模式全部的非重复出现的情况。匹配成功结果返回一个列表 ,匹配失败结果返回空列表。
finditer():查询字符串中某个正则表达式模式全部的非重复出现的情况。匹配成功返回一个迭代器。用__next__()。group()方法读取
1 '''#返回的是一个包含所有子组组成的元组的列表 2 [('abc', '123'), ('xyz', '456')] 3 ''' 4 m = re.findall("(\w\w\w)-(\d\d\d)",'abc-123 xyz-456') 5 print(m)
1 m = re.finditer("(\w\w\w)-(\d\d\d)",'abc-123 xyz-456') 2 3 print(m.__next__().group()) 4 print(m.__next__().group())#返回的是一个迭代器
6、使用sub()和subn()搜索和替换
两者几乎一样,都是将某字符串中所有匹配正则表达式的部分进行某种形式的替换。但是subn返回一个表示替换的总数,
替换后的字符串和表示替换总数的数字一起作为一个拥有两个元素的元组返回
1 m = re.sub('[ae]','x','aeiou') 2 print(m) 3 m = re.subn('[ae]','x','aeiou') 4 print(m)
7、在限定模式上使用split()分隔字符串
re模块和正则表达式的对象方法split()对于相对应字符串的工作方式是类似的,但是与分割一个固定字符串相比,它们基于正则表达式的模式分割字符串。
1 data = ('monutain, CA 98000') 2 s = re.split(',|(?= (?:\d{5}|{[A-Z]{2}))',data) 3 print(s)
8、扩展符号
re.I(IGNORECASE)忽略大小写,括号内是完整的写法re.M(MULTILINE)多行模式,改变^和$的行为re.S(DOTALL)点可以匹配任意字符,包括换行符re.L(LOCALE)做本地化识别的匹配,不推荐使用re.U(UNICODE)使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flagre.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释
不区分大小写:
>>> re.findall(r'(?i)yes','yes,Yes,YeS') ['yes', 'Yes', 'YeS'] >>>
多行模式:
1 >>> s = '''the is that lala 2 ... this is that 3 ... is the that''' 4 >>> re.findall(r'(?im)(^th[\w ]+)',s) 5 ['the is that lala', 'this is that'] 6 >>>
(?:...) :通过使用该符号可以对部分正则表达式进行分组但是不保存。
1 >>> g = re.findall('(?:"t")|h','this is That') 2 >>> g 3 ['h', 'h'] 4 >>> 5 保存了字母h 但是没有保存t
9、贪婪模式与非贪婪模式
一般情况下是默认为贪婪模式,这种情况下匹配尽可能多的字符。非贪婪模式则相反,匹配尽可能少的字符。如:
>>> pt = re.compile(r'ab*?') >>> pt.match("abbbc") <_sre.SRE_Match object; span=(0, 1), match='a'>#非贪婪模式尽可能少的匹配 >>> pt2 = re.compile(r'ab*') >>> pt2.match("abbbc") <_sre.SRE_Match object; span=(0, 4), match='abbb'> >>>

