

编译原理 — 用Flex构造词法分析器
| 基于Flex构造词法分析器
【问题描述】设计c语言常见单词的正规式,编制lex源文件,利用flex编译得到词法分析的.c文件,继而对该文件编译得到词法分析器。 【输入形式】输入一段c语言程序 【输出形式】各类单词的token字,或者给出程序中的单词错误。 【样例输入】 int main(){ int a = 10; double b = 20.9; if(a <= b) a+=b; else a = 0; return a; }
【样例输出】 line1:(type, int) line1:(keyword, main) line1:(bracket, () line1:(bracket, )) line1:(bracket, {) line2:(type, int) line2:(identify, a) line2:(OPT, =) line2:(integer, 10) line2:(bracket, ;) line3:(type, double) line3:(identify, b) line3:(OPT, =) line3:(decimal, 20.9) line3:(bracket, ;) line4:(keyword, if) line4:(bracket, () line4:(identify, a) line4:(OPT, <=) line4:(identify, b) line4:(bracket, )) line5:(identify, a) line5:(OPT, +=) line5:(identify, b) line5:(bracket, ;) line6:(keyword, else) line6:(identify, a) line6:(OPT, =) line6:(integer, 0) line6:(bracket, ;) line7:(keyword, return) line7:(identify, a) line7:(bracket, ;) line8:(bracket, })
【样例说明】需要识别的关键字包括void, int, main, double, return, float, if, else, do, while, for, scanf, printf, char, sqrt, abs, 运算符(算术、关系、逻辑、位);需要识别的其他单词有标识符, 整数(十进制形式、指数形式),实数(十进制形式、指数形式),字符串;过滤注释及空格。 【评分标准】根据设计文档的质量、lex文件的正确性,代码的正确性、代码的时间空间复杂度、识别单词的种类等综合评分 |
flex就简单学了一下,最后看了别人的代码,模仿着写了一个。
.I文件
/*e.l*/
%option main
%option yywrap
%{
#include <stdio.h>
#include <string.h>
int Row=1;
char *Ans = "";
%}
KeyWord("main"|"double"|"return"|"float"|"if"|"else"|"do"|"while"|"for"|"scanf"|"printf"|"char"|"sqrt"|"abs"|"float")
OPT ("+"|"-"|"%"|"*"|"/"|"+="|"-="|"*="|"/="|">"|"<"|"<="|">="|"=="|"="|"&"|"\|"|"!"|"<<"|">>")
Identify ({Letter}|_)({Letter}|_|{Digit})*
Digit [0-9]
UnsignedInteger [1-9]{Digit}*
Integer ("+"|"-")?{Digit}+("e"(("+"|"-"){UnsignedInteger})?)?
Decimal {Integer}.{Digit}+
Float {Integer}.{Digit}+("e"(("+"|"-"){UnsignedInteger})?)?
Letter [a-zA-Z]
Comment ("/*"|"*").*
Type ("int"|"double"|"short"|"char"|"void"|"long")
Bracket ("("|")"|"{"|"}"|"["|"]"|";"|","|"\"")
Typeidentity ("%"|"&")[a-z]
Next("\n")
%%
{Type} {
AddOutput(Row, "type", yytext);
}
{KeyWord} {
AddOutput(Row, "keyword", yytext);
}
{OPT} {
AddOutput(Row, "OPT", yytext);
}
{Identify} {
AddOutput(Row, "identify", yytext);
}
{Integer} {
AddOutput(Row, "integer", yytext);
}
{Decimal} {
AddOutput(Row, "decimal", yytext);
}
{Float} {
char *p = strchr(yytext, 'e');
if (p && yytext[strlen(yytext)-1] == 'e'){
printf("Error at Line %d: Illegal floating point number \"%s\".\n",Row,yytext);
return;
} else {
AddOutput(Row, "float", yytext);
}
}
{Next} {++Row;}
{Typeidentity} {
AddOutput(Row, "typeidentify", yytext);
}
{Bracket} {
AddOutput(Row, "bracket", yytext);
}
{Comment} {}
. {}
%%
int yywrap()
{
printf("%s", Ans);
return 1;
}
void AddOutput(int Row, char* type, char* text){
char str[50];
sprintf(str, "line%d:(%s, %s)\n", Row, type, text);
char *tmp = Ans;
Ans = (char *) malloc(strlen(tmp) + strlen(str) + 1);
sprintf(Ans, "%s%s", tmp, str);
if(strlen(tmp) > 0)
free(tmp);
return ;
}
把这个文件拖到 win_flex.exe 生成 lex.yy.c
第一题(得分1.00)
一开始没有接触过Flex工具,通过老师推荐的教程《flex与bison》对它有了大致的了解,做了几个书上的案例,结合CSDN上完成词法分析器的教程,完成了第一题。
Lex源文件很大一部分都是抄书上和教程上的,但因为学Lex的时间太短了,对于这个Lex的一些语句还不是特别理解,只是勉强能解决简单的词法分析任务,并不清楚Lex内函数的实现细节。
使用Lex来完成词法分析任务能大大减少我们的工作量。源文件仅仅使用了八十多行代码就完成了任务,相对于自己手写的两百行代码,极大的降低了任务的复杂度。更重要的是通过lex生成的代码质量高,可靠性好,比手写词法分析器产生的Bug应该会少一些。
但这并不意味着手写代码就不如Lex生成的代码。因为Lex生成的lex.yy.c文件有一千九百行,很不方便程序员对代码进一步修改,并且并不是每个人都很清楚函数的实现细节,如果真的出现Bug,对于普通人来说很难解决。
虽然通过了四组测试案例,但是还是有一些问题没有解决:
1.关键字和数据类型的问题没有解决。
在样例中可以看到,Int属于type类型,而float属于keyword类型。对于这种既是数据类型,又是关键字的词,题干中没有明确说明如何划分。
2. 我设置的小数类型是这样的
Decimal {Integer}.{Digit}+,
但在我自己测试的时候出现了这样的问题,他把20-1识别成了一个小数。
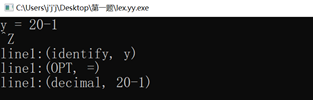
图一 存在的BUG1
3. 我设置的整数类型是这样的
Integer ("+"|"-")?{Digit}+("e"(("+"|"-"){UnsignedInteger})?)?
可是测试的时候把2e3识别成了小数

图一 存在的BUG2
