论文总结
论文总结
DDPM
stable diffusion
Transformer,Bert
Bert
Bert疑难解析
BERT中的NSP(Next Sentence Prediction)任务是有监督学习。原因在于,NSP任务需要明确的标签来训练模型,而这些标签是通过对语料库进行特定预处理生成的。
具体解释:
- 任务定义:NSP任务要求模型判断两句话之间是否存在上下文连续关系。给定两句话 和 ,模型需要预测 是不是紧接在 后的一句话。
正例:从原始文本中连续抽取的句子对(上下文连续)。
负例:从文本中随机抽取的非连续句子对(上下文不连续)。 - 训练数据生成:
NSP任务的训练数据通过标注生成:
对于正例,直接从语料库中取连续的两句话,标签为“1”(是下一句)。
对于负例,随机选取其他句子作为第二句,标签为“0”(不是下一句)。
这些标签明确地为模型提供了监督信号。 - 监督学习特性:
监督学习的关键特性是有标签的数据。在NSP任务中,正负例的标签(1或0)为模型提供了明确的学习目标,因此NSP是典型的有监督学习任务。
损失函数(如交叉熵损失)在训练时会根据这些标签来指导模型优化。 - 与无监督学习的区别:
无监督学习通常不依赖于明确的标签,例如BERT的MLM(Masked Language Model)任务,通过遮盖部分单词并让模型预测这些单词的方式实现训练。
NSP任务明确地依赖标注(正例和负例标签),因此属于有监督学习。
总结来说,虽然BERT整体被称为“预训练”模型,很多时候被误解为无监督学习,但实际上BERT的NSP任务是有监督学习的一部分。
原始的Transformer编码器(Encoder)部分确实可以看作是双向的,因为它通过自注意力机制(Self-Attention)让每个词在生成自己的表示时能够关注句子中的所有其他词,包括前文和后文。然而,仅仅有自注意力机制并不一定使模型充分利用双向信息,真正意义上的“双向性”还需要明确的训练目标(如MLM)来实现上下文的语义建模。
以下详细讨论为什么原始Transformer可以算作双向的,以及为什么需要额外任务(如MLM)来真正发挥其双向能力:
-
原始Transformer编码器中的双向性
自注意力机制如何捕捉双向信息: -
计算全局上下文相关性:
自注意力机制中,每个单词生成自己的 、、 表示,并计算自己与所有其他单词的相关性(即注意力权重)。
注意力机制对序列中所有单词的关系建模时,并不区分左侧或右侧,这使得它能够捕获全局的上下文信息。 -
并行处理所有词:
Transformer的编码器处理句子时,是一次性处理整个句子,而不是逐步处理。这种并行处理方式使得每个词的表示能够同时融合前文和后文的信息。
举例:
假设输入句子是:The cat sat on the mat.
对于单词“sat”,自注意力机制会计算其与“cat”、“on”、“the mat”等词的注意力权重。
最终,“sat”的表示不仅包含了“cat”的信息(前文),也包含了“on the mat”的信息(后文),从而实现了对双向上下文的建模。
因此,原始Transformer编码器确实具备双向上下文的建模能力 -
原始Transformer的双向性局限
尽管原始Transformer编码器通过自注意力机制捕获了双向上下文,但如果没有明确的训练目标,模型可能无法有效地学习到双向语义关系。其原因如下:
(1)缺乏特定的语言建模目标
自注意力机制捕获的是词与词的相关性,但这只是一个技术手段,并不直接约束模型去理解语言中的上下文语义。
如果没有训练目标(如MLM)引导,模型可能学到的是无意义的相关性,而不是语义上有用的信息。
(2)无法捕捉上下文的特定依赖关系
例如,在句子“The bank approved the loan”中,“bank”可以有多个含义。如果没有一个明确的训练目标(如遮盖任务要求模型预测“bank”),模型可能难以学会如何利用“approved the loan”来消解歧义。
(3)单向模型与生成任务的适配性问题
如果原始Transformer用于生成任务(如GPT),编码器的双向特性并不会自动传递到解码器,解码器生成时通常只能依赖左侧上下文,而不是全局信息。 -
BERT如何充分利用双向性
BERT引入了MLM(Masked Language Model)任务,这一训练目标使其真正成为一个双向语言模型:
MLM通过随机遮盖单词(如15%的词)并要求模型预测这些单词,迫使模型在预测时综合利用被遮盖词两侧的上下文信息。
相比原始的Transformer,MLM明确要求模型去理解和利用双向信息,这让BERT在下游任务(如分类、问答)中表现优异。
举例:
输入句子:The [MASK] is barking loudly.
模型需要预测“[MASK]”,可能是“dog”。
为此,模型必须综合利用:
前文“The”,表明“[MASK]”可能是一个名词。
后文“is barking loudly”,进一步指示“[MASK]”应是“dog”。
通过MLM任务,BERT确保了其双向机制不仅仅是技术上的支持,而是任务驱动的优化。 -
为什么原始Transformer不直接用于双向语言模型?
虽然原始Transformer编码器是双向的,但其原设计目的并不是语言模型,而是用于机器翻译等任务,具体的限制包括: -
缺乏语言建模的目标:
Transformer编码器的目的是对输入序列生成高质量的表示,而不是直接进行语言建模(如预测词序列)。 -
不能单独使用编码器进行生成任务:
原始Transformer在机器翻译中是一个编码器-解码器架构。编码器的双向特性无法直接传递到解码器,解码器的生成仍然是单向的。 -
无监督学习的缺乏:
原始Transformer需要大量标注数据,而BERT通过MLM任务实现了无监督学习,能够利用大量未标注语料进行训练。 -
对比:BERT与原始Transformer的双向能力
总结
原始Transformer编码器确实可以算是双向的,因为自注意力机制本质上是全局的,能够捕捉前后文信息。然而,双向性只是技术层面的潜力,真正让模型学习有意义的双向语义建模,还需要像MLM这样的训练目标。BERT通过结合双向Transformer编码器和MLM任务,不仅捕捉了上下文信息,还在任务驱动下优化了对语言的深度理解,这也是BERT显著优于原始Transformer在自然语言处理任务中的原因之一。
是的,原始Transformer的解码器(Decoder)可以看作是单向的,因为在生成过程中,它只使用左侧上下文(即已经生成的词)来预测当前词。这种单向性是通过自注意力机制中的掩码操作(Masked Self-Attention)实现的,以确保生成的词只能依赖于前文,而不能提前看到后文。
以下详细说明原始Transformer解码器为何是单向的:
- 原始Transformer解码器的结构
Transformer解码器由两种注意力机制组成:
- 掩码自注意力机制(Masked Self-Attention):
在解码器中,生成当前词时,掩码操作确保模型只能关注当前词之前的所有词,避免“偷看”未来的词。
这种机制通过对注意力权重矩阵添加一个上三角掩码(mask)实现,将后文的注意力分数置为负无穷,使得后文的影响为零。 - 编码器-解码器注意力机制(Encoder-Decoder Attention):
解码器的每个词都可以访问编码器输出的全部信息,这使得解码器能够结合源句子的全局信息进行翻译或生成。 - 掩码自注意力如何实现单向性
掩码操作:
在解码阶段,句子长度为 的输入序列对应的注意力矩阵是一个 的矩阵,每一行表示一个词对其他词的关注程度。
对于非掩码自注意力(如编码器中的自注意力),每个词可以看到整个句子的所有位置。
而在解码器中,掩码操作在计算注意力分数时,强制对后文的位置分数置为负无穷,从而确保模型只能利用已生成的词(左侧上下文)。
示例:
假设序列长度为 ,掩码自注意力的矩阵形式为:
\text{掩码矩阵} =
\begin{bmatrix}
1 & 0 & 0 & 0 \
1 & 1 & 0 & 0 \
1 & 1 & 1 & 0 \
1 & 1 & 1 & 1
\end{bmatrix}
这意味着:
第一个词只能看到自己。
第二个词可以看到第一个词和自己。
第三个词可以看到前两个词和自己。
以此类推。
效果:
掩码机制确保了解码器的自注意力是单向的(左到右),从而实现生成任务的因果性约束。
-
解码器的单向性与生成任务的关系
单向性的必要性:
生成任务(如机器翻译、文本生成)需要模型按顺序逐步生成文本,每生成一个词,当前预测需要基于已生成的上下文,而不能提前看到未来的词。这种单向性符合生成任务的因果逻辑。
举例
假设要生成句子“The cat sat on the mat”,解码器的生成流程如下: -
起始输入是特殊标记 "
"。 -
解码器生成第一个词“The”。
-
输入解码器的是“
+ The”,生成第二个词“cat”。 -
输入解码器的是“
+ The + cat”,生成第三个词“sat”。 -
如此依次递进,直到生成句尾标记 "
"。
在每个步骤中,解码器只能依赖已生成的词,单向的掩码自注意力确保这一点。 -
为什么解码器不使用双向性?
解码器的单向性设计是由生成任务的因果逻辑决定的: -
避免未来信息泄露:
如果解码器可以看到未来的词,就相当于模型在预测时已经“偷看”了答案,这违背了生成任务的要求。
掩码机制通过屏蔽后文,保证了生成过程中严格的因果顺序。 -
生成任务需要逐步生成:
生成任务需要模型在当前时刻依赖前文生成下一个词。这种逐词生成的逻辑与单向性设计完全一致。 -
任务目标不同:
编码器用于捕捉全局语义,适合使用双向上下文。
解码器用于生成文本,要求因果性,适合使用单向上下文。 -
单向性解码器的局限与改进
虽然单向性适合生成任务,但它也存在一些局限性:
对上下文的依赖较重:
解码器生成一个词时完全依赖前文,无法在生成阶段重新调整已生成的词。
长文本生成的难度:
单向生成任务可能在长文本中累积错误,导致上下文不一致。
改进:
一些模型通过增加双向机制的变种来提升生成任务的效果: -
双向编码器-解码器架构(如T5):
使用双向编码器捕捉全局信息,解码器则保持单向性。 -
非自回归生成模型:
模型通过一次性生成整个序列,避免逐词生成的问题。
总结
原始Transformer的解码器是单向的,这是通过掩码自注意力机制实现的。单向性设计符合生成任务的因果逻辑,确保每个词的预测只依赖于前文,不会泄露未来信息。相比之下,编码器是双向的,可以同时利用左侧和右侧上下文信息来捕捉全局语义关系。这种编码器-解码器的双向性与单向性组合,
使Transformer在理解和生成任务中都表现出色。
原始的注意力机制(Self-Attention)确实可以捕捉到上下文信息,但引入MLM任务的原因在于训练目标的不同。虽然注意力机制提供了一种捕捉上下文的技术手段,但它本身并不会告诉模型应该学习什么样的语义表示。以下是对这个问题的详细分析:
- 注意力机制的作用
原始的注意力机制(特别是自注意力,Self-Attention)是Transformer架构的核心,用于捕捉句子中各个词之间的相关性:
Q(Query)、K(Key)、V(Value):
每个单词生成自己的查询向量 ,键向量 ,和值向量 。
通过计算 和 的点积,得到每个词与其他词的注意力分数。
注意力分数对 进行加权,得到每个词的上下文表示。
效果:这种机制允许模型在计算每个单词的表示时,关注句子中的其他单词,从而捕捉上下文信息。 - 注意力机制的局限性
虽然注意力机制能够捕捉上下文信息,但它只是一种技术手段,并不提供明确的学习目标。模型的能力取决于训练任务所要求的优化方向:
(1)没有指导的学习目标
自注意力机制本身没有明确告诉模型哪些上下文信息是重要的。
如果没有具体的训练目标(如MLM任务),模型不会知道它需要学习哪些上下文关系对于语言理解是关键的。
(2)无法学习语义层次关系
注意力机制捕捉的是词与词之间的相关性,而不是更深层次的语义信息。例如,句子“The dog chased the cat”中,“dog”和“chased”之间的语义关系需要通过明确的训练目标引导模型去理解。
(3)对特定任务的适配能力有限
没有训练目标时,注意力机制捕获的上下文可能没有对准语言的实际语义规则,难以在实际任务中迁移。 - 为什么需要MLM?
MLM任务的引入弥补了注意力机制的这些局限性,提供了一种明确的目标,让模型在捕捉上下文时学习有用的语义信息:
(1)引明确的优化目标
MLM通过遮盖单词并要求模型预测它们的具体内容,明确要求模型去理解和利用上下文信息。
例如,句子“The [MASK] is barking”,模型为了预测“dog”,需要从“is barking”推断语义,并学习“dog”和“barking”之间的关联。
这种目标使得模型在训练过程中不断优化其对语言上下文的理解能力。
(2)强化上下文建模能力
注意力机制捕捉的是词与词的相关性,但MLM任务通过遮盖某些单词,迫使模型关注全局上下文,而不是仅仅依赖局部信息。
例如,在句子“The quick brown [MASK] jumps over the lazy dog”中,模型需要综合整个句子的语义,才能推断出被遮盖的词是“fox”。
(3)避免简单记忆和依赖
直接使用注意力机制可能导致模型过度依赖某些固定的模式或表面特征。而MLM随机遮盖部分单词,使得模型不能完全依赖固定的词序或搭配,需要灵活推断上下文含义。
(4)无标注学习的高效性
MLM任务是一种无监督学习方式,不需要人工标注。它通过随机遮盖的方式生成训练数据,能够充分利用大规模未标注的语料库。
-
MLM与注意力机制的协同作用
MLM任务和注意力机制在BERT中相辅相成:
注意力机制提供技术手段:捕捉词与词之间的关系,使模型可以灵活利用上下文。
MLM任务提供优化目标:指导模型学习哪些上下文关系是重要的,从而生成更加语义丰富的表示。
通过这两者的结合,BERT能够: -
捕捉句子中词语之间的全局依赖关系。
-
在理解层面上更好地掌握语言的语义规则。
-
总结:为什么用MLM任务
虽然注意力机制可以捕捉上下文信息,但它是工具而非目标,缺乏对模型语义理解的明确引导。而MLM任务通过随机遮盖的方式提供了明确的训练目标:
强化模型利用上下文理解语义的能力。
避免过度依赖表面特征,提升泛化性能。
结合注意力机制,使模型能够高效地捕获和优化双向上下文的语义信息。
因此,MLM任务是为了让模型从注意力机制中学到更有意义的语言表示,并最终在多种自然语言处理任务中表现出色。
Vit
Vit
clip(1)
clip(2)
clip(3)
VAE
Q1:为什么在调整qϕ(z|x)来最大化Lb时,目标函数值不改变
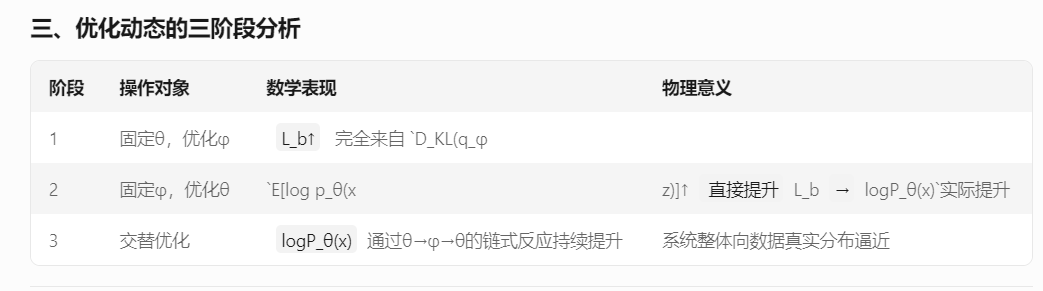
Q2:为什么要最大化目标函数的下界
logP(x) ≥ ELBO = E_{q(z|x)}[log p(x|z)] - D_KL(q(z|x)||p(z))
logP(x) = ELBO + D_KL(q||p) ≥ ELBO
当q(z|x)越接近真实后验时,KL散度越小,下界越接近真实logP(x)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号