Python爬虫 | Selenium详解
一、简介
网页三元素:
- html负责内容;
- css负责样式;
- JavaScript负责动作;
从数据的角度考虑,网页上呈现出来的数据的来源:
- html文件
- ajax接口
- javascript加载
如果用requests对一个页面发送请求,只能获得当前加载出来的部分页面,动态加载的数据是获取不到的,比如下拉滚轮得到的数据。selenium最初是一个自动化测试工具, 而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题。selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器。Selenium是python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作。
selenium在爬虫中的应用:
- 模拟登录
- 便捷的获取动态加载的数据
缺点:
- 爬取数据的效率底
- 环境部署繁琐
二、环境安装
- 下载安装selenium:pip install selenium
- 下载浏览器驱动程序:http://chromedriver.storage.googleapis.com/index.html
- 查看驱动和浏览器版本的映射关系: https://www.cnblogs.com/Summer-skr--blog/p/11715259.html
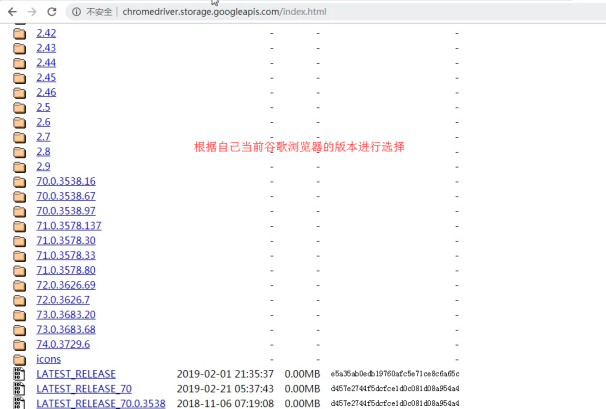
查看谷歌浏览器版本
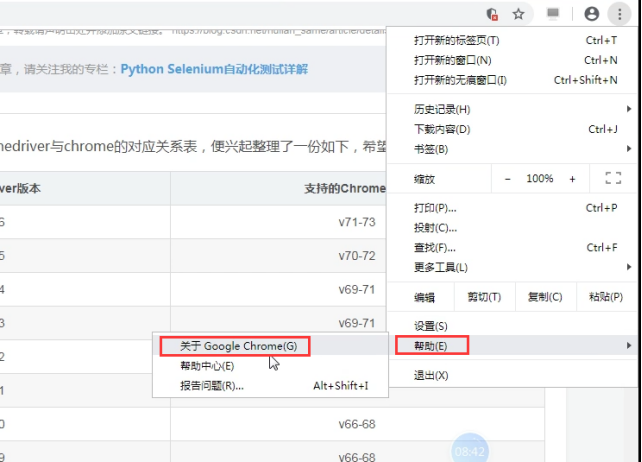
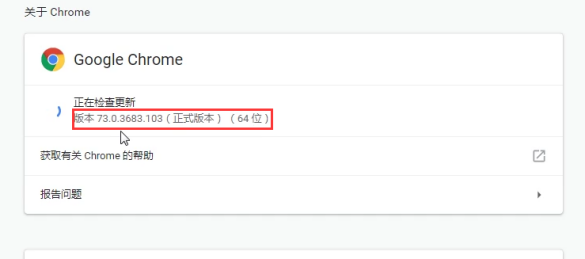
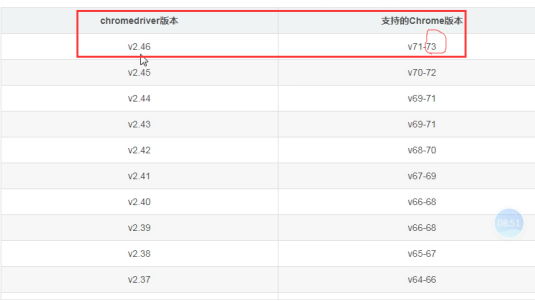
下载好以后,就有驱动程序了。
三、基本使用
1.浏览器创建
Selenium支持非常多的浏览器,如Chrome、Firefox、Edge等,还有Android、BlackBerry等手机端的浏览器。另外,也支持无界面浏览器PhantomJS。
from selenium import webdriver browser = webdriver.Chrome() browser = webdriver.Firefox() browser = webdriver.Edge() browser = webdriver.PhantomJS() browser = webdriver.Safari() browser.quit() # 关闭浏览器 browser.close() # 关闭当前页面
close 只会关闭当前窗口,而 quit 退出驱动并会关闭所有的窗口。
2.打开网页
browser.get(url) # 打开path路径 page_text = browser.page_source # 获取当前浏览器页面的源码数据
3.元素定位
查找一个元素(单节点)
element = find_element_by_id() element = find_element_by_name() element = find_element_by_class_name() element = find_element_by_tag_name() element = find_element_by_link_text() element = find_element_by_partial_link_text() element = find_element_by_xpath() element = find_element_by_css_selector()
查找多个元素(多节点)
element = find_elements_by_id() element = find_elements_by_name() element = find_elements_by_class_name() element = find_elements_by_tag_name() element = find_elements_by_link_text() element = find_elements_by_partial_link_text() element = find_elements_by_xpath() element = find_elements_by_css_selector()
注意:
(1)find_element_by_xxx第一个符合条件的标签,find_elements_by_xxx找的是所有符合条件的标签。
(2)根据ID、CSS选择器和XPath获取,它们返回的结果完全一致。
(3)另外,Selenium还提供了通用方法find_element(),它需要传入两个参数:查找方式By和值。实际上,它就是find_element_by_id()这种方法的通用函数版本,比如find_element_by_id(id)就等价于find_element(By.ID, id),二者得到的结果完全一致。
# 通过id定位 <html> <body> <form id="loginForm"> <input name="username" type="text" /> <input name="password" type="password" /> <input name="continue" type="submit" value="Login" /> </form> </body> <html> login_form = driver.find_element_by_id('loginForm')
# 通过name定位 <html> <body> <form id="loginForm"> <input name="username" type="text" /> <input name="password" type="password" /> <input name="continue" type="submit" value="Login" /> <input name="continue" type="button" value="Clear" /> </form> </body> <html> username = driver.find_element_by_name('username') password = driver.find_element_by_name('password')
# 通过链接文本定位 <html> <body> <p>Are you sure you want to do this?</p> <a href="continue.html">Continue</a> <a href="cancel.html">Cancel</a> </body> <html> continue_link = driver.find_element_by_link_text('Continue') continue_link = driver.find_element_by_partial_link_text('Conti')
# 通过标签名定位 <html> <body> <h1>Welcome</h1> <p>Site content goes here.</p> </body> <html> heading1 = driver.find_element_by_tag_name('h1')
# 通过类名定位 <html> <body> <p class="content">Site content goes here.</p> </body> <html> content = driver.find_element_by_class_name('content')
# 通过CSS选择器定位 <html> <body> <p class="content">Site content goes here.</p> </body> <html> content = driver.find_element_by_css_selector('p.content') # 推荐使用xpath定位 username = driver.find_element_by_xpath("//form[input/@name='username']") username = driver.find_element_by_xpath("//form[@id='loginForm']/input[1]") username = driver.find_element_by_xpath("//input[@name='username']")
4.节点操作
ele.text 拿到节点的内容 (包括后代节点的所有内容)
driver.find_element_by_id('gin').text
ele.send_keys("")搜索框输入文字
driver.find_element_by_id('kw').send_keys("Python")
ele.click()标签
driver.find_element_by_id('su').click()
ele.get_attribute("")获取属性值
# 获取元素标签的内容 att01 = a.get_attribute('textContent') # # 获取元素内的全部HTML att02 = a.get_attribute('innerHTML') # # 获取包含选中元素的HTML att03 = a.get_attribute('outerHTML') # 获取该元素的标签类型 tag01 = a_href.tag_name
5.动作链
from selenium.webdriver import ActionChains source = browser.find_element_by_css_selector('') target = browser.find_element_by_css_selector('') actions = ActionChains(browser) actions.drag_and_drop(source, target).perform() actions.release()
6.在页面间切换
适用与页面中点开链接出现新的页面的网站,但是浏览器对象browser还是之前页面的对象
window_handles = driver.window_handles
driver.switch_to.window(window_handles[-1])
7.保存网页截图
driver.save_screenshot('screen.png')
8.执行JavaScript
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
9.前进和后退
browser.back()
browser.forward()
10.等待
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Chrome() driver.get("http://somedomain/") try: element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "myDynamicElement")) ) finally: driver.quit()
条件


title_is
title_contains
presence_of_element_located
visibility_of_element_located
visibility_of
presence_of_all_elements_located
text_to_be_present_in_element
text_to_be_present_in_element_value
frame_to_be_available_and_switch_to_it
invisibility_of_element_located
element_to_be_clickable
staleness_of
element_to_be_selected
element_located_to_be_selected
element_selection_state_to_be
element_located_selection_state_to_be
alert_is_present
11.Cookie处理
获取、添加、删除Cookies
browser.get_cookies() browser.add_cookie({'name': 'name', 'domain': 'www.zhihu.com', 'value': 'germey'}) browser.delete_all_cookies()
12. 搜索属性值
- 获得element之后搜索
url = driver.find_element_by_name('t2').get_attribute('href')
- 页面源码中搜索
源码中搜索字符串,可以是文本值也可以是属性值 res = driver.page_source.find('字符串') 返回值 -1 未找到 其他 找到
13.谷歌无头浏览器
from selenium.webdriver.chrome.options import Options。 chrome_options = Options() chrome_options.add_argument('--headless') chrome_options.add_argument('--disable-gpu') browser = webdriver.Chrome(executable_path=path, chrome_options=chrome_options)
14.规避监测
相关的网站会对selenium发起的请求进行监测,网站后台可以根据window.navigator.webdriver返回值进行selenium的监测,若返回值为undefinded,则不是selenium进行的请求发送;若为true,则是selenium发起的请求。
规避监测的方法:
from selenium.webdriver import ChromeOptions option = ChromeOptions() option.add_experimental_option('excludeSwitches', ['enable-automation']) bro = webdriver.Chrome(executable_path='chromedriver.exe',options=option)
15. 切换子框架
此操作主要作用与 ifram子框架 的互相切换使用
iframe = driver.find_element_by_xxx('') driver.switch_to_frame(节点对象)
16. 不请求图片模式
只需要如下设置则不会请求图片, 会加快效率
chrome_opt = webdriver.ChromeOptions() prefs = {"profile.managed_default_content_settings.images": 2} chrome_opt.add_experimental_option("prefs", prefs)
四、鼠标键盘操作(ActionChains)
1. ActionChains基本用法
ActionChains的执行原理:当你调用ActionChains的方法时,不会立即执行,而是会将所有的操作按顺序存放在一个队列里,当你调用perform()方法时,队列中的时间会依次执行
有两种调用方法:
链式写法
menu = driver.find_element_by_css_selector(".nav") hidden_submenu = driver.find_element_by_css_selector(".nav #submenu1") ActionChains(driver).move_to_element(menu).click(hidden_submenu).perform()
分步写法
menu = driver.find_element_by_css_selector(".nav") hidden_submenu = driver.find_element_by_css_selector(".nav #submenu1") actions = ActionChains(driver) actions.move_to_element(menu) actions.click(hidden_submenu) actions.perform()
两种写法本质是一样的,ActionChains都会按照顺序执行所有的操作。
2. ActionChains方法列表
click(on_element=None) ——单击鼠标左键 click_and_hold(on_element=None) ——点击鼠标左键,不松开 context_click(on_element=None) ——点击鼠标右键 double_click(on_element=None) ——双击鼠标左键 send_keys(*keys_to_send) ——发送某个键到当前焦点的元素 send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素 key_down(value, element=None) ——按下某个键盘上的键 key_up(value, element=None) ——松开某个键 drag_and_drop(source, target) ——拖拽到某个元素然后松开 drag_and_drop_by_offset(source, xoffset, yoffset) ——拖拽到某个坐标然后松开 move_by_offset(xoffset, yoffset) ——鼠标从当前位置移动到某个坐标 move_to_element(to_element) ——鼠标移动到某个元素 move_to_element_with_offset(to_element, xoffset, yoffset) ——移动到距某个元素(左上角坐标)多少距离的位置 perform() ——执行链中的所有动作 release(on_element=None) ——在某个元素位置松开鼠标左键
3. 代码示例
(1)点击操作
# -*- coding: utf-8 -*- from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains from time import sleep driver = webdriver.Firefox() driver.implicitly_wait(10) driver.maximize_window() driver.get('http://sahitest.com/demo/clicks.htm') click_btn = driver.find_element_by_xpath('//input[@value="click me"]') # 单击按钮 doubleclick_btn = driver.find_element_by_xpath('//input[@value="dbl click me"]') # 双击按钮 rightclick_btn = driver.find_element_by_xpath('//input[@value="right click me"]') # 右键单击按钮 ActionChains(driver).click(click_btn).double_click(doubleclick_btn).context_click(rightclick_btn).perform() # 链式用法 print driver.find_element_by_name('t2').get_attribute('value') sleep(2) driver.quit()
element.get_attribute()获取某个元素属性
(2)鼠标移动
# -*- coding: utf-8 -*- from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains from time import sleep driver = webdriver.Firefox() driver.implicitly_wait(10) driver.maximize_window() driver.get('http://sahitest.com/demo/mouseover.htm') write = driver.find_element_by_xpath('//input[@value="Write on hover"]') # 鼠标移动到此元素,在下面的input框中会显示“Mouse moved” blank = driver.find_element_by_xpath('//input[@value="Blank on hover"]') # 鼠标移动到此元素,会清空下面input框中的内容 result = driver.find_element_by_name('t1') action = ActionChains(driver) action.move_to_element(write).perform() # 移动到write,显示“Mouse moved” print result.get_attribute('value') # action.move_to_element(blank).perform() action.move_by_offset(10, 50).perform() # 移动到距离当前位置(10,50)的点,与上句效果相同,移动到blank上,清空 print result.get_attribute('value') action.move_to_element_with_offset(blank, 10, -40).perform() # 移动到距离blank元素(10,-40)的点,可移动到write上 print result.get_attribute('value') sleep(2)
(3)拖拽
# -*- coding: utf-8 -*- from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains from time import sleep driver = webdriver.Firefox() driver.implicitly_wait(10) driver.maximize_window() driver.get('http://sahitest.com/demo/dragDropMooTools.htm') dragger = driver.find_element_by_id('dragger') # 被拖拽元素 item1 = driver.find_element_by_xpath('//div[text()="Item 1"]') # 目标元素1 item2 = driver.find_element_by_xpath('//div[text()="Item 2"]') # 目标2 item3 = driver.find_element_by_xpath('//div[text()="Item 3"]') # 目标3 item4 = driver.find_element_by_xpath('//div[text()="Item 4"]') # 目标4 action = ActionChains(driver) action.drag_and_drop(dragger, item1).perform() # 1.移动dragger到item1 sleep(2) action.click_and_hold(dragger).release(item2).perform() # 2.效果与上句相同,也能起到移动效果 sleep(2) action.click_and_hold(dragger).move_to_element(item3).release().perform() # 3.效果与上两句相同,也能起到移动的效果 sleep(2) # action.drag_and_drop_by_offset(dragger, 400, 150).perform() # 4.移动到指定坐标 action.click_and_hold(dragger).move_by_offset(400, 150).release().perform() # 5.与上一句相同,移动到指定坐标 sleep(2) driver.quit()
一般用坐标定位很少,用上例中的方法1足够了,如果看源码,会发现方法2其实就是方法1中的drag_and_drop()的实现。注意:拖拽使用时注意加等待时间,有时会因为速度太快而失败。
(4)按键
模拟按键有多种方法,能用win32api来实现,能用SendKeys来实现,也可以用selenium的WebElement对象的send_keys()方法来实现,这里ActionChains类也提供了几个模拟按键的方法。
# -*- coding: utf-8 -*- from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains from time import sleep driver = webdriver.Firefox() driver.implicitly_wait(10) driver.maximize_window() driver.get('http://sahitest.com/demo/keypress.htm') key_up_radio = driver.find_element_by_id('r1') # 监测按键升起 key_down_radio = driver.find_element_by_id('r2') # 监测按键按下 key_press_radio = driver.find_element_by_id('r3') # 监测按键按下升起 enter = driver.find_elements_by_xpath('//form[@name="f1"]/input')[1] # 输入框 result = driver.find_elements_by_xpath('//form[@name="f1"]/input')[0] # 监测结果 # 监测key_down key_down_radio.click() ActionChains(driver).key_down(Keys.CONTROL, enter).key_up(Keys.CONTROL).perform() print result.get_attribute('value') # 监测key_up key_up_radio.click() enter.click() ActionChains(driver).key_down(Keys.SHIFT).key_up(Keys.SHIFT).perform() print result.get_attribute('value') # 监测key_press key_press_radio.click() enter.click() ActionChains(driver).send_keys('a').perform() print result.get_attribute('value') driver.quit()
示例2:
# -*- coding: utf-8 -*- from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.common.keys import Keys from time import sleep driver = webdriver.Firefox() driver.implicitly_wait(10) driver.maximize_window() driver.get('http://sahitest.com/demo/label.htm') input1 = driver.find_elements_by_tag_name('input')[3] input2 = driver.find_elements_by_tag_name('input')[4] action = ActionChains(driver) input1.click() action.send_keys('Test Keys').perform() action.key_down(Keys.CONTROL).send_keys('a').key_up(Keys.CONTROL).perform() # ctrl+a action.key_down(Keys.CONTROL).send_keys('c').key_up(Keys.CONTROL).perform() # ctrl+c action.key_down(Keys.CONTROL, input2).send_keys('v').key_up(Keys.CONTROL).perform() # ctrl+v print input1.get_attribute('value') print input2.get_attribute('value') driver.quit()
五、使用示例
示例1:打开百度,搜索爬虫
from selenium import webdriver from time import sleep bro = webdriver.Chrome() bro.get(url='https://www.baidu.com/') sleep(2) text_input = bro.find_element_by_id('kw') text_input.send_keys('爬虫') sleep(2) bro.find_element_by_id('su').click() sleep(3) print(bro.page_source) bro.quit()
示例2:获取豆瓣电影中更多电影详情数据(谷歌无头浏览器)
from selenium import webdriver from time import sleep from selenium.webdriver.chrome.options import Options 第1步:下面三行固定 chrome_options = Options() chrome_options.add_argument('--headless') chrome_options.add_argument('--disable-gpu') url = 'https://movie.douban.com/typerank?type_name=%E6%83%8A%E6%82%9A&type=19&interval_id=100:90&action=' 第2步:把chrome_options对象作为参数 bro = webdriver.Chrome(chrome_options=chrome_options) bro.get(url) sleep(3) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') sleep(3) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') sleep(3) bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') sleep(2) page_text = bro.page_source with open('./douban.html','w',encoding='utf-8') as fp: fp.write(page_text) print(page_text) sleep(1) bro.quit()
示例3:登录qq空间
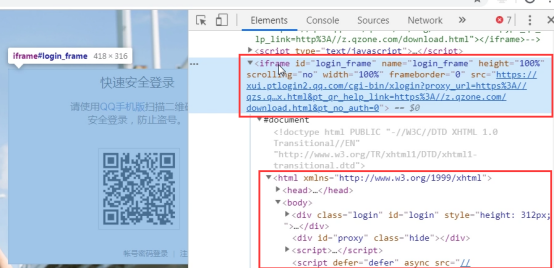
在web 中,经常会遇到frame 嵌套页面的应用,使用WebDriver 每次只能在一个页面上识别元素,对于frame 嵌套内的页面上的元素,直接定位是定位是定位不到的。这个时候就需要通过switch_to_frame()方法将当前定位的主体切换了frame 里。先定位到iframe,再在iframe中进行标签定位。否则,定位不到我们想要的标签。
import requests from selenium import webdriver from lxml import etree import time driver = webdriver.Chrome(executable_path=r'C:\Users\Administrator\chromedriver.exe') driver.get('https://qzone.qq.com/') #switch_to操作切换frame,此时才能进行登陆页面的操作。 driver.switch_to.frame('login_frame')
#点击使用账号密码登陆,需要绑定click事件 driver.find_element_by_id('switcher_plogin').click() #driver.find_element_by_id('u').clear() driver.find_element_by_id('u').send_keys('QQ') #driver.find_element_by_id('p').clear() driver.find_element_by_id('p').send_keys('密码') #点击登陆,绑定click事件 driver.find_element_by_id('login_button').click() time.sleep(2) driver.execute_script('window.scrollTo(0,document.body.scrollHeight)') time.sleep(2) driver.execute_script('window.scrollTo(0,document.body.scrollHeight)') time.sleep(2) driver.execute_script('window.scrollTo(0,document.body.scrollHeight)') time.sleep(2) page_text = driver.page_source #获取页面源码数据,注意page_source无括号。 tree = etree.HTML(page_text) #执行解析操作 li_list = tree.xpath('//ul[@id="feed_friend_list"]/li') for li in li_list: text_list = li.xpath('.//div[@class="f-info"]//text()|.//div[@class="f-info qz_info_cut"]//text()') text = ''.join(text_list) print(text+'\n\n\n') driver.quit()
发现小框是嵌套在大框里面的,在当前的html源码中,又嵌套了一个html子页面,这个子页面是包含在iframe标签中的。所以,如果定位的标签是存在于iframe中的,那么一定需要使用switch to函数,将当前浏览器页面的参照物切换到iframe中,iframe中有一个id为login_frame的属性值,可以根据它来定位。
示例4:利用搜狗搜索接口抓取微信公众号(无头、规避检测、等待、切换页面)
# 添加启动参数 (add_argument) # 添加实验性质的设置参数 (add_experimental_option) from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait import time import requests from lxml import etree option = webdriver.ChromeOptions() option.add_argument('headless') #设置chromedriver启动参数,规避对selenium的检测机制 option.add_experimental_option('excludeSwitches', ['enable-automation']) driver = webdriver.Chrome(chrome_options=option) url = 'http://weixin.sogou.com/weixin?type=1&s_from=input&query=python_shequ' driver.get(url) print(driver.title) timeout = 5 link = WebDriverWait(driver, timeout).until( lambda d: d.find_element_by_link_text('Python爱好者社区')) link.click() time.sleep(1) # 切换页面 window_handles = driver.window_handles driver.switch_to.window(window_handles[-1]) print(driver.title) article_links = WebDriverWait(driver, timeout).until( # EC.presence_of_element_located((By.XPATH, '//h4[@class="weui_media_title"]')) lambda d: d.find_elements_by_xpath('//h4[@class="weui_media_title"]')) article_link_list = [] for item in article_links: article_link = 'https://mp.weixin.qq.com' + item.get_attribute('hrefs') # print(article_link) article_link_list.append(article_link) print(article_link_list) first_article_link = article_link_list[0] header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60 } response = requests.get(first_article_link, headers=header, timeout=5 ) tree = etree.HTML(response.text) title = tree.xpath('//h2[@id="activity-name"]/text()')[0].strip() content = tree.xpath('//div[@id="js_content"]//text()') content = ''.join(content).strip() print(title) print(content)
示例5:用selenium实现一个头条号的模拟发文接口
import time import redis from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.wait import WebDriverWait r = redis.Redis('127.0.0.1', 6379) def toutiao_save_and_preview(title, content, expand_link): option = webdriver.ChromeOptions() option.add_argument('headless') driver = webdriver.Chrome(chrome_options=option) # 获取渲染的正文 driver.get('file:///Users/Documents/toutiao.html') driver.execute_script("contentIn('"+ content +"');") timeout = 5 content_copy = WebDriverWait(driver, timeout).until(lambda d: d.find_element_by_xpath('//button[@class="btn"]')) content_copy.click() # 模拟登录发文页面 cookie_toutiao = [{'name': 'ccid', 'value': 'db43e70fd9404338c49209ba04f7a11f'}, {'name': 'tt_webid', 'value': '6612748996061414925'}, {'name': 'UM_distinctid', 'value': '1667a53d28d449-0e229246a33996-4a506a-1fa400-1667a53d28e361'}, {'name': 'sso_uid_tt', 'value': '4c8179804d74252717c675607c721602'}, {'name': 'toutiao_sso_user', 'value': '8acc9b248cd201034637248021183d5a'}, {'name': 'sso_login_status', 'value': '1'}, {'name': 'sessionid', 'value': '8441fa3fc5ae5bc08c3becc780b5b2df'}, {'name': '_mp_test_key_1', 'value': '6aba81df9e257bea2a99713977f1e33b'}, {'name': 'uid_tt', 'value': '75b5b52039d4c9dd41315d061c833f0b'}, {'name': 'ccid', 'value': '4231c5cd5a98033f2e78336b1809a18a'}, {'name': 'tt_webid', 'value': '6631884089946523149'}, {'name': 'UM_distinctid', 'value': '16783e1566479-0ae7bcdcaeb592-113b6653-13c680-16783e156656d4'}, {'name': 'passport_auth_status', 'value': '99f731f2c6dc150e6dfea46799f20e90'}, {'name': 'sso_uid_tt', 'value': 'f4bcd2cf972384b428449b0479475ce6'}, {'name': 'toutiao_sso_user', 'value': '60df7bb620b4b6d1d17a1de83daec9c1'}, {'name': 'sso_login_status', 'value': '1'}, {'name': 'sessionid', 'value': '786fe64e9186d51b8427290a557b3c7b'}, {'name': 'uid_tt', 'value': '91a7a72a85861ae686fb66177bc16bca'}, {'name': '__tea_sdk__ssid', 'value': '60b289e6-e2a4-4494-a3e8-7936f9731426'}, {'name': 'uuid', 'value': 'w:3ec91cefd76b438583154fea77baa54b'}, {'name': 'tt_im_token', 'value': '1544105894108419437114683515671344747598423336731147829901779697'}] driver.get('https://mp.toutiao.com/profile_v3/index') for cookie in cookie_toutiao: driver.add_cookie(cookie) driver.get('https://mp.toutiao.com/profile_v3/graphic/publish') print(driver.title) # driver.maximize_window() # 写标题 print('写标题') write_title = WebDriverWait(driver, timeout).until(lambda d: d.find_element_by_xpath('//*[@id="title"]')) write_title.click() write_title.send_keys(title) # 粘贴正文 print('写正文') write_content = WebDriverWait(driver, timeout).until(lambda d: d.find_element_by_xpath( '//*[@id="graphic"]/div/div/div[2]/div[1]/div[2]/div[3]/div[2] | //div[contains(@class,"ql-editor")]')) write_content.click() write_content.clear() write_content.send_keys(Keys.SHIFT + Keys.INSERT) # time.sleep(1) # 检测图片上传是否完成 try: if 'img' in content: WebDriverWait(driver, timeout).until( lambda d: d.find_element_by_xpath('//div[@class="pgc-img-wrapper"]')) print('images uploaded success') else: print('no image included') except: print('images uploaded fail') # 页面向下滚动 driver.execute_script("window.scrollTo(0, document.body.scrollHeight)") time.sleep(1) # 添加扩展链接 expand_check = WebDriverWait(driver, timeout).until(lambda d: d.find_element_by_xpath( '//div[@class="pgc-external-link"]//input[@type="checkbox"]', )) expand_check.click() expand_link_box = WebDriverWait(driver, timeout).until(lambda d: d.find_element_by_xpath( '//div[@class="link-input"]//input[@type="text"]', )) expand_link_box.send_keys(expand_link) time.sleep(1) # 自动封面 front_img = WebDriverWait(driver, timeout).until(lambda d: d.find_element_by_xpath( '//div[@class="article-cover"]/div/div[@class="tui2-radio-group"]/label[3]/div/input', )) front_img.click() time.sleep(1) # 保存草稿 save_draft = WebDriverWait(driver, timeout).until(lambda d: d.find_element_by_xpath( '//div[@class="publish-footer"]/button[4]/span')) save_draft.click() time.sleep(1) # 从内容管理页,获取预览链接和文章ID print('get preview_link and article_id') # driver.refresh() preview_link = WebDriverWait(driver, timeout).until(lambda d: d.find_element_by_xpath( '//div[@id="article-list"]//div[@class="master-title"][1]/a')).get_attribute('href') article_id = preview_link.split('=')[-1] print(preview_link, article_id) time.sleep(1) content_management = WebDriverWait(driver, timeout).until(lambda d: d.find_element_by_link_text('内容管理')) content_management.click() time.sleep(1) driver.refresh() preview_link = WebDriverWait(driver, timeout).until(lambda d: d.find_element_by_xpath( '//*[@id="article-list"]/div[2]/div/div/div[1]/div/a')).get_attribute('href') article_id = preview_link.split('=')[-1] index_page = WebDriverWait(driver, timeout).until(lambda d: d.find_element_by_xpath('//a[@class="shead_logo"]')) index_page.click() driver.get('https://mp.toutiao.com/profile_v3/index') print(r.scard('cookie_pool_toutiao')) return preview_link, article_id if __name__ == "__main__": print('start') start_time = time.time() title = 'Children' content = '<p>cute</p><p><img class="wscnph" src="http://img.mp.itc.cn/upload/20170105/1a7095f0c7eb4316954dda4a8b93b88c_th.jpg" /></p>' expand_link = 'https://www.cnblogs.com/Summer-skr--blog/' img = '' preview_link, article_id = toutiao_save_and_preview(title, content, expand_link) print(preview_link) print(article_id) finish_time = time.time() print(finish_time - start_time)
selenium相关文档:
https://www.seleniumhq.org/docs/
https://selenium-python.readthedocs.io
哈哈,认认真真的写了这么长博文,如果您觉得对您有帮助,麻烦帮忙点个赞哦!一起加油!
