Python爬虫进阶 | 多线程
一、简介
为了提高爬虫程序效率,由于python解释器GIL,导致同一进程中即使有多个线程,实际上也只会有一个线程在运行,但通过request.get发送请求获取响应时有阻塞,所以采用了多线程依然可以提高爬虫效率。
多线程爬虫注意点
1.解耦
整个程序分为4部分,url list模块、发送请求,获取响应模块、数据提取模块、保存模块,如果某一模块出现问题,互相之间不会影响。
2. 资源竞争
由于使用了多线程,不同线程在共享数据时,容易产生资源竞争,假设共享数据放入列表中,那么同一时刻有可能2个线程去列表中取同一个数据,重复使用。解决办法是使用队列,使得某一线程get数据时,其他线程无法get同一数据,真正起到保护作用,类似互斥锁。
队列常用方法介绍
from queue import Queue q = Queue() q.put(url) q.get() # 当队列为空时,阻塞 q.empty() # 判断队列是否为空,True/False

注意:
- get和get_nowait两者的区别是当队列取完了即队列为空时,get()会阻塞,等待着新数据继续取,而get_nowait()会报错;
- put和put_nowait 两者的区别是当队列为满时,put_nowait()会报错;
队列其他方法join task_done setDaemon
- 在python3中,join()会等待子线程、子进程结束之后,主线程、主进程才会结束.
- 队列中put队列计数会+1,get时计数不会减1,但当get+task_done时,队列计数才会减1,如果没有task_done则程序跑到最后不会终止。task_done()的位置,应该放在方法的最后以保证所有任务全部完成.
- setDaemon方法把子线程设置为守护线程,即认为该方法不是很重要,记住主线程结束,则该子线程结束
- join方法和setDaemon方法搭配使用。主线程进行到join()处,join的效果是让主线程阻塞,等待子线程中队列任务完成之后再解阻塞,等子线程结束,join效果失效,之后主线程结束,由于使用了setDaemon(True),所以子线程跟着结束,此时整个程序结束。
线程模块
from threading import Thread # 使用流程 t = Thread(target=函数名) # 创建线程对象 t.start() # 创建并启动线程 t.join() # 阻塞等待回收线程
应用场景
- 多进程 :CPU密集程序
- 多线程 :爬虫(网络I/O)、本地磁盘I/O
二、案例
1. 小米应用商店抓取
目标
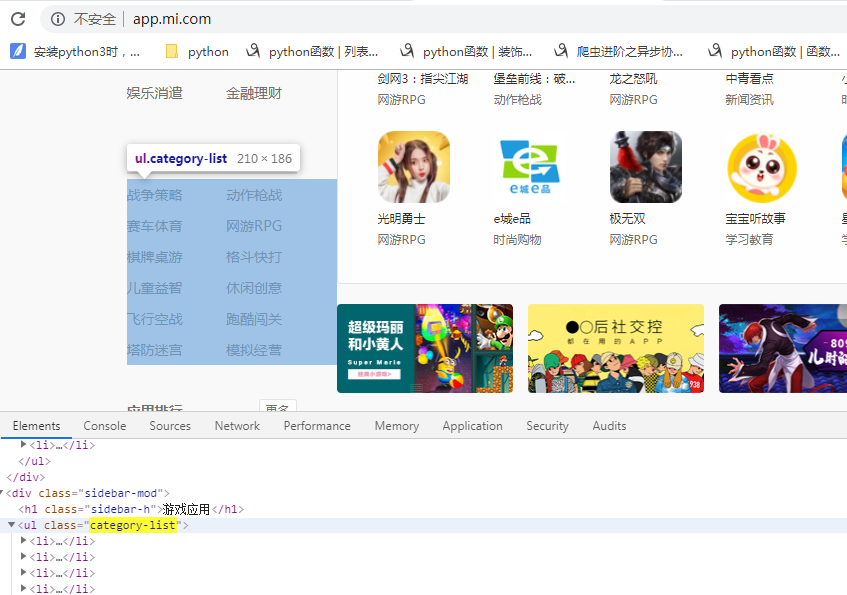
- 网址 :百度搜 - 小米应用商店,进入官网,应用分类 - 聊天社交
- 目标 :爬取应用名称和应用链接
实现步骤
1、确认是否为动态加载:页面局部刷新,查看网页源代码,搜索关键字未搜到,因此此网站为动态加载网站,需要抓取网络数据包分析
2、抓取网络数据包
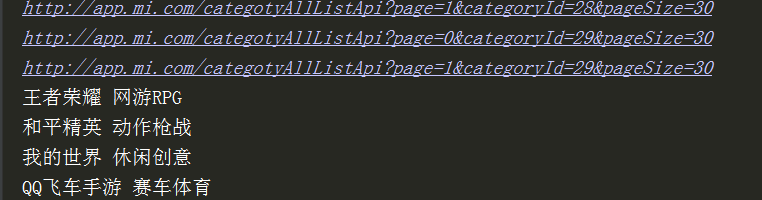
- 抓取返回json数据的URL地址(Headers中的Request URL)http://app.mi.com/categotyAllListApi?page={}&categoryId=2&pageSize=30
- 查看并分析查询参数(headers中的Query String Parameters)只有page在变,0 1 2 3 ... ... ,这样我们就可以通过控制page的值拼接多个返回json数据的URL地址
page: 1 categoryId: 2 pageSize: 30
3、将抓取数据保存到csv文件。注意多线程写入的线程锁问题
from threading import Lock lock = Lock() lock.acquire() lock.release()
整体实现思路
- 在 __init__(self) 中创建文件对象,多线程操作此对象进行文件写入;
- 每个线程抓取数据后将数据进行文件写入,写入文件时需要加锁;
- 所有数据抓取完成关闭文件;
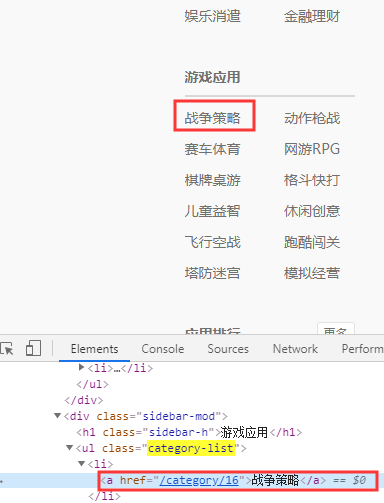
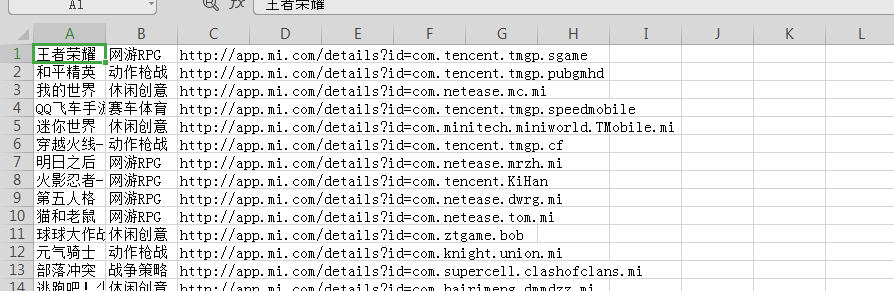
import requests from threading import Thread from queue import Queue import time from lxml import etree import csv from threading import Lock class XiaomiSpider(object): def __init__(self): self.url = 'http://app.mi.com/categotyAllListApi?page={}&categoryId={}&pageSize=30' self.ua = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1'} self.q = Queue() # 存放所有URL地址的队列 self.i = 0 self.id_list = [] # 存放所有类型id的空列表 # 打开文件 self.f = open('xiaomi.csv', 'a', newline="") self.writer = csv.writer(self.f) self.lock = Lock() # 创建锁 def get_cateid(self): url = 'http://app.mi.com/' html = requests.get(url=url, headers=self.ua).text parse_html = etree.HTML(html) li_list = parse_html.xpath('//ul[@class="category-list"]/li') for li in li_list: typ_name = li.xpath('./a/text()')[0] typ_id = li.xpath('./a/@href')[0].split('/')[-1] pages = self.get_pages(typ_id) # 计算每个类型的页数 self.id_list.append((typ_id, pages)) self.url_in() # 入队列 def get_pages(self, typ_id): # 每页返回的json数据中,都有count这个key url = self.url.format(0, typ_id) html = requests.get(url=url, headers=self.ua).json() count = html['count'] # 类别中的数据总数 pages = int(count) // 30 + 1 # 每页30个,看有多少页 return pages # url入队列 def url_in(self): for id in self.id_list: # id为元组,(typ_id, pages)-->('2',pages) for page in range(2): url = self.url.format(page, id[0]) print(url) # 把URL地址入队列 self.q.put(url) # 线程事件函数: get() - 请求 - 解析 - 处理数据 def get_data(self): while True: # 当队列不为空时,获取url地址 if not self.q.empty(): url = self.q.get() html = requests.get(url=url, headers=self.ua).json() self.parse_html(html) else: break # 解析函数 def parse_html(self, html): # 存放1页的数据 - 写入到csv文件 app_list = [] for app in html['data']: # 应用名称 + 链接 + 分类 name = app['displayName'] link = 'http://app.mi.com/details?id=' + app['packageName'] typ_name = app['level1CategoryName'] # 把每一条数据放到app_list中,目的为了 writerows() app_list.append([name, typ_name, link]) print(name, typ_name) self.i += 1 # 开始写入1页数据 - app_list self.lock.acquire() self.writer.writerows(app_list) self.lock.release() # 主函数 def main(self): self.get_cateid() # URL入队列 t_list = [] # 创建多个线程 for i in range(1): t = Thread(target=self.get_data) t_list.append(t) t.start() # 统一回收线程 for t in t_list: t.join() # 关闭文件 self.f.close() print('数量:', self.i) if __name__ == '__main__': start = time.time() spider = XiaomiSpider() spider.main() end = time.time() print('执行时间:%.2f' % (end - start))

2.腾讯招聘数据抓取(Ajax)
确定URL地址及目标
- URL: 百度搜索腾讯招聘 - 查看工作岗位https://careers.tencent.com/search.html
- 目标: 职位名称、工作职责、岗位要求
要求与分析
- 通过查看网页源码,得知所需数据均为 Ajax 动态加载
- 通过F12抓取网络数据包,进行分析
- 一级页面抓取数据: 职位名称
- 二级页面抓取数据: 工作职责、岗位要求
一级页面json地址(pageIndex在变,timestamp未检查)
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn
二级页面地址(postId在变,在一级页面中可拿到)
https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn
useragents.py文件
ua_list = [ 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1', 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)', ]
非多线程爬取


import time import json import random import requests from useragents import ua_list class TencentSpider(object): def __init__(self): self.one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn' self.two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn' self.f = open('tencent.json', 'a') # 打开文件 self.item_list = [] # 存放抓取的item字典数据 # 获取响应内容函数 def get_page(self, url): headers = {'User-Agent': random.choice(ua_list)} html = requests.get(url=url, headers=headers).text html = json.loads(html) # json格式字符串转为Python数据类型 return html # 主线函数: 获取所有数据 def parse_page(self, one_url): html = self.get_page(one_url) item = {} for job in html['Data']['Posts']: item['name'] = job['RecruitPostName'] # 名称 post_id = job['PostId'] # postId,拿postid为了拼接二级页面地址 # 拼接二级地址,获取职责和要求 two_url = self.two_url.format(post_id) item['duty'], item['require'] = self.parse_two_page(two_url) print(item) self.item_list.append(item) # 添加到大列表中 # 解析二级页面函数 def parse_two_page(self, two_url): html = self.get_page(two_url) duty = html['Data']['Responsibility'] # 工作责任 duty = duty.replace('\r\n', '').replace('\n', '') # 去掉换行 require = html['Data']['Requirement'] # 工作要求 require = require.replace('\r\n', '').replace('\n', '') # 去掉换行 return duty, require # 获取总页数 def get_numbers(self): url = self.one_url.format(1) html = self.get_page(url) numbers = int(html['Data']['Count']) // 10 + 1 # 每页有10个推荐 return numbers def main(self): number = self.get_numbers() for page in range(1, 3): one_url = self.one_url.format(page) self.parse_page(one_url) # 保存到本地json文件:json.dump json.dump(self.item_list, self.f, ensure_ascii=False) self.f.close() if __name__ == '__main__': start = time.time() spider = TencentSpider() spider.main() end = time.time() print('执行时间:%.2f' % (end - start))
多线程爬取
多线程即把所有一级页面链接提交到队列,进行多线程数据抓取
import requests import json import time import random from useragents import ua_list from threading import Thread from queue import Queue class TencentSpider(object): def __init__(self): self.one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn' self.two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn' self.q = Queue() self.i = 0 # 计数 # 获取响应内容函数 def get_page(self, url): headers = {'User-Agent': random.choice(ua_list)} html = requests.get(url=url, headers=headers).text # json.loads()把json格式的字符串转为python数据类型 html = json.loads(html) return html # 主线函数: 获取所有数据 def parse_page(self): while True: if not self.q.empty(): one_url = self.q.get() html = self.get_page(one_url) item = {} for job in html['Data']['Posts']: item['name'] = job['RecruitPostName'] # 名称 post_id = job['PostId'] # 拿postid为了拼接二级页面地址 # 拼接二级地址,获取职责和要求 two_url = self.two_url.format(post_id) item['duty'], item['require'] = self.parse_two_page(two_url) print(item) # 每爬取按完成1页随机休眠 time.sleep(random.uniform(0, 1)) else: break # 解析二级页面函数 def parse_two_page(self, two_url): html = self.get_page(two_url) # 用replace处理一下特殊字符 duty = html['Data']['Responsibility'] duty = duty.replace('\r\n', '').replace('\n', '') # 处理要求 require = html['Data']['Requirement'] require = require.replace('\r\n', '').replace('\n', '') return duty, require # 获取总页数 def get_numbers(self): url = self.one_url.format(1) html = self.get_page(url) numbers = int(html['Data']['Count']) // 10 + 1 return numbers def main(self): # one_url入队列 number = self.get_numbers() for page in range(1, number + 1): one_url = self.one_url.format(page) self.q.put(one_url) t_list = [] for i in range(5): t = Thread(target=self.parse_page) t_list.append(t) t.start() for t in t_list: t.join() print('数量:', self.i) if __name__ == '__main__': start = time.time() spider = TencentSpider() spider.main() end = time.time() print('执行时间:%.2f' % (end - start))
多进程实现
import requests import json import time import random from useragents import ua_list from multiprocessing import Process from queue import Queue class TencentSpider(object): def __init__(self): self.one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1563912271089&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn' self.two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1563912374645&postId={}&language=zh-cn' self.q = Queue() # 获取响应内容函数 def get_page(self, url): headers = {'User-Agent': random.choice(ua_list)} html = requests.get(url=url, headers=headers).text # json格式字符串 -> Python html = json.loads(html) return html # 主线函数: 获取所有数据 def parse_page(self): while True: if not self.q.empty(): one_url = self.q.get() html = self.get_page(one_url) item = {} for job in html['Data']['Posts']: # 名称 item['name'] = job['RecruitPostName'] # postId post_id = job['PostId'] # 拼接二级地址,获取职责和要求 two_url = self.two_url.format(post_id) item['duty'], item['require'] = self.parse_two_page(two_url) print(item) else: break # 解析二级页面函数 def parse_two_page(self, two_url): html = self.get_page(two_url) # 用replace处理一下特殊字符 duty = html['Data']['Responsibility'] duty = duty.replace('\r\n', '').replace('\n', '') # 处理要求 require = html['Data']['Requirement'] require = require.replace('\r\n', '').replace('\n', '') return duty, require # 获取总页数 def get_numbers(self): url = self.one_url.format(1) html = self.get_page(url) numbers = int(html['Data']['Count']) // 10 + 1 return numbers def main(self): # url入队列 number = self.get_numbers() for page in range(1, number + 1): one_url = self.one_url.format(page) self.q.put(one_url) t_list = [] for i in range(4): t = Process(target=self.parse_page) t_list.append(t) t.start() for t in t_list: t.join() if __name__ == '__main__': start = time.time() spider = TencentSpider() spider.main() end = time.time() print('执行时间:%.2f' % (end - start))
基于multiprocessing.dummy线程池的数据爬取
案例:爬取梨视频数据。在爬取和持久化存储方面比较耗时,所以两个都需要多线程
import requests import re from lxml import etree from multiprocessing.dummy import Pool import random pool = Pool(5) # 实例化一个线程池对象 url = 'https://www.pearvideo.com/category_1' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' } page_text = requests.get(url=url,headers=headers).text tree = etree.HTML(page_text) li_list = tree.xpath('//div[@id="listvideoList"]/ul/li') video_url_list = [] for li in li_list: detail_url = 'https://www.pearvideo.com/'+li.xpath('./div/a/@href')[0] detail_page = requests.get(url=detail_url,headers=headers).text video_url = re.findall('srcUrl="(.*?)",vdoUrl',detail_page,re.S)[0] video_url_list.append(video_url) # pool.map(回调函数,可迭代对象)函数依次执行对象 video_data_list = pool.map(getVideoData,video_url_list) # 获取视频 pool.map(saveVideo,video_data_list) # 持久化存储 def getVideoData(url): return requests.get(url=url,headers=headers).content def saveVideo(data): fileName = str(random.randint(0,5000))+'.mp4' # 因回调函数只能传一个参数,所以没办法再传名字了,只能自己取名 with open(fileName,'wb') as fp: fp.write(data) pool.close() pool.join()

