python基础 | 入门需知(必会)
一、变量
1.变量的定义
将程序运算的中间结果临时存在内存里,以便后续代码调用。
2.变量的使用规范
1)变量必须要有数字,字母,下划线,任意组合。
2)变量不能数字开头。
3)不能是python中的关键字(有特殊意义)。
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for','from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
4)变量要具有可描述性。
name = 12 # 错
5)变量不建议使用中文。
6)变量不能过长。fdhsjkfdsakfljfkl = 12
7)变量不能使用拼音
官方推荐:
驼峰体:AgeOfOldboy = 56
下划线:age_of_oldboy = 56
变量小高级
1 age1 = 12
2 age2 = age1
3 age3 = age2
4 age2 = 18
5
6 print(age1,age2,age3) # 12 18 12 age3不等于18,不能网上面找,直下
变量的用处:
- 减少重复率
- 过长的结果让变量替代
二、常量
常量:一直不变的量。如π 3.1415926 等等不变的量,或者是在程序运行过程中不改变的量
默认全部大写的变量就是常量
将变量全部大写就是常量。NAME = 'summer',这样NAME就永远不变了
一般,设置一些不变的量,放在文件的最上面。
三、注释
单行注释:#
多行注释:单引号和双引号没有区别
'''
被注释内容
'''
四、赋值
赋值计算
- 先计算等号右边的,再把计算的值赋值给左边
- 代码一行行执行,后面的变量会覆盖前面的
分别赋值
1 a,b=10,20 # a=10,b=10
2 a,b=[10,20] # a=10,b=10
3 a,b=[(10,20),(30,40)] # a=(10,20),b=(30,40)
4 a,b=b,a #a和b交换值
# a = 4,b = 5,请用一行代码,将a和b的值互换。 a = 4,b = 5 a,b = b,a
五、用户交互input
input出来的数据都是字符串类型。
name = input('请输入姓名:')
print(name,type(name))
name = input('请输入姓名:')
age = input('请输入年龄:')
sex = input('请输入性别:')
msg = "我叫" + name + "今年" + age + "性别" + sex
print(msg)
input阻塞式的。程序会停留在这句话。等着用户输入。当输入回车的时候,程序继续执行
六、运算符
1、算数运算符
|
运算符 |
描述 |
实例 |
|
+ |
加 |
a + b =30 |
|
- |
减 |
a - b = -10 |
|
* |
乘 |
a * b = 200 |
|
/ |
除 |
a / b = 0.5 |
|
% |
取余 |
a % b = 10 |
|
** |
幂 |
a ** b = 10000000000 |
|
// |
整除 |
a // b = 0 |
2、比较运算符
|
运算符 |
描述 |
|
= |
等于 |
|
!= |
不等于 |
|
> |
大于 |
|
< |
小于 |
|
>= |
大于等于 |
|
<= |
小于等于 |
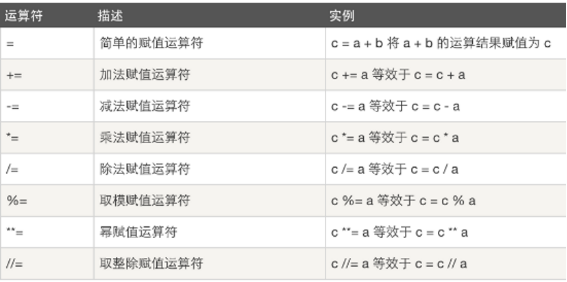
3、赋值运算符
4、逻辑运算符(not、and、or)
逻辑运算的进一步研究:
(1)在没有()的情况下,优先级关系为( )>not>and>or,同一优先级从左往右计算。
(2)false and 任何条件,都是false
(3)在or中,只要有真,结果必定为真。
第一种:前后都是比较运算
print(1 > 2 and 3 < 4) # False
print(1 > 2 and 3 < 4 and 3 > 2 or 2 < 3) # True
print(1 and 2) # 2
print(0 and 2) # 0
第二种:前后都是数字运算
(1)x or y , x为真,值就是x,x为假,值是y;
(2)x and y, x为真,值是y, x为假,值是x。
(3)非0的数字,都是真
print(1 or 3) # 1
print(2 or 3) # 2
print(0 or 3) # 3
print(-1 or 3) # -1
第三种:混合。一边为比较运算,一边为数值运算
print(1 > 2 or 3 and 4) # 4
print(1 > 2 or 3 and 4) # 4
print(2 or 2 > 3 and 4) # 2
print(3 > 1 and 2 or 2 < 3 and 3 and 4 or 3 > 2) # 2
七、in的使用
1. in 操作符用于判断关键字是否存在于变量中
in是整体匹配,不会拆分匹配。
a = '男孩Jasper'
print('男孩Niol' in a) # False
应用。比如评论的敏感词汇,会用到in 和not in
comment = input('请输入你的评论:')
if '宝宝' in comment:
print('您输入的有敏感词汇,请重新输入')
执行输出:
请输入你的评论:宝宝
您输入的有敏感词汇,请重新输入
八、range和enumerate
自定制数据范围的可迭代对象,可以类比成列表,只是和for循环结合使用
范围可控,步长可正可负
注意:range()不会打印末尾的数字,默认是从0开始的。
01: 打印0到9
for i in range(10):
print(i)
执行输出:
0
1
2
02:打印1~10之间的奇数
for i in range(1,10,2):
print(i)
执行输出:
1
3
5
7
9
03:打印0~10之间的偶数
for i in range(0,10,2):
print(i)
执行输出:
0
2
4
6
8
04:反向步长,倒序输出1到10
for i in range(10,0,-1):
print(i)
执行输出:
10
9
8
7
6
5
4
3
2
1
05:遍历列表元素,打印每一个索引值
li = [2,3,'alex',4,5]
for i in li:
print(li.index(i))
执行输出:
0
1
2
3
4
06:使用range打印列表中的索引
li = [2,3,'alex',4,5]
for i in range(0,len(li)):
print(i)
执行输出:
0
1
2
3
4
07
l1 = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
for i in l1:
print(l1.index(i)) # 方法1:列表中不能有重复的元素
for i in range(0, len(l1)): # 方法2:列表中可以有重复的元素
print(i)
列表长度永远比索引值大1,所以可以用range方式
enumerate:枚举
对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值。
li = ['spring', 'summer', 'autumn', 'winter']
for i in enumerate(li):
print(i)
结果输出:
(0, 'spring')
(1, 'summer')
(2, 'autumn')
(3, 'winter')
for index, name in enumerate(li, 1):
print(index, name)
结果输出:
1 spring
2 summer
3 autumn
4 winter
for index, name in enumerate(li, 100): # 起始位置默认是0,可更改
print(index, name)
结果输出:
100 spring
101 summer
102 autumn
103 winter
九、join split
join用字符串做一个连接符,连接可迭代对象中的每一个元素,形成一个新的字符串
s = '@'.join('我是谁')
print(s) # 我@是@谁
split str ---> list 使用split方法将字符串转换为列表
s = 'spring summer autumn winter'
print(s.split()) # ['spring', 'summer', 'autumn', 'winter']
join list ---> str 使用join方法将列表转换为字符串
li = ['spring', 'summer', 'autumn', 'winter']
print(' '.join(li)) # spring summer autumn winter
join很重要,一定要掌握
十、流程控制语句
五种情况
- 单独if;
- if else;
- if elif elif....... 无else
- if elif elif....... else
- if 嵌套
例子:
一定要注意把分数高的写在前面
score = int(input("输入分数:"))
if score > 100:
print("优秀")
elif score >= 90:
print("A")
elif score >= 80:
print("B")
elif score >= 70:
print("C")
elif score >= 60:
print("D")
else:
print("不及格")
username = input('请输入用户名:')
password = input('请输入密码:')
if username == 'summer' :
if password == '123456':
print('成功登陆')
else:
print('密码错误')
else:
print('用户名错误')
十一、流程控制语句while
1.基本结构
while 条件:
循环体
2.执行流程:
判断条件是否为真, 如果真, 执行循环体,然后再次判断条件是否为真。直到条件为假。循环终止
3.如何终止循环
a.条件不成立
b.break
4.关键字 break 和 continue区别
break 彻底终止这个循环
continue 终止当前本次循环。继续执行下一次循环
5.while else 固定搭配
演示生活中循环听歌. While True循环的执行结果就是这样一直循环,只要电脑不死机
while True:
print('海绵宝宝')
print('夜曲')
print('小星星')
print('曲终人散')
print('疯子')
如何终止循环?
- 改变条件(根据上面的流程,只要改变条件,就会终止循环)。
- 关键字:break。
- 关键字:continue(终止本次循环)
方法1:利用改变条件,终止循环。引入标志位
flag = True
while flag:
print('海绵宝宝')
print('夜曲')
print('小星星')
print('曲终人散')
print('疯子')
flag = False
练习1:输出1~100所有的数字
count = 1
flag = True
while flag:
print(count)
count = count + 1
if count == 101:
flag = False
练习2:使用while循环求出1-100所有数的和.
count = 1
s = 0
while count < 101:
s = s + count
count = count + 1print(s)
方法2:break
循环中,只要遇到break马上退出循环。
while True:
print('海绵宝宝')
print('夜曲')
print('小星星')
print('曲终人散')
break
print('疯子')
练习:打印1~100所有的偶数
# 方法一:
count = 1
while True:
if count % 2 == 0:
print(count)
count = count + 1
if count == 101:
Break
# 方法二:
count = 1
while count < 101:
if count % 2 == 0:
print(count)
count = count + 1
# 方法三:
count = 2
while count < 101:
print(count)
count = count + 2
方法3:continue
continue 用于终止本次循环,继续下一次循环。
while True:
print('海绵宝宝')
print('夜曲')
print('小星星')
print('曲终人散')
continue
print('疯子')
执行结果:永远不打印疯子,并且循环一直进行
练习: 使用while循环打印 1 2 3 4 5 6 8 9 10
count = 0
while count < 10:
count = count + 1
if count == 7:
continue
print(count)
练习:请输出1,2,3,4,5,95,96,97,98,99,100
count = 0
while count <= 100 :
count += 1
if count > 5 and count < 95: #只要count在6-94之间,就不走下面的print语句,直接进入下一次loop
continue
print( count)
while else的使用
while else中, 如果循环被break打断,程序不会走else
count = 0
while count <= 5 :
count += 1
print("Loop",count)
else:
print("循环正常执行完啦")
print("-----out of while loop ------")
输出
Loop 1
Loop 2
Loop 3
Loop 4
Loop 5
Loop 6
循环正常执行完啦
-----out of while loop ------
如果执行过程中被break啦,就不会执行else的语句啦
count = 0
while count <= 5 :
count += 1
if count == 3:break
print("Loop",count)
else:
print("循环正常执行完啦")
print("-----out of while loop ------")
输出:
Loop 1
Loop 2
-----out of while loop ------
十二、for循环
先来使用while循环,打印每一个字符串 *****
s = 'abcdef'
count = 0
while count < len(s):
print(s[count])
count += 1
输出结果:
a
b
c
d
e
f
使用for循环完成上面的功能
s = 'abcdef'
for i in s:
print(i)
for循环和while循环的区别在于 *****
for 循环是有限循环
while 循环是无限循环
有些情况,在不需要终止条件的情况下,使用for循环;有终止条件的,使用while循环
for循环会自动停止
使用for循环实现九九乘法表: *****
for i in range(1, 10):
for j in range(1, i + 1):
print('{}x{}={}\t'.format(j, i, i * j), end='')
print('\n')
执行输出:
1x1=1 1x2=2 2x2=4 1x3=3 2x3=6 3x3=9 1x4=4 2x4=8 3x4=12 4x4=16 1x5=5 2x5=10 3x5=15 4x5=20 5x5=25 1x6=6 2x6=12 3x6=18 4x6=24 5x6=30 6x6=36 1x7=7 2x7=14 3x7=21 4x7=28 5x7=35 6x7=42 7x7=49 1x8=8 2x8=16 3x8=24 4x8=32 5x8=40 6x8=48 7x8=56 8x8=64 1x9=9 2x9=18 3x9=27 4x9=36 5x9=45 6x9=54 7x9=63 8x9=72 9x9=81
十三、小数据池
1. id、is 、==
id:在python中,id就是内存地址。例如使用id()内置函数去查询一个数据的内存地址:
name='summer'
print(id(name))
输出结果是name的内存地址:2151381407344(每次运行时的id地址都不一样)
==:比较两边的数值是否相等
is:比较两边的id是否相同

如果说内存地址相同,那么值一定相同;如果值相同,内存地址不一定相同。
2.小数据池
概念:小数据池也叫小整数缓存机制,或者称为驻留机制。小数据池只针对于 整数、字符串、bool值。其它的数据类型,不存在小数据池。
整数:Python自动将-5~256的整数进行了缓存。就是说当你将这些整数赋值给变量时,并不会创建新的对象(不会在内存中开辟新的房间给变量),而是使用已经创建好的对象。
例如:用cmd运行python,每行都是一个代码块

字符串:python会将一定规则的字符串放在字符串驻留池中,当你将这些字符串赋值给变量时不会创建新的对象,而是使用在字符串驻留池中已经创建好的对象。
1.如果含有特殊字符,不存在小数据池
2. str(单个) * int int > 20 不存在小数据池
小数据池对于字符串的规定要从以下四个方面进行讨论:
1、字符串长度为0或者1时,默认采用了驻留机制
2、字符串长度>1,且只含有大小写字母,数字,下划线时候,默认采用驻留机制
3、用乘法得到的字符串
①乘数为1时:
Ⅰ.仅含有大小写字母、数字、下划线,默认驻留
Ⅱ.含其他字符,长度<=1,默认驻留
Ⅲ.含其他字符,长度>1,默认驻留
②乘数>=2时:仅含有大小写字母,数字,下划线,总长度<=20,默认驻留
4、指定驻留:你可以指定任意的字符串加入到小数据池中,让其只在内存中创建一个对象,多个变量都是指向这一个字符串
小数据池优缺点
优点:需要值相同的字符串和整数时,能够直接进行调用,避免频繁的创建和销毁,提升效率,节约内存。
缺点:在池中创建或插入字符、整数时,会发费更多的时间。
3.代码块与小数据池的关系
i1 = 1000
i2 = 1000
print(i1 is i2)
交互下

Pycharm下执行,内存地址相同,因为这是一个代码块
同样一段代码,在Pycham和交互方式执行的结果不同。 在Pycharm中,结果是True,在cmd下结果是False。因为代码块内的缓存机制和代码块之间的缓存机制不同。
- Python在执行同一个代码块的初始化对象命令时,会检查其值是否已经存在,如果存在,会将其重用。换句话说,执行同一个代码块,遇到初始化对象的命令时,会将初始化的变量和值存储在一个字典中,在遇到新的变量时,会在字典中查询记录,如果有同样的记录,那么会重复使用字典中的这个值。
- 如果是不同的代码块,会看这两个变量的值是否满足小数据池的范围,如果满足则指向同一个地址。
对于同一个代码块变量复用的问题,只能针对于数字,字符串,bool值,而对于其他数据类型是不成立的。
十四、格式化输出
某些参数的位置是固定的,但是值是动态的需要用到格式化输出。格式化输出,就是做固定模板填充
% 占位符
百分号 %
%s 标识符 万能的 %.ns 截取
msg = "my name is %s" % 'Summer' print(msg) # my name is Summer msg = "my name is %.3s" % 'Summer' print(msg) # my name is Sum msg = "my name is %s,age is %s" % ('Summer', 22) print(msg) # my name is Summer,age is 22 msg = "my name is %s,age is %.4s" % ('Summer', 22.3345) print(msg) # my name is Summer,age is 22.3 msg = "my name is %s,age is %s" % ('Summer', [22, 33]) print(msg) # my name is Summer,age is [22, 33]
%d 标识符 只能接受整型数字
msg = "my name is %s,age is %d" % ('Summer', 22) print(msg) # my name is Summer,age is 22
%f 标识符 接受浮点数 可指定小数位 四舍五入
msg = "age is %f" % 22 print(msg) # age is 22.000000 msg = "age is %.2f" % 22.356 print(msg) # age is 22.36 # 打印百分比 %% msg = "percent %.2f %%" % 90.769 print(msg) # percent 90.77 %
%(key)
msg = "i am %(name)s, age %(age)d" % {"name": "Summer", "age": 6} print(msg) # i am Summer, age 6
# %-ns 左对齐 msg = "i am %-6s" % ("Summer") print(msg) # i am Summer # %ns 右对齐 msg = "i am %6s" % ("Summer") print(msg) # i am Summer # 以\033[xx;1m 开头 \033[0m 结尾 加颜色 xx 控制颜色 msg = "my name is \033[45;1mSummer\033[0m" print(msg) # my name is Summer # print 分隔符 : print('Spring', 'Summer', 'Winter', sep=':') # Spring:Summer:Winter
name = input('请输入你的姓名:') age = input('请输入你的年龄:') hobby = input('请输入你的爱好:') msg = '我叫%s,今年%d岁,爱好%s' % (name, int(age), hobby) print(msg)
输出结果: 请输入你的姓名:summer 请输入你的年龄:19 请输入你的爱好:skiing 我叫summer,今年19岁,爱好skiing
dic = {'name':'jsummer','age':19,'hobby':'skiing'}
msg = '我叫%(name)s,今年%(age)d岁,爱好%(hobby)s' % dic
print(msg
dic = {'name':'jsummer','age':19,'hobby':'skiing'}
msg = '我叫%(name)s,今年%(age)d岁,爱好%(hobby)s' % dic
print(msg
输出结果: 我叫jsummer,今年19岁,爱好skiing
format
# {} msg = "i am {},age is {}".format("Summer", 6) print(msg) # i am Summer,age is 6 # {n} msg = "i am {1},age is {0}".format(6, "Summer") print(msg) # i am Summer,age is 6 # 不一一对应 msg = "i am {1},age is {1}".format(6, "Summer") print(msg) # i am Summer,age is Summer # 键值对 msg = "i am {name},age is {age}".format(age=6, name="Summer") print(msg) # i am Summer,age is 6 # 字典 msg = "i am {name},age is {age}".format(**{"name": "Summer", "age": 6}) print(msg) # i am Summer,age is 6
第一种替换方式
第二种替换方式:定义一个字典
第三种替换方式:在格式化输出中单纯的显示%,用%%解决
name = input('请输入你的姓名:')
age = input('请输入你的年龄:')
msg = '我叫%s,今年%d岁,100%%中国人' % (name,int(age))
print(msg)
输出结果:
我叫summer,今年19岁,100%中国人
第四种替换方式
name = input('请输入你的姓名:')
age = input('请输入你的年龄:')
msg = '我叫{},今年{}岁'.format(name,int(age))
print(msg)
十五、编码
1,发电报:滴滴滴滴 实际是高低电平。
密码本:
敌 0000 0001
人 0000 0101
最 0000 0011
近 0000 1100
有 0001 1010
行 0001 0001
动 1000 0000
2,计算机在存储,和传输的时候
asiic 最早版本的'密码本'.
包含数字,英文,特殊字符。八位
01000001 01000010 01000011 A B C
8位 = 1 byte 表示一个字符。
ascii最左1位都是0,为了拓展使用的。
ASCII码表里的字符总共有256个
前128个为常用的字符如运算符
后128个为 特殊字符是键盘上找不到的字符
万国码unicode,将所有国家的语言包含在这个密码本。(浪费资源,占空间)
初期:16位,两个字节,表示一个字符。
A : 00010000 00010010
中: 00010010 00010010
升级:32位,四个字节,表示一个字符。
A : 00010000 00010010 00010000 00010010
中: 00010010 00010010 00010010 00010010
32位资源浪费。
utf-8。对Unicode编码的压缩和优化。
英文:8bit
欧文:16bit
中文:24bit 3个字节
utf-16 不常用,最少用16位
gbk:国标。
只包含:中文,英文,数字,特殊字符
英文:1个字节(8位)
中文:2个字节(16位)
gb2312 也是国标的一种
单位换算
8 bit = 1 byte
1024 byte = 1 kb
1024 kb = 1 MB
1024 MB = 1 GB
1024 GB = 1 TB
编码之间不能互相识别
网络传输或者硬盘存储的二进制必须是以非Unicode编码方式。Unicode 32位一个字符,资源浪费
大环境Python3x:
str:内部编码方式是Unicode。所以python文件中的字符串不能直接进行文件存储和传输。
bytes:python中的基础数据类型之一,与str相当于双胞胎。str拥有的所有方法,bytes类型都适用。
str与bytes的区别:
1、英文字母:
str:
表现形式:s1 =“summer”
内部编码方式:Unicode
bytes:
表现形式:b1 = b"summer" # 字符串前面的b表示bytes类型
内部编码方式:非Unicode
2、中文
str:
表现形式:s1 =“夏天”
内部编码方式:Unicode
bytes:
表现形式:b1 = b'\xe4\xb8\xad\xe5\x9b\xbd'
内部编码方式:非Unicode
你想将一部分内容(字符串)写入文件,或者通过网络socket传输,这部分内容(字符串)必须转化成bytes类型。

1)str---> bytes :encode
转换为utf-8
s = '中国'
s1 = s.encode('utf-8')
print(s1) # b'\xe4\xb8\xad\xe5\x9b\xbd' 一个 \ 表示一位,上面的输出,可以看出占用了6位。
s = 'summer'
s1 = s.encode('utf-8')
print(s1) # b'summer'
转换为gbk
s = 'hello girl'
s1 = s.encode('gbk')
print(s1) # b'hello girl'
2)bytes ---> str :decode
s1 = b'\xe4\xb8\xad\xe5\x9b\xbd'
s2 = s1.decode(encoding='utf-8')
print(s2) # 中国
s1 = '天气晴朗'
d1 = s1.encode('gbk')
print(d1) # b'\xcc\xec\xc6\xf8\xc7\xe7\xc0\xca'
s2 = d1.decode('gbk')
print(s2) # 天气晴朗
utf-8和gbk不能直接互相转化,必须通过unicode才可以。
s = 'summer'
s1 = s.encode('gbk') # unicode转换为gbk
s2 = s1.decode('gbk') # gbk转换为unicode
s2.encode('utf-8') # unicode转换为utf-8
print(s2) # 执行输出:summer
只有将字符串写入文件或者发送数据时,才需要用到编码转换。
例如,运行以下代码,写入中文时,
qc_summary = data+"/Assembly.stat.txt" with open(qc_summary,'w') as file: file.write("指标名称\t实际值\t评价标准\t是否达标\n")
报错:
Traceback (most recent call last):
file.write("\u6307\u6807\u540d\u79f0\t\u5b9e\u9645\u503c\t\u8bc4\u4ef7\u6807\u51c6\t\u662f\u5426\u8fbe\u6807\n") File "/share/nas2/genome/biosoft/Python/3.7.3/lib/python3.7/encodings/iso8859_15.py", line 19, in encode return codecs.charmap_encode(input,self.errors,encoding_table)[0] UnicodeEncodeError: 'charmap' codec can't encode characters in position 0-3: character maps to <undefined>
加入encoding='utf-8',就好了
qc_summary = data+"/Assembly.stat.txt" with open(qc_summary,'w',encoding="utf-8") as file: file.write("指标名称\t实际值\t评价标准\t是否达标\n")
或者将python版本换为2,然后加入如下代码,即可使用中文
import sys reload(sys) sys.setdefaultencoding( "utf-8" )
十六、深浅copy
1、赋值运算:等号两边的变量指向的内存地址是一样的
li_1 = [1,2,3]
li_2 = li_1
li_2.append(456)
print(li_1)
print(li_2)
执行输出:
[1, 2, 3, 456]
[1, 2, 3, 456]
对于赋值运算,指向的是同一个内存地址。字典,列表,集合都一样
2、浅copy:
l2=l1.copy() 第一层的内存地址不一样,但是第二层的内存地址还是一样的。
copy不是指向一个,在内存中开辟了一个内存空间
li1 = [1,2,3] li2 = li1.copy() li2.append(111) print(li1) # [1, 2, 3] print(li2) # [1, 2, 3, 111] print(id(li1)) # 2204788806984 print(id(li2)) # 2204788808776 发现,内存地址是不一样的
l1=[1,2,3,[22,]]
l2=l1.copy()
l1.insert(0,'hello')
print(l2) #第一层,l2与l1的内存地址不同没有变
l1[-1].append('taibai')
print(l2) #第二层,l2和l1的内存地址相同,l2改变了
输出结果是:
[1, 2, 3, [22]]
[1, 2, 3, [22, 'taibai']]
为什么呢?因为内部的列表内存地址是独立的一个,一旦修改,其他引用的地方,也会生效。
对于浅copy来说,第一层创建的新的内存地址,而从第二层开始,指向的都是同一个内存地址
切片是浅copy
3、深copy
import copy # 深copy必须要导入一个模块copy
l2 = l1.deepcopy
对于深copy来说,两个变量的内存地址是完全独立的,无论改变任何一个元素(无论多少层),另一个不会跟着改变
import copy
li_1 = [1,2,[1,2,3],4]
li_2 = copy.deepcopy(li_1)
#内部列表添加一个值
li_1[2].append(666)
print(li_1)
print(li_2)
执行输出:
[1, 2, [1, 2, 3, 666], 4]
[1, 2, [1, 2, 3], 4]
浅copy,第一层是新的,从第二层开始,共用一个内存地址
深copy,每一层,是完全用新的内存地址
对于深copy来说,两个是完全独立的,改变任意一个的任何元素(无论多少层),另一个绝对不改变
下面的例子,l2是深copy还是浅copy
l1 = [1,2,3,[22,33]]
l2 = l1[:]
l1[3].append(666)
print(l2)
执行输出:
[1, 2, 3, [22, 33, 666]]
对于切片来说,它是属于浅copy

