

【昇腾开发全流程】MindSpore华为云模型训练
 学会如何安装配置华为云ModelArts、开发板Atlas 200I DK A2。
并打通一个Ascend910训练到Ascend310推理的全流程思路。
> 在本篇章,我们首先开始训练阶段!
学会如何安装配置华为云ModelArts、开发板Atlas 200I DK A2。
并打通一个Ascend910训练到Ascend310推理的全流程思路。
> 在本篇章,我们首先开始训练阶段!
前言
学会如何安装配置华为云ModelArts、开发板Atlas 200I DK A2。
并打通一个Ascend910训练到Ascend310推理的全流程思路。
在本篇章,我们首先开始训练阶段!
训练阶段
A. 环境搭建
MindSpore 华为云 模型训练
Step1 创建OBS并行文件
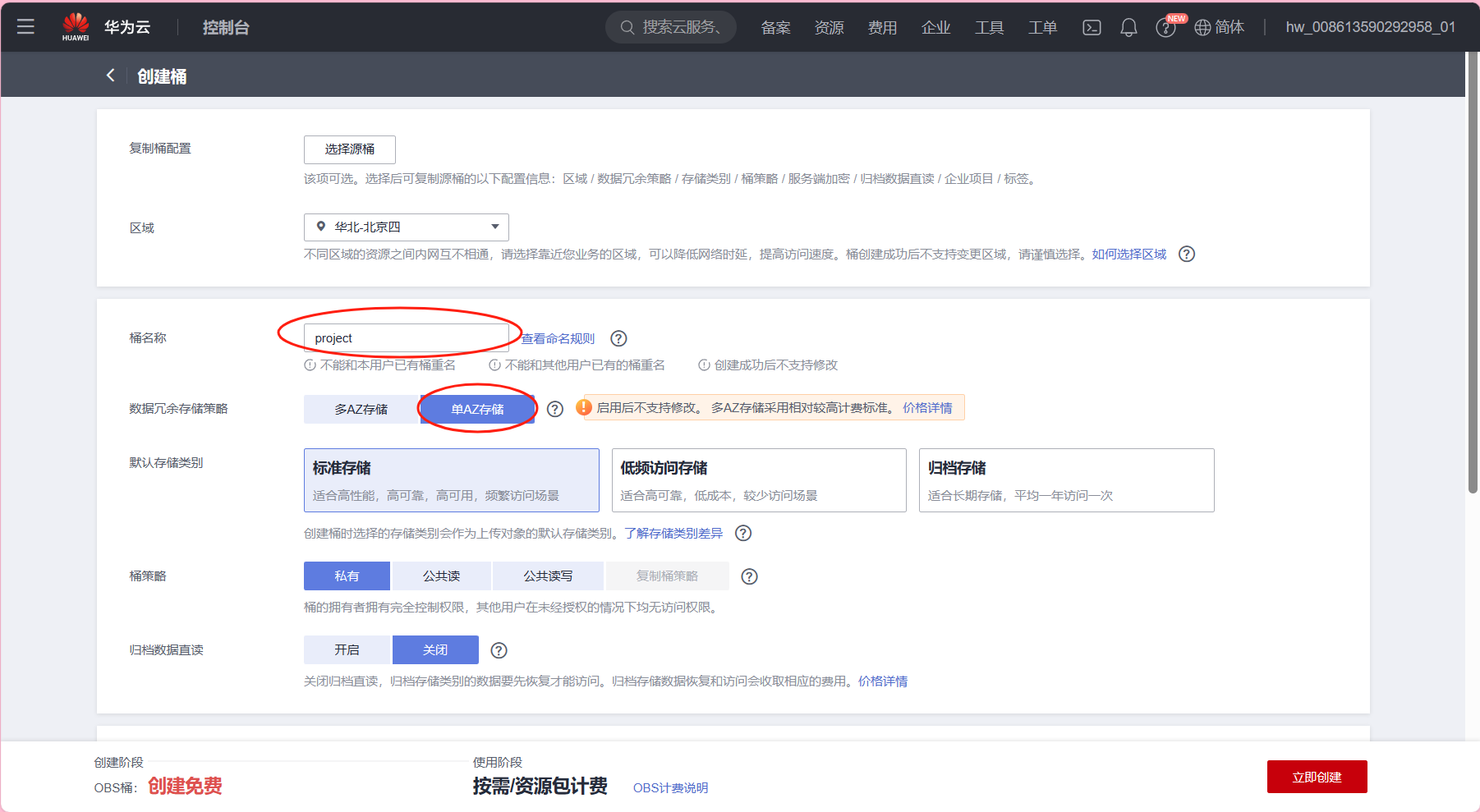
- 登录华为云 -> 控制台 -> 左侧导航栏选择“对象存储服务 OBS” ->
在左侧导航栏选择“桶列表” -> 单击右上角“创建桶”
如下图所示:
- 在左侧列表中的“并行文件系统” -> 单击右上角“创建并行文件系统”。
如下图所示:

进行以下配置:
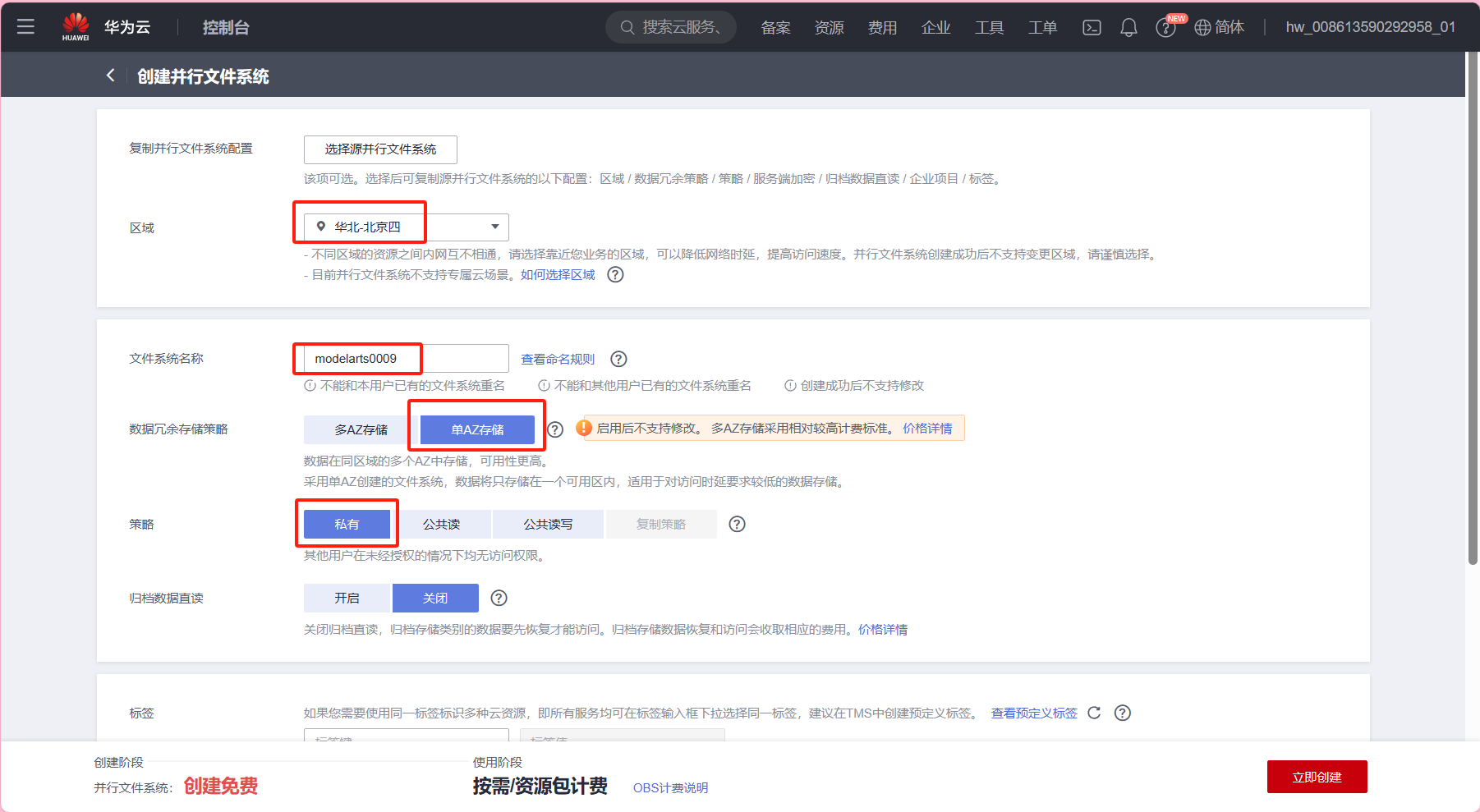
主要参数信息如下,其余配置请保持默认配置
区域:选择“华北-北京四”
文件系统名称:自定义,本例使用modelarts0009
(请使用modelarts作为文件系统前缀,注意名称为全局唯一)
数据冗余存储策略:选择“单AZ存储”
策略:选择“私有”
Step2 上传数据文件至OBS并行文件系统
- 点击已创建的并行文件系统 -> 点击“新建文件夹”
输入文件夹的名称,这里命名为input
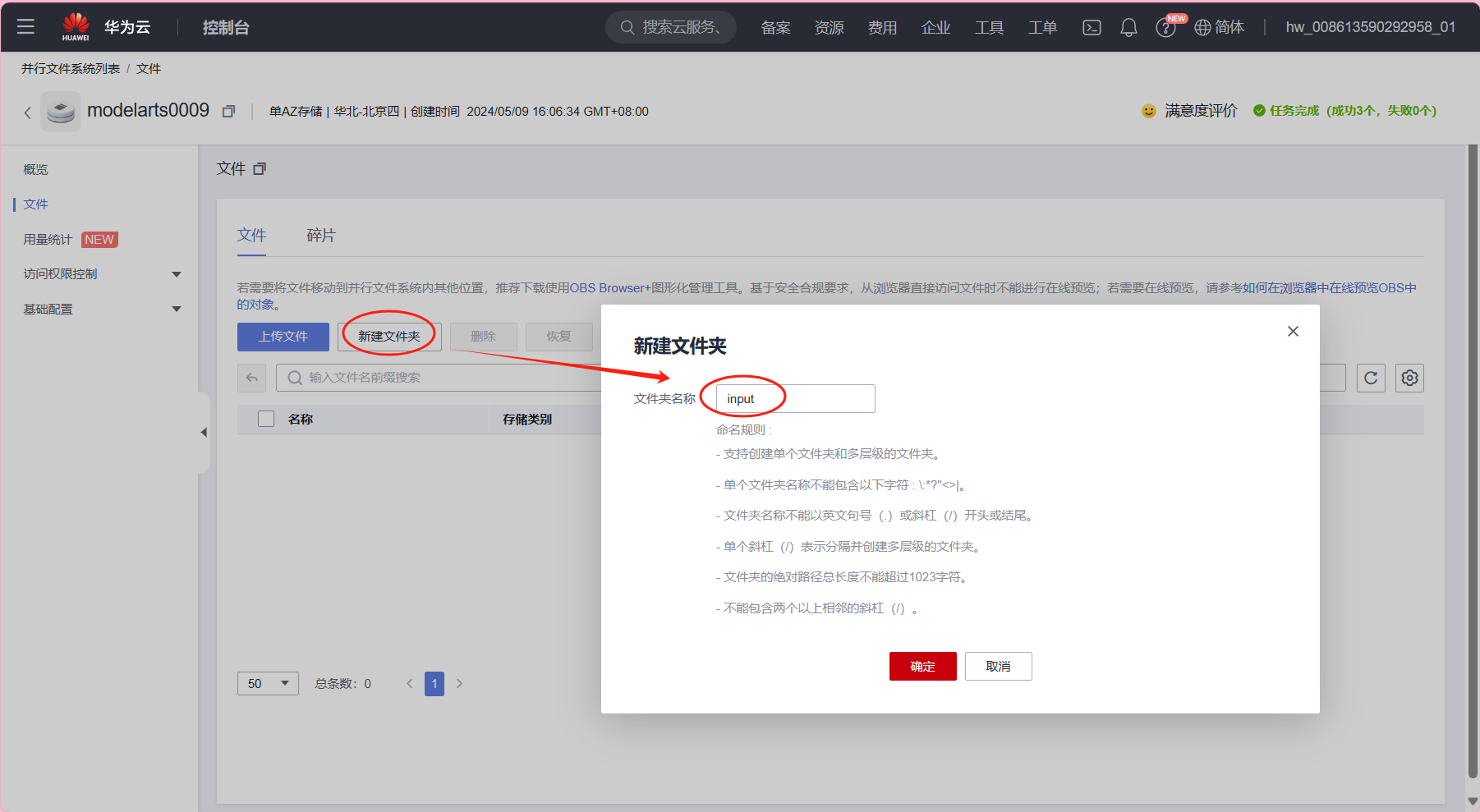
- 进入该文件夹中 -> 点击“上传文件”:
将准备好的项目工程文件压缩包上传至该OBS中。
Step3 基于ModelArts创建Notebook编程环境
-
在“全局配置”页面查看是否已经配置授权,允许ModelArts访问OBS:
登录华为云 -> 控制台 -> 左侧导航栏选择“ModelArts” -> 在左侧导航栏选择“全局配置” -> 单击“添加授权”
首次使用ModelArts:直接选择“新增委托”中的“普通用户”权限
-
登录华为云 -> 控制台 -> 左侧导航栏选择“ModelArts” -> 在左侧导航栏选择“开发环境”-> “Notebook” -> 点击“创建”
进行以下配置:主要参数信息如下,其余配置请保持默认配置
名称:自定义,本例使用notebook-test
自动停止:自行选择,本例选择4小时
镜像:选择“公共镜像”,并选择“mindspore_1.10.0-cann_6.0.1-py_3.7-euler_2.8.3”
资源类型:选择“公共资源池”
磁盘规格:使用50GB
Step4 为Notebook编程环境添加训练阶段项目工程文件
-
点击已创建的Notebook -> “存储配置” -> “添加数据存储”
进行以下配置:
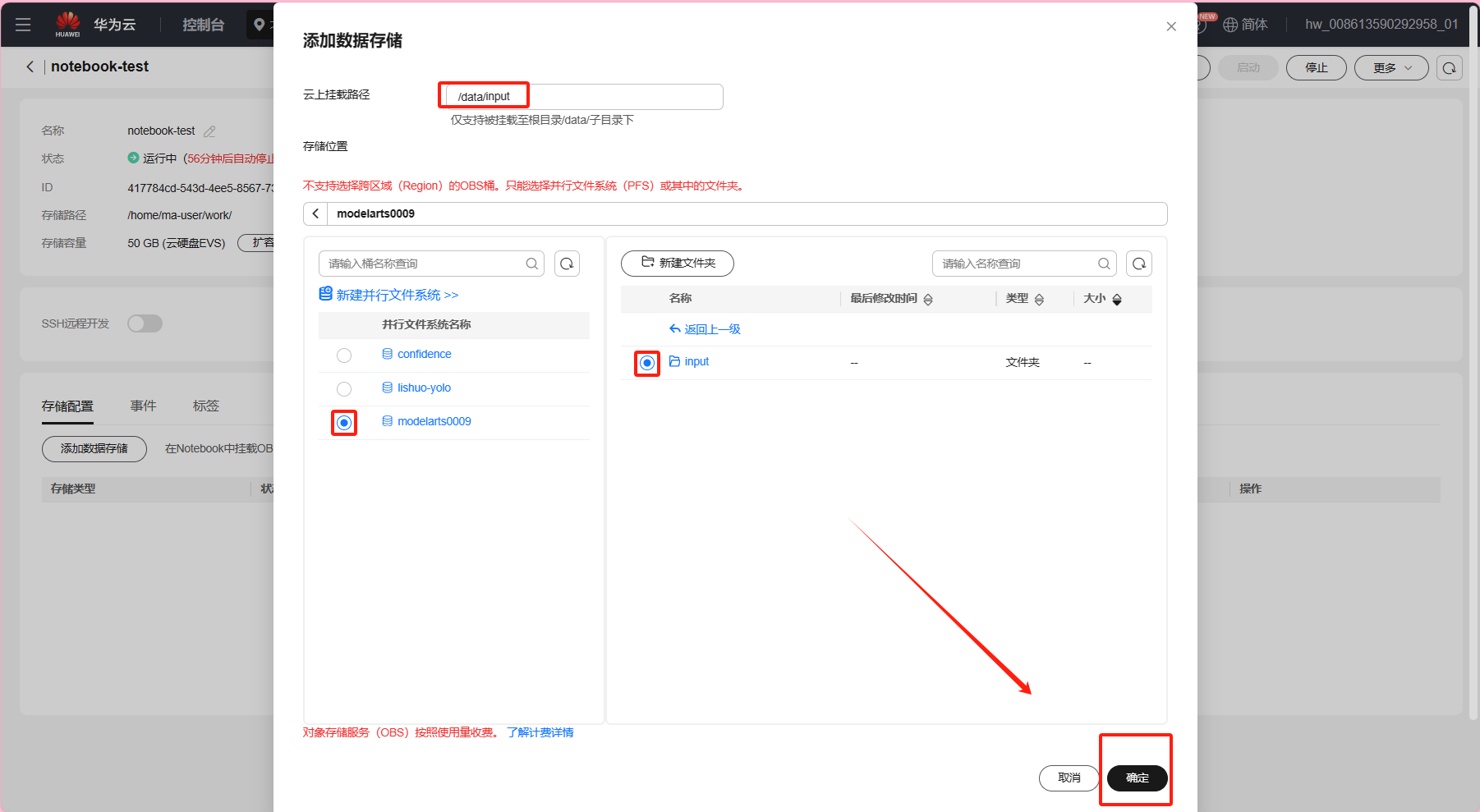
本地挂载目录:自定义创建本地挂载目录,本例使用/data/input
存储位置:选择所创建的并行文件系统(本例选择已创建的moderarts0009),以及数据集所在的目录input -
返回Notebook界面 -> 点击“打开”notebook-test ->
打开“Terminal”命令行终端界面 ->
执行以下命令,创建用于测试的test文件
touch /data/input/test
再执行以下命令,可以看到你刚创建的test文件&先前上传的文件
ls /data/input -
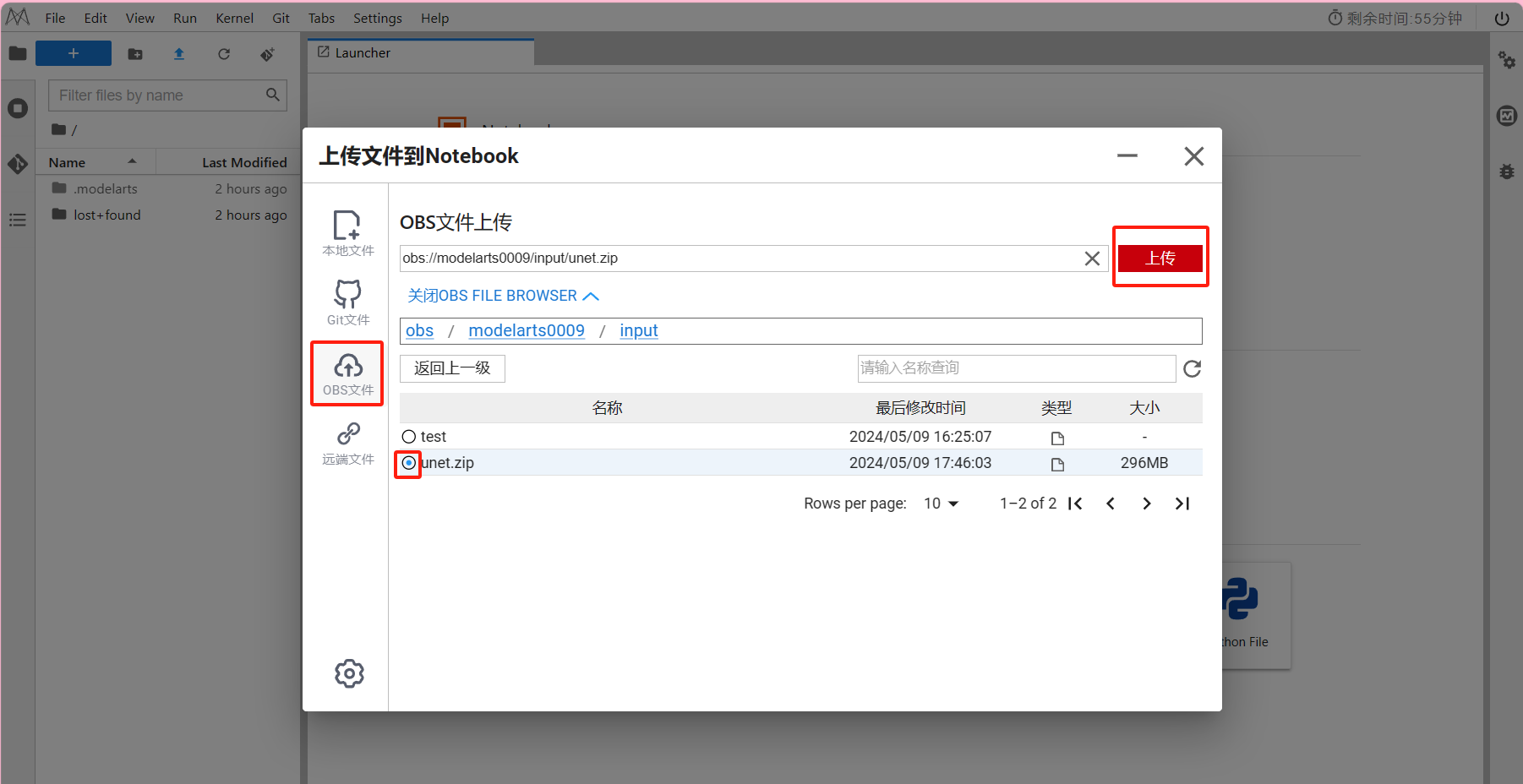
上传
这里选择OBS文件上传,
因为这里本地上传限制为100M文件。
-
解压
打开“Terminal”命令行终端界面 ->
执行以下命令,查看是否在正确的路径下
pwd
ls -l
执行以下命令,解压项目工程文件压缩包
(这里以工业质检Unet为例,具体代码可参考文末学习资源推荐)
unzip unet.zip
unzip unet_sdk.zip
- 训练阶段工程目录结构如下:
├──unet ├──data // 预处理后的数据集文件夹 ├──raw_data // 原始数据集 ├──out_model // 模型导出保存文件夹 ├──pred_visualization // 可视化图片保存文件夹(需要自己创建) ├──src // 功能函数 │ ├──unet_medical // U-Net网络 │ ├──unet_nested // U-Net++网络 │ ├──config.py // 配置文件 │ ├──data_loader.py // 数据加载 │ ├──eval_callback.py // 训练时评估回调 │ ├──loss.py // 损失函数 │ ├──utils.py // 工具类函数 ├──draw_result_folder.py // 文件夹图片可视化 ├──draw_result_single.py // 单张图片可视化 ├──eval.py // 模型验证 ├──export.py // 模型导出,ckpt转air/mindir/onnx ├──postprocess.py // 后处理 ├──preprocess.py // 前处理 ├──preprocess_dataset.py // 数据集预处理 ├──train.py // 模型训练 ├──requirements.txt - 模型转换工程目录结构如下:
├── unet_sdk ├── model │ ├──air2om.sh // air模型转om脚本 │ ├──xxx.air //训练阶段导出的air模型 │ ├──aipp_unet_simple_opencv.cfg // aipp文件
注:
接下来就可以开始旅程,进入训练阶段。
若中途暂停实验,记得做停止资源操作,消耗最少费用;
若返回继续实验,再次启动Notebook编程环境;
若完成了本实验,最后是释放资源操作,为了停止计费。
一. 配置文件参数和数据预处理
MindSpore 数据集预处理preprocess_dataset.py文件需调用如下脚本:
文件参数脚本src/config.py文件。
文件参数脚本为src/config.py,包括
unet_medical,
unet_nested,
unet_nested_cell,
unet_simple,
unet_simple_coco
共5种配置,表示模型与数据集之间的组合。
包含超参数、数据集路径等文件参数
Step 运行脚本
-
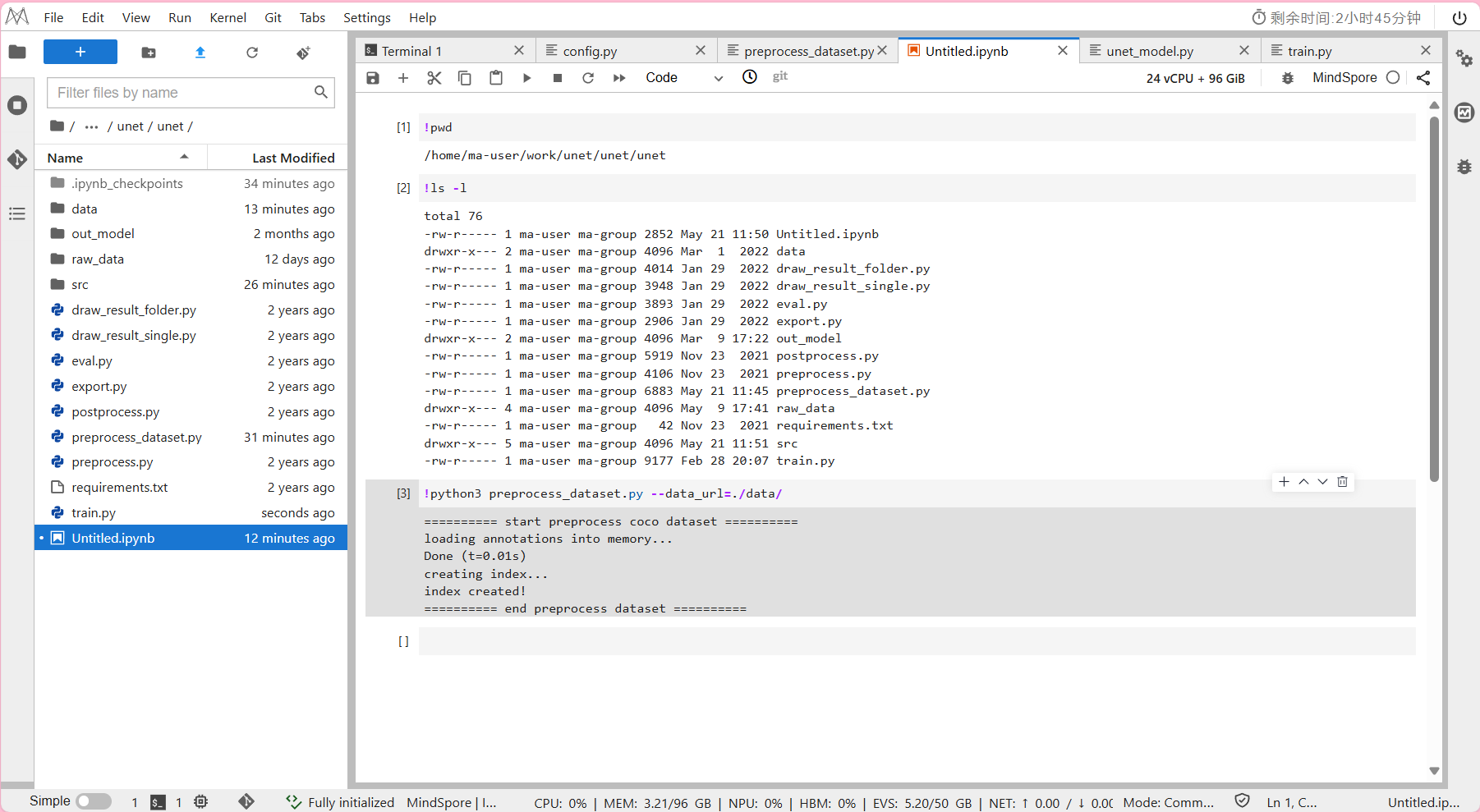
新建NoteBook中:查看是否在工程目录unet/路径下
!pwd -
进入NoteBook中:运行示例
!python3 preprocess_dataset.py --data_url=./data/
其中--data_url:数据集预处理后的保存路径。
- 预计数据集预处理所需时间约为10分钟。
预处理完的数据集会保存在/unet/data/文件夹下。
输出结果:
二. 模型训练
MindSpore模型训练 需调用如下脚本:
preprocess_dataset.py:将类coco数据集 转化成 模型训练需要数据格式。
src/unet_xxx/:存放 unet/unet++ 模型结构。
src/data_loader.py:存放 数据加载功能函数。
src/eval_callback:存放 cb 函数,用于训练过程中进行eval.
src/utils.py: mindspore 自定义 cb 函数,自定义 metrics 函数。
train.py
Step 运行脚本
- 进入NoteBook中:运行示例
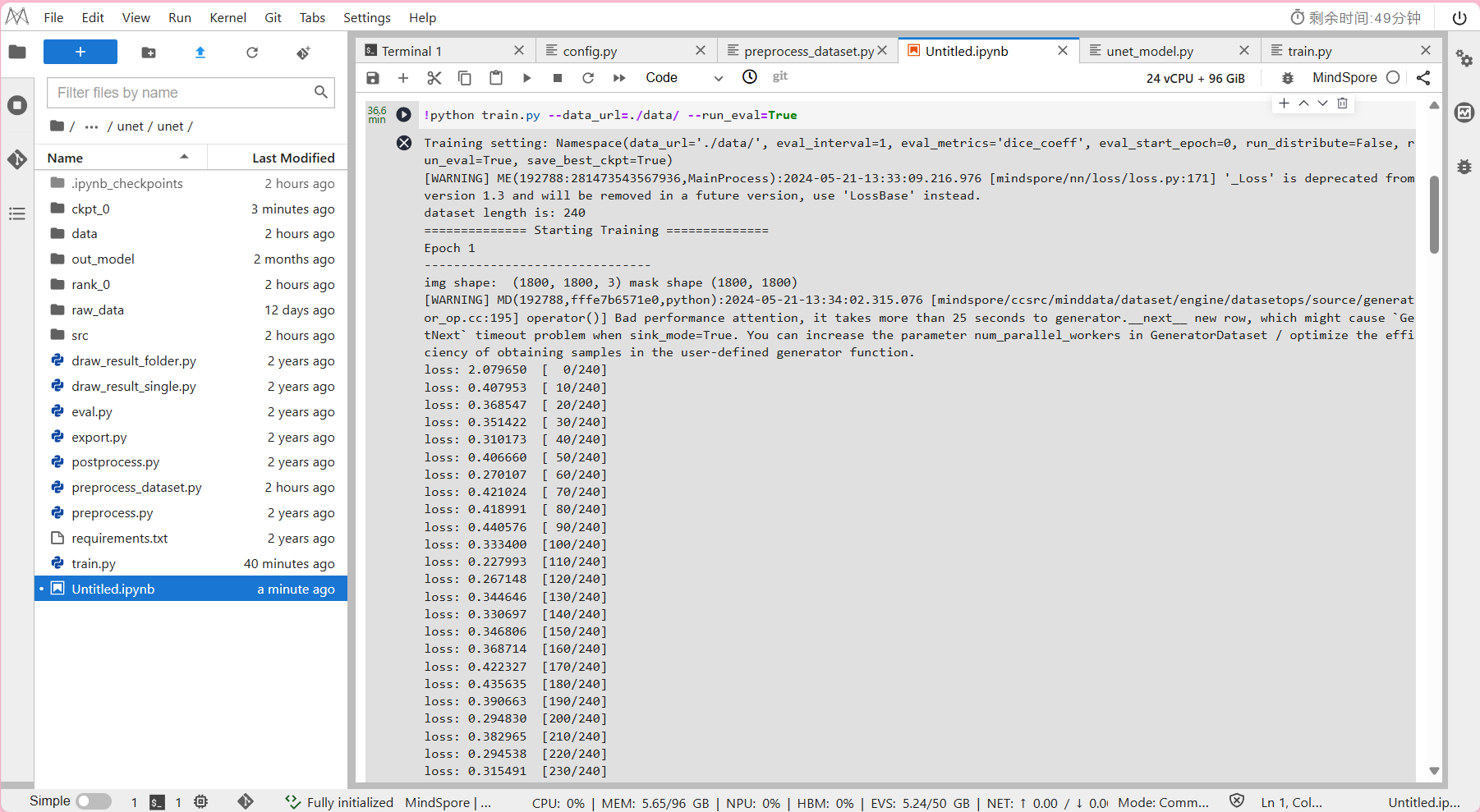
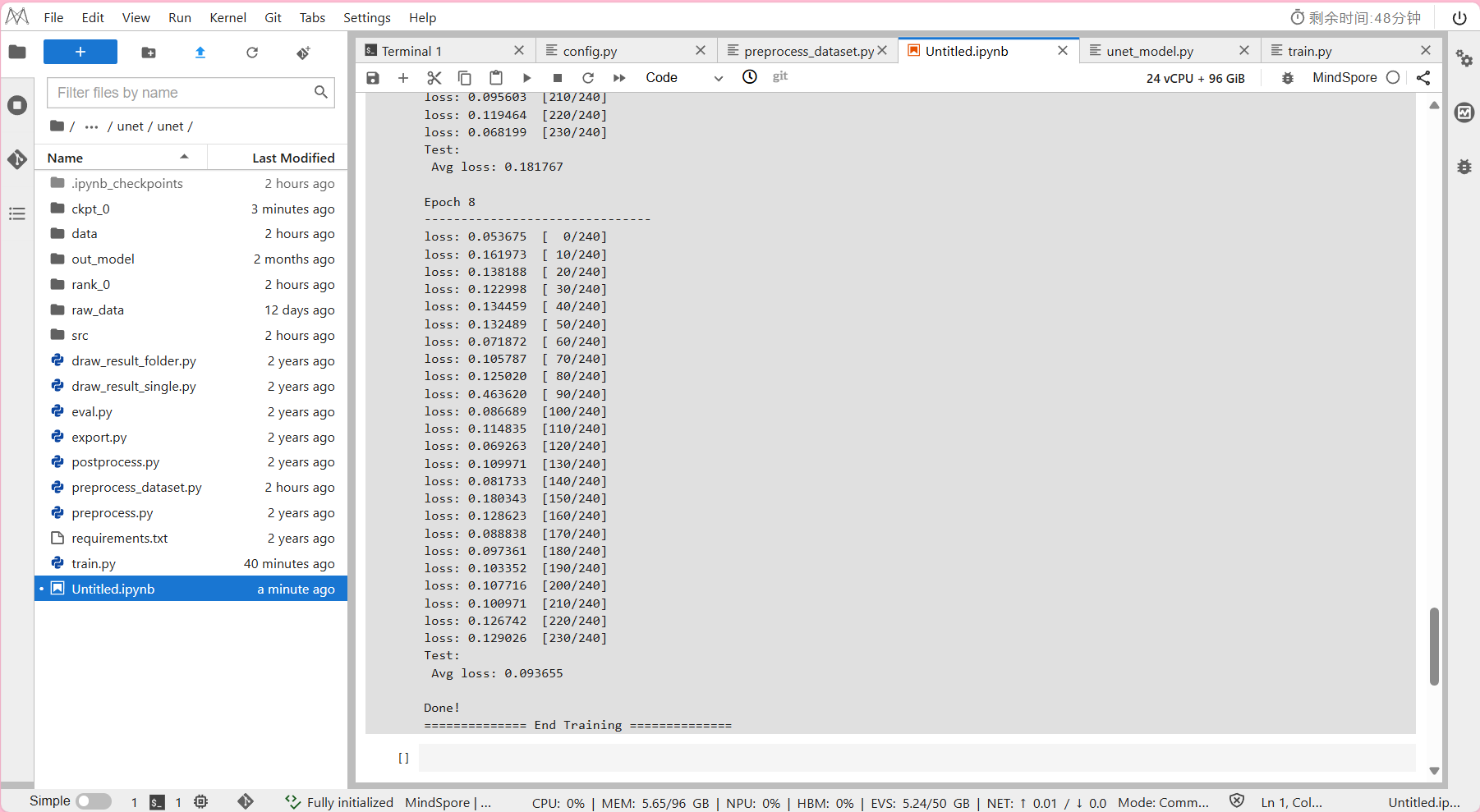
!python train.py --data_url=./data/ --run_eval=True
其中--data_url: 数据集输入路径。
其中--run_eval: True 表示训练过程中同时进行验证。
- 预计模型训练所需时间约为36分钟。
输出结果:
三. 模型推理
MindSpore模型推理 需调用如下脚本:
src/unet_xxx/:存放unet/unet++模型结构。
src/data_loader.py:存放数据预处理,数据加载功能函数。
src/utils.py:mindspore自定义cb函数,自定义metrics函数。
eval.py
Step 运行脚本
- 进入NoteBook中:运行示例
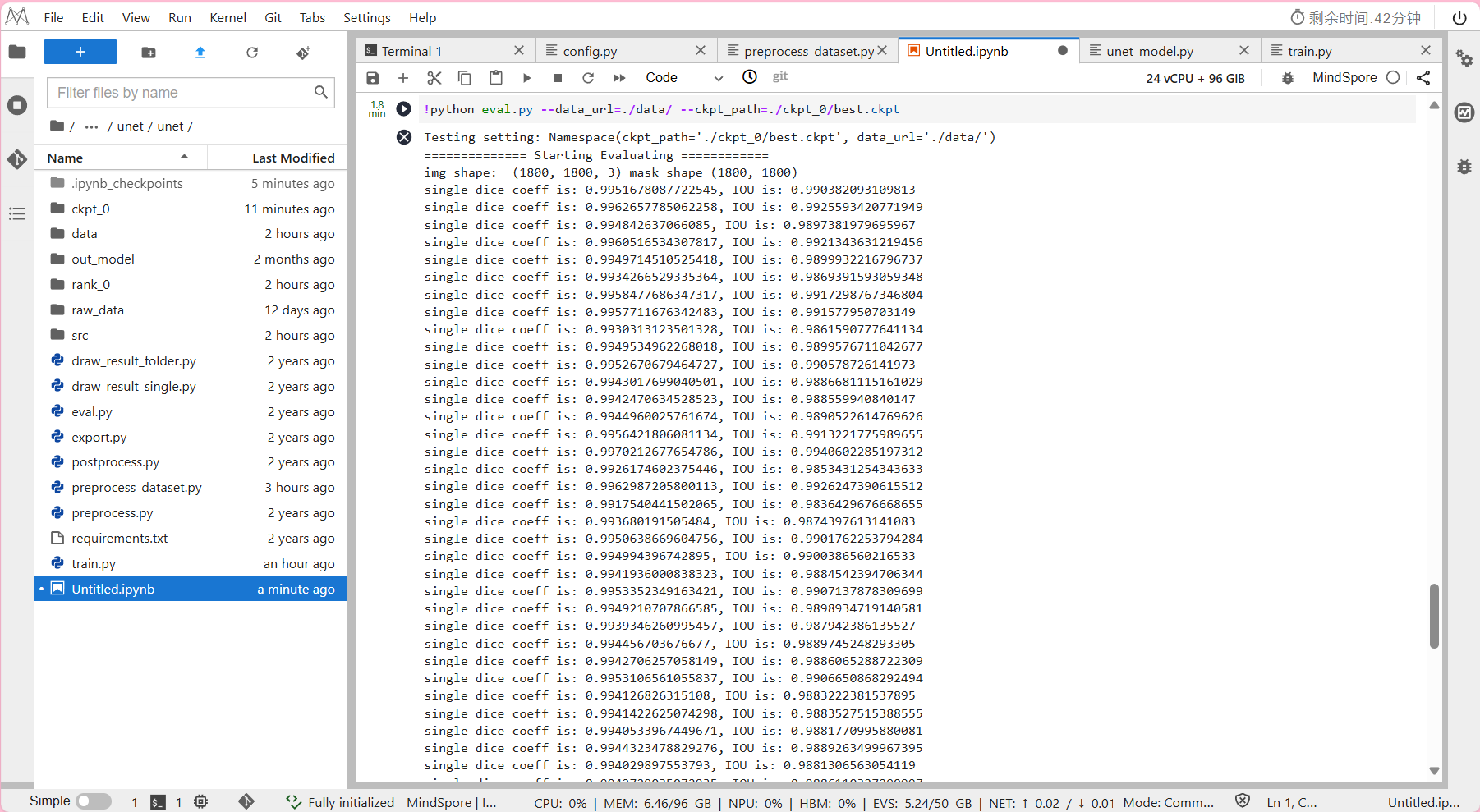
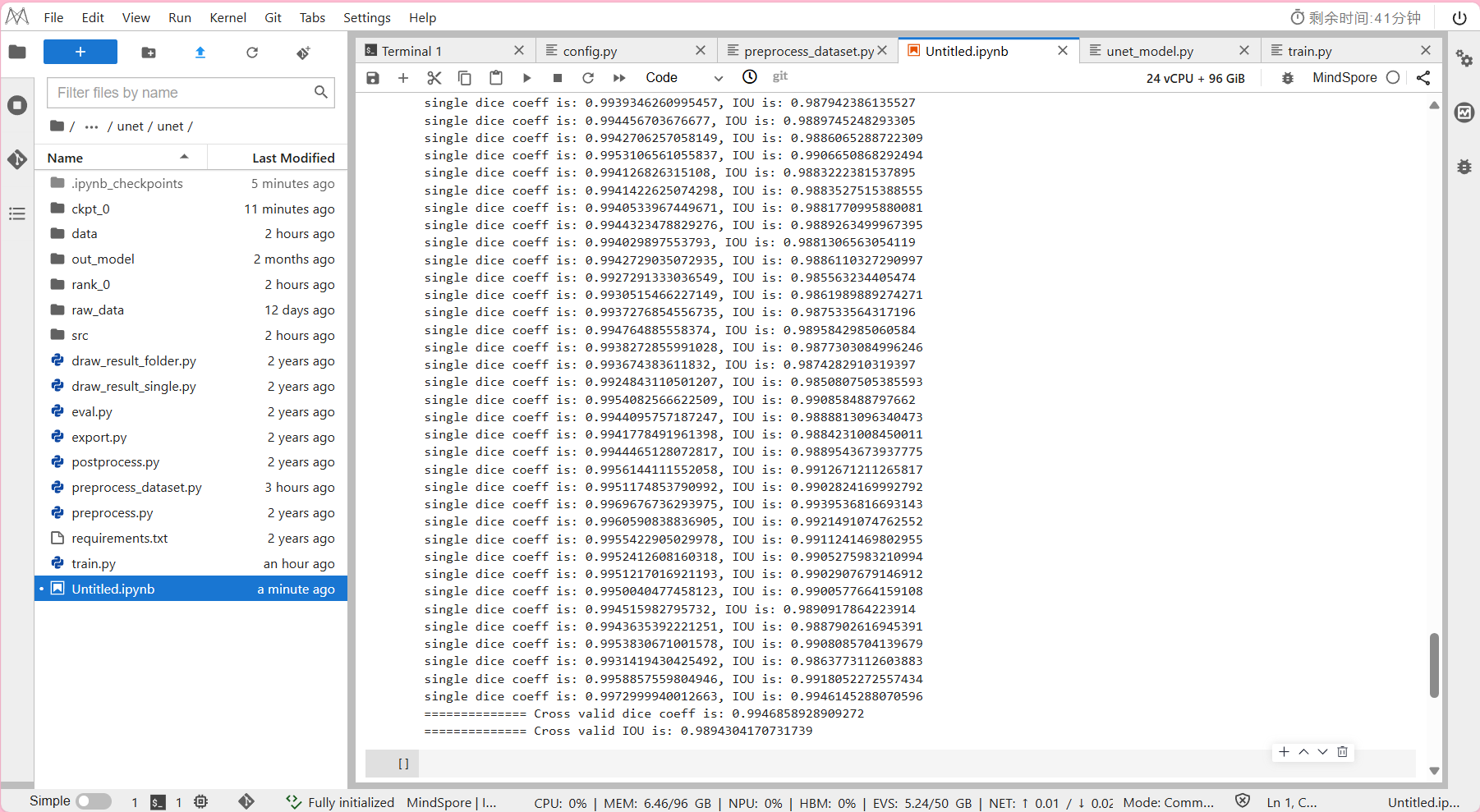
!python eval.py --data_url=./data/ --ckpt_path=./ckpt_0/best.ckpt
其中--data_url:数据集输入路径。
其中--ckpt_path:ckpt 读取路径
- 预计模型推理所需时间约为2分钟。
输出结果:
注:
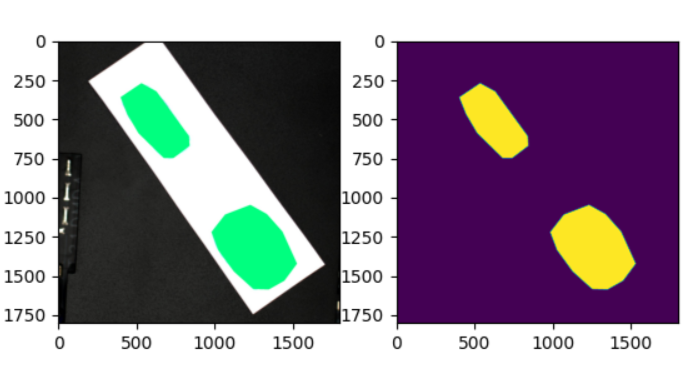
IOU(Intersection over Union)是一个度量函数,
用来描述两个物体边界框的重叠程度(取值范围为[0,1]),
重叠的区域越大,IOU值就越大。
四. 结果可视化
可以通过画图的方式将图像的结果可视化,方便查看。
可视化方法有两种。
方法一 单张图片可视化
draw_result_single.py:单张图片可视化,
输出单张图片的裁剪画图结果crop_plot.png和模型预测的结果predict_plot.png。
Step 运行脚本
-
查看工程目录unet/路径下
确保已经事先创建好
可视化图片保存文件pred_visualization文件夹 -
进入NoteBook中:运行示例
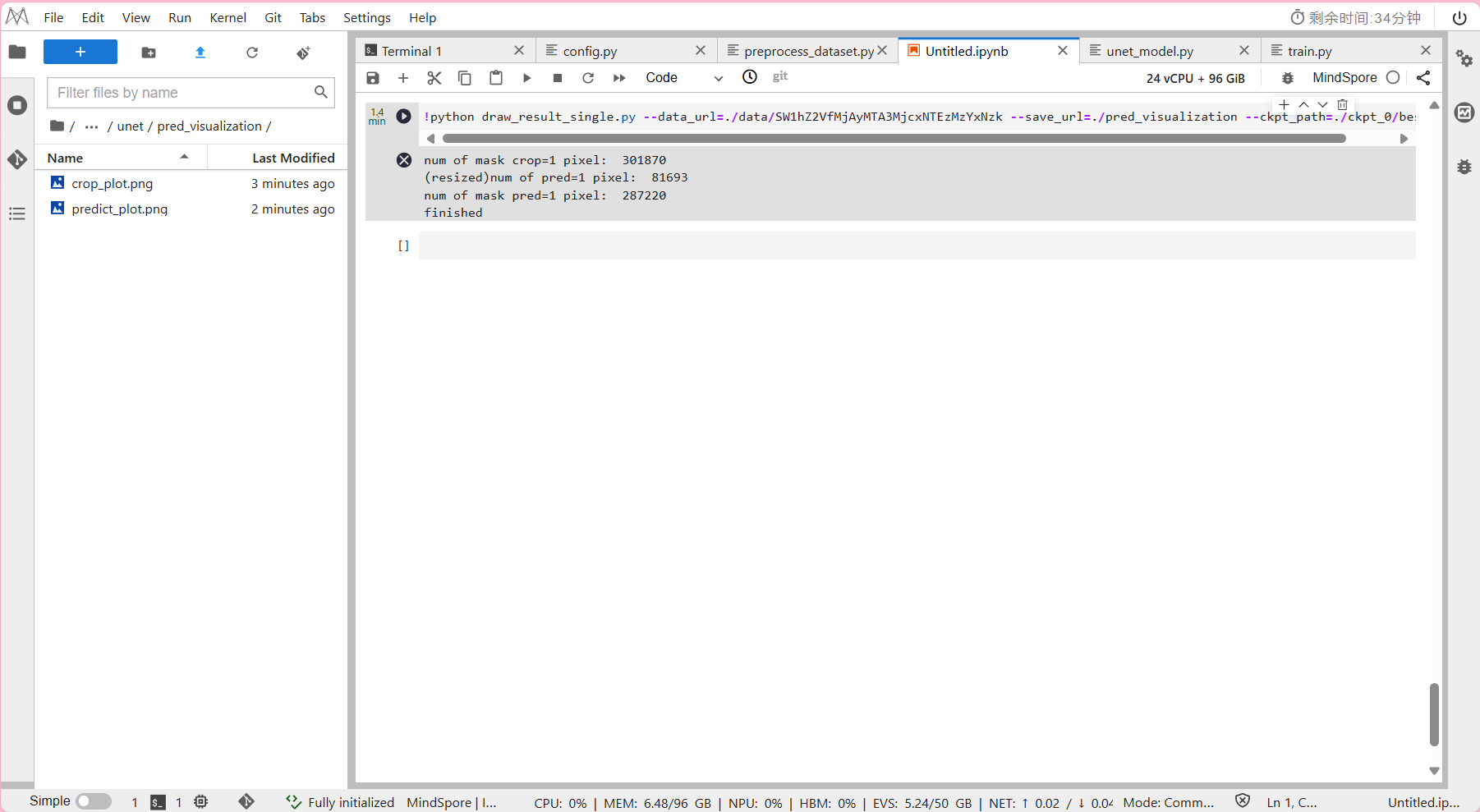
!python draw_result_single.py --data_url=./data/SW1hZ2VfMjAyMTA3MjcxNTEzMzYzNzk --save_url=./pred_visualization --ckpt_path=./ckpt_0/best.ckpt
其中--data_url:数据集输入路径(到单张图像)。
其中--save_url:输出图像保存路径。
其中--ckpt_path:ckpt读取路径。
- 单张图片可视化所需时间约为1分钟。
可视化完的图片会保存在/unet/pred_visualization文件夹下。
输出结果:
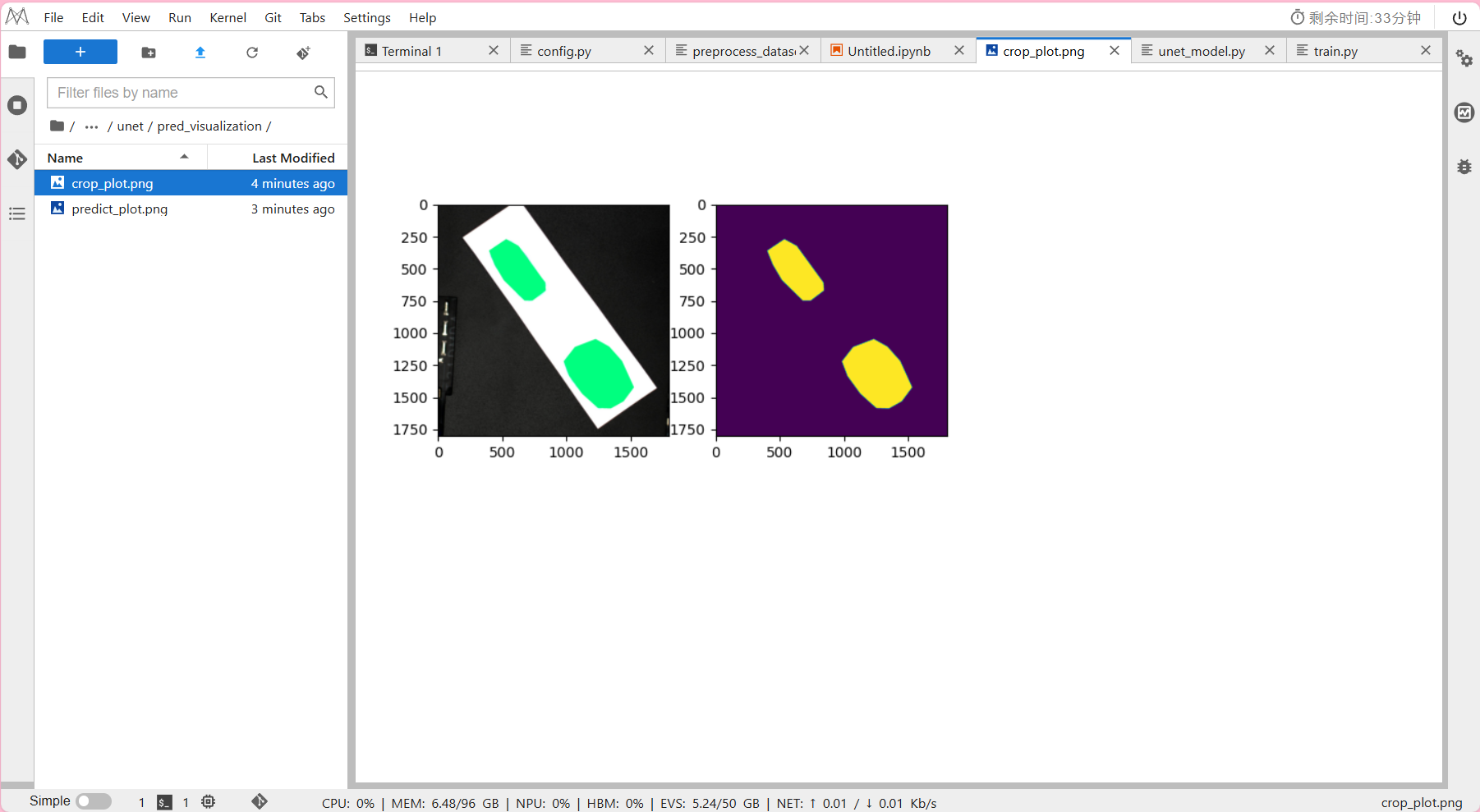
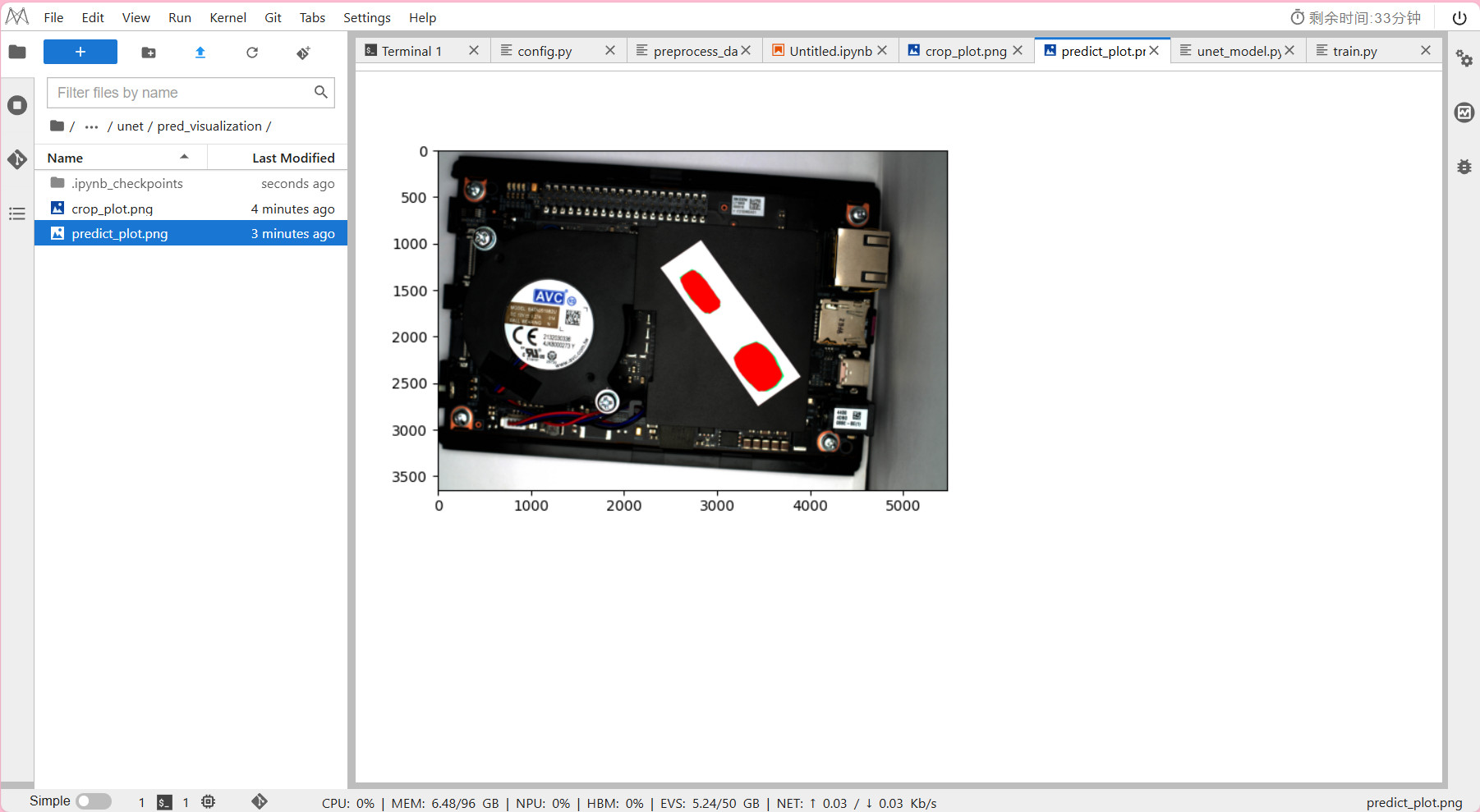
方法二 文件夹图片可视化
draw_result_folder.py:文件夹图片可视化,
输出文件夹内图片的模型预测结果predict.png。
Step 运行脚本
-
查看工程目录unet/路径下
确保已经事先创建好
可视化图片保存文件pred_visualization文件夹 -
进入NoteBook中:运行示例
!python draw_result_folder.py --data_url=./data/ --save_url=./pred_visualization --ckpt_path=./ckpt_0/best.ckpt
其中--data_url:数据集输入路径(到图像文件夹)。
其中--save_url:输出图像保存路径。
其中--ckpt_path:ckpt读取路径。
- 文件夹图片可视化所需时间约为10分钟。
可视化完的图片会保存在/unet/pred_visualization文件夹下。
输出结果:
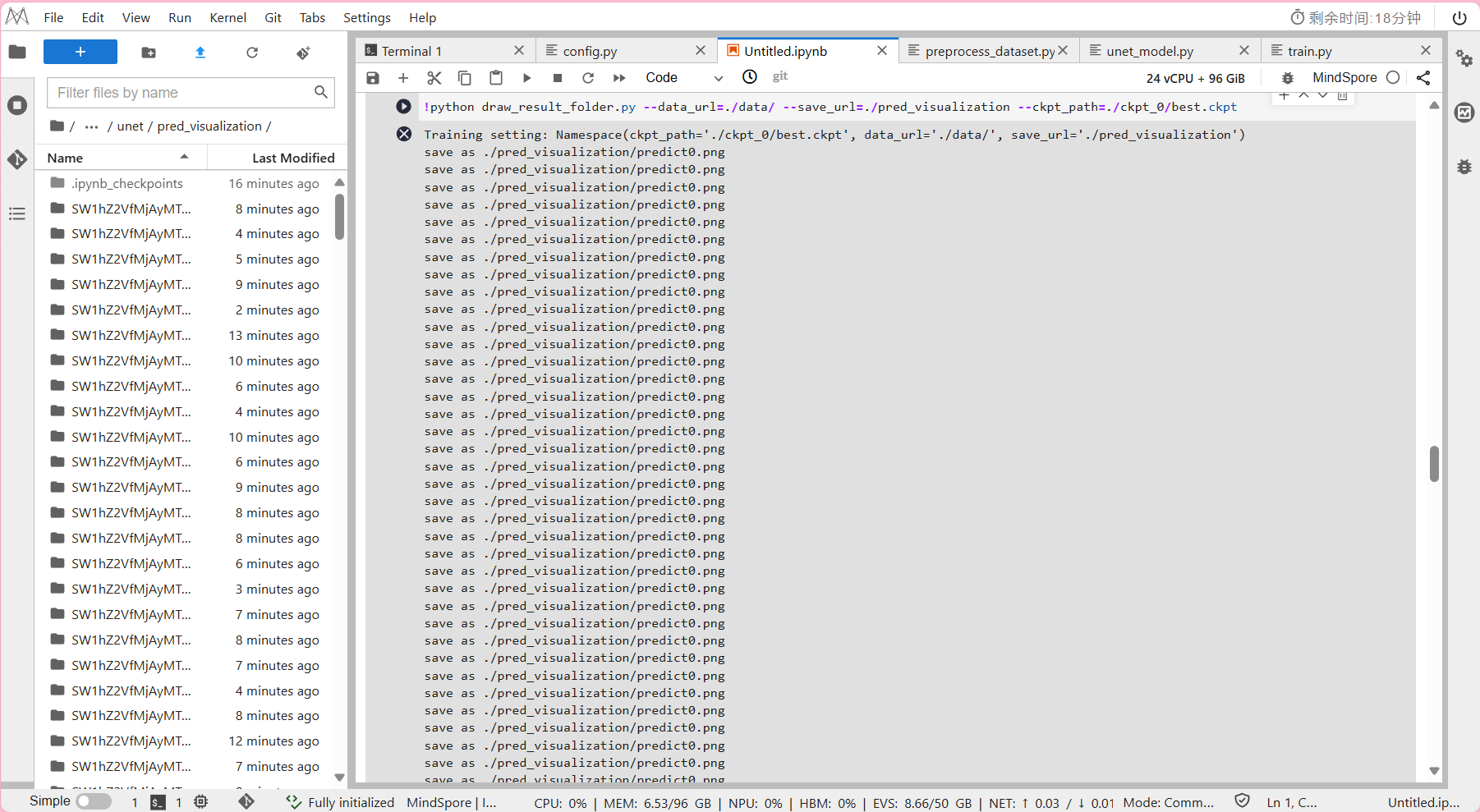
五. 模型保存
如果想在昇腾AI处理器上执行推理,
可以通过网络定义和CheckPoint生成AIR格式模型文件。
Step 运行脚本
- 进入NoteBook中:运行示例
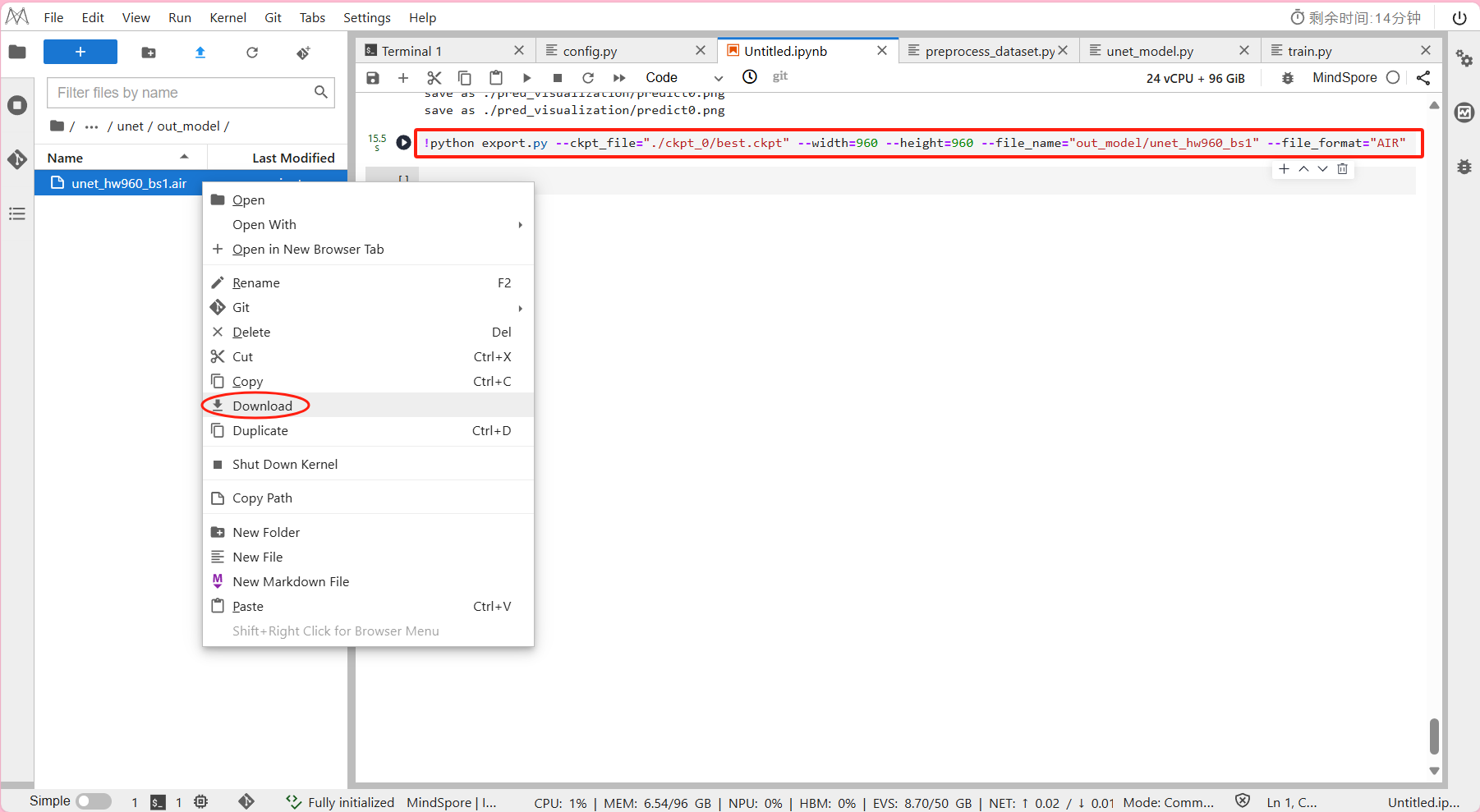
!python export.py --ckpt_file="./ckpt_0/best.ckpt" --width=960 --height=960 --file_name="out_model/unet_hw960_bs1" --file_format="AIR"
其中–-ckpt_file: ckpt路径。
其中--width: 模型输入尺寸。
其中--height: 模型输入尺寸。
其中--file_name: 输出文件名。
其中--file_format: 输出格式,必须为[“ONNX”, “AIR”, “MINDIR”]。
- 模型保存即导出模型的输出结果在out_model/unet_hw960_bs1.air
最后将导出的模型下载至本地,供后续推理阶段实验使用:
右键 -> Download
六. 模型转换
此处模型转换需要用到ATC工具。
详细内容&错误码请参考昇腾官网文档-使用ATC工具转换模型
Step1 上传air模型
- 将训练阶段实验模型保存的air模型上传至华为云ModelArts的unet_sdk/model/目录下
这里因为模型中有optype[ArgMaxD],因此需要在Ascend910系列芯片上执行模型转换才能成功。
(此次华为云ModelArts使用的正是Ascend910A)
而一般情况,模型训练完进行的模型转换是可以选择在开发者套件(Ascend310系列芯片)和Ubuntu系统中执行的。
(具体方法请参考昇腾官网文档-转换模型)
Step2 模型转换命令
-
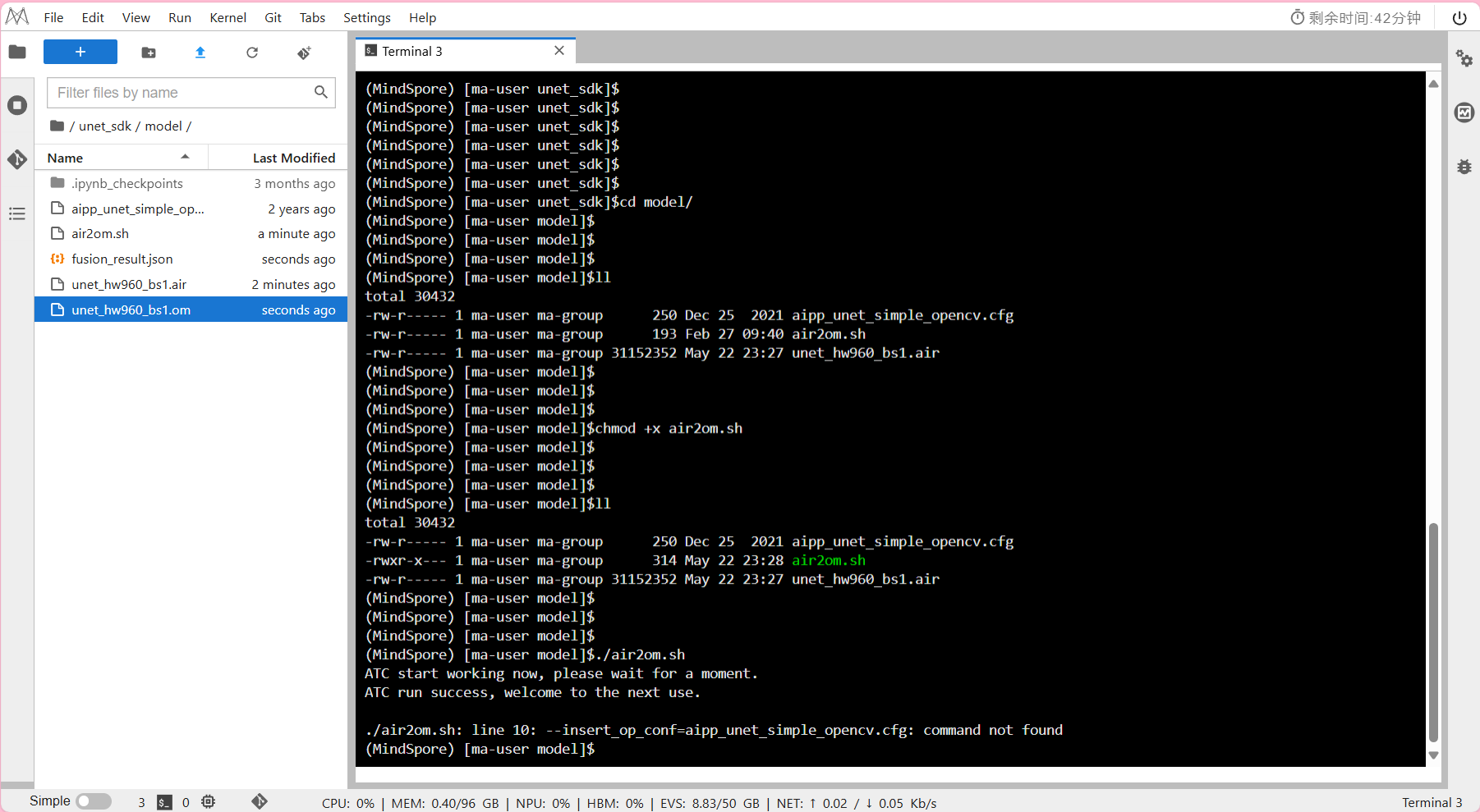
打开unet_sdk/model/air2om.sh文件
使用atc命令如下,可根据实际开发情况进行修改。atc --framework=1 --model=unet_hw960_bs1.air --output=unet_hw960_bs1 --input_format=NCHW --soc_version=Ascend910A --log=error --insert_op_conf=aipp_unet_simple_opencv.cfg本实验将训练阶段实验模型保存的air模型转为昇腾Al处理器支持的om格式离线模型
注意:air 模型转 om 只支持静态 batch,这里 batchsize=1。
其中--framework:原始框架类型。
其中--model:原始模型文件路径与文件名。
其中--output:转换后的离线模型的路径以及文件名。
其中--input_format:输入数据格式。
其中--soc_version:模型转换时指定芯片版本。
(这句话指的是当前执行模型转换时候所在机器的芯片版本,可通过命令行终端输入npu-smi info查看)
其中--log:显示日志的级别。
其中--insert_op_conf:插入算子的配置文件路径与文件名,这里使用AIPP预处理配置文件,用于图像数据预处理。
Step3 运行脚本
-
确保在工程目录unet_sdk/model/路径下,首先查看文件权限
ls -l
(如果文件权限列中没有x,你才需要继续下一命令赋予它执行权限)
输入
chmod +x air2om.sh -
运行示例
输入
./air2om.sh
- 输出结果:
注:
到此我们在华为云上使用MindSpore的训练阶段实验就结束了。
有了导出的air模型及其模型转换出的om模型,我们就可以继续进入下一篇章:AscendCL推理阶段。
结束后记得及时关闭云上环境,避免资源浪费和产生额外的费用!!!
学习资源推荐
-
昇思官网
-
GitHub代码仓mindspore-ai / models
https://github.com/mindspore-ai/models/tree/master/official/cv

