
苏玲俐--第一次个人编程作业
| 博客班级 | <班级链接> |
|---|---|
| 作业要求 | <第一次个人编程作业> |
| 作业目标 | 采集腾讯视频里电视剧《在一起》的全部评论信息,进行词频统计,使用echarts生成词云,并将代码上传到GitHub |
| 作业源代码 | <云仓库地址> |
| 学号 | 211806130 |
@
一.时间等于金钱
| 需求分析时间 | 编程代码时间 | 资料查询及学习 | 编码行数 |
|---|---|---|---|
| 3h | 5h | 巨久,久到不想回忆 | 100+ |
二.作业分析
1.数据采集
这一部分是上学期学过的爬虫的知识,使用谷歌浏览器进入腾讯视频找到要爬取的《在一起》电视剧网页,下拉发现它的评论是需要不断点击“查看更多评论”才能获取到更多的。
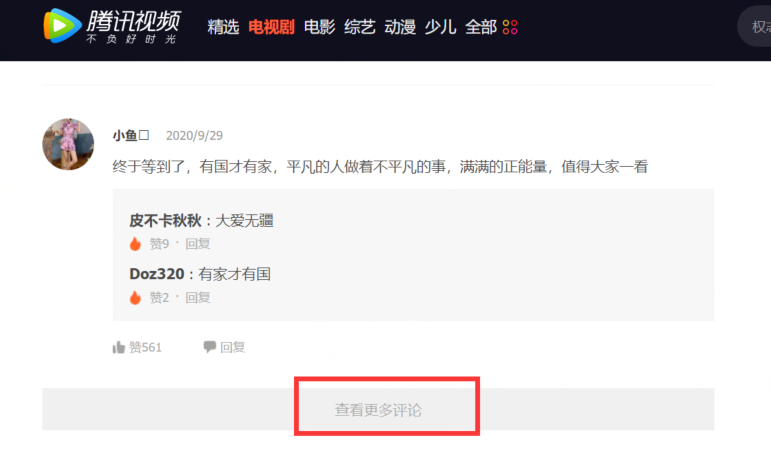
于是可以知道评论使用了Ajax异步刷新技术,就不能单纯的只分析当前页面找出规律了,因为展示的页面只有部分评论,还有大量的评论没有被刷新出来,所以要采用抓包的方法。点击开发者工具得到网页结构并分析寻找规律,后来发现评论都在v2?callback=_varticle...的“content”里面,于是可以根据这个进行爬取数据了,并把它保存在txt文件中。
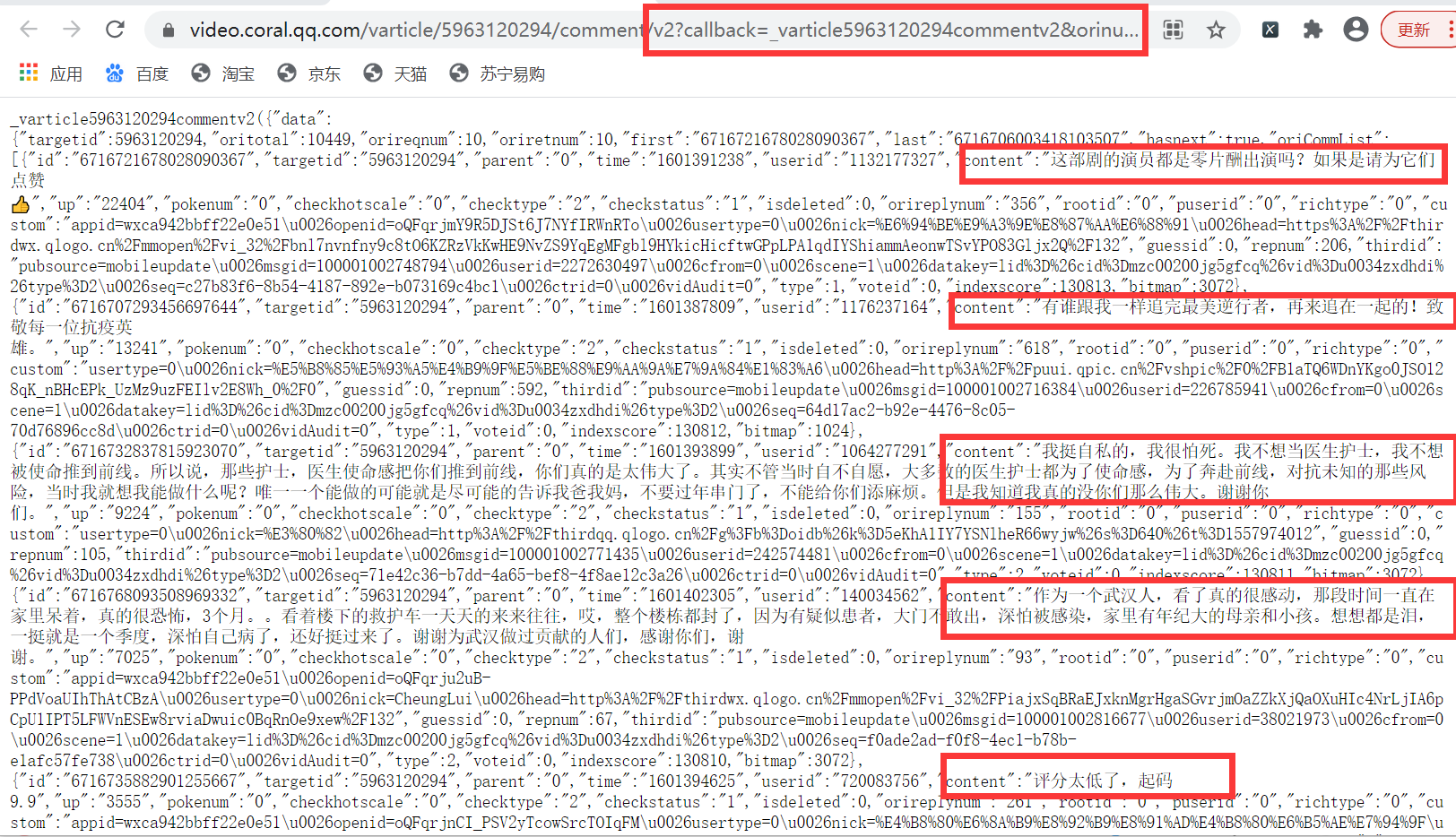
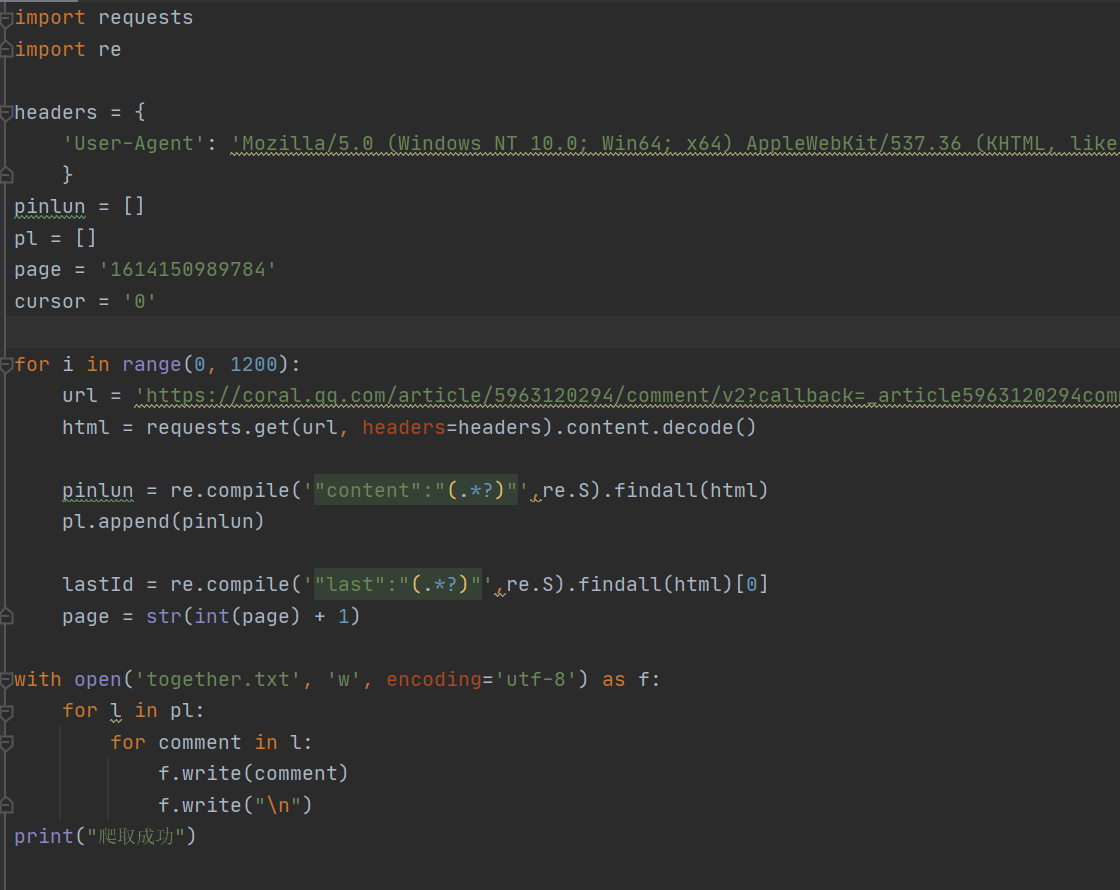
2.词频统计
在数据处理这一环节,需要使用jieba分词,这一知识点学起来比较省力,有许多详细的资料能让我大致的学习了解。我直接在pycharm里面安装了jieba库,它的使用也是较简单的,通过精确模式的分词,并统计它们出现的次数,编写代码让结果以键值对的形式存入一个列表中保存在json文件里,为后面的词云数据做准备。
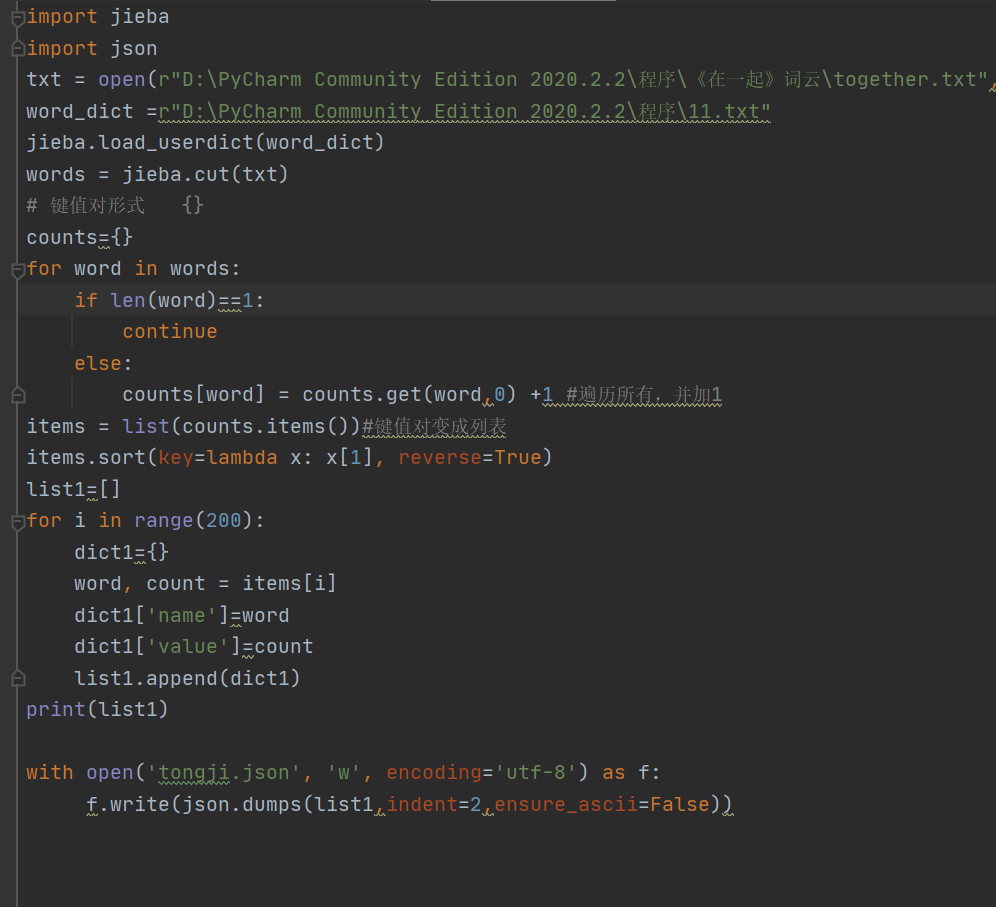
3.词云图的制作
词云图的生成要求使用echarts插件,关于echarts的运用,完成作业时在这块地方卡了很久,一开始不知道如何下载它,下载了也不知道如何使用,网上也没有关于它的小白介绍,直接就开始侃侃而谈它的“五分钟入门”。可能真的很简单,但是我也真的卡了很久,心情逐渐郁闷。后来慢慢的自我摸索才有了点头绪,然后试运行网上类似的词云模板,可是没有得到结果,在这里又卡壳了,于是查找是否是我安装路径的错误,或者是代码错误等。不断的查询资料并且观看echarts的学习视频,耗时几小时,仍然没有找到相关可行的解决办法。最后发现了一个模板,尝试把数据替换成自己的,然后竟然出现了结果,生成了一个五边形的图案,但看起来有点像皇冠,调了参数的一点数值,但跟原结果差别不大。想要模仿网上的将词云图片设计成自定义的图案,但又出现了报错,修改了一番也没有成功。官网上没有关于词云的案例详解,网上的资料关于这方面的也不多,希望在以后的课堂上能有机会听到老师对echarts生成词云的入门教学。

4.代码上传至GitHub
1.在github上面创建仓库first-personal-work,初始化README.md文件并且设置为公开.
2.新建一个“第一次个人编程作业”文件夹,右击“第一次个人编程作业”文件夹根目录,点击“Git Bash Here”,输入git命令行。

3.将仓库克隆到本地。
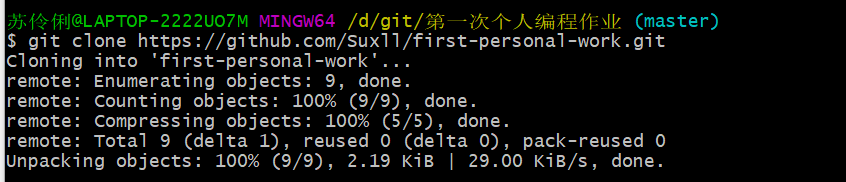
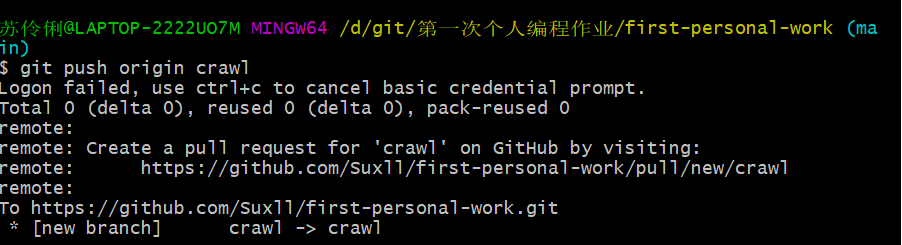
4.仓库新建crawl和chart两个分支(注意都要push,不然无法创建成功)。

5.用(git checkout 分支名)实现分支间的跳转,使用以下步骤将自己的index.html文件上传到指定的chart分支。
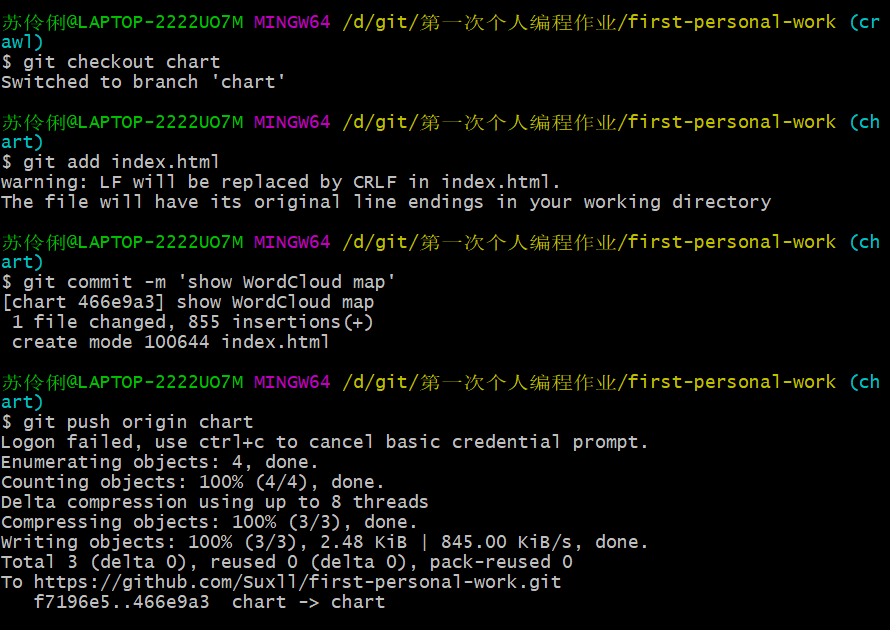
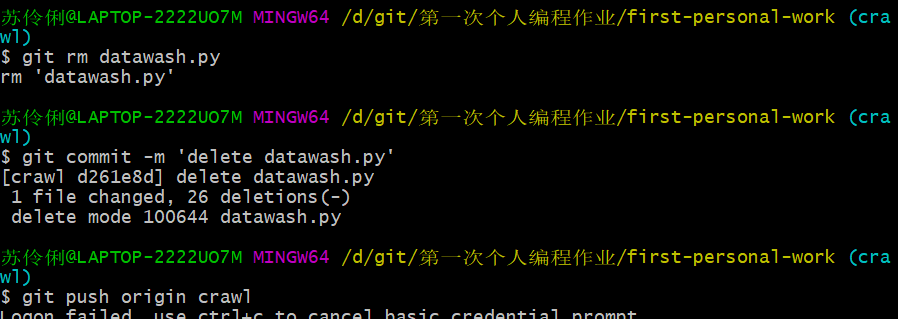
照样,分别完成五次commit。
(PS:若要删除分支里的文件也是类似的操作)
6.将两个分支分别合并到主分支。
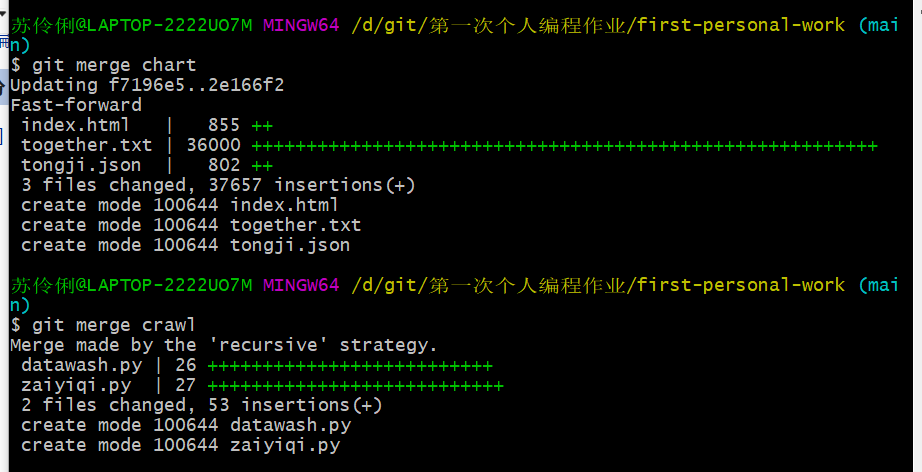
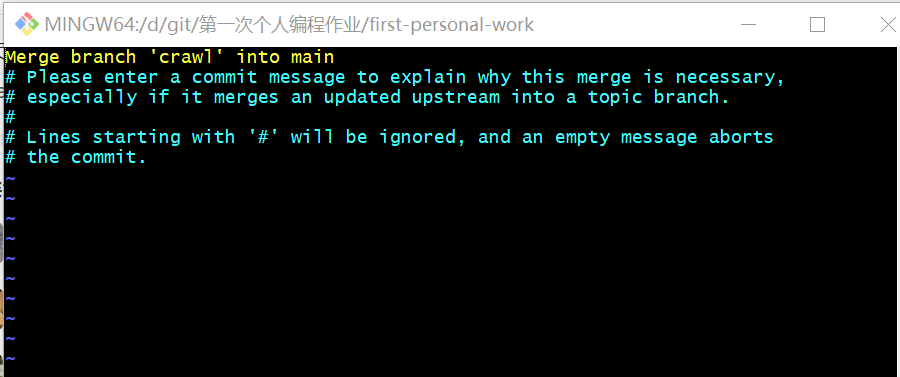
(PS:在合并crawl分支时,出现了如下图的情况,百度后是发生了合并冲突,按ESC,:wq退出即可)
7.将本地代码推送到远程。

三.心路历程
看到作业内容的时候,脑子是空白的,光是审题就花了快一个小时,两个作业对比选择了作业一。原因很简单,第二个的未知知识多于第一个,所以退缩了。这两天的学习过程是煎熬的,尤其今天坐在电脑前从早到晚,除了正常的活动,没有分心去做别的事情,但感觉最后也只是勉勉强强完成了作业,对于作业所要求掌握的知识点也只是一知半解。突然感觉到了自己与别人的差距,可能在别人眼里很容易完成的任务我耗费了很多时间也完成得不尽理想,竟没发觉是何时开始落后于人。希望自己今后把握好时间,提高学习能力和效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号