
Anchor-Free目标检测算法
按时间排序的anchor free论文
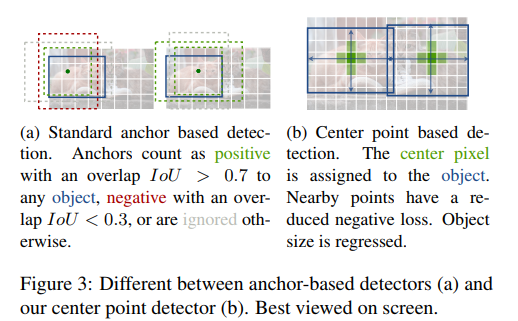
为什么要anchor free?
1、anchor的数量 大小 和宽高比这些超参要调
2、dense anchor boxes create a huge imbalance between positive and negative anchor boxes during training. This imbalance causes the training to be inefficient and hence the performance to be suboptimal
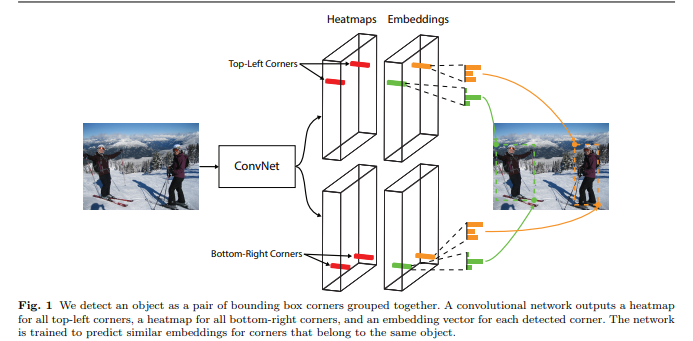
CornerNet: Detecting Objects as Paired Keypoints
论文地址 https://arxiv.org/pdf/1808.01244.pdf
两个角点预测分支和偏移量预测分支 :预测了两个分支的HxWxC的热图,C是类别数 不含背景类。
whose center is at the positive location and whose σ is 1/3 of the radius
pcij 是类别c在(i,j)上的预测得分,ycij 是用高斯核增强后的gt
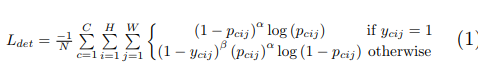
原图中(x,y)的位置映射到热力图上是(x/n,y/n),n是下采样因子。
为什么要预测偏移量?因为卷积网络输出的heatmap大小和原图大小不一致,映射会原图会有精度的损失。
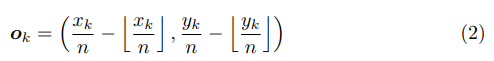
embedding分支:loss只用于GT角点位置
左上角的点与右下角的点如果属于同一bounding box,则他们embedding的向量之间的距离应该要小
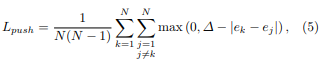
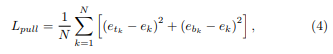
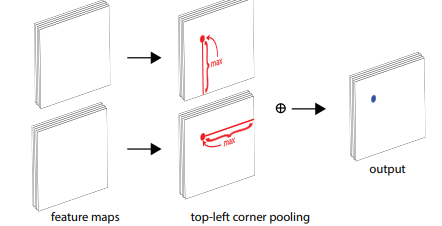
Corner Pooling:
对于左上角的点,需要水平方向往右找到上边界,垂直方向下找到右边界
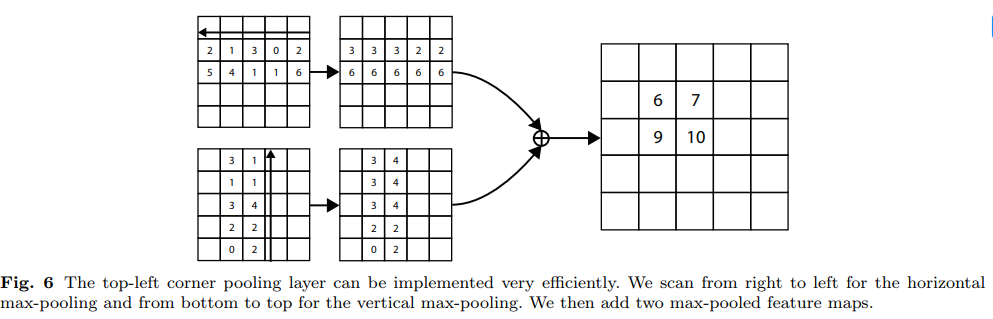
测试阶段:
(1)、对heatmap使用maxpooling (相当于做了NMS)
(2)、选择top100的左上角点和top100右下角点,左上角右下角点根据embedding的L1距离来匹配成对,>0.5就不成对
(3)、左上角和右下角点的score取均值作为最终的框的置信度。原图和翻转图送到网络得到框在做soft-NMS
创新点/优点:
(1)对每个角点预测了一个embedding的特征
(2)提出了cornerpooling的操作:左上的角点分别从右往左 和从下往上求最大值的
缺点:处理时间久,效率低。COCO mAP 42.2% 1.147s每张图。
Feature Selective Anchor-Free Module for Single-Shot Object Detection
卡耐基梅隆大学 https://arxiv.org/pdf/1903.00621.pdf
CornerNet-Lite: Efficient Keypoint Based Object Detection
cornernert作者改进 论文地址 https://arxiv.org/pdf/1904.08900.pdf 代码开源:https://github.com/ princeton-vl/CornerNet-Lite
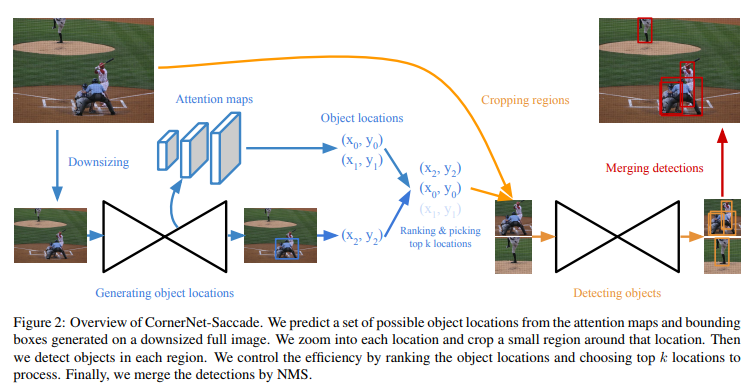
CornerNet-Saccade:
1、Estimating Object Locations:
首先用下采样的图生成attention map和粗糙的边界框。
对下采样的图像,saccade预测出3个attention map分别表示大中小目标,使用Hourglass中上采样层的特征,The feature maps at finer scales are used for smaller objects and the ones at coarser scales are for larger objects. attention map通过 3x3 Conv + 1x1 Relu+ 1x1Conv+Sigmoid得到
训练阶段:物体中心点设为正样本,其余为负样本,使用focalloss。 在测试阶段:只处理score大于阈值的位置,score阈值设为0.3
2、检测阶段:
3个attention map可以为每个尺度的目标设置了一个放大尺度,小目标的长边放大后24像素,中目标放大后64像素,大目标192像素。
The scale is determined such that the longer side of the bounding box after zoom-in is 24 for a small object, 64 for a medium object and 192 for a large object
充分利用GPU,将原始图存放在GPU,直接在gpu上resize和裁剪操作减少cpu和gpu之间的切换。
第一阶段得到的检测框按score排序后选择Top k,再在这Kmax个位置上进行检测目标。
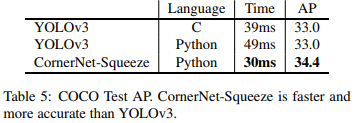
CornerNet-Squeeze
因为cornernet中backbone 是最耗时的, 借鉴了SqueezeNet and MobileNets的思想,
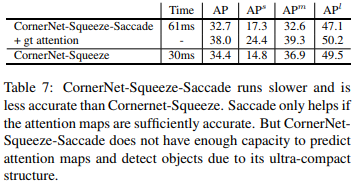
CornerNet-Squeeze-Saccade比CornerNet-Squeeze跑的慢还精度低,主要是因为saccade是依赖与精确的attention map,
gt attention 是将预测的attention map换成gt,可以看到明显的上升。这 说明attention map的质量对检测精度有影响。
创新点:
(1)整体流程很像二阶的目标检测,先得到一些框,从原图上裁剪出目标区再根据目标大小进行放大送到检测器。
(2)使用缩小的图像送到网络生成不同尺度的目标的ttention map
缺点:
(1)cornernet-squeeze也仅仅只是借用轻量化网络的idea,个人感觉创新点:不大
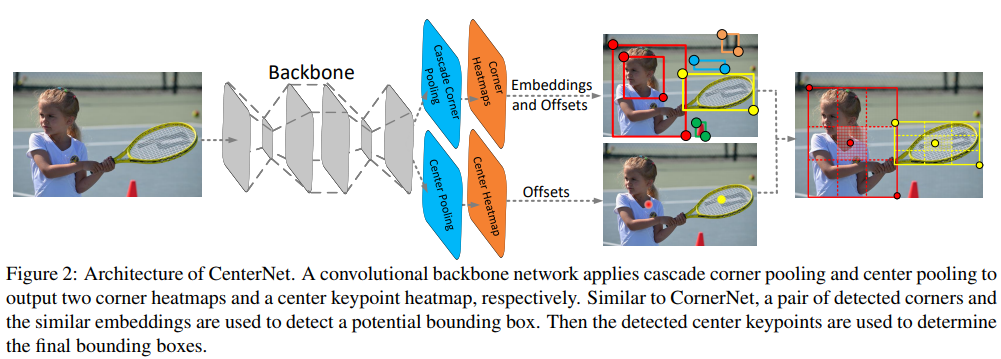
CenterNet: Keypoint Triplets for Object Detection
论文地址 https://arxiv.org/pdf/1904.08189.pdf 代码开源:https://github.com/ Duankaiwen/CenterNet
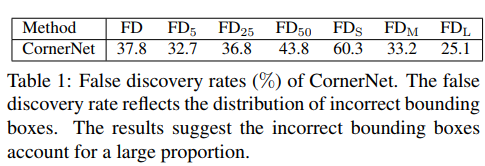
本文出发点:cornernet误检率很高, 原因之一可能是cornernet没法看到目标框内
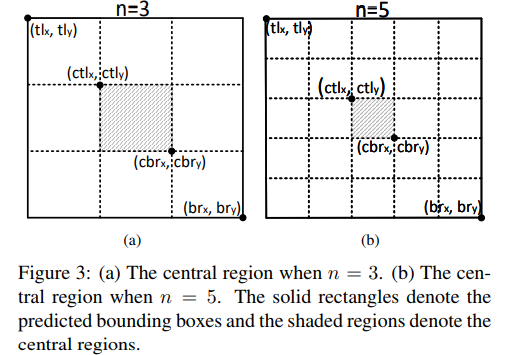
Center Region 中心点的回归:
目标小于150的中心区域使用n=3,大于150使用n=5
预测得到的框求出一个中心区域,如果有预测的中心的落在这个区域内,则保留这个预测框。,最终的框的score去三个点的平均score。
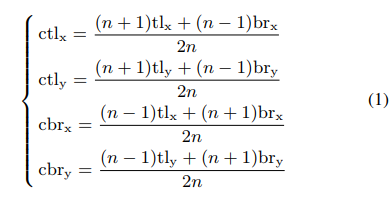
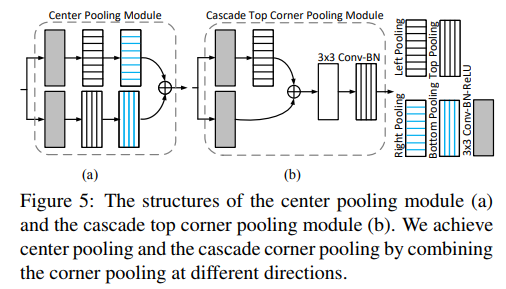
Center-pooling,cascade corner pooling
Center pooling 由于中心点不一定是有显著的视觉特征(人的头部是有显著特征,而中心点是在身体上)
Cascade corner pooling:角点 通常实在物体外,缺乏目标外表的特征,corner pooling可以看做是为了找到最大边界
这两种pooling 都可以用cornerpooling组合实现
训练阶段:输入图像511x511,Adam,batch size=48。相比cornernet,增加了中心点的预测和中心点偏移的预测,训练loss如下:
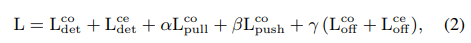
测试阶段:Top70的中心点,Top70的左上角点和Top70的右下角点,最后根据检测结果的score选择top100
创新点:
(1)提出了新的三元组检测网络:左上角点+中心点+右下角点
(2)改进了corner pooling
(3)由于单阶段去除了RoI的提取,所以单阶段缺乏能够关注目标内部的信息。
An intuitive explanation of our contribution lies in that we equip a one-stage detector with the ability of two-stage approaches, with an efficient discriminator being added.
缺点/改进点:
(1)backbone 可以像cornernet-lite改进,
(2)还是一样和cornernet有关键点组合,耗时
Objects as Points
伯克利大学 论文地址: https://arxiv.org/pdf/1904.07850.pdf 代码开源 https://github. com/xingyizhou/CenterNet
原文提到a combinatorial grouping stage after keypoint detection, which significantly slows down each algorithm.
cornernet 和extremenet都是要在关键点检测完之后,对关键点进行匹配组合,大大拉低算法运行时间。
本文没有网络结构图=。= 说明
(1)回归中心点,回归宽和高,
(2)为了解决卷积网络里stride,额外预测了一个局部偏移量![]()
(3)从点映射会边界框,无需NMS等后处理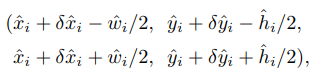
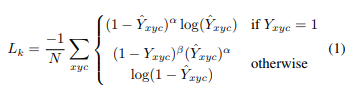
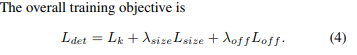
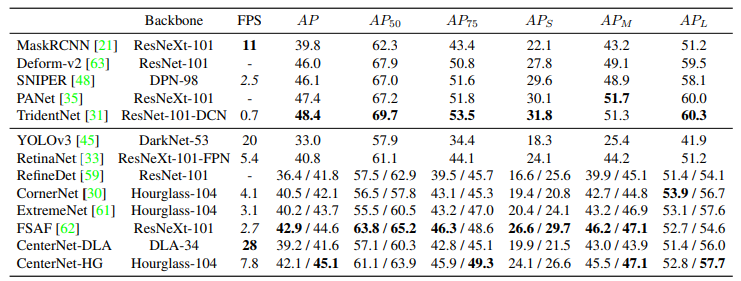
创新点/优点:
(1)能够达到实时;在COCO上28.1% AP at 142 FPS, 37.4% AP at 52 FPS, and 45.1% AP 多尺度测试 1.4 FPS。
(2)不像CornerNet,无须关键点组合和复杂的后处理。
(3)可扩展性强:3D目标检测,人体姿态估计等。
缺点:精度不够高

FCOS: Fully Convolutional One-Stage Object Detection
阿德莱德大学 论文地址: https://arxiv.org/pdf/1904.01355.pdf
基于anchor的缺点:(1)anchor的属性这些超参调 (2)这种固定好的anchor影响泛化性,(3)大量的anchor被标记为负样本,训练过程中正负不平衡。
一般anchor free的算法都不适合通用的目标检测,因为难以处理重叠框和低召回率的问题。
unsuitable for generic object detection due to difficulty in handling overlapping bounding boxes and the recall being relatively low
(1)基于像素点的预测 (2)多级预测来提高召回(3)通过中心度预测分支来解决低质量的预测框
FCOS网络结构如下:基于像素预测中心度 ,类别heatmap和4个坐标点的回归。
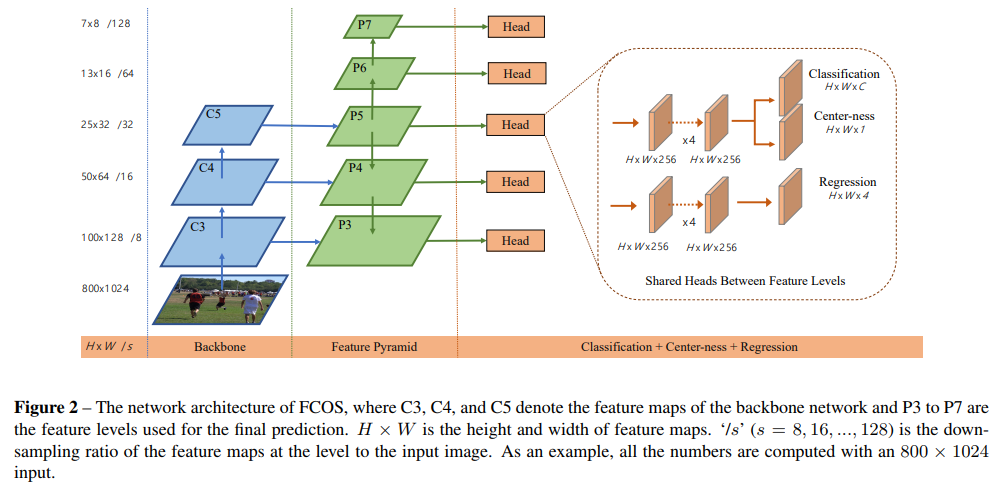
Fully Convolutional One-Stage Object Detector
训练损失如下,分类使用focalloss,回归使用iou loss
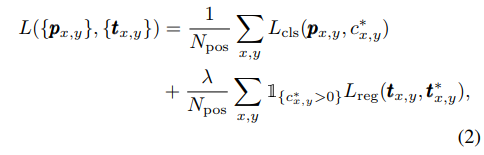
Multi-level Prediction with FPN for FCOS (用FPN多级预测)
基于anchor的检测器将不同大小的anchor box分配到不同level的特征上,FCOS直接限制不同feature level用于回归不同的边界框; mi表示第 i 级的feature需要回归的最大目标大小。本文中 m2, m3, m4, m5, m6 and m7 分别设为 0, 64, 128, 256, 512 and ∞,
不同大小的特征图负责回归不同的大小目标,因此没必要单独的网络。
As a result, instead of using the standard exp(x), we make use of exp(six) with a trainable scalar si to automatically adjust the base of the exponential function for feature level Pi , which slightly improves the detection performance.
Center-ness for FCOS
为什么要有中心度预测?即使有了多级预测,FCOS和基于anchor的方法还有很大差距,预测框的中心离gt很远。
中心度的值实在0~1,所以可以使用BCE损失。测试的时候最后框排序依据的分数是中心度*类别得分。
下表比较了不加中心度分支,使用回归分支直接求得的中心度 和单独中心度预测分支
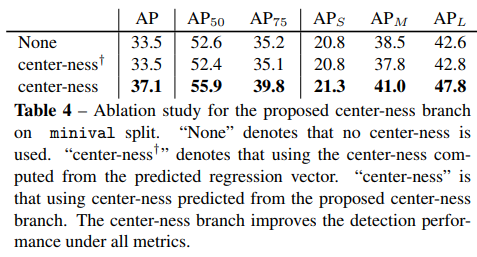
优点:
(1)FCOS可以作为二阶段网络的RPN 部分 大大提高精度。
(2)有效缓解了重叠框(模糊) 和单阶段低召回率的问题。
(3)简单高效,效果好

