论文阅读|SOLO: Segmentation Objects by LOcation
论文链接:https://arxiv.org/pdf/1912.04488.pdf
名字挺有意思,参照YOLO划分网格的思想
阿德莱德大学沈春华团队和字节跳动合作的新实例分割框架
1、摘要
We view the task of instance segmentation from a completely new perspective by introducing the notion of “instance categories”, which assigns categories to each pixel within an instance according to the instance’s location and size, thus nicely converting instance mask segmentation into a classification-solvable problem.
We demonstrate a much simpler and flexible instance segmentation framework with strong performance, achieving on par accuracy with Mask R-CNN and outperforming recent singleshot instance segmenters in accuracy
2、相关工作
之前的实例分割有两种
(1)Top-down: 先检测后分割,基于proposal的方法
MaskRcnn:https://blog.csdn.net/wangdongwei0/article/details/83110305
Mask-Score-RCNN:https://www.cnblogs.com/wemo/p/10505970.html
PANet:https://www.cnblogs.com/wzyuan/p/10029830.html
tensorMask
(2)Bottom-up:学习仿射关系,对每个像素分配一个向量,拉近同实例的像素,拉远不同实例的像素。
SGN (Sequential grouping networks for instance segmentation)
SSAP (Ssap: Single-shot instance segmentation with affinity pyramid)
一张图中实例目标之间fundamental的区别是什么? MSCOCO,有36780个目标在验证子集里,98.3%的目标对之间中心点距离为>30个像素。剩余1.7%的目标对中40% Size ratio超过了1.5。 两个实例要么有不同的中心点或者是不同的大小size 。那我们是否能直接通过中心点和大小来区分两个实例呢
本文中心思想:通过定位(locations)和大小(size)将目标实例区分开
Location 定位:一张图分为SxS的cells网格,因此有SxS个定位中心,根据目标中心点落到的网格坐标,一个实例目标就可以分配到一个网格中。
Size 大小:为了区分不同大小的实例目标,采用金字塔将不同大小的目标分配到不同尺度的特征图上。FPN最初是为了检测不同尺度的目标。
3、提出的SOLO
网络结构:
将实例分割问题转化成二分类任务和实例掩码生成任务
输入图像划分网格,目标中心落在一个网格中,则该网格负责预测语义类别,分割该目标的实例

(1)语义类别分支:
每个网格,SOLO 预测得到C维输出,便是语义类别的置信度,是类别数。置信度 输出空间是SxSxC,,这是基于每个网格都属于一个单独的实例。在inference阶段,C维输出就代表了每个目标实例的类别概率。
(2)实例掩码分支:
对于一张输入图像,划分成SxS的网格,总共就会有SxS个mask要预测。很好理解即使有HxWxS2大小的掩码图,第k个通道对应了坐标(i,j)网格输出的掩码。K=i*S+j
一种直接的方法是采用全卷积网络预测实例掩码,FCNs。但是传统卷积操作是空间不变。在一些任务像图像分类,空间不变性能够提高鲁棒性。我们在分割掩码是想要模型对位置敏感的。
(这一部分不太懂CoordConv)构造了一个和输入相同尺度的张量,这个张量和输入特征拼接一起送到后续的网络层。使用半卷积会更好?,CoordConv更简便。假设原始特征是HxWxD,新特征变成HxWx(D+2)最后的两个维度代表着坐标
(3)生成实例分割掩码:
使用NMS作为后处理获得最后的结果。网络结构 使用FPN生成特征金字塔,不同层金字塔的网格数可能不同,最后的1x1卷积不共享
3.3损失函数
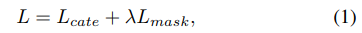
Lcate类别损失用的是focal loss
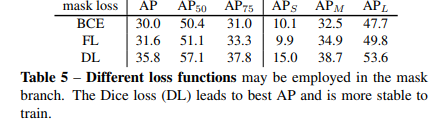
Lmask:作者对比了BCE loss Dice loss,Focal Loss。最后采用了Dice loss
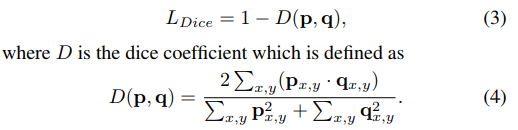
p,q代表预测的mask 和GT 在x,y位置上的像素值。
3.4 Inference
预测阶段,输入图片,经过backbone和FPN,然后得到类别分数p,和对应的掩码mk,(k=i*S+j) ,我们使用0.1过滤低置信度的预测。选取top500的分数mask做NMS。使用0.5的阈值对得到的soft mask二值化。最终取top100的实例掩码
4 Experiments
数据集MS COCO ,训练细节,优化器SGD,8GPUs,mini-batch 为16 每个GOU2张图,学习率初始化0.01,在27epoch和33epoch*0.1 使用ImageNet预训练模型初始化 。
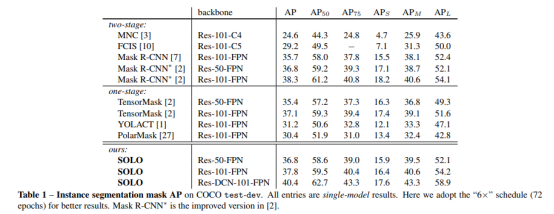
SOLO效果超过了单阶段分割,接近了二阶段的实例分割, 但小目标的分割还是没有比基于proposal的maskrcnn好。
(1)特征图上网格的数量:但单一尺度的模型(只用一层特征预测)远差与金字塔模型
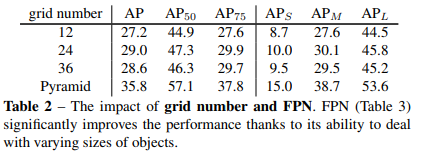
本文使用了5层的特征金字塔,低层特征图划分网格数多,高层划分得少,不同特征图负责分割不同大小的实例

(2)损失函数的对比
focalloss 效果要比BCE好,因为大部分mask像素是背景
Focalloss 是用过设置正反样本损失权重来缓解样本不平衡问题。
DiceLoss能够自动调整背景和前景的平衡,无需人为调参
(3)在类别分支的对齐
因为要划分网格,每个网格负责一个类别,从HxW大小变为SxS,作者对比了三种方法:双线性插值法,自适应池化(adaptive maxpooling),Region-grid-interpolation(在每个网格对密集采样点做插值后取均值)。实验发现这些方法AP差别都在0.1左右,所以用哪个都行。
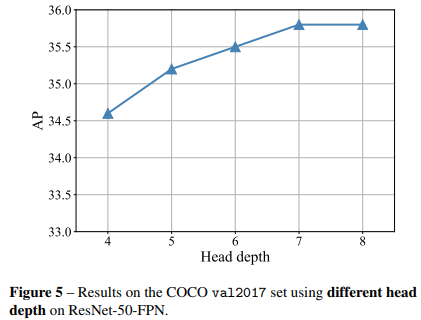
(4)不同的预测深度:
4层增加到7层能提高1.2AP,超过7层就提升不明显,Mask-rcnn中mask预测分支也是使用了4层卷积。
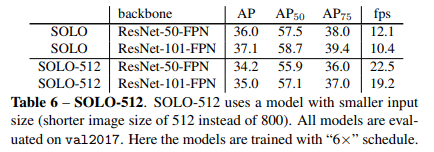
(5)SOLO 512: 使用512作为短边训练的模型分割速度能达到22FPS
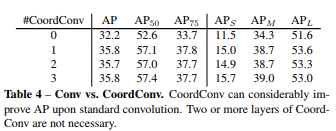
(6)CoordConv:使用一次就能有提升,2次以上提升不明显
论文(An intriguing failing of convolutional neural networks and the coordconv solution)
5 decoupled SOLO:对普通的SOLO优化 将SXS通道的分解成了 2个分支通道数就变为了2xS,而精度没有下降
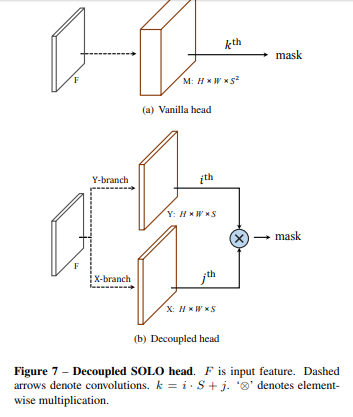
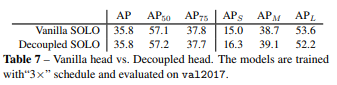
6 误差分析:
作者将mask分支预测出来的mask替换成GT的mask可以看到AP提升到68,也就说明了mask分支还有改进的空间,是一个改进发paper的方向。
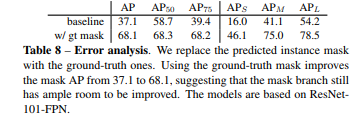
7、实例边界检测


目标实例间中心点间隔大,不同实例的大小差别大 ,感觉有点针对COCO数据集提出来的实例分割,可能在密集的数据集分割效果不好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号