spark学习(2)--hadoop安装、配置
环境:
三台机器 ubuntu14.04
hadoop2.7.5
jdk-8u161-linux-x64.tar.gz (jdk1.8)
架构:
machine101 :名称节点、数据节点、SecondaryNaemnode(辅助名称节点)、ResourceManager、NodeManger
machine102、machine103 :数据节点、NodeManger
1、安装jdk\hadoop
(1)解压hadoop.tar.gz到/soft/
(2)配置环境变量
JAVA_HOME=/soft/jdk1.7.0_45 (必须要写,hadoop会去找名叫JAVA_HOME的值) HADOOP_HOME=/soft/hadoop-2.7.5 (必须要写) PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/soft/jdk1.7.0_45/bin:/soft/hadoop-2.7.5/bin:/soft/hadoop-2.7.5/sbin"
(3)source /etc/environment
(4)验证是否安装成功 :查看版本 $> hadoop version
2、配置hadoop的三种模式
1、standalone/local 独立/本地模式 (默认是此模式,不需要配置)
----使用本地文件系统,此模式只用在开发、调试时。
2、Pseudodistributed mode 伪分布式模式 (一般都用完全分布式,需要多台服务器)
----完全类似完全分布式,但是只有一个节点。
3、Fully distributes mode 完全分布式模式
第一步: 三台客户机,安装jdk,hadoop,配置两者的环境变量
第二步: 安装ssh实现无密登陆,只有NN(名称节点)需要生成密钥对,把其公钥放在数个DN(数据节点)的~/.ssh/authorized_keys
1)用户是ailab,需要明确是哪个用户
$>sudo apt-get install ssh
2)生成密钥
$>ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
3)将自己的公钥导入自己的公钥数据库(~/.ssh/authorized_keys就是公钥数据库)
$>cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
4)实现对自己的无密登陆
$>ssh localhost
A登陆B,需要A用自己的私钥加密,传递给B,B用A的公钥解密。即,A需要事先把公钥给B
machine101公钥从101传递给machine102上
方法1:直接用scp拷贝过去
machine101: scp ~/.ssh/id_rsa.pub ailab@192.168.1.200:/home/ailab/
machine102: cat id_rsa.pub >>authorized_keys
方法2:
第一步: ailab@machine102:~/.ssh$ nc -l 8888 > id_rsa.pub.machine101
第二步: ailab@machine101:~/.ssh$ nc machine102 8888 < id_rsa.pub
结果 : 在machine102的~/.ssh目录下多出“id_rsa.pub.machine101”文件
第三步 :cat id_rsa.pub.machine101 >>authorized_keys (将101的公钥写入102的公钥数据库)
结果 : ailab@machine101:~/.ssh$ ssh machine102 (可以在101无密登陆102了)
![]()

第三步:配置hadoop文件:
在/soft/hadoop/etc/hadoop/目录下
a.修改core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://machine101:8020/</value> //写名称结点 </property>
<property>
<name>hadoop.tmp.dir</name> <value>/home/ailab/hadoop</value> //每个节点需要自己创建该目录,最后没有左斜杠
</property> </configuration>
b.修改hdfs-site.xml
<property>
<name>dfs.replication</name> #副本数
<value>3</value>
</property>
#如果说还有第四台机子的话,应该把machine104设置为SecondaryNaemnode(辅助名称节点)
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>machine104:50090</value>
</property>
c.cp mapred-site.xml.template mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
</configuration>
d.修改yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>machine101</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
e.修改vim slaves (存储数据结点ip)
machine 101 #既作名称节点,又作数据节点
machine 102
machine 103
第四步:scp命令(远程文件拷贝),基于ssh
------把jdk,hadoop文件拷贝到其他机器
scp -r /soft/* ailab@machine102:/soft #把jdk/hadoop传给其他机器
scp /etc/environment root@machine102:/etc/
第五步:
格式化文件系统 machine101 $>hadoop namenode -format (初始化了namenode工作目录)
启动所有进程 machine101 $>start-all.sh (datanode启动后,初始化datanode工作目录)
停止 machine101 $> stop-all.sh
重启系统(考察start-all.sh是否ok)
不需要格式化(以后都不需要格式化)
直接start-all.sh
检查jps

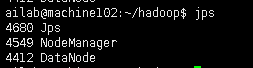
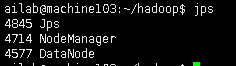
第六步番外:
如果以后修改了配置文件
需要先stop-all.sh
格式化文件系统 $>hadoop namenode -format,在启动
=====================================================================================================================
背景知识:
hadoop所有类库、配置文件都在tar包中,jar包在share/hadoop/.
1、解压tar包
2、hadoop-2.7.5\share\hadoop\common\hadoop-common-2.7.5.jar里有core-default.xml默认的配置文件
同样道理,也存在jar包中也存在hdfs-default.xml等
比如,如果你不修改服务器中soft/hadoop/etc/hadoop/core-site.xml的话,就会读取jar包里默认的core-default.xml
以下内容来自jar包中的core-default.xm
<property> <name>fs.defaultFS</name> <value>file:///</value> #默认是本地模式 </property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-${user.name}</value> #默认的hadoop.tmp.dir值
<description>A base for other temporary directories.</description>
</property>
以下来自hdfs-default.xml
动态获取hadoop.tem.dir的值。所以只需要在core-site.xml配置hadoop.tem.dir就可以了
datanode工作目录:
<property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/dfs/data</value> </property>
=============================================================================================================
hadoop进程管理:
第一步:查看hadoop进程个数(5个) $>jps
第二步:如果进程个数不对,杀死所有进程 $>stop-all.sh
第三步:重新格式化系统 machine101$>hadoop namenode -format
第四步:启动所有进程 machine101$>start-all.sh
电脑一旦重启,就需要重新格式化hadoop,因为伪分布式下,他把本地文件保存为临时文件,重新开机后文件就删除了
如果配置了hadoop.tmp.dir,就没事,数据文件会保存下来
首次启动hadoop:
第一步:格式化文件系统 $>hadoop namenode -format
第二步:启动所有进程 $>start-all.sh
第三步:查询进程 $>jps
查看文件目录 $> hadoop fs -ls /
创建文件 $> hadoop fs -mkdir -p /user/ailab/data
基于web ui 访问文件系统hdfs : http://localhost:50070
需要注意的问题:
hadoop伪分布式下 无法启动datanode的原因及解决办法
版本一:----------------------------------------------------------------------------------------------
在每次执行hadoop namenode -format时,都会为NameNode生成namespaceID,,但是在hadoop.tmp.dir目录下的DataNode还是保留上次的namespaceID,因为namespaceID的不一致,而导致DataNode无法启动,所以只要在每次执行hadoop namenode -format之前,先删除hadoop.tmp.dir(路径为 /usr/local/hadoop/下的)tmp目录就可以启动成功,或者删除/usr/local/hadoop/tmp/dfs下的data目录,然后重新启动dfs(在hadoop安装路径 /usr/local/hadoop/ 下,运行命令./sbin/start-dfs.sh)即可。请注意是删除hadoop.tmp.dir对应的本地目录,即/usr/local/hadoop/下的tmp文件夹,而不是HDFS目录。
以后在hadoop format过程中 要注意不要频繁地reformat namnode(格式化命令为 ./bin/hadoop namenode -format)的ID信息。format过程中选择N(否)就是了。
Hadoop namenode重新格式化需注意问题
版本二:
----------------------------------------------------------------------------------------------
(1)Hadoop的临时存储目录tmp(即core-site.xml配置文件中的hadoop.tmp.dir属性,默认值是/tmp/hadoop-${user.name}),如果没有配置hadoop.tmp.dir属性,那么hadoop格式化时将会在/tmp目录下创建一个目录,例如在cloud用户下安装配置hadoop,那么Hadoop的临时存储目录就位于/tmp/hadoop-cloud目录下
(2)Hadoop的namenode元数据目录(即hdfs-site.xml配置文件中的dfs.namenode.name.dir属性,默认值是${hadoop.tmp.dir}/dfs/name),同样如果没有配置该属性,那么hadoop在格式化时将自行创建。必须注意的是在格式化前必须清楚所有子节点(即DataNode节点)dfs/name下的内容,否则在启动hadoop时子节点的守护进程会启动失败。这是由于,每一次format主节点namenode,dfs/name/current目录下的VERSION文件会产生新的clusterID、namespaceID。但是如果子节点的dfs/name/current仍存在,hadoop格式化时就不会重建该目录,因此形成子节点的clusterID、namespaceID与主节点(即namenode节点)的clusterID、namespaceID不一致。最终导致hadoop启动失败。
2、hadoop 的三个模块
hdfs 分布式文件系统
【进程】
NameNode //名称节点--存目录的地方
DataNode //数据节点--存数据的地方
SecondaryNaemnode //辅助名称节点--备份目录的地方
yarn 作业(job)调度集群资源管理框架e
ResourceManager //资源管理器
NodeManger //节点管理器
mapreduce 基于yarn的对大数据集进行并行处理技术
()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号