
Hbase
Hbase
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文《Bigtable》一个结构化数据的分布式存储系统"
非关系型数据库和关系型数据库
传统关系型数据库的缺陷
1)高并发读写的瓶颈
2)可扩展性的限制
3)事务一致性的负面影响
4)复杂SQL查询的弱化
NoSQL数据库的优势
1)扩展性强
2)并发性能好
3)数据模型灵活
总结
HBase的列式存储的特性支撑它实时随机读取、基于KEY的特殊访问需求
Hadoop最适合的应用场景是离线批量处理数据,其离线分析的效率非常高,Hadoop针对数据的吞吐量做了大量优化,能在分钟级别处理TB级的数据,但是Hadoop不能做到低延迟的数据访问,所以一般的应用系统并不适合批量模式访问,更多的还是用户的随机访问,就类似访问关系型数据库中的某条记录一样。
BigTable介绍
BigTable是Google设计的分布式数据存储系统,用来处理海量的数据的一种非关系型的数据库。
BigTable是非关系的数据库,是一个稀疏的、分布式的、持久化存储的多维度排序Map。
Bigtable的用三维表来存储数据,分别是行键(row key)、列键(column key)和时间戳(timestamp),
行存储 VS 列存储
概述
目前大数据存储有两种方案可供选择:行存储(Row-Based)和列存储(Column-Based)。
Hadoop的HBase采用列存储,MongoDB是文档型的行存储,Lexst是二进制型的行存储。
集中焦点是:谁能够更有效地处理海量数据,且兼顾安全、可靠、完整性
什么是列存储?
列式存储(column-based)是相对于传统关系型数据库的行式存储(Row-basedstorage)来说的。
Ø Row-based storage stores atable in a sequence of rows.
Ø Column-based storage storesa table in a sequence of columns.
在数据写入上的对比
1)行存储的写入是一次完成。如果这种写入建立在操作系统的文件系统上,可以保证写入过程的成功或者失败,数据的完整性因此可以确定。
2)列存储由于需要把一行记录拆分成单列保存,写入次数明显比行存储多(意味着磁头调度次数多,而磁头调度是需要时间的,一般在1ms~10ms),再加上磁头需要在盘片上移动和定位花费的时间,实际时间消耗会更大。所以,行存储在写入上占有很大的优势。
3)还有数据修改,这实际也是一次写入过程。不同的是,数据修改是对磁盘上的记录做删除标记。行存储是在指定位置写入一次,列存储是将磁盘定位到多个列上分别写入,这个过程仍是行存储的列数倍。所以,数据修改也是以行存储占优。
在数据读取上的对比
1)数据读取时,行存储通常将一行数据完全读出,如果只需要其中几列数据的情况,就会存在冗余列,出于缩短处理时间的考量,消除冗余列的过程通常是在内存中进行的。
2)列存储每次读取的数据是集合的一段或者全部,不存在冗余性问题。
3) 两种存储的数据分布。由于列存储的每一列数据类型是同质的,不存在二义性问题。比如说某列数据类型为整型(int),那么它的数据集合一定是整型数据。这种情况使数据解析变得十分容易。相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗CPU,增加了解析的时间。所以,列存储的解析过程更有利于分析大数据。
4)从数据的压缩以及更性能的读取来对比
优缺点
1)行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略;数量大可能会影响到数据的处理效率。
2)列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。
列存储的适用场景
1)一般来说,一个OLAP类型的查询可能需要访问几百万甚至几十亿个数据行,且该查询往往只关心少数几个数据列。
2)很多列式数据库还支持列族(column group,Bigtable系统中称为locality group),即将多个经常一起访问的数据列的各个值存放在一起
3)此外,由于同一个数据列的数据重复度很高,因此,列式数据库压缩时有很大的优势。
总结
传统行式数据库的特性
①数据是按行存储的。
②没有索引的查询使用大量I/O。比如一般的数据库表都会建立索引,通过索引加快查询效率。
③建立索引和物化视图需要花费大量的时间和资源。
④面对查询需求,数据库必须被大量膨胀才能满足需求。
列式数据库的特性
①数据按列存储,即每一列单独存放。
②数据即索引。
③只访问查询涉及的列,可以大量降低系统I/O。
④每一列由一个线程来处理,即查询的并发处理性能高。
⑤数据类型一致,数据特征相似,可以高效压缩。比如有增量压缩、前缀压缩算法都是基于列存储的类型定制的,所以可以大幅度提高压缩比,有利于存储和网络输出数据带宽的消耗。
HBASE基本概念
HBase以表的形式存储数据。表有行和列组成。列划分为若干个列族(row family)
hbase本质上也是一种Key-Value存储系统。
1)Row Key
访问hbase table中的行,只有三种方式
1 通过单个row key访问
2 通过row key的range
3 全表扫描
Row key行键 (Row key)可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes),在hbase内部,row key保存为字节数组。
存储时,数据按照Row key的字典序(byte order)排序存储。设计key时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
2)列族(列簇)
hbase表中的每个列,都归属与某个列族。
列族是表的schema的一部分(而列不是),列族必须在使用表之前定义。列名都以列族作为前缀。
访问控制、磁盘和内存的使用统计都是在列族层面进行的。
实际应用中,列族上的控制权限能 帮助我们管理不同类型的应用:我们允许一些应用可以添加新的基本数据、一些应用可以读取基本数据并创建继承的列族、一些应用则只允许浏览数据(甚至可能因 为隐私的原因不能浏览所有数据)。
3)Cell与时间戳
由{row key, column( =<family> + < label>), version} 唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存贮。
每个 cell都保存着同一份数据的多个版本
版本通过时间戳来索引。
时间戳的类型是 64位整型。
每个 cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,hbase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
Hbase物理存储原理
Hbase里的一个Table 在行的方向上分割为多个Hregion。
即HBase中一个表的数据会被划分成很多的HRegion,HRegion可以动态扩展并且HBase保证HRegion的负载均衡。HRegion实际上是行键排序后的按规则分割的连续的存储空间。
一张Hbase表,可能有多个HRegion,每个HRegion达到一定大小(默认是10GB)时,进行分裂。
拆分流程
Hregion是按大小分割的,每个表一开始只有一个Hregion,随着数据不断插入表,Hregion不断增大,当增大到一个阀值的时候,Hregion就会等分会两个新的Hregion。当table中的行不断增多,就会有越来越多的Hregion。
HRegion由一个或者多个HStore组成,每个Hstore保存一个columns family。每个HStore又由一个memStore和0至多个StoreFile组成
HRegion是分布式的存储最小单位,StoreFile(Hfile)是存储最小单位。
Hbase系统架构
Hbase与Hadoop架构图
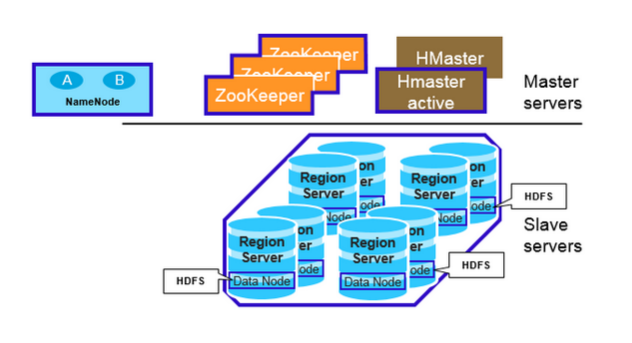
Hbase于Hadoop的体系图
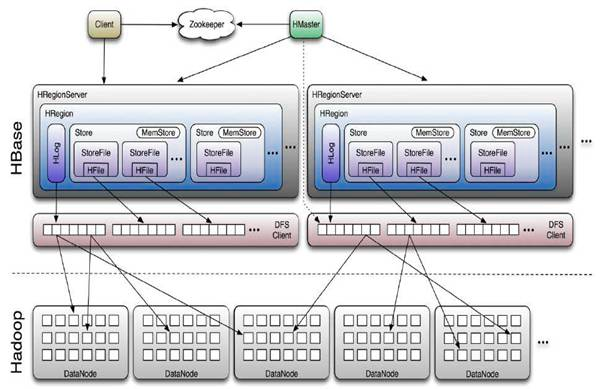
HBase采用Master/Slave架构搭建集群,它隶属于Hadoop生态系统,由以下类型节点组成:
1.HMaster节点
2.HRegionServer节点
3.ZooKeeper集群
4.Hbase的数据存储于HDFS中,因而涉及到HDFS的NameNode、DataNode等。RegionServer和DataNode一般会放在相同的Server上实现数据的本地化(避免或减少数据在网络中的传输,节省带宽)。
HMaster节点
1.管理HRegionServer,实现其负载均衡。
2.管理和分配HRegion,比如在HRegion split时分配新的HRegion;在HRegionServer退出时迁移其内的HRegion到其他HRegionServer上。
3.实现DDL操作(Data Definition Language,namespace和table的增删改,column familiy的增删改等)。
4.管理namespace和table的元数据(实际存储在HDFS上)。
5.权限控制(ACL)。
HMaster
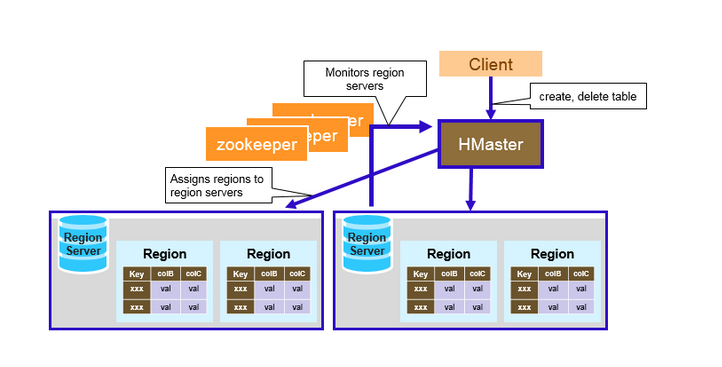
HMaster没有单点故障问题,可以启动多个HMaster,通过ZooKeeper的Master Election机制保证同时只有一个HMaster出于Active状态,其他的HMaster则处于热备份状态。
一般情况下会启动两个HMaster,非Active的HMaster会定期的和Active HMaster通信以获取其最新状态,从而保证它是实时更新的,因而如果启动了多个HMaster反而增加了Active HMaster的负担。
HMaster的主要用于HRegion的分配和管理,DDL(Data Definition Language,既Table的新建、删除、修改等)的实现等,既它主要有两方面的职责:
HRegionServer节点
一.存放和管理本地HRegion。
二.读写HDFS,管理Table中的数据。
三.Client直接通过HRegionServer读写数据(从HMaster中获取元数据,找到RowKey所在的HRegion/HRegionServer后)。
协调HRegionServer
启动时HRegion的分配,以及负载均衡和修复时HRegion的重新分配。
监控集群中所有HRegionServer的状态(通过Heartbeat和监听ZooKeeper中的状态)。
Admin职能
创建、删除、修改Table的定义
Hregion
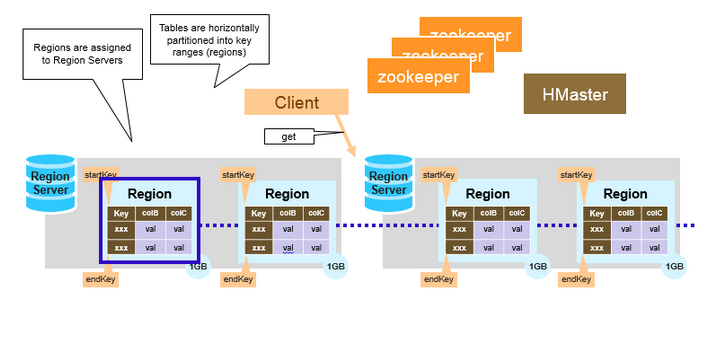
HBase使用RowKey将表水平切割成多个HRegion,从HMaster的角度,每个HRegion都纪录了它的StartKey和EndKey,由于RowKey是排序的,因而Client可以通过HMaster快速的定位每个RowKey在哪个HRegion中
HRegion由HMaster分配到相应的HRegionServer中,然后由HRegionServer负责HRegion的启动和管理,和Client的通信,负责数据的读(使用HDFS)
HRegion
1.WAL即Write Ahead Log
所有写操作都会先保证将数据写入这个Log文件后,才会真正更新MemStore,最后写入HFile中。
采用这种模式,可以保证HRegionServer宕机后,我们依然可以从该Log文件中恢复数据,Replay所有的操作,而不至于数据丢失。
一般一个HRegionServer只有一个WAL实例
2.BlockCache是一个读缓存。即“引用局部性”原理
3.HRegion是一个Table中的一个Region在一个HRegionServer中的表达。
因而最好将具有相近IO特性的Column存储在一个Column Family,以实现高效读取(数据局部性原理,可以提高缓存的命中率)
4.MemStore是一个写缓存(In Memory Sorted Buffer)
由MemStore根据一定的算法(LSM-TREE算法,这个算法的作用是将数据顺序写磁盘,而不是随机写,减少磁头调度时间,从而提高写入性能)
5.HFile(StoreFile) 用于存储HBase的数据(Cell/KeyValue)。
在HFile中的数据是按RowKey、Column Family、Column排序,对相同的Cell(即这三个值都一样),则按timestamp倒序排列。
因为Hbase的HFile是存到HDFS上,所以Hbase实际上是具备数据的副本冗余机制的。
ZooKeeper集群
1.存放整个 HBase集群的元数据以及集群的状态信息。
2.实现HMaster主备节点的failover。
ZooKeeper:协调者
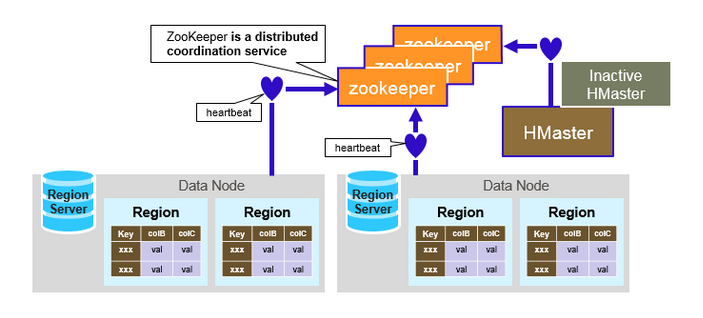
ZooKeeper为HBase集群提供协调服务,它管理着HMaster和HRegionServer的状态(available/alive等),并且会在它们宕机时通知给HMaster,从而HMaster可以实现HMaster之间的failover(失败恢复),或对宕机的HRegionServer中的HRegion集合的修复(将它们分配给其他的HRegionServer)
ZooKeeper集群本身使用一致性协议(PAXOS协议,
PAXOS算法的思想是:在分布式的环境下,如何就某个决议达成一致性的算法,PAXOS算法的缺点是存在活锁问题,ZK是基于PAXOS实现的Fast PAXOS)保证每个节点状态的一致性。
How The Components Work Together
ZooKeeper协调集群所有节点的共享信息,在HMaster和HRegionServer连接到ZooKeeper后创建Ephemeral( 临时)节点,并使用Heartbeat机制维持这个节点的存活状态,如果某个Ephemeral节点实效,则HMaster会收到通知,并做相应的处理
通信
HBase Client通过RPC方式和HMaster、HRegionServer通信
一个HRegionServer可以存放1000个HRegion(1000个数字的由来是来自于Google的Bigtable论文);
底层Table数据存储于HDFS中,而HRegion所处理的数据尽量和数据所在的DataNode在一起,实现数据的本地化;
数据本地化并不是总能实现,比如在HRegion移动(如因Split)时,需要等下一次Compact才能继续回到本地化。
客户端在第一次访问用户Table的流程
从ZooKeeper(/hbase/meta-region-server)中获取hbase:meta的位置(HRegionServer的位置),缓存该位置信息。
从HRegionServer中查询用户Table对应请求的RowKey所在的HRegionServer,缓存该位置信息。
从查询到HRegionServer中读取Row。
然而随着时间的推移,客户端缓存的位置信息越来越多,以至于不需要再次查找hbase:meta Table的信息,除非某个HRegion因为宕机或Split被移动,此时需要重新查询并且更新缓存。
hbase:meta表
①元表的作用是根据指定Table Key去找到对应HRegion,以及找到存储这个HRegion的服务器(RS)
②META TBLE的row key:table ,key ,region || value:rs服务器地址
③META 的数据结构是一个B Tree ,通过B Tree 所以可以加快查找速度。
Hbase写流程
HRegionServer中数据写流程
当客户端发起一个Put请求时,首先它从hbase:meta表中查出该Put数据最终需要去的HRegionServer。然后客户端将Put请求发送给相应的HRegionServer,在HRegionServer中它首先会将该Put操作写入WAL日志文件中(Flush到磁盘中)。
写完WAL日志文件后,HRegionServer根据Put中的TableName和RowKey找到对应的HRegion,并根据Column Family找到对应的HStore,并将Put写入到该HStore的MemStore中。此时写成功,并返回通知客户端。
MemStore Flush
MemStore是一个In Memory Sorted Buffer,在每个HStore中都有一个MemStore,即它是一个HRegion的一个Column Family对应一个实例。它的排列顺序以RowKey、Column Family、Column的顺序以及Timestamp的倒序
每一次Put/Delete请求都是先写入到MemStore中,当MemStore满后会Flush成一个新的StoreFile(底层实现是HFile),即一个HStore(Column Family)可以有0个或多个StoreFile(HFile)。
下三种情况可以触发MemStore的Flush动作:
1. 当一个HRegion中的MemStore的大小超过了:hbase.hregion.memstore.flush.size的大小,默认128MB。此时当前的MemStore会Flush到HFile中。
2. 当RS服务器上所有的MemStore的大小超过了:hbase.regionserver.global.memstore.upperLimit的大小,35%的内存使用量。此时当前HRegionServer中所有HRegion中的MemStore可能都会Flush。从最大的Memostore开始flush
3. 当前HRegionServer中WAL的大小超过了 1GBhbase.regionserver.hlog.blocksize * hbase.regionserver.max.logs的数量,当前HRegionServer中所有HRegion中的MemStore都会Flush这里指的是两个参数相乘的大小。查代码发现:hbase.regionserver.max.logs默认值是32,而hbase.regionserver.hlog.blocksize是HDFS的默认blocksize,32MB
在MemStore Flush过程中,还会在尾部追加一些meta数据,其中就包括Flush时最大的WAL sequence值,以告诉HBase这个StoreFile写入的最新数据的序列,那么在Recover时就直到从哪里开始。在HRegion启动时,这个sequence会被读取,并取最大的作为下一次更新时的起始sequence。
HFile格式
HBase的数据以KeyValue(Cell)的形式顺序的存储在HFile中,在MemStore的Flush过程中生成HFile,由于MemStore中存储的Cell遵循相同的排列顺序,因而Flush过程是顺序写,我们知道磁盘的顺序写性能很高,因为不需要不停的移动磁盘指针。
HFileV1
V1的HFile由多个Data Block、Meta Block、FileInfo、Data Index、Meta Index、Trailer组成,其中Data Block是HBase的最小存储单元
HFileV1版本的在实际使用过程中发现它占用内存多,因而增加了启动时间。
HFileV2
为了提升启动速度,还引入了延迟读的功能,即在HFile真正被使用时才对其进行解析。
对HFileV2格式具体分析,它是一个多层的类B+树索引,采用这种设计,可以实现查找不需要读取整个文件
HFileV3
三个版本。随着HFile版本迁移,KeyValue(Cell)的格式并未发生太多变化,只是在V3版本,尾部添加了一个可选的Tag数组。
LSM-TREE
概述
根据磁盘I/O类型,关系型存储引擎中广泛使用的B树及B+树,而Bigtable的存储架构基础的会使用Log-Structured Merge Tree。
而LSM-tree工作在磁盘传输速率的级别上,可以更好地扩展到更大的数据规模上,保证一个比较一致的插入速率,因为它会使用日志文件和一个内存存储结构,将随机写操作转化为顺序写。
优化系统性能往往需要和磁盘I/O打交道,而磁盘I/O产生的时延主要由下面3个因素决定
1)寻道时间(将磁盘臂移动到适当的柱面上所需要的时间,寻道时移动到相邻柱面移动所需时间1ms,而随机移动所需时间位5~10ms)
2)旋转时间(等待适当的扇区旋转到磁头下所需要的时间)
3)实际数据传输时间(低端硬盘的传输速率为5MB/ms,而高速硬盘的速率是10MB/ms)
磁盘I/O瓶颈可能出现在seek(寻道)和transfer(数据传输)上面。
B- Tree和B+Tree
如果没有太多的写操作,B+树可以工作的很好,它会进行比较繁重的优化来保证较低的访问时间。
The Log-Structured Merge-Tree(LSM-Tree)的一个重要思想就是通过使用某种算法
该算法会对索引变更进行延迟及批量处理,并通过一种类似于归并排序的方式高效地将更新迁移到磁盘,进行批量写入,利用磁盘顺序写性能远好于随机写这一特点,将随机写转变为顺序写,从而保证对磁盘的操作是顺序的,以提升写性能,同时建立索引,以获取较快的读性能,在读和写性能之间做一个平衡。
LSM-Tree原理
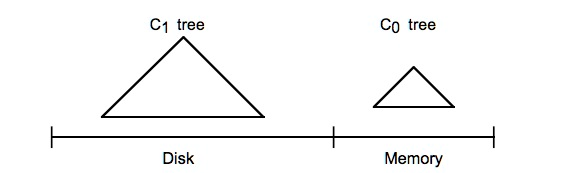
c0 Tree 是存在内存的的树结构,可以是(B-树,B+树,二叉树,跳跃表)
c1 Tree 是存在磁盘上的文件(本身也是一个树结构)
HBase的实现
MemStore
MemStore是HBase中C0的实现,向HBase中写数据的时候,首先会写到内存中的MemStore,当达到一定阀值之后,flush(顺序写)到磁盘,形成新的StoreFile(HFile),最后多个StoreFile(HFile)又会进行Compact。
memstore内部维护了一个数据结构:ConcurrentSkipListMap,数据存储是按照RowKey排好序的跳跃列表。跳跃列表的算法有同平衡树一样的渐进的预期时间边界,并且更简单、更快速和使用更少的空间。
C0树不一定要具有一个类B-树的结构。HBase中采用了线程安全的ConcurrentSkipListMap数据结构
HFile
HFlile是lsm tree中C1的实现
磁盘上的C1树是一个类似于B-Tree的数据结构,但是它是为顺序性的磁盘访问优化过的。
HBase读的实现
扫瞄读写的顺序依次是:BlockCache、MemStore、StoreFile(HFile)
Compaction机制
MemStore每次Flush会创建新的HFile,而过多的HFile会引起读的性能问题
Base采用Compaction机制来解决这个问题。在HBase中Compaction分为两种
Minor Compaction是指选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,在这个过程中不会处理已经Deleted或Expired的Cell。一次Minor Compaction的结果是更少并且更大的StoreFile。
Major Compaction是指将所有的StoreFile合并成一个StoreFile,在这个过程中,标记为Deleted的Cell会被删除,而那些已经Expired的Cell会被丢弃,那些已经超过最多版本数的Cell会被丢弃。一次Major Compaction的结果是一个HStore只有一个StoreFile存在。Major Compaction可以手动或自动触发,然而由于它会引起很多的IO操作而引起性能问题,因而它一般会被安排在周末、凌晨等集群比较闲的时间。
Hbase默认用的是Minor compaction。
Major Compaction可能会代理大量的磁盘I/O,从而阻塞Hbase其他的读写操作。所以对于Major Compactoin,一般选择在业务峰值低的时候执行。
HBASE表设计
Rowkey设计
Rowkey是不可分割的字节数,按字典排序由低到高存储在表中。
应该基于预期的访问模式来为Rowkey建模。Rowkey决定了访问HBase表时可以得到的性能
1)Region基于Rowkey为一个区间的行提供服务,并且负责区间的每一行;
2)HFile在硬盘上存储有序的行。
这两个因素是相互关联的。当Region将内存中数据刷写为HFile时,这些行已经排过序,也会有序地写到硬盘上。Rowkey的有序特性和底层存储格式可以保证HBase表在设计Rowkey之后的良好性能。
HBase只能在Rowkey上建立索引
1.将Rowkey以字典顺序从大到小排序
2.RowKey尽量散列设计
3.RowKey的长度尽量短
4.RowKey唯一
5.RowKey建议用String类型
6.RowKey设计得最好有意义
7.具有定长性
列族的设计
在设计hbase表时候,列族不宜过多,尽量的要少使用列族。
经常要在一起查询的数据最好放在一个列族中,尽量的减少跨列族的数据访问。
BloomFilter
Hash 函数在计算机领域,尤其是数据快速查找领域,加密领域用的极广
其作用是将一个大的数据集映射到一个小的数据集上面(这些小的数据集叫做哈希值,或者散列值)。
Hash table(散列表,也叫哈希表),是根据哈希值(Key value)而直接进行访问的数据结构。
它通过把哈希值映射到表中一个位置来访问记录,以加快查找的速度
Bloom Filter概述
Bloom Filter是1970年由布隆(Burton Howard Bloom)提出的。
它实际上是一个很长的二进制向量和一系列随机映射函数(Hash函数)
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法。
如 Hbase,Accumulo,Leveldb
使用了布隆过滤器来加快查询过程
访问磁盘需要花费大量时间,然而使用布隆过滤器可以快速判断某个Key对应的Value是否存在,因此可以避免很多不必要的磁盘IO操作,只是引入布隆过滤器会带来一定的内存消耗。
Bloom Filter 原理
布隆过滤器的缺点和优点一样明显。误算率(False Positive)是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
总结:
Bloom Filter 通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。
此外,引入布隆过滤器会带来一定的内存消耗。
布隆过滤器(Bloom Filter)允许对存储在每个数据块的数据做一个反向测验
Hbase优化
硬件和操作系统调优
1)配置内存
HBase对于内存的消耗是非常大的,主要是其LSM树状结构、缓存机制和日志记录机制决定的,所以物理内存当然是越大越好。推荐最小在32GB,再小会严重影响性能
2)配置CPU
一般CPU的品牌有Intel、AMD、IBM,Intel是主流。
3)垃圾回收器的选择
对于运行HBase相关进程JVM的垃圾回收器,不仅仅关注吞吐量,还关注停顿时间,而且两者之间停顿时间更为重要-----cms或G1
最终选用的垃圾收集器搭配组合是CMS+ParNew
4)JVM堆大小设置
堆内存大小参数hbase-env.sh文件中设置
export HBASE_HEAPSIZE=16384-----16G
这个值需要根据节点实际的物理内存来决定。一般不超过实际物理内存的1/2。
Hbase调优
1)调节数据块(data block)的大小
HFile数据块大小可以在列族层次设置
数据块越小,索引越大,从而占用更大内存空间
同时加载进内存的数据块越小,随机查找性能更好。
如果需要更好的序列扫描性能,那么一次能够加载更多HFile数据进入内存更为合理
这意味着应该将数据块设置为更大的值。相应地,索引变小,将在随机读性能上付出更多的代价。
大号的Block利于顺序扫描,小号的Bolck利于随机查找
2)适当时机关闭数据块缓存
把数据放进读缓存,并不是一定能够提升性能
如果一个表或表的列族只被顺序化扫描访问或很少被访问,则Get或Scan操作花费时间长一点是可以接受的。
关闭缓存的原因在于:如果只是执行很多顺序化扫描,会多次使用缓存,并且可能会滥用缓存,从而把应该放进缓存获得性能提升的数据给排挤出去。
3)开启布隆过滤器
数据块索引提供了一个有效的方法getDataBlockIndexReader(),在访问某个特定的行时用来查找应该读取的HFile的数据块。
该方法的作用有限。
当该行在表中不存在,或者存放在另一个HFile中,甚至在MemStore中
从硬盘读取数据块会带来I/O开销,也会滥用数据块缓存,这会影响性能,尤其是当面对一个巨大的数据集且有很多并发读用户时。
行级布隆过滤器比列标识符级布隆过滤器占用空间要少。当空间不是问题时,它们可以压榨整个系统的性能潜力。
4)开启数据压缩
HFile可以被压缩并存放在HDFS上,这有助于节省硬盘I/O,但是读写数据时压缩和解压缩会抬高CPU利用率。
5)设置Scan缓存
HBase的Scan查询中可以设置缓存,定义一次交互从服务器端传输到客户端的行数
这样能有效地减少服务器端和客户端的交互,更好地提升扫描查询的性能。
6)显式地指定列
当使用Scan或Get来处理大量的行时,最好确定一下所需要的列
在查询中指定某列或者某几列,能够有效地减少网络传输量,在一定程度上提升查询性能。
7)关闭ResultScanner
ResultScanner类用于存储服务端扫描的最终结果,可以通过遍历该类获取查询结果。
不关闭该类,可能会出现服务端在一段时间内一直保存连接,资源无法释放,从而导致服务器端某些资源的不可用,还有可能引发RegionServer的其他问题。
在使用完该类之后,需要执行关闭操作。这一点与JDBC操作MySQL类似,需要关闭连接。
8)使用批量读
通过调用HTable.get(Get)方法可以根据一个指定的行键获取HBase表中的一行记录
同样HBase提供了另一个方法可以根据一个指定的行键列表,批量获取多行记录
使用该方法可以在服务器端执行完批量查询后返回结果,降低网络传输的速度,节省网络I/O开销,对于数据实时性要求高且网络传输RTT高的场景,能带来明显的性能提升。
9)使用批量写
这样做的好处是批量执行,减少网络I/O开销。
通过调用HTable.put(Put)方法可以将一个指定的行键记录写入HBase,同样HBase提供了另一个方法,通过调用HTable.put(List<Put>)方法可以将指定的多个行键批量写入。
10)关闭写WAL日志
在默认情况下,为了保证系统的高可用性,写WAL日志是开启状态
WAL是规避数据丢失风险的一种补偿机制,如果应用可以容忍一定的数据丢失的风险,可以尝试在更新数据时,关闭写WAL。
该方法存在的风险是,当RegionServer宕机时,可能写入的数据会出现丢失的情况,且无法恢复。
11)设置AutoFlush
HTable有一个属性是AutoFlush,该属性用于支持客户端的批量更新。
如果将该属性设置为false,当客户端提交Put请求时,将该请求在客户端缓存,直到数据达到某个阈值的容量时才提交
这种方式避免了每次跟服务端交互,采用批量提交的方式,所以更高效。
但是,如果还没有达到该缓存而客户端崩溃,该部分数据将由于未发送到RegionServer而丢失。这对于有些零容忍的在线服务是不可接受的。所以,设置该参数的时候要慎重。
12)预创建Region
在HBase中创建表时,该表开始只有一个Region,插入该表的所有数据会保存在该Region中。
当该Region大小达到一定阈值时,就会发生分裂(Region Splitting)操作
并且在这个表创建后相当长的一段时间内,针对该表的所有写操作总是集中在某一台或者少数几台机器上,这不仅仅造成局部磁盘和网络资源紧张,同时也是对整个集群资源的浪费。
这个问题在初始化表,即批量导入原始数据的时候,特别明显。为了解决这个问题,可以使用预创建Region的方法。
13)调整ZooKeeper Session的有效时长
这个默认值是180秒
这意味着一旦某个RegionServer宕机,HMaster至少需要180秒才能察觉到宕机,然后开始恢复。或者客户端读写过程中,如果服务端不能提供服务,客户端直到180秒后才能觉察到。
在某些场景中,这样的时长可能对生产线业务来讲不能容忍,需要调整这个值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号