
Go-内存To Be
做一个快乐的互联网搬运工~
逃逸分析
逃逸分析的概念
在编译程序优化理论中,逃逸分析是一种确定指针动态范围的方法——分析在程序的哪些地方可以访问到指针。 它涉及到指针分析和形状分析。 当一个变量(或对象)在子程序中被分配时,一个指向变量的指针可能逃逸到其它执行线程中,或是返回到调用者子程序。
——维基百科
Go在一定程度消除了堆和栈的区别,因为go在编译的时候进行逃逸分析,来决定一个对象放栈上还是放堆上,不逃逸的对象放栈上,可能逃逸的放堆上。
逃逸分析的作用
堆与栈相比,栈具有速度快,易分配、易释放的特点,而堆适合不可预知大小的内存分配,但分配、回收成本大。通过逃逸分析,可以尽量把那些不需要分配到堆上的变量直接分配到栈上,堆上的变量少了,会减轻分配堆内存的开销,同时也会减少gc的压力,提高程序的运行速度。
另外,通过逃逸分析,还可以进行同步消除,如果你定义的对象的方法上有同步锁,但在运行时,却只有一个线程在访问,此时逃逸分析后的机器码,会去掉同步锁运行。
如何逃逸分析
根据维基百科的定义我们可以简化一下概念:如果一个函数返回对一个变量的引用,那么它就会发生逃逸。
看一个例子:


package main
import "fmt"
//func foo() *int {
// t:=3
// return &t
//}
func boo() int {
t:=3
return t
}
func main() {
//x:=foo()
//fmt.Println(*x)
//# command-line-arguments
//./memory.go:7:9: &t escapes to heap
//./memory.go:6:2: moved to heap: t
//./memory.go:17:14: *x escapes to heap
//./memory.go:17:13: main ... argument does not escape
var x int
x=boo()
fmt.Println(x)
//# command-line-arguments
//./memory.go:20:13: x escapes to heap
//./memory.go:20:13: main ... argument does not escape
}
其中有两个函数,一个传值,一个传地址,我们可以通过命令
go build -gcflags '-m -l' main.go
发现,传值变量没有发生逃逸,传址变量发生了逃逸。
但是代码中,main函数里的x也逃逸了,这是因为有些函数参数为interface类型,比如fmt.Println(a ...interface{}),编译期间很难确定其参数的具体类型,也会发生逃逸。
并且,如果一个变量需要申请的内存过大,超过了栈的存储能力,即便在函数返回后,它不会被引用,还是会被分配到堆上。
因此,当出现地址引用、申请内存过大、无法确定内存大小(比如切片)、无法确定引用类型(比如interface)这4种情况的时候,会发生逃逸。
所以啊,指针是把双刃剑,减少逃逸代码,有助于提升代码运行效率。
实例
type S struct {}
func main() {
var x S
y:=&x
_=*identity(y)
}
func identity(z *S) *S {
return z
}
//# command-line-arguments
//./memory2.go:11:15: leaking param: z to result ~r1 level=0
//./memory2.go:7:5: main &x does not escape
//没有发生逃逸
//因为identity这个函数仅仅输入一个变量,
//又将这个变量作为返回输出,但identity并没有引用z,所以这个变量没有逃逸,
//而x没有被引用,且生命周期也在mian里,x没有逃逸,分配在栈上。
//但是参数z发生了泄漏(也有的说法是z是流式的),参数泄漏不是内存泄漏,
//仅仅是指而是指该传入参数的内容的生命期,超过函数调用期,也就是函数返回后,该参数的内容仍然存活
package main
type M struct {}
func main() {
var x M
_=*ref(x)
}
func ref(z M) *M {
return &z
}
//# command-line-arguments
//./memory3.go:11:9: &z escapes to heap
//./memory3.go:10:10: moved to heap: z
//变量z发生了逃逸
//go都是值传递,ref函数copy了x的值,传给z,返回z的指针,
//然后在函数外被引用,说明z这个变量在函数內声明,可能会被函数外的其他程序访问。
//所以z逃逸了,分配在堆上。
type Q struct {
A *int
}
func main() {
var i int
refStruct(i)
}
func refStruct(y int) (z Q) {
z.A=&y
return z
}
//# command-line-arguments
//./memory4.go:13:6: &y escapes to heap
//./memory4.go:12:16: moved to heap: y
//y发生逃逸
//在struct里好像并没有区别,有可能被函数外的程序访问就会逃逸
type Q2 struct {
A *int
}
func main() {
var i int
refStruct2(&i)
}
func refStruct2(y *int) (z Q2) {
z.A=y
return z
}
//# command-line-arguments
//./memory5.go:12:17: leaking param: y to result z level=0
//./memory5.go:9:13: main &i does not escape
//y没有逃逸,只是发生了参数泄漏
//因为y只作为一个复制的载体,并不会被外部引用
type D struct {
J *int
}
func main() {
var x D
var i int
ref2(&i,&x)
}
func ref2(y *int,z *D) {
z.J=y
//return z
}
//# command-line-arguments
//./memory6.go:13:11: leaking param: y
//./memory6.go:13:18: ref2 z does not escape
//./memory6.go:10:7: &i escapes to heap
//./memory6.go:9:6: moved to heap: i
//./memory6.go:10:10: main &x does not escape
//y没有逃逸,只是泄漏,因为显而易见的原因
//z也没有发生逃逸,因为它作为一个在函数内被定义的变量,只是被赋了个值而已,并不会再被外部引用
//而i发生了逃逸,因为i作为一个在main函数里被定义的变量,被传到函数ref2里,它这块内存锁标定的地址被外部引用,因此发生逃逸。
//x没有发生逃逸,因为它作为一个在main函数里被定义的变量,只是被赋值,并没有将自己的地址进行传递,因此没有发生逃逸
//加上return,是如下结果
//# command-line-arguments
//./memory6.go:13:11: leaking param: y
//./memory6.go:13:18: leaking param: z to result ~r2 level=0
//./memory6.go:10:7: &i escapes to heap
//./memory6.go:9:6: moved to heap: i
//./memory6.go:10:10: main &x does not escape
//大体结果一样,只不过z发生了泄漏
看完这些例子,你应该对逃逸分析有了一个大体的了解,或者,更凌乱了。
内存管理
对于内置runtime system的编程语言,通常会抛弃传统的内存分配方式,改为自主管理内存。这样可以完成类似预分配、内存池、垃圾回收等操作,以避开频繁地向操作系统申请、释放内存,产生过多的系统调用而导致的性能问题。
golang的runtime system同样实现了一套内存池机制,接管了所有的内存申请和释放的动作。
基础概念
Golang程序启动伊始,会向系统申请一块内存(虚拟的地址空间),如下图:
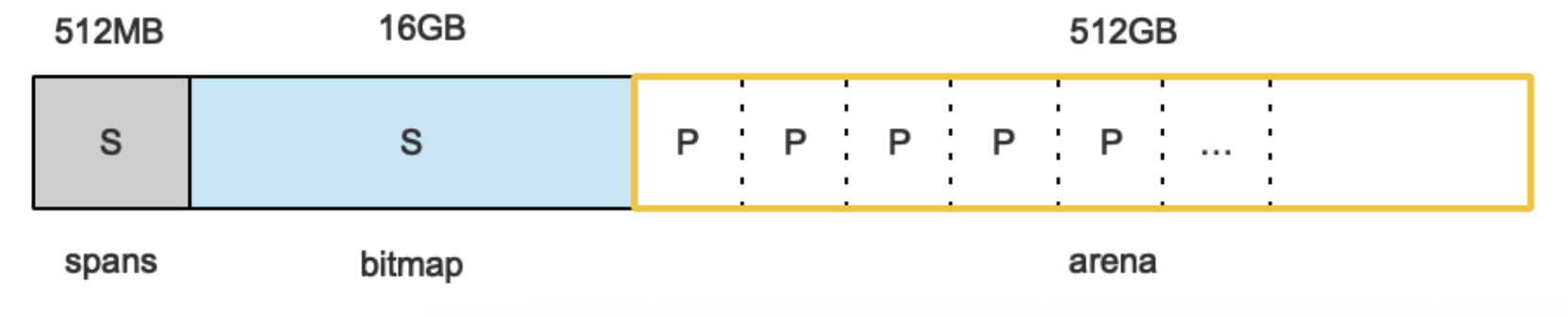
盗了下面链接一个作者的图~
预申请的内存分为三部分:spans、bitmap、arena。
arena就是通俗意义上的堆区,它被分割成页,每一页8KB,所以一共有512GB/8KB页。
bitmap用于标识arena中哪些地址保存了对象,以及对象是否包含指针,如下图:
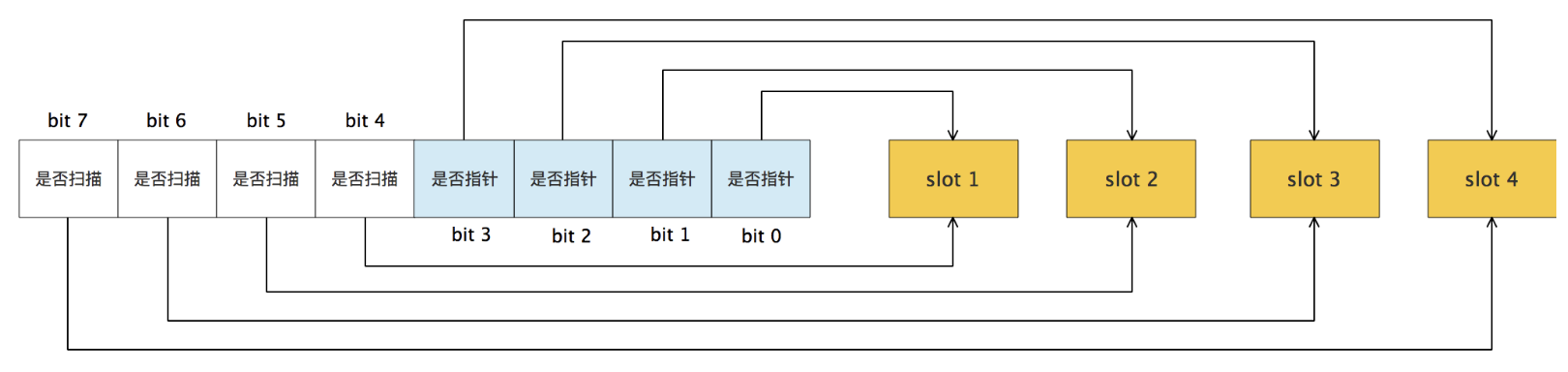
其中1个byte(8bit)标识arena中4页的信息,也就是说2bit标识1页,所以bitmap的大小为((512GB/8KB)/4)*1B=16GB。
spans用于表示arena区中的某一页属于哪个mspan(就是由arena页组合起来的内存管理基本单元),如下图:
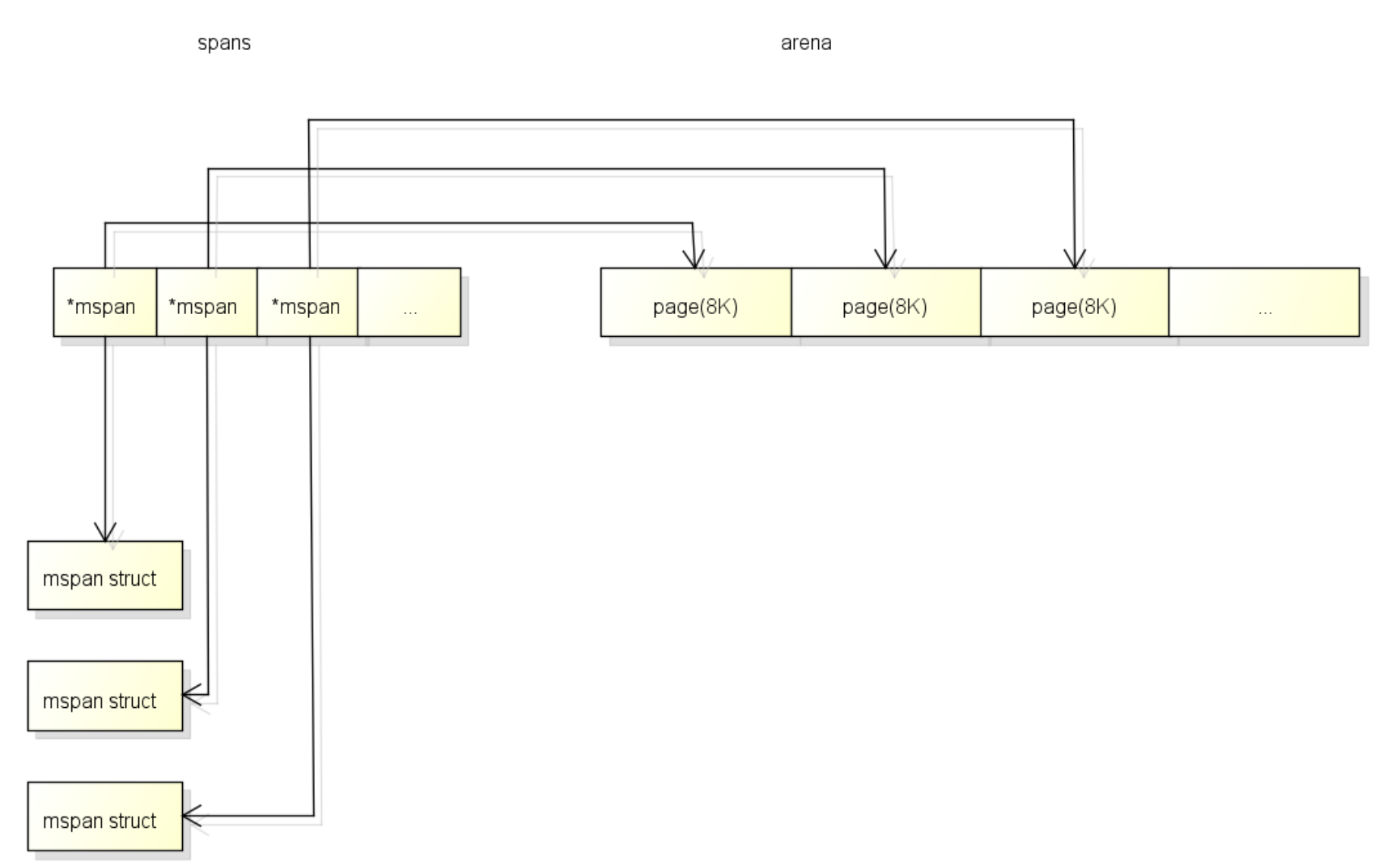
每个指针对应一页,所以spans的大小为(512GB/8K)*8B。
核心数据结构
内存管理单元
mspan
mspan是内存分配和管理的基本单位,用于管理预分配个数为sizeClass的连续地址内存。
如下源码:
package runtime
// class bytes/obj bytes/span objects tail waste max waste
// 1 8 8192 1024 0 87.50%
// 2 16 8192 512 0 43.75%
// 3 32 8192 256 0 46.88%
// 4 48 8192 170 32 31.52%
// 5 64 8192 128 0 23.44%
// 6 80 8192 102 32 19.07%
// 7 96 8192 85 32 15.95%
// 8 112 8192 73 16 13.56%
// 9 128 8192 64 0 11.72%
// 10 144 8192 56 128 11.82%
// 11 160 8192 51 32 9.73%
// 12 176 8192 46 96 9.59%
// 13 192 8192 42 128 9.25%
// 14 208 8192 39 80 8.12%
// 15 224 8192 36 128 8.15%
// 16 240 8192 34 32 6.62%
// 17 256 8192 32 0 5.86%
// 18 288 8192 28 128 12.16%
// 19 320 8192 25 192 11.80%
// 20 352 8192 23 96 9.88%
// 21 384 8192 21 128 9.51%
// 22 416 8192 19 288 10.71%
// 23 448 8192 18 128 8.37%
// 24 480 8192 17 32 6.82%
// 25 512 8192 16 0 6.05%
// 26 576 8192 14 128 12.33%
// 27 640 8192 12 512 15.48%
// 28 704 8192 11 448 13.93%
// 29 768 8192 10 512 13.94%
// 30 896 8192 9 128 15.52%
// 31 1024 8192 8 0 12.40%
// 32 1152 8192 7 128 12.41%
// 33 1280 8192 6 512 15.55%
// 34 1408 16384 11 896 14.00%
// 35 1536 8192 5 512 14.00%
// 36 1792 16384 9 256 15.57%
// 37 2048 8192 4 0 12.45%
// 38 2304 16384 7 256 12.46%
// 39 2688 8192 3 128 15.59%
// 40 3072 24576 8 0 12.47%
// 41 3200 16384 5 384 6.22%
// 42 3456 24576 7 384 8.83%
// 43 4096 8192 2 0 15.60%
// 44 4864 24576 5 256 16.65%
// 45 5376 16384 3 256 10.92%
// 46 6144 24576 4 0 12.48%
// 47 6528 32768 5 128 6.23%
// 48 6784 40960 6 256 4.36%
// 49 6912 49152 7 768 3.37%
// 50 8192 8192 1 0 15.61%
// 51 9472 57344 6 512 14.28%
// 52 9728 49152 5 512 3.64%
// 53 10240 40960 4 0 4.99%
// 54 10880 32768 3 128 6.24%
// 55 12288 24576 2 0 11.45%
// 56 13568 40960 3 256 9.99%
// 57 14336 57344 4 0 5.35%
// 58 16384 16384 1 0 12.49%
// 59 18432 73728 4 0 11.11%
// 60 19072 57344 3 128 3.57%
// 61 20480 40960 2 0 6.87%
// 62 21760 65536 3 256 6.25%
// 63 24576 24576 1 0 11.45%
// 64 27264 81920 3 128 10.00%
// 65 28672 57344 2 0 4.91%
// 66 32768 32768 1 0 12.50%
const (
_MaxSmallSize = 32768
smallSizeDiv = 8
smallSizeMax = 1024
largeSizeDiv = 128
_NumSizeClasses = 67
_PageShift = 13
)
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
var class_to_allocnpages = [_NumSizeClasses]uint8{0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 2, 1, 2, 1, 3, 2, 3, 1, 3, 2, 3, 4, 5, 6, 1, 7, 6, 5, 4, 3, 5, 7, 2, 9, 7, 5, 8, 3, 10, 7, 4}
type divMagic struct {
shift uint8
shift2 uint8
mul uint16
baseMask uint16
}
var class_to_divmagic = [_NumSizeClasses]divMagic{{0, 0, 0, 0}, {3, 0, 1, 65528}, {4, 0, 1, 65520}, {5, 0, 1, 65504}, {4, 9, 171, 0}, {6, 0, 1, 65472}, {4, 10, 205, 0}, {5, 9, 171, 0}, {4, 11, 293, 0}, {7, 0, 1, 65408}, {4, 9, 57, 0}, {5, 10, 205, 0}, {4, 12, 373, 0}, {6, 7, 43, 0}, {4, 13, 631, 0}, {5, 11, 293, 0}, {4, 13, 547, 0}, {8, 0, 1, 65280}, {5, 9, 57, 0}, {6, 9, 103, 0}, {5, 12, 373, 0}, {7, 7, 43, 0}, {5, 10, 79, 0}, {6, 10, 147, 0}, {5, 11, 137, 0}, {9, 0, 1, 65024}, {6, 9, 57, 0}, {7, 6, 13, 0}, {6, 11, 187, 0}, {8, 5, 11, 0}, {7, 8, 37, 0}, {10, 0, 1, 64512}, {7, 9, 57, 0}, {8, 6, 13, 0}, {7, 11, 187, 0}, {9, 5, 11, 0}, {8, 8, 37, 0}, {11, 0, 1, 63488}, {8, 9, 57, 0}, {7, 10, 49, 0}, {10, 5, 11, 0}, {7, 10, 41, 0}, {7, 9, 19, 0}, {12, 0, 1, 61440}, {8, 9, 27, 0}, {8, 10, 49, 0}, {11, 5, 11, 0}, {7, 13, 161, 0}, {7, 13, 155, 0}, {8, 9, 19, 0}, {13, 0, 1, 57344}, {8, 12, 111, 0}, {9, 9, 27, 0}, {11, 6, 13, 0}, {7, 14, 193, 0}, {12, 3, 3, 0}, {8, 13, 155, 0}, {11, 8, 37, 0}, {14, 0, 1, 49152}, {11, 8, 29, 0}, {7, 13, 55, 0}, {12, 5, 7, 0}, {8, 14, 193, 0}, {13, 3, 3, 0}, {7, 14, 77, 0}, {12, 7, 19, 0}, {15, 0, 1, 32768}}
var size_to_class8 = [smallSizeMax/smallSizeDiv + 1]uint8{0, 1, 2, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10, 11, 11, 12, 12, 13, 13, 14, 14, 15, 15, 16, 16, 17, 17, 18, 18, 18, 18, 19, 19, 19, 19, 20, 20, 20, 20, 21, 21, 21, 21, 22, 22, 22, 22, 23, 23, 23, 23, 24, 24, 24, 24, 25, 25, 25, 25, 26, 26, 26, 26, 26, 26, 26, 26, 27, 27, 27, 27, 27, 27, 27, 27, 28, 28, 28, 28, 28, 28, 28, 28, 29, 29, 29, 29, 29, 29, 29, 29, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 30, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31}
var size_to_class128 = [(_MaxSmallSize-smallSizeMax)/largeSizeDiv + 1]uint8{31, 32, 33, 34, 35, 36, 36, 37, 37, 38, 38, 39, 39, 39, 40, 40, 40, 41, 42, 42, 43, 43, 43, 43, 43, 44, 44, 44, 44, 44, 44, 45, 45, 45, 45, 46, 46, 46, 46, 46, 46, 47, 47, 47, 48, 48, 49, 50, 50, 50, 50, 50, 50, 50, 50, 50, 50, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 52, 52, 53, 53, 53, 53, 54, 54, 54, 54, 54, 55, 55, 55, 55, 55, 55, 55, 55, 55, 55, 55, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 57, 57, 57, 57, 57, 57, 58, 58, 58, 58, 58, 58, 58, 58, 58, 58, 58, 58, 58, 58, 58, 58, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 60, 60, 60, 60, 60, 61, 61, 61, 61, 61, 61, 61, 61, 61, 61, 61, 62, 62, 62, 62, 62, 62, 62, 62, 62, 62, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66}
可以看到,
mspan共有67种sizeClass,每个mspan按照自身的sizeClass分割成若干个object,每个object可存储一个对象。
比如,某mspan的sizeClass为3,那么其划分的object大小就是32B,可以存储(16B,32B]大小的的对象。同时,sizeClass还决定了mspan能够分到的页数,比如,sizeClass对应能分到的页数是1。
另外,数组中最大的数是32768,也就是32KB,超过32KB即是大对象,sizeClass=0就表示大对象,不通过mspan,直接由mheap分配内存。对于,小于16B的是微小对象,分配器会将其合并,将几个对象分配到同一个object中。
有一点我有些恍惚,最大的容量是32KB,而arena中每一页的大小是8KB,也就是说,定然存在跨页存储,虽然没有找到可靠的资料,但是,观察一下源码可以发现,页数为1的最大object容量是8192B,也就正好是8KB。当object为32KB时,页数为4,当object为24KB时,页数为3,也就是说,在golang写死的sizeClass里,针对页面容量、可存放对象大小和页数已经预置了对应关系,或许,这也是写死sizeClass的原因之一。
mspan的结构体如下:
type mspan struct {
next *mspan // next span in list, or nil if none
prev *mspan // previous span in list, or nil if none
list *mSpanList // For debugging. TODO: Remove.
startAddr uintptr // address of first byte of span aka s.base()
npages uintptr // number of pages in span
manualFreeList gclinkptr // list of free objects in mSpanManual spans
// freeindex is the slot index between 0 and nelems at which to begin scanning
// for the next free object in this span.
// Each allocation scans allocBits starting at freeindex until it encounters a 0
// indicating a free object. freeindex is then adjusted so that subsequent scans begin
// just past the newly discovered free object.
//
// If freeindex == nelem, this span has no free objects.
//
// allocBits is a bitmap of objects in this span.
// If n >= freeindex and allocBits[n/8] & (1<<(n%8)) is 0
// then object n is free;
// otherwise, object n is allocated. Bits starting at nelem are
// undefined and should never be referenced.
//
// Object n starts at address n*elemsize + (start << pageShift).
freeindex uintptr
// TODO: Look up nelems from sizeclass and remove this field if it
// helps performance.
nelems uintptr // number of object in the span.
// Cache of the allocBits at freeindex. allocCache is shifted
// such that the lowest bit corresponds to the bit freeindex.
// allocCache holds the complement of allocBits, thus allowing
// ctz (count trailing zero) to use it directly.
// allocCache may contain bits beyond s.nelems; the caller must ignore
// these.
allocCache uint64
// allocBits and gcmarkBits hold pointers to a span's mark and
// allocation bits. The pointers are 8 byte aligned.
// There are three arenas where this data is held.
// free: Dirty arenas that are no longer accessed
// and can be reused.
// next: Holds information to be used in the next GC cycle.
// current: Information being used during this GC cycle.
// previous: Information being used during the last GC cycle.
// A new GC cycle starts with the call to finishsweep_m.
// finishsweep_m moves the previous arena to the free arena,
// the current arena to the previous arena, and
// the next arena to the current arena.
// The next arena is populated as the spans request
// memory to hold gcmarkBits for the next GC cycle as well
// as allocBits for newly allocated spans.
//
// The pointer arithmetic is done "by hand" instead of using
// arrays to avoid bounds checks along critical performance
// paths.
// The sweep will free the old allocBits and set allocBits to the
// gcmarkBits. The gcmarkBits are replaced with a fresh zeroed
// out memory.
allocBits *gcBits
gcmarkBits *gcBits
// sweep generation:
// if sweepgen == h->sweepgen - 2, the span needs sweeping
// if sweepgen == h->sweepgen - 1, the span is currently being swept
// if sweepgen == h->sweepgen, the span is swept and ready to use
// if sweepgen == h->sweepgen + 1, the span was cached before sweep began and is still cached, and needs sweeping
// if sweepgen == h->sweepgen + 3, the span was swept and then cached and is still cached
// h->sweepgen is incremented by 2 after every GC
sweepgen uint32
divMul uint16 // for divide by elemsize - divMagic.mul
baseMask uint16 // if non-0, elemsize is a power of 2, & this will get object allocation base
allocCount uint16 // number of allocated objects
spanclass spanClass // size class and noscan (uint8)
state mSpanState // mspaninuse etc
needzero uint8 // needs to be zeroed before allocation
divShift uint8 // for divide by elemsize - divMagic.shift
divShift2 uint8 // for divide by elemsize - divMagic.shift2
scavenged bool // whether this span has had its pages released to the OS
elemsize uintptr // computed from sizeclass or from npages
unusedsince int64 // first time spotted by gc in mspanfree state
limit uintptr // end of data in span
speciallock mutex // guards specials list
specials *special // linked list of special records sorted by offset.
}
next *mspan
指向链表里的下一个mspan
prev *mspan
指向链表里的上一个mspan
list *mSpanList
mspan链表
startAddr uintptr
管理页的起始地址,直接指向arena区域的的某个位置
npages uintptr
管理的页数
manualFreeList gclinkptr
空闲对象列表
freeindex uintptr
freeindex是0到nelems之间的位置索引,在该索引处开始扫描此mspan的下一个空闲对象。每次分配从freeindex开始扫描allocBits,直到遇到空闲对象。然后调整freeindex,以便于后续扫描发现下一个空闲对象。如果freeindex等于nelems,那么这片mspan没有空闲对象。
nelems uintptr
管理的对象数
allocBits *gcBits
allocBits是此mspan中对象的位图。当n>=freeindex并且其位图标记为0,那么这个对象就是空闲的,否则,这个对象就是被占用的。
allocCount uint16
已分配的对象的个数
elemsize uintptr
对象的大小
内存管理组件
内存分配由内存分配器完成。分配器由3种组件构成:mcache、mcentral、mheap。
mcache
首先我们需要先简单了解一个概念,Go调度器的基本结构,也就是G-P-M模型:
-
G: 表示Goroutine,每个Goroutine对应一个G结构体,G存储Goroutine的运行堆栈、状态以及任务函数,可重用。G并非执行体,每个G需要绑定到P才能被调度执行。
-
P: Processor,表示逻辑处理器, 对G来说,P相当于CPU核,G只有绑定到P(在P的local runq中)才能被调度。对M来说,P提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等,P的数量决定了系统内最大可并行的G的数量(前提:物理CPU核数 >= P的数量),P的数量由用户设置的GOMAXPROCS决定,但是不论GOMAXPROCS设置为多大,P的数量最大为256。
-
M: Machine,OS线程抽象,代表着真正执行计算的资源,在绑定有效的P后,进入schedule循环;而schedule循环的机制大致是从Global队列、P的Local队列以及wait队列中获取G,切换到G的执行栈上并执行G的函数,调用goexit做清理工作并回到M,如此反复。M并不保留G状态,这是G可以跨M调度的基础,M的数量是不定的,由Go Runtime调整,为了防止创建过多OS线程导致系统调度不过来,目前默认最大限制为10000个。
其中,P是一个虚拟资源,同时只能被一个协程访问,所以P中的数据不需要锁。为了分配对象时有更好的性能,各个P中都有各种sizeClass的mspan的缓存,这样就可以直接给G分配。其结构如下:
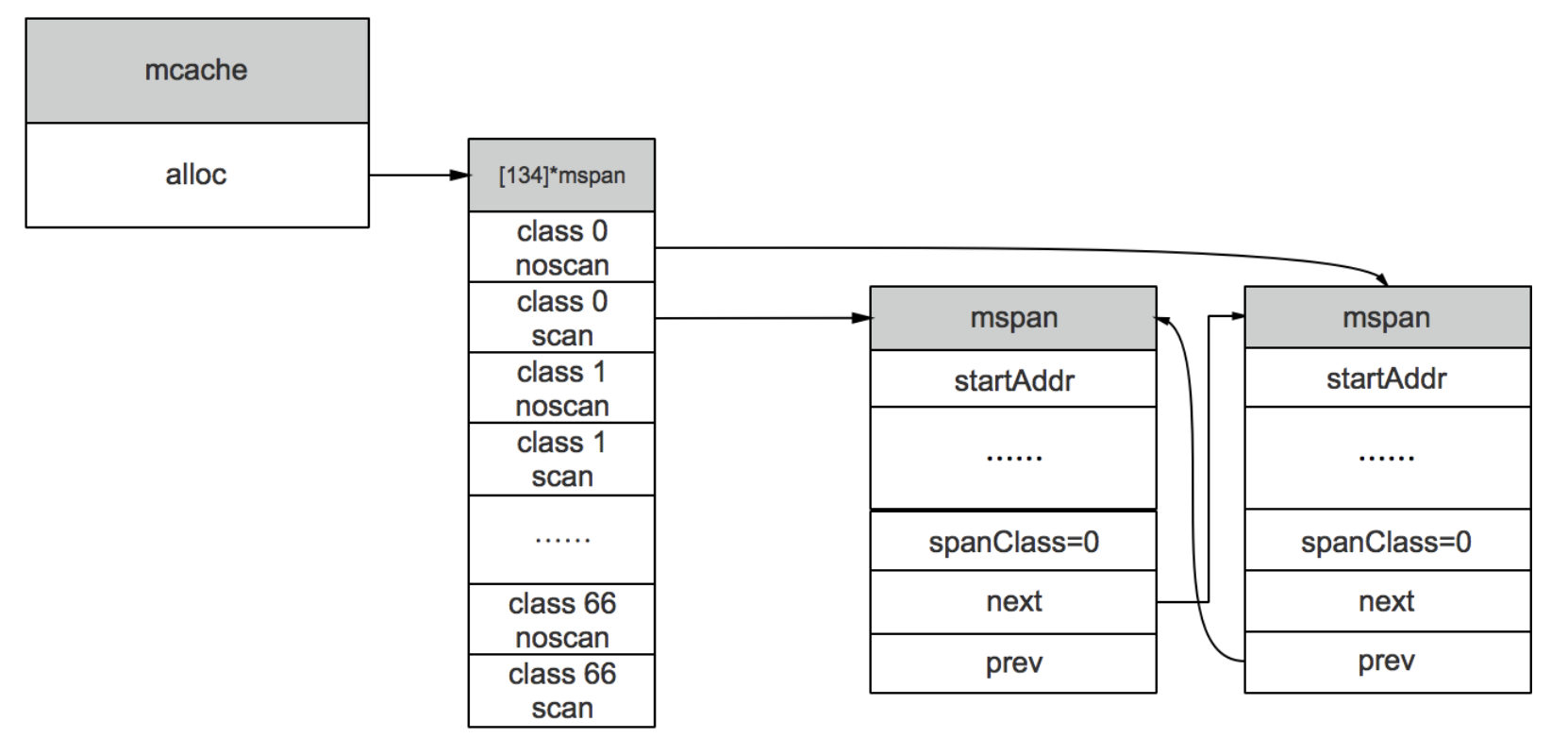
其中,对于67中sizeClass各有两个,一个用于分配包含指针的对象,一个用于分配不包含指针的对象,因此一个P中共有134个mspan的缓存。对于无指针对象的mspan在进行垃圾回收时,不需要进一步扫描它是否引用了其他活跃的对象。
mcache在初始化时没有任何mspan资源,在使用过程中会动态地从mcentral申请,之后缓存下来。当对象<=32KB时,使用mcache相应规格的mspan分配。
type mcache struct {
// The following members are accessed on every malloc,
// so they are grouped here for better caching.
next_sample int32 // trigger heap sample after allocating this many bytes
local_scan uintptr // bytes of scannable heap allocated
// Allocator cache for tiny objects w/o pointers.
// See "Tiny allocator" comment in malloc.go.
// tiny points to the beginning of the current tiny block, or
// nil if there is no current tiny block.
//
// tiny is a heap pointer. Since mcache is in non-GC'd memory,
// we handle it by clearing it in releaseAll during mark
// termination.
tiny uintptr
tinyoffset uintptr
local_tinyallocs uintptr // number of tiny allocs not counted in other stats
// The rest is not accessed on every malloc.
alloc [numSpanClasses]*mspan // spans to allocate from, indexed by spanClass
stackcache [_NumStackOrders]stackfreelist
// Local allocator stats, flushed during GC.
local_largefree uintptr // bytes freed for large objects (>maxsmallsize)
local_nlargefree uintptr // number of frees for large objects (>maxsmallsize)
local_nsmallfree [_NumSizeClasses]uintptr // number of frees for small objects (<=maxsmallsize)
// flushGen indicates the sweepgen during which this mcache
// was last flushed. If flushGen != mheap_.sweepgen, the spans
// in this mcache are stale and need to the flushed so they
// can be swept. This is done in acquirep.
flushGen uint32
}
其中numSpanClasses的就是134,而且mcache中也没有任何加锁信息。
mcentral
为所有mcache提供切分好的mspan资源,包含已分配出去的和未分配出去的。每个mcentral对应一种sizeClass的mspan,因此共有134个mcentral。其结构如下:

当P中没有特定大小的mspan时,就会向mcentral申请。mcentral由于是共享资源,因此需要有锁。
type mcentral struct {
lock mutex
spanclass spanClass
nonempty mSpanList // list of spans with a free object, ie a nonempty free list
empty mSpanList // list of spans with no free objects (or cached in an mcache)
// nmalloc is the cumulative count of objects allocated from
// this mcentral, assuming all spans in mcaches are
// fully-allocated. Written atomically, read under STW.
nmalloc uint64
}
mcentral的结构体源码很短,清晰地体现出了它的特点。其中的nmalloc用于累计已分配的mspan数量。
mcache向mcentral获取、归还mspan的流程:
- 获取:加锁;从nonempty中取出一个可用mspan;将其从nonempty链表删除;将其加入到empty链表;解锁。
- 归还:加锁;将mspan从empty链表删除;加入到nonempty链表;解锁。
mheap
代表Go程序持有的所有堆空间。当mcentral没有空闲的mspan时,会向mheap申请。若mheap也没有,会向操作系统申请。mheap主要用于大对象的内存分配,以及管理未切割的mspan,用于给mcentral切割成小对象。其结构如下:
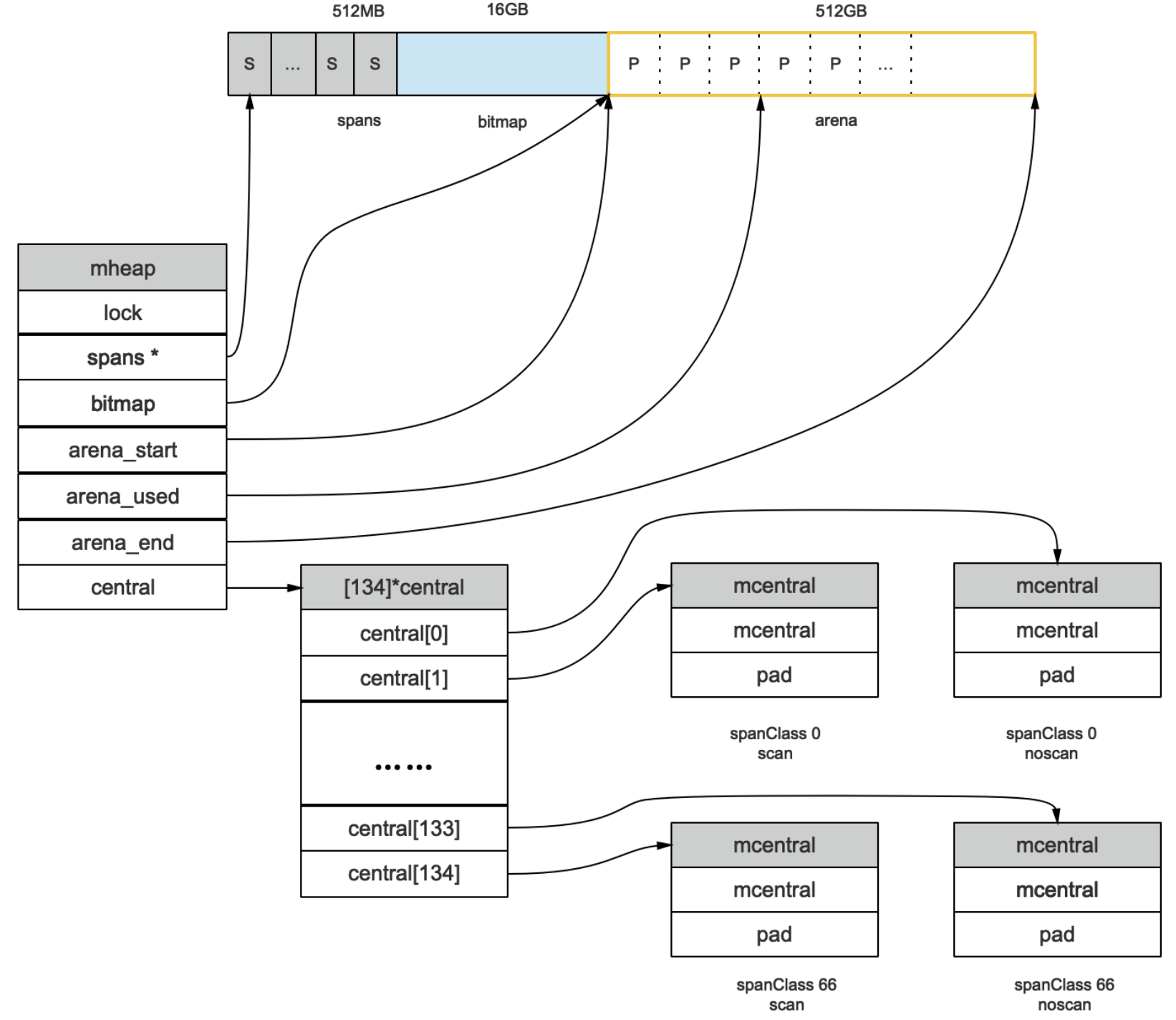
mheap的源码如下:
type mheap struct {
lock mutex
free mTreap // free and non-scavenged spans
scav mTreap // free and scavenged spans
sweepgen uint32 // sweep generation, see comment in mspan
sweepdone uint32 // all spans are swept
sweepers uint32 // number of active sweepone calls
// allspans is a slice of all mspans ever created. Each mspan
// appears exactly once.
//
// The memory for allspans is manually managed and can be
// reallocated and move as the heap grows.
//
// In general, allspans is protected by mheap_.lock, which
// prevents concurrent access as well as freeing the backing
// store. Accesses during STW might not hold the lock, but
// must ensure that allocation cannot happen around the
// access (since that may free the backing store).
allspans []*mspan // all spans out there
// sweepSpans contains two mspan stacks: one of swept in-use
// spans, and one of unswept in-use spans. These two trade
// roles on each GC cycle. Since the sweepgen increases by 2
// on each cycle, this means the swept spans are in
// sweepSpans[sweepgen/2%2] and the unswept spans are in
// sweepSpans[1-sweepgen/2%2]. Sweeping pops spans from the
// unswept stack and pushes spans that are still in-use on the
// swept stack. Likewise, allocating an in-use span pushes it
// on the swept stack.
sweepSpans [2]gcSweepBuf
_ uint32 // align uint64 fields on 32-bit for atomics
// Proportional sweep
//
// These parameters represent a linear function from heap_live
// to page sweep count. The proportional sweep system works to
// stay in the black by keeping the current page sweep count
// above this line at the current heap_live.
//
// The line has slope sweepPagesPerByte and passes through a
// basis point at (sweepHeapLiveBasis, pagesSweptBasis). At
// any given time, the system is at (memstats.heap_live,
// pagesSwept) in this space.
//
// It's important that the line pass through a point we
// control rather than simply starting at a (0,0) origin
// because that lets us adjust sweep pacing at any time while
// accounting for current progress. If we could only adjust
// the slope, it would create a discontinuity in debt if any
// progress has already been made.
pagesInUse uint64 // pages of spans in stats mSpanInUse; R/W with mheap.lock
pagesSwept uint64 // pages swept this cycle; updated atomically
pagesSweptBasis uint64 // pagesSwept to use as the origin of the sweep ratio; updated atomically
sweepHeapLiveBasis uint64 // value of heap_live to use as the origin of sweep ratio; written with lock, read without
sweepPagesPerByte float64 // proportional sweep ratio; written with lock, read without
// TODO(austin): pagesInUse should be a uintptr, but the 386
// compiler can't 8-byte align fields.
// Page reclaimer state
// reclaimIndex is the page index in allArenas of next page to
// reclaim. Specifically, it refers to page (i %
// pagesPerArena) of arena allArenas[i / pagesPerArena].
//
// If this is >= 1<<63, the page reclaimer is done scanning
// the page marks.
//
// This is accessed atomically.
reclaimIndex uint64
// reclaimCredit is spare credit for extra pages swept. Since
// the page reclaimer works in large chunks, it may reclaim
// more than requested. Any spare pages released go to this
// credit pool.
//
// This is accessed atomically.
reclaimCredit uintptr
// scavengeCredit is spare credit for extra bytes scavenged.
// Since the scavenging mechanisms operate on spans, it may
// scavenge more than requested. Any spare pages released
// go to this credit pool.
//
// This is protected by the mheap lock.
scavengeCredit uintptr
// Malloc stats.
largealloc uint64 // bytes allocated for large objects
nlargealloc uint64 // number of large object allocations
largefree uint64 // bytes freed for large objects (>maxsmallsize)
nlargefree uint64 // number of frees for large objects (>maxsmallsize)
nsmallfree [_NumSizeClasses]uint64 // number of frees for small objects (<=maxsmallsize)
// arenas is the heap arena map. It points to the metadata for
// the heap for every arena frame of the entire usable virtual
// address space.
//
// Use arenaIndex to compute indexes into this array.
//
// For regions of the address space that are not backed by the
// Go heap, the arena map contains nil.
//
// Modifications are protected by mheap_.lock. Reads can be
// performed without locking; however, a given entry can
// transition from nil to non-nil at any time when the lock
// isn't held. (Entries never transitions back to nil.)
//
// In general, this is a two-level mapping consisting of an L1
// map and possibly many L2 maps. This saves space when there
// are a huge number of arena frames. However, on many
// platforms (even 64-bit), arenaL1Bits is 0, making this
// effectively a single-level map. In this case, arenas[0]
// will never be nil.
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
// heapArenaAlloc is pre-reserved space for allocating heapArena
// objects. This is only used on 32-bit, where we pre-reserve
// this space to avoid interleaving it with the heap itself.
heapArenaAlloc linearAlloc
// arenaHints is a list of addresses at which to attempt to
// add more heap arenas. This is initially populated with a
// set of general hint addresses, and grown with the bounds of
// actual heap arena ranges.
arenaHints *arenaHint
// arena is a pre-reserved space for allocating heap arenas
// (the actual arenas). This is only used on 32-bit.
arena linearAlloc
// allArenas is the arenaIndex of every mapped arena. This can
// be used to iterate through the address space.
//
// Access is protected by mheap_.lock. However, since this is
// append-only and old backing arrays are never freed, it is
// safe to acquire mheap_.lock, copy the slice header, and
// then release mheap_.lock.
allArenas []arenaIdx
// sweepArenas is a snapshot of allArenas taken at the
// beginning of the sweep cycle. This can be read safely by
// simply blocking GC (by disabling preemption).
sweepArenas []arenaIdx
// _ uint32 // ensure 64-bit alignment of central
// central free lists for small size classes.
// the padding makes sure that the mcentrals are
// spaced CacheLinePadSize bytes apart, so that each mcentral.lock
// gets its own cache line.
// central is indexed by spanClass.
central [numSpanClasses]struct {
mcentral mcentral
pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte
}
spanalloc fixalloc // allocator for span*
cachealloc fixalloc // allocator for mcache*
treapalloc fixalloc // allocator for treapNodes*
specialfinalizeralloc fixalloc // allocator for specialfinalizer*
specialprofilealloc fixalloc // allocator for specialprofile*
speciallock mutex // lock for special record allocators.
arenaHintAlloc fixalloc // allocator for arenaHints
unused *specialfinalizer // never set, just here to force the specialfinalizer type into DWARF
}
其中具备了,锁信息、spans信息、arena区信息、central信息。
内存分配规则
大致的分配规则如下:
- <=16B的对象(小对象)使用mcache的tiny分配器分配;
-
(16B,32KB]的对象(一般对象),首先计算对象的规格大小,然后使用mcache中相应规格大小的mspan分配;
-
32KB以上的对象(大对象),直接从mheap上分配;
大致的分配流程可以从下图看出:
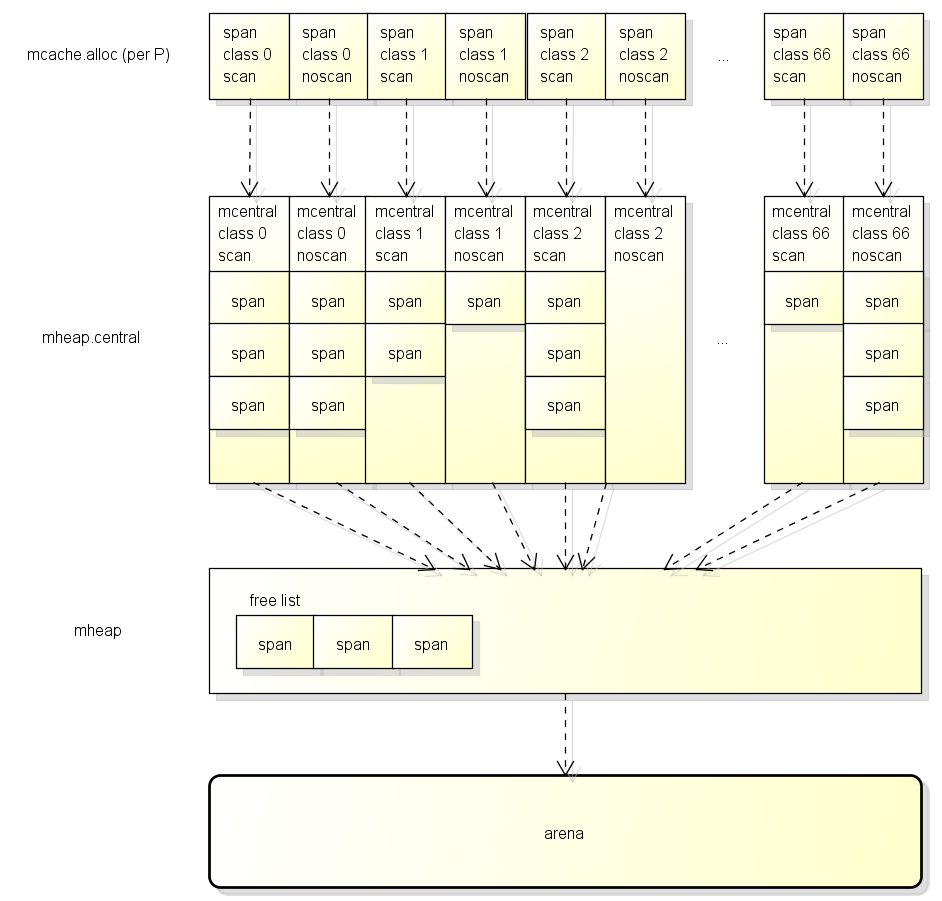
如果mcache没有相应规格大小的mspan,则向mcentral申请;
如果mcentral没有相应规格大小的mspan,则向mheap申请;
如果mheap也没有合适大小的mspan,则向操作系统申请。
参考资料
https://www.cnblogs.com/qcrao-2018/p/10453260.html
https://swanspouse.github.io/2018/08/22/golang-memory-model/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号