
PYTORCH
什么是 PyTorch ?
PyTorch是一个python库,它主要提供了两个高级功能:
- GPU加速的张量计算
- 构建在反向自动求导系统上的深度神经网络
1.定义数据
一般定义数据使用torch.Tensor , tensor的意思是张量,是数字各种形式的总称
#导入pytorch包
import torch
#数字
x = torch.tensor(0)
print(x)
#一维数组(向量)
x = torch.tensor([1,2,3,4,5,6])
print(x)
#二维数组(矩阵)
x = torch.ones(2,3)
print(x)
#任意维度的数组(张量)
x = torch.ones(2,3 4)
print(x)
输出结果:

创建Tensor有多种方法,包括:ones, zeros, eye, arange, linspace, rand, randn, normal, uniform, randperm:
# 创建一个空张量
x = torch.empty(5,3)
print(x)
# 创建一个随机初始化的张量
x = torch.rand(5,3)
print(x)
# 创建一个全0的张量,里面的数据类型为 long
x = torch.zeros(5,3,dtype=torch.long)
print(x)
# 基于现有的tensor,创建一个新tensor,
# 从而可以利用原有的tensor的dtype,device,size之类的属性信息
y = x.new_ones(5,3) #tensor new_* 方法,利用原来tensor的dtype,device
print(y)
z = torch.randn_like(x, dtype=torch.float) # 利用原来的tensor的大小,但是重新定义了dtype
print(z)
运行结果:

2.定义操作
凡是用Tensor进行各种运算的,都是Function
最终,还是需要用Tensor来进行计算的,计算无非是
- 基本运算,加减乘除,求幂求余
- 布尔运算,大于小于,最大最小
- 线性运算,矩阵乘法,求模,求行列式
基本运算包括: abs/sqrt/div/exp/fmod/pow ,及一些三角函数 cos/ sin/ asin/ atan2/ cosh,及 ceil/round/floor/trunc 等具体在使用的时候可以百度一下
布尔运算包括: gt/lt/ge/le/eq/ne,topk, sort, max/min
线性计算包括: trace, diag, mm/bmm,t,dot/cross,inverse,svd 等

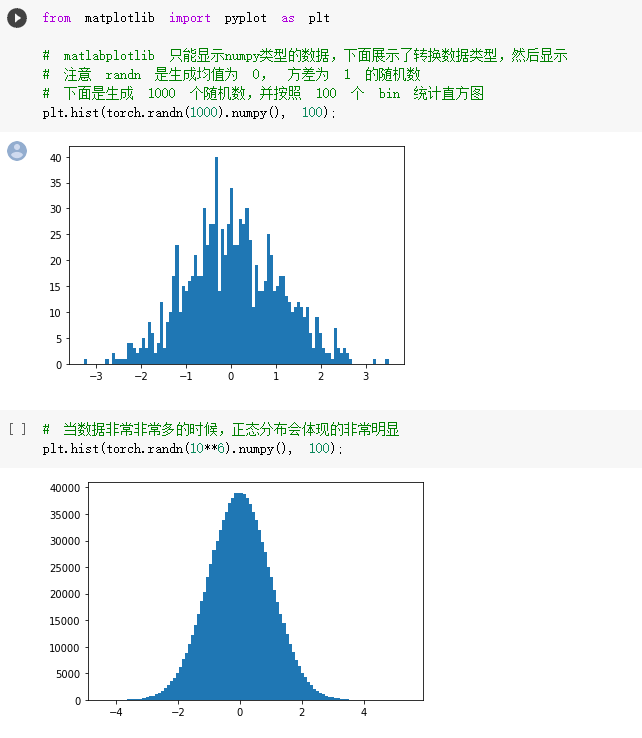
螺旋数据分类
- 初始数据
import random
import torch
from torch import nn, optim
import math
from IPython import display
from plot_lib import plot_data, plot_model, set_default
# 因为colab是支持GPU的,torch 将在 GPU 上运行
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device: ', device)
# 初始化随机数种子。神经网络的参数都是随机初始化的,
# 不同的初始化参数往往会导致不同的结果,当得到比较好的结果时我们通常希望这个结果是可以复现的,
# 因此,在pytorch中,通过设置随机数种子也可以达到这个目的
seed = 12345
random.seed(seed)
torch.manual_seed(seed)
N = 1000 # 每类样本的数量
D = 2 # 每个样本的特征维度
C = 3 # 样本的类别
H = 100 # 神经网络里隐层单元的数量
X = torch.zeros(N * C, D).to(device)
Y = torch.zeros(N * C, dtype=torch.long).to(device)
for c in range(C):
index = 0
t = torch.linspace(0, 1, N) # 在[0,1]间均匀的取10000个数,赋给t
# 下面的代码不用理解太多,总之是根据公式计算出三类样本(可以构成螺旋形)
# torch.randn(N) 是得到 N 个均值为0,方差为 1 的一组随机数,注意要和 rand 区分开
inner_var = torch.linspace( (2*math.pi/C)*c, (2*math.pi/C)*(2+c), N) + torch.randn(N) * 0.2
# 每个样本的(x,y)坐标都保存在 X 里
# Y 里存储的是样本的类别,分别为 [0, 1, 2]
for ix in range(N * c, N * (c + 1)):
X[ix] = t[index] * torch.FloatTensor((math.sin(inner_var[index]), math.cos(inner_var[index])))
Y[ix] = c
index += 1
print("Shapes:")
print("X:", X.size())
print("Y:", Y.size())
# visualise the data
plot_data(X, Y)
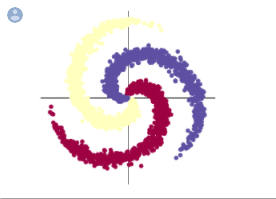
1.构建线性模型分类
learning_rate = 1e-3
lambda_l2 = 1e-5
# nn 包用来创建线性模型
# 每一个线性模型都包含 weight 和 bias
model = nn.Sequential(
nn.Linear(D, H),
nn.Linear(H, C)
)
model.to(device) # 把模型放到GPU上
# nn 包含多种不同的损失函数,这里使用的是交叉熵(cross entropy loss)损失函数
criterion = torch.nn.CrossEntropyLoss()
# 这里使用 optim 包进行随机梯度下降(stochastic gradient descent)优化
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
# 开始训练
for t in range(1000):
# 把数据输入模型,得到预测结果
y_pred = model(X)
# 计算损失和准确率
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = (Y == predicted).sum().float() / len(Y)
print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc))
display.clear_output(wait=True)
# 反向传播前把梯度置 0
optimizer.zero_grad()
# 反向传播优化
loss.backward()
# 更新全部参数
optimizer.step()
print(y_pred.shape)
print(y_pred[10, :])
print(score[10])
print(predicted[10])
# Plot trained model
print(model)
plot_model(X, Y, model)

心得体会
通过本次的pytorch练习,我熟悉了pytorch的基本操作,通过tensor来进行定义数据和定义操作等,以及初步学习螺旋数据的分类。在螺旋数据分类中,发现两层神经网络的分类准确率比线性模型分类的准确率高出了很高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号