
WM算法详解
提到多模式匹配算法,就得说一下Wu-Manber算法,其在多模式匹配领域相较于Aho-Corasick算法,就好象在单模式匹配算法中BM算法相较于KMP算法一样,在绝大多数场合,Wu-Manber算法的匹配效率要好于Aho-Corasick算法。这个算法是由吴升(台湾)和他的导师Udi Manber在九十年代提出。当然,要想充分理解WM算法如何加快多模式匹配的效率,还需要对BM算法的深刻了解,可以参考我的另一篇文章《BM算法详解》。
在BM算法中引入的坏字符跳转概念,是BM算法能够在一般应用场景中,效率高于KMP算法的主要原因。WM算法在多模式匹配中,也引入了类似的概念,从而实现了模式匹配中的大幅度跳转。但是在单模式应用场景,很少有哪个模式串会包含所有可能的输入字符,而在多模式匹配场景,如果模式集合的规模较大的话,很可能会覆盖很大一部分输入字符,导致坏字符跳转没有用武之地。所以WM算法中使用的坏字符跳转,不是指一个字符,而是一个字符块,或者说几个连续的字符。通过字符快的引入,扩大了字符范围,使得实现坏字符跳转的可能性大大增加。
WM算法一般由三个表构成,SHIFT,HASH,PREFIX。
SHIFT表就相当于BM算法中的坏字符表,其构建过程有如下几点需要关注
- 我们对模式集合中所有模式的前m个字符构建SHIFT表,其中的m,是模式集合中最短模式的长度值。
- 对于字符块的长度B的选择,我们一般选择2,3个字节。
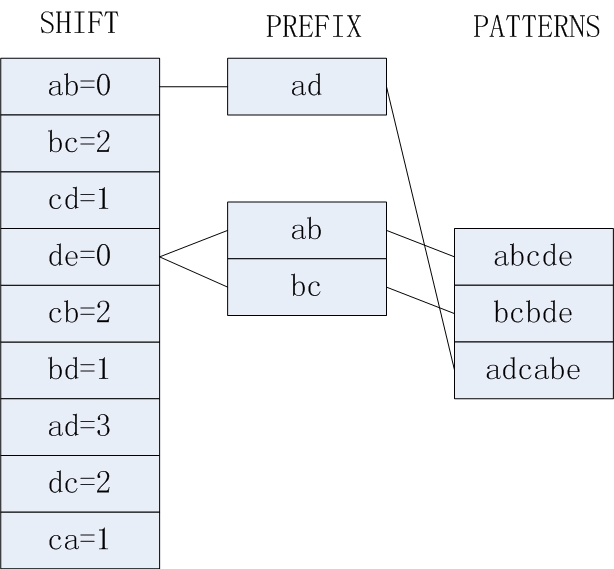
- 在构建SHIFT表的时候,对一个模式p的前m个字符,我们要处理其所有长度为B的子串,并填充对应的SHIFT值,假设字符块大小为B,当前字符快的尾字符与模式前缀的末尾距离为n,则SHIFT[p]=n。以模式abcdefgh为例,假设要处理其前6个字符构成的子串,那么SHIFT[ab]=4,SHIFT[bc]=3,SHIFT[cd]=2,SHIFT[de]=1,SHIFT[ef]=0都要加入SHIFT表中。
- 如果多个模式串前缀,或者同一模式前缀中,有相同的字符块,则保留其中SHIFT值的最小者。比如模式串p1 = abcab,p2=dcabe,其中对于块ab可以计算出三个SHIFT值3,1,0,这里我们需要保留SHIFT[ab]=0。
HASH表就是对应字符块B,所有SHIFT[B]=0的模式与B的映射关系。比如模式串abcde,bcbde,对于块de,他们的SHIFT值都是0,所以他们都由de索引。
实际上,在WM算法中,是可以没有PREFIX表的,但是对于字母文字来说,可能存在多个模式由一个字符块共同索引的情况,如上例,如果存在10个最末两个字符为de的模式串的话,那么在目标串中检索出de组合之后,要用当前的子串逐个尝试匹配这10个模式串,对于算法效率影响很大。所以WM算法同时截取了模式串的一个长度为2或者3的前缀,构建PREFIX表。在执行中缀查找的基础之上,再执行前缀查找,缩小备选模式集,提高匹配效率。如上例,abcde,bcbde,有共同的字符块de,使得SHIFT[de]=0,如果没有PREFIX表,就需要将游标向前移动5位,然后逐一尝试匹配这两个备选模式,如果有了PREFIX表,我们就可以用两个模式的前缀ab,bc再执行一次索引,一般情况下SHIFT值相同,PREFIX也相同的模式串比例很小,本例中二者的前缀是不同的,索引之后就只剩下一个备选模式,此时执行一次字符串比较即可判断当前位置是否发现了匹配模式。
下面用图来描述一下WM算法所要维护的数据结构:
WM算法执行模式匹配的流程如下。
对于目标串target,游标i,模式前缀长度m,字符快长度B,前缀长度C。我们取target[i-B+1...i],查找其在SHIFT表中的对应值SHIFT[target[i-B+1...i]],如果找不到,则i+=m-B+1,如果其值为c(c != 0),那么我们i+=c,再执行上述操作。如果其SHIFT值等于0,我们需要取出target[i-m+1...i-m+C],然后在SHIFT[de]=0对应PREFIX结合中查找PREFIX[target[i-m+1...i-m+C]],如果不存在,则将游标i+=1。如果存在则用target[i-m+1]开始的子串,依次匹配满足条件的所有模式串,直到找到匹配模式,或者未发现匹配位置。然后i+=1,继续向后查找。
下面以WM算法对目标串target[1...10]=dcbacabcde,模式结合P{abcde,bcbde,abcabe},的匹配过程来形象的说明一下。首先,对于模式集合P预处理之后的结果如上面的程序结构图所示。然后从i=5开始执行算法。首先我们发现target[4...5] = ac,SHIFT表中不存在ac,所以i+4,到target[9],此时发现target[8...9]=cd,SHIFT[cd]=1,所以i+1,然后发现target[9...10]=0,我们取target[6...7]=ab,发现PREFIX[ab]对应的模式串是abcde,然后我们从target[6]开始用目标串与模式串比较,发现匹配模式abcde。
后继:
既然WM算法也是堪称经典的多模式匹配算法,就不能回避与AC算法的比较。
- 从算法的效率角度讲,按照Wu Sun,Manber两人的论文所列的数据,WM算法的性能要明显优于AC算法。
- 从模式集预处理的角度讲,两者的预处理过程都很复杂,但是AC算法由于要维护一个状态机,所以在构建的时间和空间复杂度上,还是要比WM算法更消耗资源。而且AC算法既然要维护自动机,就不得不考虑用什么样的算法来实现自动机的问题,所以自动机的实现方式也会影响AC算法的效果,而WM算法需要考虑的问题就要简单多,一个给力的字典结构足矣。
- 从模式集角度讲,如果模式集动态可变,AC算法动态调整自动机的成本可能要比WM算法高很多。
- 从程序适应性的角度讲,AC算法对于任何模式结合,任何目标串都是O(n)的时间复杂度,而WM算法,对于某些模式集和目标串可能会发生退化现象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号