
模式匹配之路
之前我的文章中,介绍了KMP,BM,AC,WM等几个经典的模式匹配算法,本文我将对常用的模式匹配算法做一小结。
模式匹配算法的关系图如下所示:
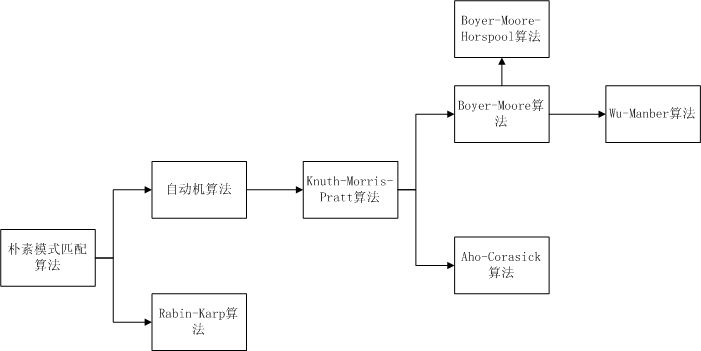
这里有几个我的文章中暂时没有涵盖的算法,这里做一简要说明。
Rabin-Karp算法,这是一个基于散列值的模式匹配算法,根据散列算法,将长度为m的模式串计算一个散列值,然后对于目标串中各长度为m的子串分别计算散列值,与模式串的散列结果相比较,只有散列值相同的,才会再执行与模式串的逐一字符比较。这个算法的适应性很强,如果选择比较优秀的散列算法,可以在近似O(n)的时间复杂度内完成匹配操作。但是美中不足的是,虽然散列计算的运算开销不是很大,但是对于字符串匹配这种每秒钟可能需要执行数万次的基本运算来说,散列计算可能就是比较大的负担了,其在实际应用中使用的不多,但是散列思想也是解决模式匹配的重要手段,WM算法就受到了该算法的启发。
自动机算法,我在《KMP算法详解》一文中,略微提到了一下,实际上KMP算法构造的next表,就一个简化的和输入字符集合不相关的自动机。自动机是解决模式匹配问题最经典,也最为有效的方法。KMP,BM,AC算法无一没有它的影子,但是自动机也有无法克服的缺点,就是构造模式串所对应的自动机的成本较高。在一般的单模式匹配场景中,构造模式串自动机的开销,很可能比用朴素的模式匹配算法执行一次对目标串的匹配还要高,这使得自动机算法的实用价值大大下降,不过正因为此,才促使人们去研究如何以较低的成本计算模式串的自动机,或者说叫做状态转移表,从而催生出像KMP这样的精妙算法的诞生。
Boyer-Moore-Horspool算法,是BM算法的一个简化版本,由于BM算法中的好后缀表计算成本不低,Horspool于1980年提出这个BM简化算法,抛弃了好后缀表跳转,只使用坏字符跳转规则.在最好情况下,也可以获得O(m/n)的时间复杂度(m是目标串长度,n是模式串长度),但是对于某些坏情况,时间复杂度仍可能为O(mn)。
这些算法共同构成了模式匹配的发展脉络,在实际应用中,更多的情况下并不是使用这其中的某一个典型算法,而是将多个算法的思想结合起来,进一步优化模式匹配的效率。以WM算法为例,其本身就借鉴了BM算法和RK算法的核心思想,如果在发现SHIFT为0的一组备选模式集合之后,再使用AC算法的自动机来执行对备选模式集合的匹配操作,则相较于WM两人论文中所用的逐一匹配方法,效率还会有提高。同样,对于AC算法,如果使用WM算法中的坏字符块跳转,将目标串中,模式集合不存在的字符序列跳过,也会大幅提升效率。总结起来,解决模式匹配无外乎坏字符,自动机,散列三种基本工具而已,只要这三种工具读者烂熟于胸,对于任何的模式匹配问题,解决方案只是信手拈来而已。
这些算法,都是前人的智慧结晶,对于我们来说,更多的时候是拿来主义,用用而已,但是对于那种并非课后作业题的应用场合,我们还是有必要去深刻了解他们的具体细节。没有对这些算法的深刻理解,我们就不会了解哪个算法用在那个场景更合适,如何仅作小小的修改就能解决性能问题。就单模式匹配而言,KMP作为最稳定的匹配算法当仁不让,但是对于绝大多数情况,朴素的模式匹配算法就足够了,特别是对于像中文这样前缀自包含很不常见的象形文字。而如果要追求绝对速度,则BM算法才是真正的王道,但是你需要考虑如何优化好后缀的计算开销。如果觉得好后缀的计算搞不定,又想有不错的速度表现,那么BMH算法也是可以参考的利器。在多模式应用场景,如果你对要处理的模式集合一无所知,那么你很难将WM应用于这样的场合,个别的畸形模式可能会让算法的效率大打折扣,还是乖乖的使用AC算法,但是实际上你也轻松不到哪里去,如何权衡AC算法的自动机开销,将是你无法回避的问题。而对于更多的情况,特别是中文词条处理,WM算法还是可以找到更广阔的应用天地的,只要你的手头有一个足够好用的字典库。所以更多的时候算法的应用没有最优只有权衡。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号