KMP学习笔记
时间复杂度:O(n+m)
定义一个nxt数组:

我们看一下 nxt 数组是如何降低字串匹配的复杂度的
比如我们现在有一原串 ABAABABABCA 而我们要把子串 ABABC 与其进行匹配
暴力做法是从 0 开始枚举子串首的位置 如下图:
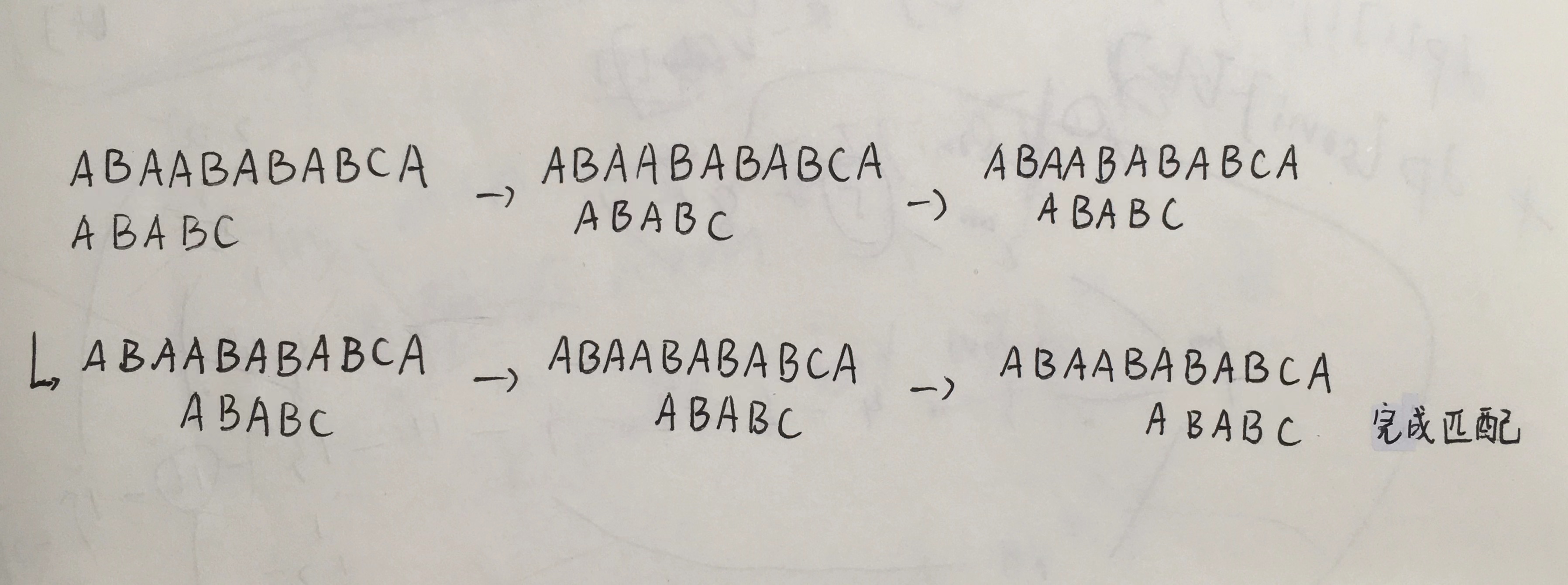
不难发现 此方法时间复杂度非常之高 为 O(mn)
那么 KMP 是如何匹配的呢
首先我们可以求出来这样的一个 nxt 数组(求法一会讲):
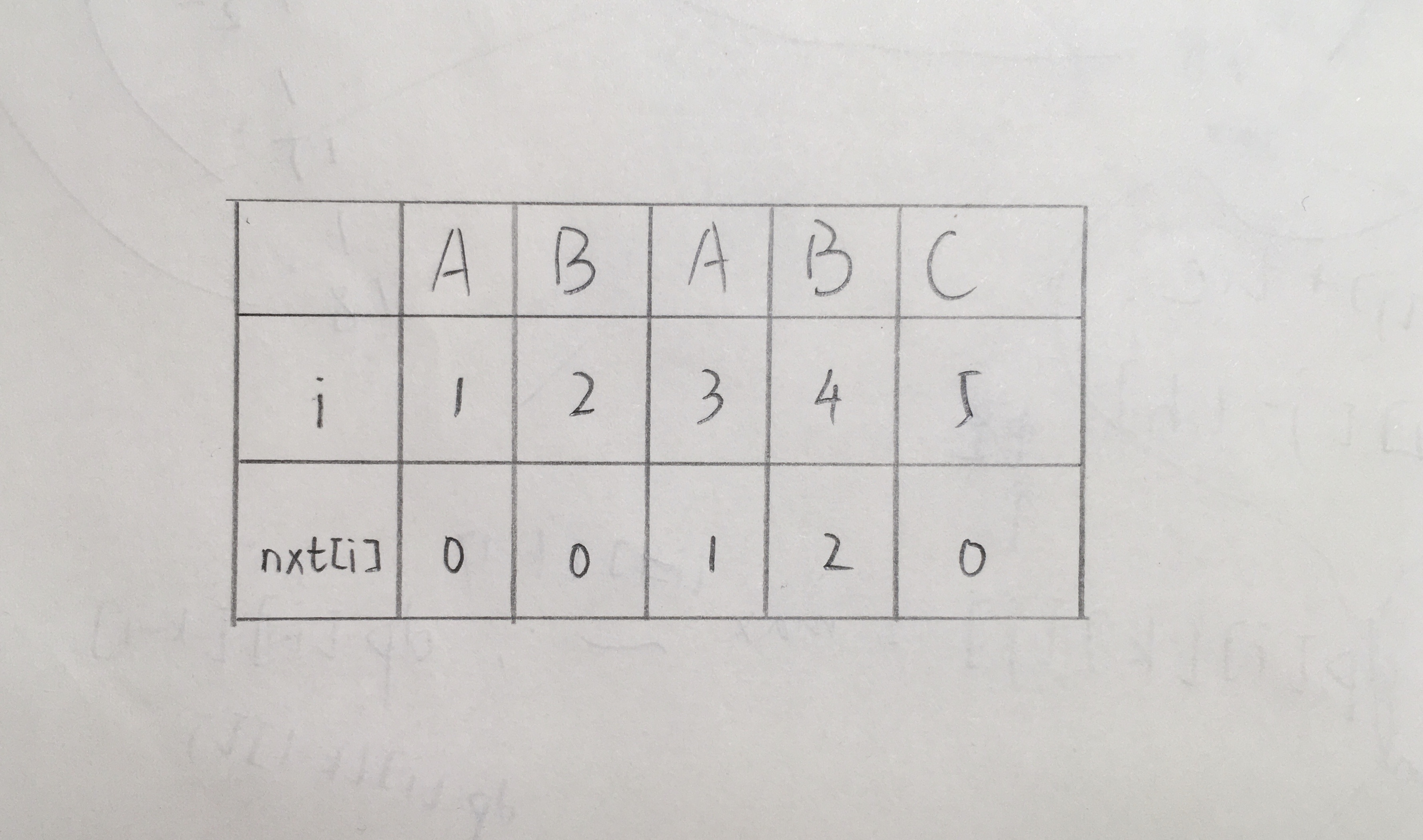
然后我们维护两个指针 i 和 j 分别记录在原串和子串中的位置
若当前位匹配成功 则 j 前移一位
失配时 查找 j 前一位的字符对应的 nxt 值 跳过前 nxt[j-1] 个字符的比较 具体过程如下图所示:
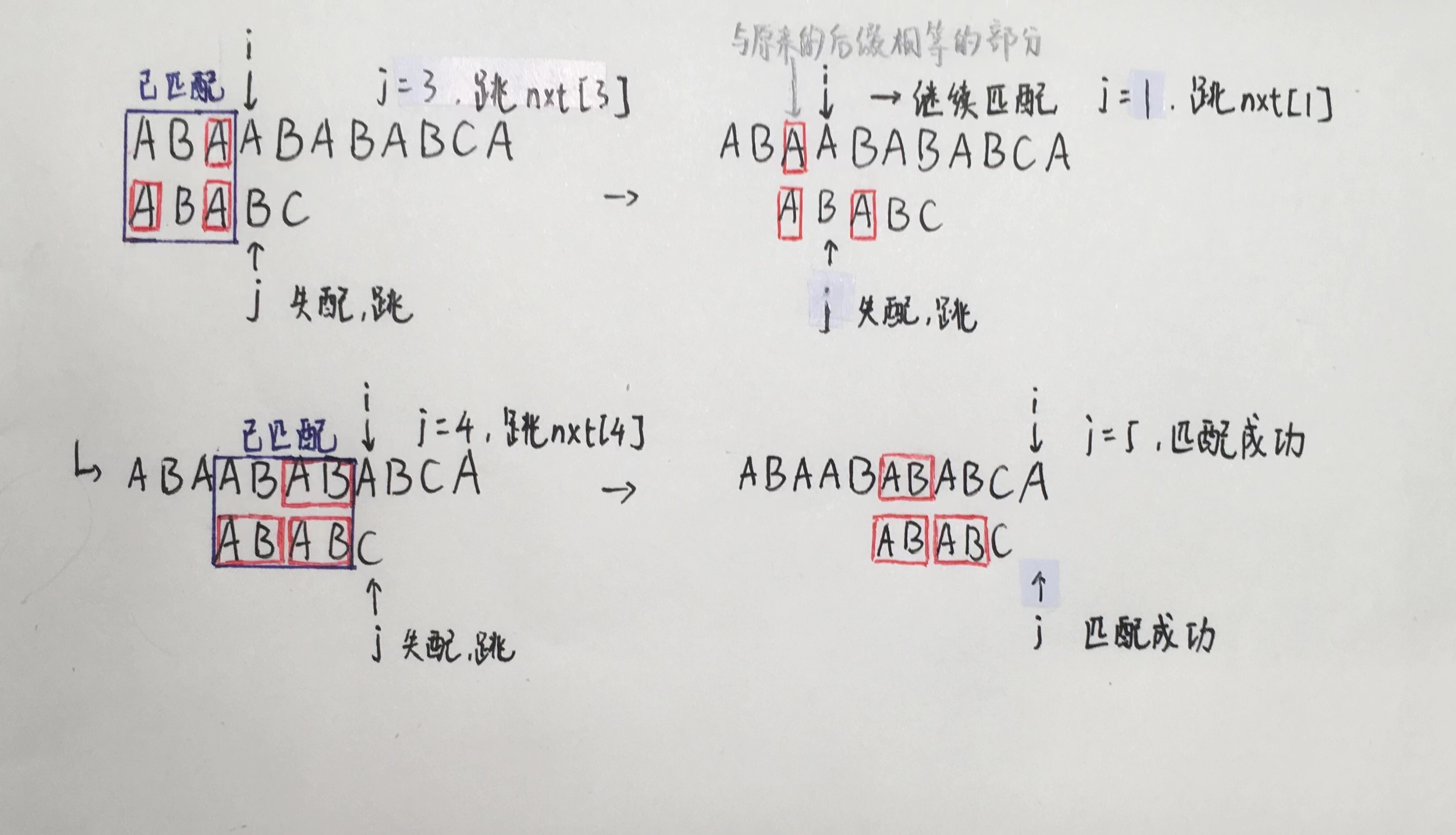
简要概括就是:匹配成功就可以把 j 前移一位 失配时让 j 不断跳 nxt
由于 i 是一直增加的 所以此过程变成了线性 大大降低了复杂度
具体代码如下:

现在我们来看 nxt 数组的求法 我们以 ABCABEEEABCABC 为例
可以看作是自己和自己匹配
还是定义两个指针 i j 表示当前串的末位和已经匹配好的前缀的末位
首先 nxt[0] nxt[1] 都必定为 0
我们考虑当新的一位加入 会对 nxt 数组产生的影响
1.若 s[i] 与 s[j] 相同 则 nxt[i] = nxt[i-1] + 1 :

2.若 s[i] 与 s[j] 不相同 与上文所述匹配时同理 不断跳 nxt 即可:

总体代码如下:

这里说下KMP的一些应用:
1.字符串配对(本职工作)P1470 [USACO2.3]最长前缀 Longest Prefix
2.循环节 周期:设该字符串长度为 len 则 len - nxt[len] 即为该子串的最小循环节 Om Nom and Necklace
3.fail树 P2375 [NOI2014] 动物园
2 + 3 :P3435 [POI2006] OKR-Periods of Words
4.border性质(这个暂时不会,可以看看这篇博客)
5.扩展KMP(同上)
Fail树
本来想单开一篇的 但是因为真的没啥新的就补在后面吧(
实际就是将 nxt[i] 作为 i 的父节点 那么 i 不断向上找父亲的过程就是跳 nxt 的过程
模板题:P5829 【模板】失配树
对于LCA不了解的戳这里
(顺便 对于这道题而言 由于 border 不能是为自身 所以若 x 或 y 就是它们的公共祖先 要返回其父亲)
代码如下:
求nxt:

lca:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号