2025.1.19 CW 模拟赛
T1
算法
动态规划, 树状数组.
思路
发现原问题其实就是一个二维偏序问题, 所以可以先按原串字典序排序消去一维的限制.
令 \(f_i\) 表示从 \(1 \sim i\) 钦定选第 \(i\) 个的最大答案, 那么有转移方程 \(\displaystyle f_i = \max_{j < i} f_j + 1\), 同时 \(j\) 需要满足 \(i, j\) 中只有一个含有 m, 并且 \(\displaystyle s^r_j < s^r_i\).
这样时间复杂度是 \(\mathcal{O}(n^2)\) 的. 但是我们可以观察到这个转移其实就是在求一个前缀最大值, 用两个树状数组分别维护即可.
void calculate() {
insert(s[1].m, s[1].rk, f[1] = 1);
for (int i = 2; i <= n; ++i)
insert(s[i].m, s[i].rk, f[i] = 1 + query(s[i].m ^ 1, s[i].rk - 1));
cout << *max_element(f + 1, f + n + 1) << '\n';
}
T2
数组意义给我绕死了.
算法
并查集, 拓扑排序.
思路
先抛一些定义:
- \(sa_i\) 表示排名为 \(i\) 的后缀在原序列上的位置.
- \(rk_i\) 表示第 \(i\) 个后缀的排名.
- \(height_i\) 表示相邻排名的两个后缀的最大公共前缀.
考虑其约束:
- \(\forall i \in (1, n], S[sa_i] \ge S[sa_{i - 1}]\). 根据定义便可知道, 更一般的, 如果 \(\displaystyle rk_{sa_{i - 1} + 1} > rk_{sa_i + 1}\), 那么 \(S[sa_{i - 1}] < S[sa_{i}]\).
- \(\forall i \in (1, n], j \in [0, height_i), S[sa_i + j] = S[sa_{i - 1} + j]\). 与此同时, 也约束了 若 \(i + height_i \le n\), 那么 \(S[sa_i + height_i] > S[sa_{i - 1} + height_i]\).
发现 \(sa\) 数组就是一个拓扑排序, 按照其处理即可.
首先, 按照上面两个约束, 先把确切的小于关系与等于关系记下来, 小于关系连一条边, 等于关系用并查集合并即可. 还是太困难了, 拼尽全力无法战胜.
T3
算法
拓扑序, 贪心.
思路
有点聪明.
如果 \(k = 0\), 我们用小根堆维护当前入度为 0 的点即可.
接下来考虑 \(k > 0\). 如果当前入度为 0 的点有多个, 贪心的, 我们一定不能直接输出最小的, 而是考虑向其进行连边, 这样就只能选更大的点了.
瓶颈在于我们我们无法知道哪一个点会向其连边, 这十分复杂.
聪明就聪明在我们可以先不考虑, 直接用一个大根堆维护那些需要被连边的点. 等什么时候需要输出他的时候将上一个输出的数向其连边即可.
priority_queue<int> p;
priority_queue<int, vector<int>, greater<int>> q;
void calculate() {
for (int i = 1; i <= n; ++i)
if (!rd[i]) q.push(i);
for (int x, y; !q.empty() or !p.empty();) {
while (!q.empty() and k) {
x = q.top(), y = p.empty() ? 0 : p.top();
if (x > y and q.size() == 1) break;
q.pop(), p.push(x), --k;
}
if (!q.empty()) x = q.top(), q.pop();
else x = p.top(), p.pop();
print(x, ' ');
for (int v : e[x])
if (!(--rd[v])) q.push(v);
}
}
T4
算法
并查集.
思路
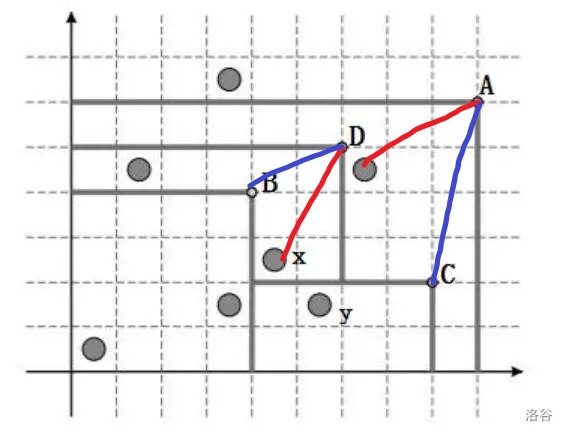
每个栅栏先计算被本身包含的点. 举个例子, 被 A 包含的只有一个点, 被 D 包含的有两个, 被 C 包含的有一个.
根据题目 (图片), 栅栏之间可能存在包含关系, D, C 均被 A 给包含, 所以计算 A 的答案, 等价于计算只被这三部分包含的答案之和. 同时, 这种包含关系形成了树的结构.
但这样就会出现问题, 栅栏有时间先后关系, 可能 B 先存在, D 后存在, 所以 B 的答案不会加在 D 的答案上. 对于这种情况, 我们可以归结为儿子发生时间靠后才会影响到父亲, 所以应该按照时间节点从后往前处理, 使用并查集.
至于如何计算「每个栅栏被本身包含的点」, 我们可以套路地先按照纵坐标降序排序. 从上往下扫, 每一个点所属的栅栏即为其右上第一个点的标号 (图中红线). 具体的, 我们用一个 set 存储当前存在的横坐标, 以便 \(\mathcal{O}(\log n)\) 地找到第一个大于等于其横坐标的栅栏 X, 然后令 \(cnt_X\) 加一. 模拟一下可以发现, y 点的归属判断有误, 这是因为 C 栅栏发生时间比 D 栅栏更加靠前, 所以在处理时现将 C 插入, 并且将 set 中横坐标小于 C 且发生时间大于其的 \(\rm{erase}\) 掉即可.
建立树形关系如法炮制即可 (图中蓝线).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号