
依赖注入 - 看这篇就够了
引言
本文是依赖注入技术的入门文章,基于 .NET 平台使用 C# 语言讲解。
如果对 C# 语言的基本特性和语法比较熟悉,那么理解起来会更加容易一些,其中包括,但不仅限于, C# 中的类,函数,接口。
如果对 C# 语言没有任何基础,但是了解其他面向对象的语言,那么应该也不妨碍你读懂这篇文章。
之前接触的一些框架和源码里有用到依赖注入容器,但当时我不知道依赖注入容器怎么用,更加不知道依赖注入技术是什么。我不清楚其他人第一次看到依赖注入容器的代码是什么感觉,至少我起初看到这些代码,是比较困惑的,因为没法连贯起代码的逻辑性,必要时,只能自己摸索着做些修改,然后运行程序看看结果。直到研究了依赖注入的思想和原理,才算搞明白其中的原委。
声明
本文有部分内容,包括文字(原文为英文),代码,和图片,来自 Pluralsight 在线学习门户,主要目的是对阶段性学习做个总结分享,非用于商业用途,侵删。
什么是依赖注入
越来越多的框架植入了依赖注入容器。那么什么是依赖注入容器?要解答这个问题,我们得先了解什么是依赖注入。因为许多功能都隐藏在依赖注入容器背后,只学会依赖注入容器的使用而不了解依赖注入技术本身的原理,显然是管中窥豹可见一斑。
那么什么是依赖注入,依赖注入技术在我们的应用程序代码中起到了什么作用?这个问题每个人理解不同,自然有很多不同的答案,但基本大同小异。这里翻译了其中一种解释(原文可以参考 Mark Seemann 的书籍 Dependency Injection in .NET)。
让我们一起来看。
依赖注入,也就是 DI,英文 dependency injection 的缩写,是一系列用于开发解耦合代码的软件设计原则和模式。
这个定义不仅解释了什么是依赖注入:软件设计原则和模式。同时也告诉了我们依赖注入的作用:开发解耦合的代码。
所以,依赖注入是设计模式范畴的技术,和其他我们接触过的设计模式一样,主要是用于降低应用程序代码的耦合度。
那么又有问题来了,为什么我们关心耦合度,或者说,为什么我们追求解耦合的代码?有以下几点原因:
- 解耦合的代码更加易于扩展。我们能够在不改变大量对象的情况下增加功能。
- 我们能够将功能独立开来,以便编写简短的,易于阅读的单元测试。
- 我们也获得了易于维护的代码。当程序出错的时候,我们能够更加容易发现我们需要修改哪部分内容。
- 我们在团队协作开发的过程中,比如提交合并代码,通常不希望也应该避免团队成员之间的代码存在冲突,而解耦合有利于团队成员各自维护自己的代码片段而互相不受影响。
- 解耦合可以使延迟绑定变得更加容易。延迟绑定,或者运行时绑定,是我们在运行时做决定而不是编译时,这在特定场合下很有用。
这么说可能不够直观,没关系,我们只要知道解耦合能够给我们带来不少好处,至于具体如何体现的,我们后面会慢慢讲。
我们首先会看下紧耦合代码带来的一些问题,然后演示如何通过依赖注入来解耦合代码,以便于进一步的扩展和测试。最后还会介绍如何将 Ninject 容器应用到我们的程序中。
另外,当我们演示代码时,还会涉及 SOLID 原则相关的部分内容。SOLID 原则包括了个五个编码设计原则,它能够帮助我们设计出更易维护的代码。但本文的主题是依赖注入,对 SOLID 原则的部分内容只简单带过,如果想深入了解和学习,可以自行搜索相关资料。
依赖注入的实现方式有很多种,为了缩短篇幅,我将只挑选其中最常用的模式来讲解,构造函数注入。但是要知道,如果实际的应用场景不太一样,还有其他的一些模式可以选择。
示例程序
由于设计模式的部分概念过于抽象,单纯用文字想解释清楚也比较困难。所以,这里准备了一个应用程序,后面的内容都将围绕这个应用程序进行讲解,这个程序看起来很简单,实际又有些复杂。

说它简单是因为这个程序只有一个窗口。它从 Web 服务读取数据,然后显示在列表中,这就完了。通常我们不会在这么小规模的应用中使用依赖注入。因为它并不值得,为了代码的解耦而增加了程序的复杂性。
但是如果给你们展示一个真实的应用,又容易迷失在应用程序架构,模块交互,业务处理,以及其他许多方面的事情。
因此,我们将使用一个单窗体的应用以便于我们能够将注意力放在依赖注入的概念上。
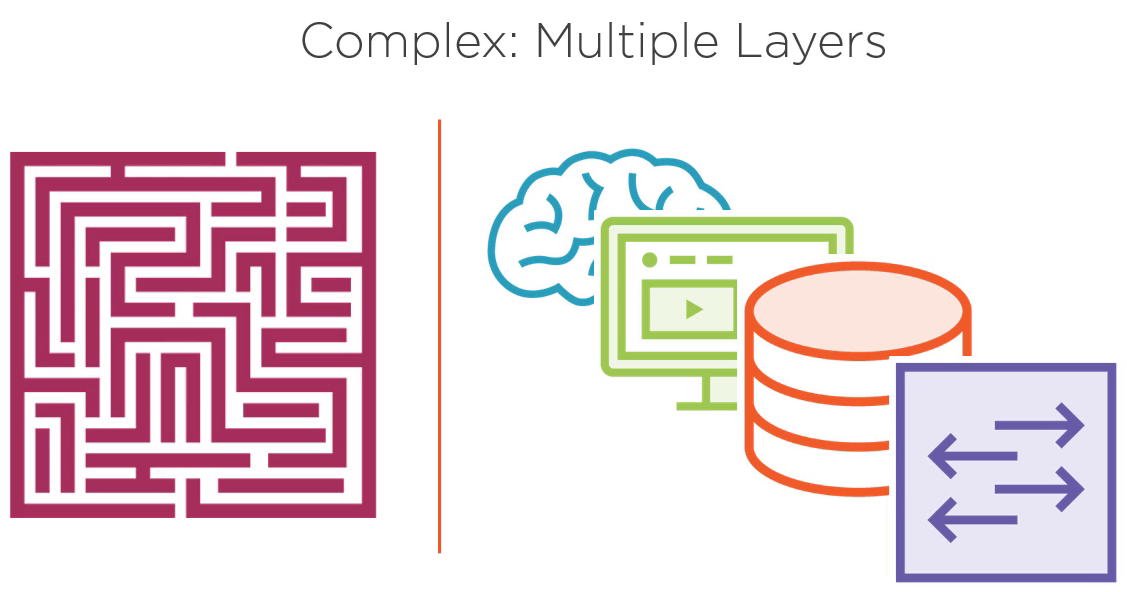
说它复杂是因为这个单窗体的应用被分割成了多个层级。通常,我们不会对一个单窗体应用这么分层。但是,这同样有助于我们关注依赖注入本身,以及我们将看到依赖注入是如何帮助我们在大型应用中解决问题的。
这个应用程序分为四层:
- 视图层,应用的界面。它由用户界面,控件比如按钮,列表等组成。
- 表现层,处理 UI 的逻辑部分。它包含了按钮事件调用的函数,UI 界面列表绑定的存储数据的对象。
- 数据访问层,负责与数据仓库的交互代码。示例的开始,我们从 Web 服务获取数据。数据访问层知道如何发起一个 Web 服务调用,然后将数据存储到对象中,以便应用的其他模块可以方便的使用。
- 数据仓库,获取实际数据的地方。
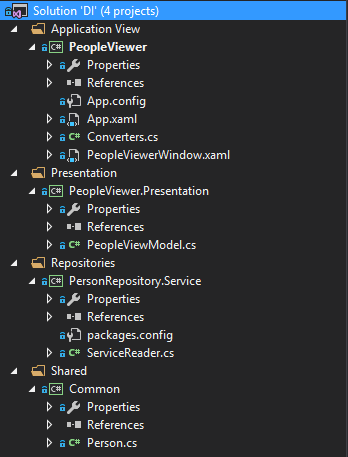
整个应用程序的代码结构可以参考下图:
下面贴上主要部分的代码:
PeopleViewerWindow.xaml.cs
using PeopleViewer.Presentation; using System.Windows; namespace PeopleViewer { public partial class PeopleViewerWindow : Window { public PeopleViewerWindow() { InitializeComponent(); DataContext = new PeopleViewModel(); } } }
PeopleViewModel.cs
using Common; using PersonRepository.Service; using System; using System.Collections.Generic; using System.ComponentModel; using System.Windows.Input; namespace PeopleViewer.Presentation { public class PeopleViewModel : INotifyPropertyChanged { protected ServiceReader Repository; public PeopleViewModel() { Repository = new ServiceReader(); } private IEnumerable<Person> _people; public IEnumerable<Person> People { get { return _people; } set { if (_people == value) return; _people = value; RaisePropertyChanged("People"); } } private string _repositoryType = string.Empty; public string RepositoryType { get { return _repositoryType; } set { if (_repositoryType == value) return; _repositoryType = value; RaisePropertyChanged("RepositoryType"); } } #region RefreshCommand Standard Stuff private RefreshCommand _refreshPeopleCommand = new RefreshCommand(); public RefreshCommand RefreshPeopleCommand { get { if (_refreshPeopleCommand.ViewModel == null) _refreshPeopleCommand.ViewModel = this; return _refreshPeopleCommand; } } public class RefreshCommand : ICommand { public PeopleViewModel ViewModel { get; set; } public event EventHandler CanExecuteChanged; public bool CanExecute(object parameter) { return true; } #endregion RefreshCommand Standard Stuff public void Execute(object parameter) { ViewModel.People = ViewModel.Repository.GetPeople(); ViewModel.RepositoryType = ViewModel.Repository.ToString(); } } #region ClearCommand Standard Stuff private ClearCommand _clearPeopleCommand = new ClearCommand(); public ClearCommand ClearPeopleCommand { get { if (_clearPeopleCommand.ViewModel == null) _clearPeopleCommand.ViewModel = this; return _clearPeopleCommand; } } public class ClearCommand : ICommand { public PeopleViewModel ViewModel { get; set; } public event EventHandler CanExecuteChanged; public bool CanExecute(object parameter) { return true; } #endregion public void Execute(object parameter) { ViewModel.People = new List<Person>(); ViewModel.RepositoryType = string.Empty; } } #region INotifyPropertyChanged Members public event PropertyChangedEventHandler PropertyChanged; private void RaisePropertyChanged(string propertyName) { var handler = PropertyChanged; if (handler != null) handler(this, new PropertyChangedEventArgs(propertyName)); } #endregion } }
ServiceReader.cs
using Common; using Newtonsoft.Json; using System; using System.Collections.Generic; using System.Net; namespace PersonRepository.Service { public class ServiceReader { public IEnumerable<Person> GetPeople() { WebClient client = new WebClient(); var baseUrl = "http://localhost:5001/api/people/"; var result = client.DownloadString(baseUrl); return DeserializeObject(result); } private IEnumerable<Person> DeserializeObject(string result) { return JsonConvert.DeserializeObject<IEnumerable<Person>>(result); } public Person GetPerson(string lastName) { throw new NotImplementedException(); } } }
Person.cs
using System; namespace Common { public class Person { public string FirstName { get; set; } public string LastName { get; set; } public DateTime StartDate { get; set; } public int Rating { get; set; } } }
提供 Web 服务相关的代码没有放上来,因为不影响我们讲解的内容,我们只需要知道示例程序中访问的 Web API 的 Url,就像我们知道文件系统某个目录下有个 CSV 文件,能够给我们提供一些 Person 数据,这就够了。
什么是紧耦合
粗略一看,我们的应用程序代码似乎挺好的。代码有合理地分层,每个层级负责特定的任务。UI 相关的任务都在视图层,获取数据相关的任务都在数据访问层。
但是我们的应用程序还是存在着一个问题:紧耦合。
尽管每个代码层级负责不同的任务,但是每个层级还是干了一些不属于它职责范围的操作,这就导致了紧耦合。
让我们回到这个应用程序再看一下。
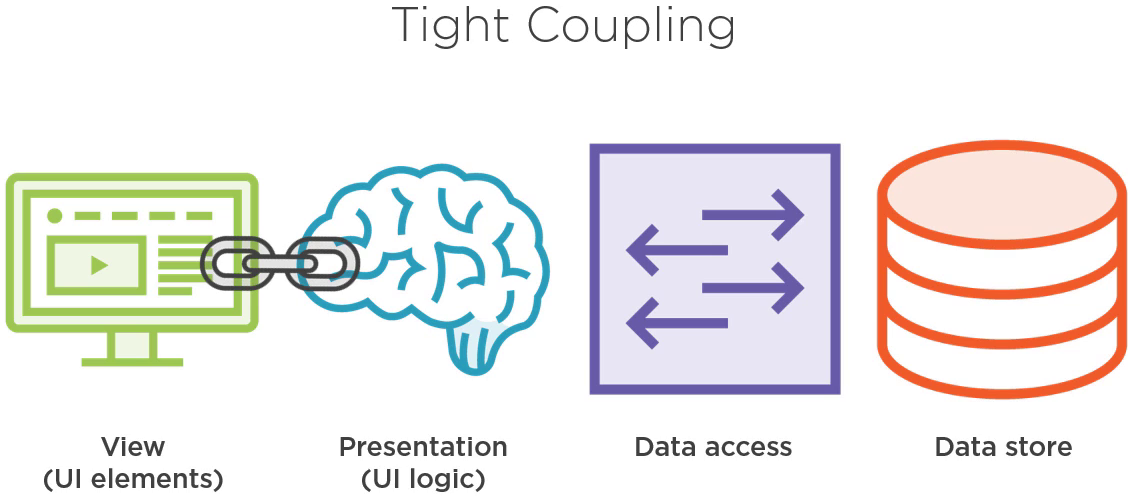
类 PeopleViewerWindow 在视图层,包含了 UI 控件。但是我们看下它的构造函数会发现,在视图层, PeopleViewerWindow 正在实例化一个 PeopleViewModel 对象。当我们在代码中实例化一个对象,耦合就产生了。
PeopleViewerWindow's Constructor
public partial class PeopleViewerWindow : Window { public PeopleViewerWindow() { InitializeComponent(); DataContext = new PeopleViewModel(); } }
首先,我们需要在编译时引用那个对象。如果我们不在编译时引用,毫无疑问,编译器没法成功编译我们的代码。另外,无论何时我们实例化一个对象,我们就得负责这个对象的生命周期。这样的结果就是,PeopleViewerWindow 和 PeopleViewModel 在表现层紧紧地耦合在了一起。
我们继续往下看,还会发现同样的问题。
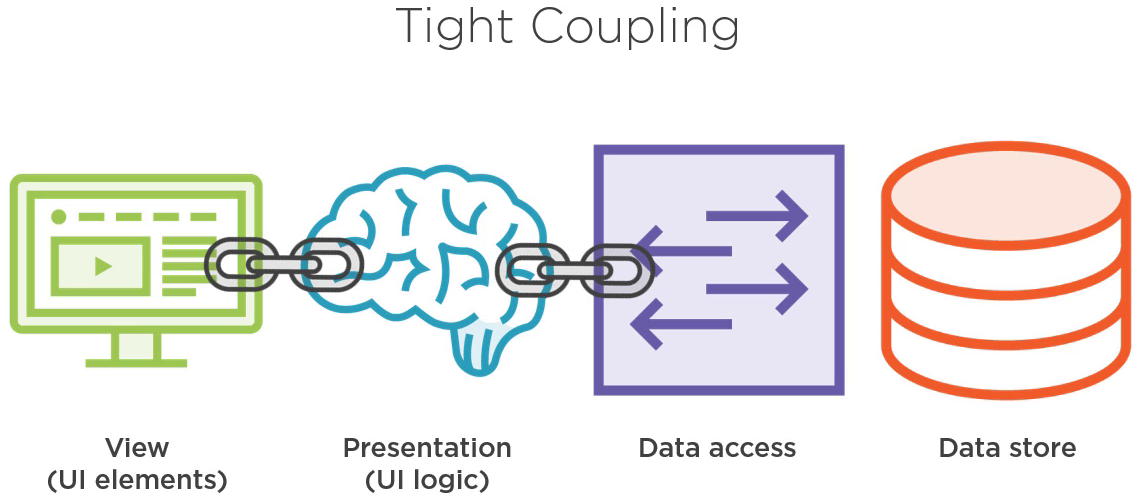
类 PeopleViewModel 负责表现层的逻辑。
在它的构造函数中,我们实例化了一个数据访问对象 ServiceReader。
PeopleViewModel's Constructor
public class PeopleViewModel : INotifyPropertyChanged { protected ServiceReader Repository; public PeopleViewModel() { Repository = new ServiceReader(); } ... }
正如我们刚刚提到的,我们对 ServiceReader 程序集产生了编译时的引用,我们就得负责这个对象的生命周期。
特别是,PeopleViewModel 在选择用什么技术来获取数据。通过实例化出 ServiceReader,PeopleViewModel 决定了数据来自 Web 服务。这样的结果就是位于表现层的 PeopleViewModel 和位于数据访问层的 ServiceReader 紧紧地耦合了。
更糟糕地是,在类 ServiceReader 的方法 GetPeople 中,它实例化了一个 WebClient 对象,来获取实际的 Web 服务。
ServiceReader's GetPeople
public class ServiceReader { public IEnumerable<Person> GetPeople() { WebClient client = new WebClient(); var baseUrl = "http://localhost:5001/api/people/"; var result = client.DownloadString(baseUrl); return DeserializeObject(result); } }
这意味着我们在编译时引用了 WebClient,我们就得负责这个对象的生命周期。当我们想要在应用中多个地方共享同一个 WebClient 时,这尤其会成为一个问题。结果就是数据访问层紧紧地耦合了数据源。
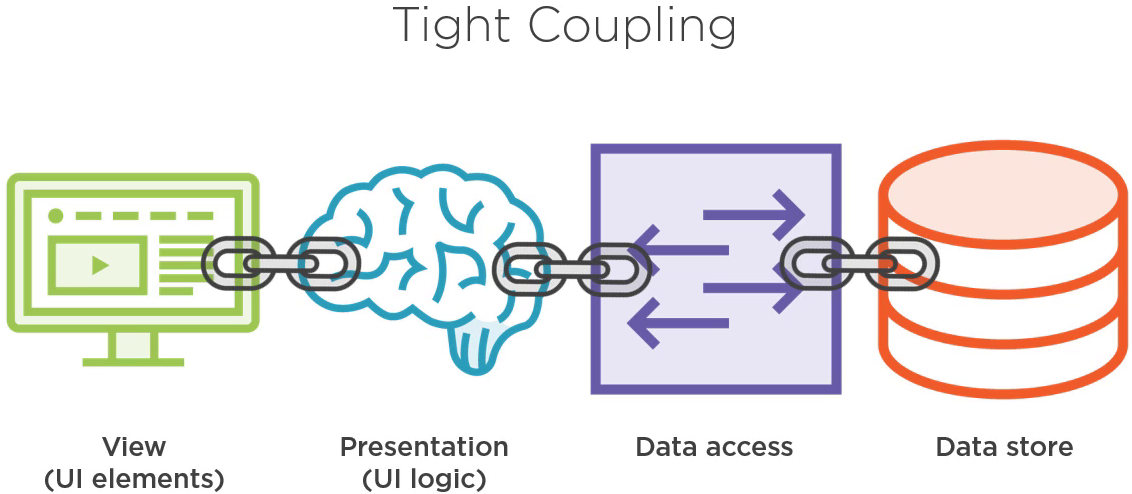
数据访问层通常需要知道数据源相关的一些信息,这里的耦合还不是那么严重。然而,这影响了应用程序整体的耦合度。因为视图层耦合着表现层,表现层耦合着数据访问层,数据访问层耦合着数据源,这意味着视图层耦合着数据源。

可能有人会问,对于这么简单的一个应用程序来说,代码耦合有关系吗?答案是有关系!因为我们的应用程序开发并没有结束,还会有新的需求,我们往下看。
紧耦合是如何影响我们的代码的
刚开始,当我们把这个应用演示给客户的时候,他们会说,emm,不错,这就是我们想要的功能:读取数据,并且按照我们的需求显示出来。

但是,这还不够。
首先,客户希望程序可以连接不同的数据源。应用程序从 Web 服务获取数据没有问题,但是并不是所有的客户端都使用 Web 服务。部分客户端使用逗号分隔的文本文件,比如 CSV,部分使用 SQL 数据库,部分使用文件数据库,他们还希望客户端能够支持云服务甚至 Azure 功能。
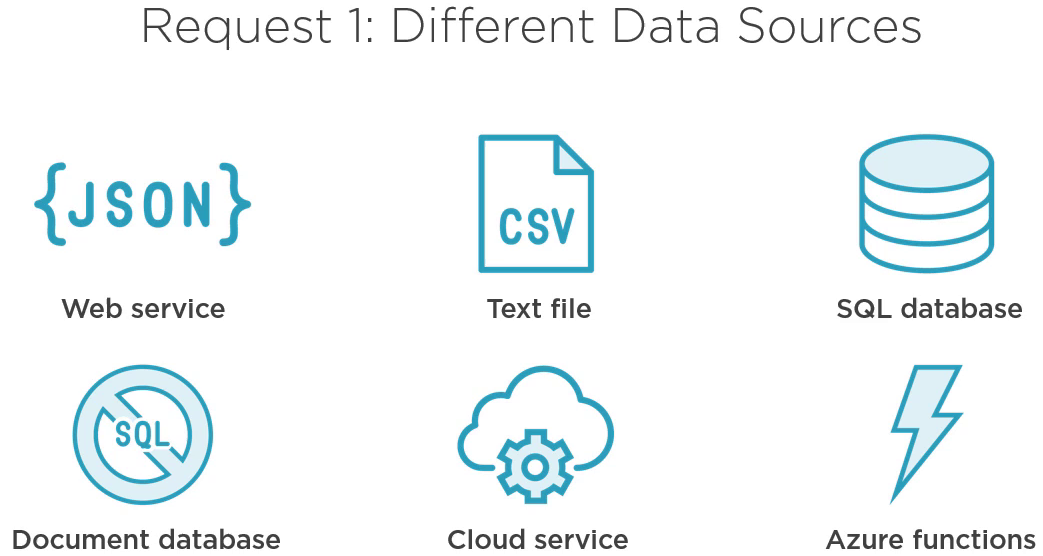
OK,我们想了一下,应该没什么问题。这表示我们需要在实例化 ServiceReader 的地方做一些修改。最懒惰的方法就是可以增加 switch 声明,PeopleViewModel 可以实例化 ServiceReader,CSVReader,SQLReader。

代码看起来比较挫,但是他能实现我们的功能,所以让我们接着往下看。
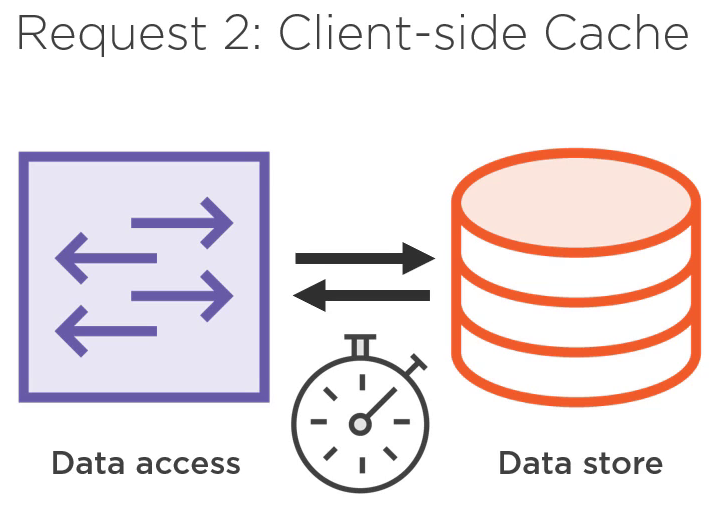
客户又有更多需求:在客户端要支持缓存。
在我们的应用中,数据访问层和数据源之间的通信通常花费了大部分的时间。因为我们通常通过网络发送信息,这受到网络延迟和带宽的限制。因为这个过程很耗时,所以支持客户端的缓存是很有必要的。所以我们需要一份数据的本地备份,从而不需要总是通过网络请求就可以重用数据。另外,客户还要求:缓存应当是可选的。
于是,我们继续扩展 switch 声明来支持带缓存或者不带缓存的各种 DataReader。

到这里,应该感觉到代码有些问题了,问题出在哪呢?我们来看。
问题在于,这部分代码违反了 SOLID 原则中的 S,也就是单一职责原则(Single Responsibility Principle)。
单一职责原则告诉我们,对象应当只有一个原因去作出变更。但是我们的 PeopleViewModel 有多个职责。主要的职责是表现层逻辑,但是它还负责为应用程序选择数据源,以及负责这些数据源的生命周期。现在,它还要决定我们是否使用缓存。毫无疑问,这肯定包含了太多的职责,这也是为什么代码会变得越来越难维护。
不仅如此,客户还要求有单元测试。
单元测试能够帮助我们节约很多编码时间。如果我们尝试为表现层的 PeopleViewModel 写单元测试,就需要实例化 PeopleViewModel 对象。但是在 PeopleViewModel 的构造函数中,我们实例化了 ServiceReader,而 ServiceReader 实例化了连接 Web 服务的 WebClient 对象。意味着测试想要正常工作,Web 服务就需要保持运行。

这显然是不现实的,我们需要应用程序有更好的独立性,以便测试更加可靠和可重复。我们可以在测试中使用反射来改变 ServiceReader,但是这么做的结果是测试代码变得复杂以及难以维护,而我们希望单元测试应该有简单可读的代码,这样我们才会更愿意去使用它们。
在我们继续之前,我们再整理下客户的需求:
- 使用不同的数据源
- 增加客户端缓存,并且是可选的
- 包含单元测试
上面说的方案显然是不可取的,那么我们怎么样才能避免产出紧耦合的代码呢?这就引出了本文的主题,我们继续往下看。
使用依赖注入解耦合应用
到这里,我们的主角终于可以上场了。

下面,我们就使用依赖注入进行代码解耦合。
首先,我们给代码添加一层抽象。然后,我们会使用依赖注入中的一种模式——构造函数注入,来创建解耦合的代码。
在之前我们设想的方案中,问题主要出在类 PeopleViewModel 上,也就是应用的表现层,尤其是类 PeopleViewModel 的构造函数,实例化类 ServiceReader 的地方。
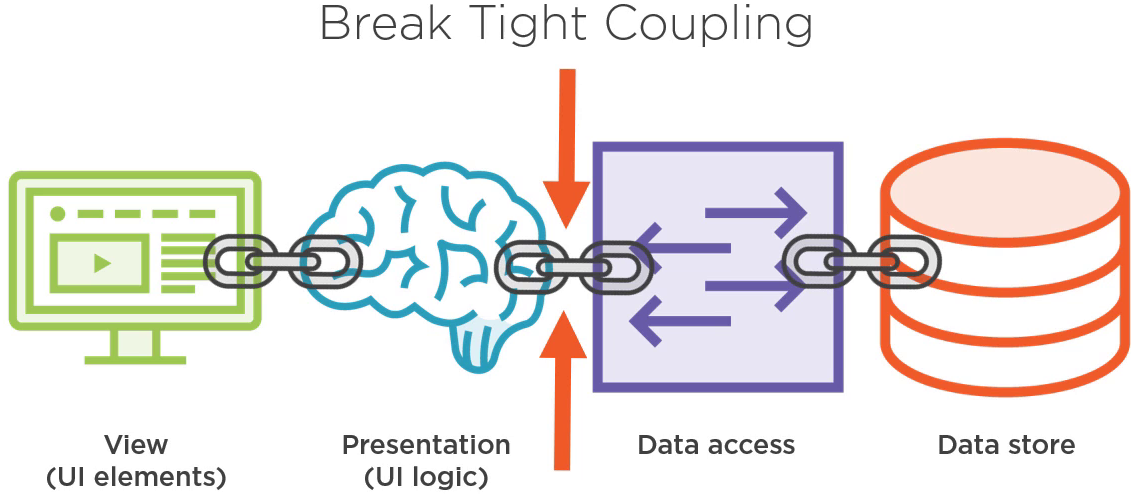
因此,我们将关注于类 PeopleViewModel 和 ServiceReader 的解耦。如果我们解耦成功,我们就能够更容易地满足用户的需求。
所以,总体来讲,解耦可以分为三步:
- 添加一个接口,一个抽象层,增加代码灵活性
- 在应用程序代码中加入构造函数注入
- 将解耦的各个模块组合到一起
首先第一步,我们需要思考下如何才能够让我们的应用程序连接不同的数据源。

这里直接引入 Repository 模式。
Repository 模式作为应用程序对象和数据获取模块的媒介,使用类似集合的接口来获取应用程序对象。它将应用程序从特定的数据存储技术分割了出来。
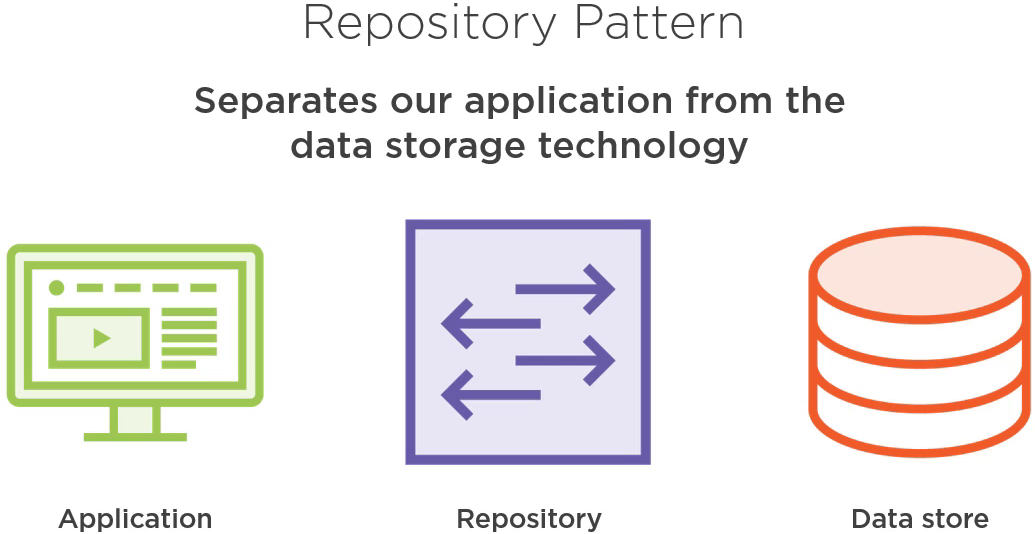
Repository 的思想是知道如何和数据源沟通,不管是 HTTP,文件系统上的文档,还是数据库访问。在获得这些数据之后,将其转换成应用程序其他模块可以使用的 C# 对象。
emm,这不就是 ServiceReader 现在干的事情嘛。它对 Web 服务发起了一个 HTTP 请求,然后将 JSON 格式的结果转换成应用程序可以理解的 People 类对象。但是问题在于表现层的 PeopleViewModel 与数据访问层的 ServiceReader 直接进行了交互。
为了我们的应用更加地灵活,我们给 Repository 加上接口,所有在表现层的通信都将通过这个接口实现。
这符合 SOLID 原则中的 D,也就是依赖倒置原则(Dependency Inversion Principle)。依赖倒置原则中的一点是,上层的模块不应该依赖于下层的模块,应该都依赖于接口。
有了抽象,表现层就可以很容易的与 CSV 或者 SQL Repository 通信了。
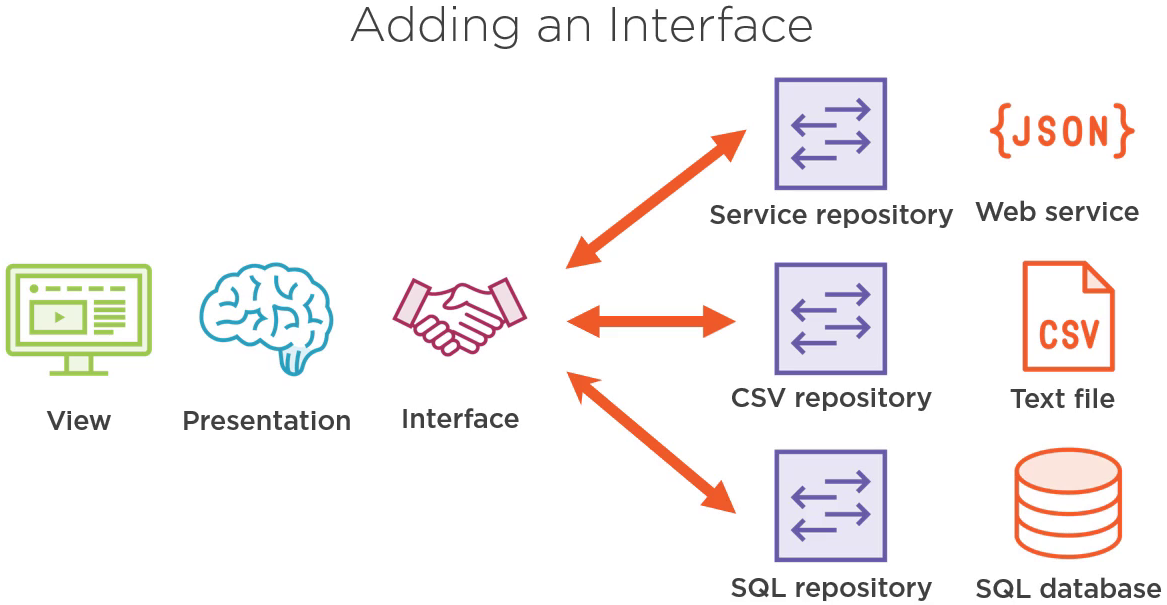
很多时候,我们使用的 Repository 是 CRUD Repository,CRUD 代表 create, read, update, 以及 delete。
然而,我们不需要所有这些操作。SOLID 原则中 I,也就是接口分离原则(Interface Segregation Principle)告诉我们,接口应该只包含需要的功能。
一个完整的 Repository 通常有读写的操作,但是我们的应用程序中,类 PeopleViewModel 只需要读操作。
因此为了符合接口分离原则,我们的接口应该也只支持读操作。
基于此,我们将创建一个数据读取接口,IPersonReader。接口包含了一个 GetPeople 函数,返回所有的 Person 对象,还有一个 GetPerson 方法检索单个人的信息。
IPersonReader
namespace Common { public interface IPersonReader { IEnumerable<Person> GetPeople(); Person GetPerson(string lastName); } }
让我们在代码里加上这个接口,以对 PeopleViewModel 和 ServiceReader 进行解耦。
类 ServiceReader 有两个方法 GetPeople 和 GetPerson。这也是我们在接口中需要的两个方法。
所以我们新建接口 IPersonReader,并且让 ServiceReader 继承它。
ServiceReader
namespace PersonRepository.Service { public class ServiceReader : IPersonReader { public IEnumerable<Person> GetPeople() { ... } public Person GetPerson(string lastName) { throw new NotImplementedException(); } ... } }
我们回到表现层的 PeopleViewModel,将成员变量 ServiceReader 改为 IPersonReader。这只是解耦的一小部分,我们需要的是避免在构造函数中实例化 ServiceReader。
所以,下面我们准备解耦表现层的 PeopleViewModel 和 数据访问层的 ServiceReader。
解耦的方式是,通过构造函数,注入 ServiceReader 到 PeopleViewModel, 注入 PeopleViewModel 到 PeopleViewerWindow,然后再将这些对象组合在一起。
我们来看下,在 PeopleViewModel 中的构造函数中,我们不希望实例化 ServiceReader。因为选取数据源不是 PeopleViewModel 的职责。
所以我们给构造函数添加一个参数,通过这个参数我们将 ServiceReader 对象传递给 PeopleViewModel 的成员变量 IPersonReader。
这个添加构造函数参数的简单操作,其实就实现了依赖注入。
PeopleViewModel
namespace PeopleViewer.Presentation { public class PeopleViewModel : INotifyPropertyChanged { protected IPersonReader DataReader; public PeopleViewModel(IPersonReader reader) { DataReader = reader; } ... } }
我们没有消除依赖,PeopleViewModel 仍然依赖于 IPersonReader,我们通过这个接口调用 GetPeople。
但是 PeopleViewModel 不再需要管理依赖对象,我们通过构造函数注入依赖,这就是为什么这个模式叫做构造函数注入。
这个时候如果我们编译程序会发现,PeopleViewerWindow 的代码出错了,因为它想要实例化一个无参的 PeopleViewModel 构造函数。我们可以在 PeopleViewerWindow 中实例化 ServiceReader,但是实例化 ServiceReader 不是 PeopleViewModel 的职责,所以更加不是 PeopleViewerWindow 的职责。
那么怎么解决呢?
我们把这个问题丢出去,不管谁创建了 PeopleViewModel,都应该负责创建一个 ServiceReader。所以我们仍然用构造函数将 PeopleViewModel 注入到 PeopleViewerWindow。
PeopleViewerWindow
namespace PeopleViewer { public partial class PeopleViewerWindow : Window { public PeopleViewerWindow(PeopleViewModel viewModel) { InitializeComponent(); DataContext = viewModel; } } }
有件事注意一下,这里我们没有给 PeopleViewModel 创建接口,通常我们只在需要的时候添加接口,因为接口增加了一层复杂性以及对代码进行了重定向。以我们一贯的经验来看,View 和 ViewModel 之间的关系大多是一对一或者多对一的,因此我们不介意在这有具体类的耦合。
如果我确实需要将多个 PeopleViewModel 绑定到同一个 PeopleViewerWindow,那么我会先添加一个接口。
接下来,我们需要将各个解耦合的模块组合起来,我们打开 App.xaml.cs 文件,在 OnSratup 方法中实例化 PeopleViewerWindow,由于 PeopleViewerWindow 的构造函数需要一个 PeopleViewModel 的对象,所以我们需要首先实例化 PeopleViewModel,而 PeopleViewModel 的构造函数需要一个 IPersonReader 类型的对象,所以我们还得先实例化一个 ServiceReader 对象并注入到 PeopleViewModel 的构造函数。
App.OnStartup
namespace PeopleViewer { /// <summary> /// Interaction logic for App.xaml /// </summary> public partial class App : Application { protected override void OnStartup(StartupEventArgs e) { base.OnStartup(e); ComposeObjects(); Application.Current.MainWindow.Show(); } private static void ComposeObjects() { var repository = new ServiceReader(); var viewModel = new PeopleViewModel(repository); Application.Current.MainWindow = new PeopleViewerWindow(viewModel); } } }
这里我们在做的就是把各个解耦的片段组合起来。运行程序后,和之前一样,从 web 服务读取的数据显示在界面上了。
我们看到,类 App 中的 OnStartup 扮演的是一个 Bootstrapper 的角色,负责启动应用程序,以及将不同模块的对象组合到一起。
现在 Bootstrapper 和 Viewer 在同一个工程,我们也可以把 Viewer 放到单独的一个工程,后面依赖注入容器的部分,我们会看到,我们可以使用不同的 Bootstrapper 来调用这个 Viewer 对象。
我们来回顾下这部分内容,我们对 PeopleViewModel 和 ServiceReader 通过构造函数注入进行解耦。

我们给构造函数增加了一个参数,同时增加了依赖注入,而不是在内部处理依赖。类 PeopleViewModel 依赖 IPersonReader,因为需要调用接口 IPersonReader 的 GetPeople 方法。
我们没有消除依赖,我们只是控制了怎么处理依赖,通过添加构造函数注入,我们把处理依赖的部分丢给了 Bootstrapper 模块,这就是依赖注入实现的方式。
PeopleViewModel 不再负责依赖对象的生命周期管理,而只是使用依赖对象。由此,我们解耦合了表现层的 PeopleViewModel 和数据访问层的 ServiceReader。这给了我们进一步开发的灵活性。
在上一节,我们看到了第一个版本的代码违反了 SOLID 原则中的 S,单一职责原则。

而更新的代码中,PeopleViewModel 不再通过实例化 ServiceReader 来选择数据源,不再负责 ServiceReader 的生命周期,也不再决定是否使用客户端缓存。

PeopleViewModel 现在只负责表现层的逻辑,提供 UI 能够调用的方法和绑定的数据,这就做到了职责单一。
解耦合代码解决的问题
在之前的内容中,我们花了不少时间在应用程序中加入依赖注入。我们通过构造函数注入依赖,然后在启动应用的 Bootstrapper 中将不同模块的对象组合起来。
现在代码已经解耦了,那么,这给我们带来了什么好处?
后面的内容,我们可以看到,通过替换程序中 ServiceReader,可以从不同的数据源获取数据,我们可以从文本文件中获取数据,也可以从数据库中获取数据。
我们还可以给程序增加一个客户端缓存,在应用程序的内存中保存数据,以避免我们每次请求都访问数据源。
我们可以很容易的给程序添加简洁的单元测试代码。
这也是我们之前看过的三个需求,并且我们也会看到代码的实现方式都遵循了 SOLID 原则。
我们先来看第一个需求,替换不同的数据源。
我们以读取 CSV 文件的数据为例子,要从 CSV 文件获取数据,我们将增加一个 CSV 文件的 DataReader, 然后把它加到程序里。
我们添加一个 PersonDataReader.CSV 工程,其中,类 CSVReader 有我们需要的功能。
CSVReader
namespace PersonRepository.CSV { public class CSVReader : IPersonReader { string _csvFilename; public CSVReader() { _csvFilename = AppDomain.CurrentDomain.BaseDirectory + "Resources\\People.csv"; } public IEnumerable<Person> GetPeople() { var people = new List<Person>(); if (File.Exists(_csvFilename)) { using (var sr = new StreamReader(_csvFilename)) { string line; while ((line = sr.ReadLine()) != null) { var elems = line.Split(','); var per = new Person() { FirstName = elems[0], LastName = elems[1], StartDate = DateTime.Parse(elems[2]), Rating = Int32.Parse(elems[3]) }; people.Add(per); } } } return people; } public Person GetPerson(string lastName) { Person selPerson = new Person(); if (File.Exists(_csvFilename)) { var sr = new StreamReader(_csvFilename); string line; while ((line = sr.ReadLine()) != null) { var elems = line.Split(','); if (elems[1].ToLower() == lastName.ToLower()) { selPerson.FirstName = elems[0]; selPerson.LastName = elems[1]; selPerson.StartDate = DateTime.Parse(elems[2]); selPerson.Rating = Int32.Parse(elems[3]); } } } return selPerson; } } }
首先,CSVReader 实现了 IPersonReader 接口,因此我们的 PeopleViewModel 能够像使用 ServiceReader 一样使用 CSVReader。
方法 GetPeople 使用 StreamReader 从文件系统加载文件,一旦数据返回,它就将数据解析到 Person 对象。
然后,我们需要重新组合应用程序模块,用 CSVReader 替换 ServiceReader。
所以我们重新回到 bootstrapper 工程的类 App,引用 PersonDataReader.CSV 工程。然后在 OnStartup 函数中实例化一个 CSVReader 来替代 ServiceReader,只有一行代码的改动,是不是很简单。
App.OnStartup
namespace PeopleViewer { /// <summary> /// Interaction logic for App.xaml /// </summary> public partial class App : Application { protected override void OnStartup(StartupEventArgs e) { base.OnStartup(e); ComposeObjects(); Application.Current.MainWindow.Show(); } private static void ComposeObjects() { var repository = new CSVReader(); var viewModel = new PeopleViewModel(repository); Application.Current.MainWindow = new MainWindow(viewModel); } } }
我们重新运行我们的应用,点击 Fetch People 按钮,我们从 CSV 文件获取到了数据。
我们看到,我们不需要修改程序中的 PeopleViewModel 类,不需要修改 PeopleViewerWindow 类,也不需要修改 ServiceReader 类,就替换了程序的数据源。

这符合 SOLID 原则中的 O,也就是开闭原则(Open-Closed Principle)。开闭原则要求我们现有的代码应当面向扩展开放,而面向修改封闭。
我们接着再来看第二个需求,增加客户端缓存。

我们可以在 CSVReader 或者 ServiceReader 中直接增加数据缓存的代码,但是现在我们的代码已经解耦合了,我们有更好的方式去实现这个功能,这里我们引入 Decorator 模式。
那么什么是 Decorator 模式? Decorator 模式是一种通过包装现有接口来增加功能的模式。
根据我们的需求翻译下就是,包装实现了接口 IPersonReader 的 ServiceReader 或者 CSVReader,来增加数据缓存功能。
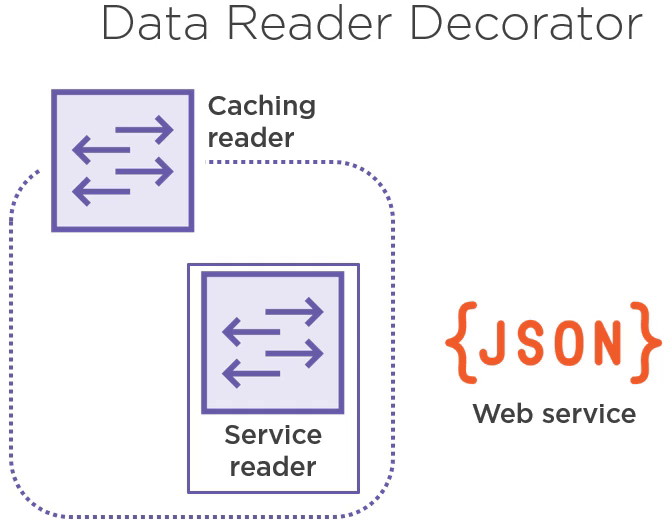
我们先导入 PersonRepository.Caching 工程,暂时先不管 CachingReader 的代码实现,我们先看看现有的代码需要做哪些修改。
我们以 ServiceReader 为例,ServiceReader 实现了 IPersonReader 接口。我们获取 ServiceReader, 并将它包装在一个 CachingReader 里。这样就增加了我们需要的数据缓存功能。
App.OnStartup
namespace PeopleViewer { /// <summary> /// Interaction logic for App.xaml /// </summary> public partial class App : Application { protected override void OnStartup(StartupEventArgs e) { base.OnStartup(e); ComposeObjects(); Application.Current.MainWindow.Show(); } private static void ComposeObjects() { var repository = new CSVReader(); var wrappedRepository = new CachingReader(repository); var viewModel = new PeopleViewModel(wrappedRepository); Application.Current.MainWindow = new MainWindow(viewModel); } } }
完了吗?完了!就这么简单。
我们重新运行下程序,确保 Web 服务运行,然后 Fetch People,得到了数据。我们再把 Web 服务关掉,清空数据,重新 Fetch People,依然能够获得数据,我们的缓存时间设置了15秒,所以我们等缓存时间到了,重新 Fetch People,数据没有了,如果我们重新启动 Web 服务,重新 Fetch People,会发现数据又恢复了。
现在让我们来看下 CachingReader 类的实现。
CachingReader
namespace PersonRepository.Caching { public class CachingReader : IPersonReader { private TimeSpan _cacheDuration = new TimeSpan(0, 0, 15); private DateTime _dataDateTime; private IPersonReader _wrappedRepository; private IEnumerable<Person> _cachedItems; public CachingReader(IPersonReader wrappedPersonRepository) { _wrappedRepository = wrappedPersonRepository; } public IEnumerable<Person> GetPeople() { ValidateCache(); return _cachedItems; } public Person GetPerson(string lastName) { ValidateCache(); return _cachedItems.FirstOrDefault(p => p.LastName == lastName); } private bool IsCacheValid { get { var _cacheAge = DateTime.Now - _dataDateTime; return _cacheAge < _cacheDuration; } } private void ValidateCache() { if (_cachedItems == null || !IsCacheValid) { try { _cachedItems = _wrappedRepository.GetPeople(); _dataDateTime = DateTime.Now; } catch { _cachedItems = new List<Person>() { new Person(){ FirstName="No Data Available", LastName = string.Empty, Rating = 0, StartDate = DateTime.Today}, }; } } } private void InvalidateCache() { _dataDateTime = DateTime.MinValue; } } }
CachingReader 同样是个 IPersonReader,所以对应用的其他部分来说,CachingReader 与 ServiceReader 或者 CSVReader 没有什么区别。

这符合 SOLID 原则中的 L,也就是李氏替换原则(Liskov Substitution Principle)。任何基类可以出现的地方,子类一定可以出现。
通过使用 Decorator 模式,我们能够包装任何一个现有的 DataReader。我们在 CachingReader 上同样使用构造函数,来注入真正的 DataReader。
我们有一个私有成员变量 _wrappedReader,和一个 IPersonReader 类型变量,这是我们想要包装并添加缓存功能的真正的 DataReader。
其他类成员用来控制缓存。TimeSpan 类型的 cacheDuration 对象用来判断缓存在内存中保留的时间,这里我们设置了15秒,但是我们可以通过配置文件来修改它。其他两个变量和缓存本身有关,cacheDuration 变量是一个 Person 类型的 IEnumerable 对象,这就是我们内存中的缓存,dataDateTime 变量包含了缓存更新的上一次时间,因此我们能够通过这个变量来判断我们的缓存是否有效或者过期。
如果我们看下 GetPeople 方法,会发现有两个处理步骤。
第一个是验证缓存。如果缓存过期或者没有缓存,它就会通过包装的 reader 来获取数据,并且保存到 cachedItems 中。如果缓存有效, 那么就直接使用缓存。这只是简单的客户端缓存实现方式。

我们也已经看到,通过 Decorator 模式增加缓存功能,只需要在 Bootstrapper 工程中简单地修改几行代码就能够实现,并且如果需要,我们也可以很容易地配置程序来启用或者禁用缓存功能。
依赖注入为单元测试带来了什么
我们都知道,单元测试是用于测试独立的功能模块的。这里我们就来看下,怎么为 PeopleViewModel 模块做单元测试。
首先,我们需要测试 RefreshPeople 方法。当这个方法被调用时,我们期望 PeopleViewModel 的 People 属性被赋值了。
类似的,我们需要测试 ClearPeople 方法。当这个方法被调用时,我们期望 PeopleViewModel 的 People 属性被清空了。
回到我们添加依赖注入之前,我们了解了对紧耦合的代码做单元测试带来的问题。

由于代码的耦合度很高,单元测试会依赖于实际的生产数据。
但是,现在我们的代码是解耦合的,我们不需要依赖于实际数据源。这里,我们创建了一个模拟的数据访问接口 FakeReader,并且在方法 GetPeople 中返回一些测试数据。
FakeReader
namespace PersonRepository.Fake { public class FakeReader : IPersonReader { public IEnumerable<Person> GetPeople() { return new List<Person>() { new Person() {FirstName = "John", LastName = "Smith", Rating = 7, StartDate = new DateTime(2000, 10, 1)}, new Person() {FirstName = "Mary", LastName = "Thomas", Rating = 9, StartDate = new DateTime(1971, 7, 23)}, }; } public Person GetPerson(string lastName) { throw new NotImplementedException(); } } }
然后我们看下测试代码。
UnitTest
namespace PeopleViewer.Presentation.Tests { [TestClass] public class PeopleViewModelTests { [TestMethod] public void People_OnRefreshCommand_IsPopulated() { // Arrange var repository = new FakeReader(); var vm = new PeopleViewModel(repository); // Act vm.RefreshPeopleCommand.Execute(null); // Assert Assert.IsNotNull(vm.People); Assert.AreEqual(2, vm.People.Count()); } [TestMethod] public void People_OnClearCommand_IsEmpty() { // Arrange var repository = new FakeReader(); var vm = new PeopleViewModel(repository); vm.RefreshPeopleCommand.Execute(null); Assert.AreEqual(2, vm.People.Count(), "Invalid Arrangement"); // Act vm.ClearPeopleCommand.Execute(null); // Assert Assert.AreEqual(0, vm.People.Count()); } } }
我们发现 FakeReader 也是完全独立的,并不影响实际的数据访问逻辑,我们可以通过 PeopleViewModel 的构造函数注入 FakeReader 对象进行单元测试。这就给了我们对测试代码,数据源的完全控制。
并且,测试的代码只有几行,而易于阅读和编写的测试是能够鼓励程序员去使用它们的。
依赖注入容器
到这里,我们已经基本了解了依赖注入的概念,并且在应用程序中通过依赖注入,我们解耦合了代码。我们也看到了依赖注入给我们带来的便利,包括但不仅限于易于扩展代码,易于单元测试。
在 .NET 的世界中,有很多流行的功能齐全的依赖注入容器,许多框架也都包含了依赖注入容器,比如 ASP.NET Core MVC。

我觉得依赖注入容器就像一个蒙面侠,为什么呢?
主要是因为当我刚接触依赖注入容器的代码时,就感觉像是隔着一层面具在观察陌生人,你想象不出他脸上遮住的部分,但是当我们看过了这个陌生人的脸后(了解了依赖注入的原理),即使他重新戴回面具,我们依然能够想起他的长相。
这就是为什么一开始我们避开了容器来讲解依赖注入。
我们以 NinJect 为例进行讲解。我们会看到如何在程序中配置容器,管理对象生命周期,以及从容器中获得对象。
我们可以通过包管理平台 NuGet 下载 NinJect 包,并在项目中引用。
这里,我们将 Bootstrappter 部分的代码和 PeopleViewerWindow 分开放在了单独的工程里,以便 PeopleViewerWindow 可以被多个版本的 Bootstrappter调用。以下是更新后的工程目录:
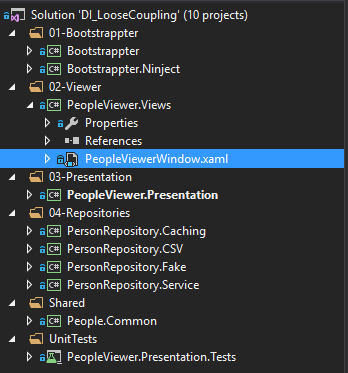
以下是涉及依赖注入容器的代码部分。
App.OnStartup with NinJect
namespace Bootstrappter.Ninject { public partial class App : Application { IKernel Container; bool IsCacheEnabled = false; protected override void OnStartup(StartupEventArgs e) { base.OnStartup(e); ConfigureContainer(); ComposeObjects(); Application.Current.MainWindow.Show(); } private void ConfigureContainer() { Container = new StandardKernel(); if (IsCacheEnabled) { Container.Bind<IPersonReader>().To<CachingReader>().InSingletonScope() .WithConstructorArgument<IPersonReader>(Container.Get<CSVReader>()); } else { Container.Bind<IPersonReader>().To<CSVReader>().InSingletonScope(); } } private void ComposeObjects() { Application.Current.MainWindow = Container.Get<PeopleViewerWindow>(); } } }
在了解依赖注入原理之前,看到这段代码可能是比较痛苦的。在现在的上下文环境里,我们或许能够猜测,这跟我们之前手动组合模块的代码实现的功能是基本一样的。但是,我们发现,这里面见不到类 PeopleViewModel 的影子,可我们很清楚,不说功能,单从编译的角度来讲,实例化类 PeopleViewModel 是必须的,因为 PeopleViewerWindow 的构造函数需要一个 PeopleViewModel 对象。那么就只有一种可能,就是依赖注入容器内部实例化了 PeopleViewModel 对象并且传递给了 PeopleViewerWindow 的构造函数。
所以,我们看到,容器具有自动注册功能,它会为对象搜索依赖并归类,并且能够根据依赖关系将对象串联起来。
这使得我们的配置代码降到了最少,同时,也给了我们很大的灵活性。
当然,这也降低了效率,因此应用程序的启动时间变长了。所以我们在使用容器的时候要考虑,是否需要牺牲程序运行的效率来简化代码。
容器另一个特性是生命周期管理,当我们在看紧耦合的代码时,我们发现如果一个对象实例化一个依赖,那么它就得负责这个对象的生命周期。有了依赖注入容器,容器会负责生命周期。我们能够告诉容器如何管理生命周期,比如使用单例还是每次调用都使用新的实例。
我们还看到,通过变量 IsCacheEnabled 控制着应用程序是否支持缓存功能。想要更加的灵活,我们可以选择从配置文件读取变量 IsCacheEnabled 的值。
总结
相信看到这部分内容的,已经对依赖注入以及依赖注入容器有了基本的了解。本文只是依赖注入的入门讲解,重点介绍了如何通过构造函数来注入依赖。
我们看到,紧耦合的应用程序带来了许多问题,而解耦合给我们的代码带来了许多益处。不仅如此,我们还看到了我们的应用程序是怎么遵守 SOLID 原则的,以及 Decorator 模式在程序中的应用。
最后,再次强调,依赖注入是帮助我们开发解耦合代码的一系列软件设计原则和模式。解耦合代码是其中的关键,也是本文的中心,而依赖注入只是其中的一种解耦合方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号