01.Spark(spark shell实现word count)
spark shell实现word count
scala>sc
[签名]
res0:org.apache.spark.sparkContext=org.apache.Spark.SparkContext@3331800f(对象hash码地址)
scala>sc. +tab键它能把所有方法补齐![sc方法]
![]()
加载一个文档计算单词的个数
RDD(Resilient Distributed dataset)弹性分布式数据集当于List
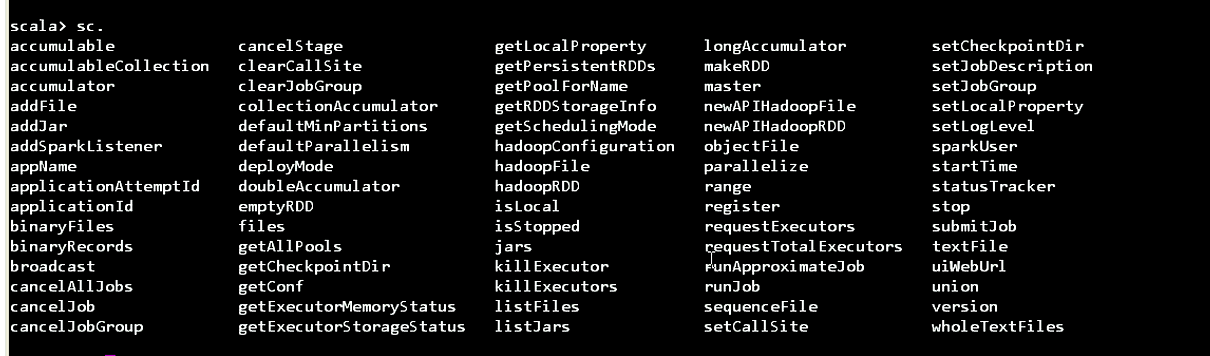
scala> sc.textFile
def textFile(path:String,minPartitions:Int):org.apache.spark.rdd.RDD[String]
scala>sc.textFile
RDD的方法
Spark中提供了八十多种高级算子,很大一部分在RDD上提供了这些算子。
scala> rdd1.foreach
[签名]
foreach foreachAsync foreachPartition foreachPartitionAsync
scala> rdd1.foreach
[签名]
// (f: String=>Unit)高阶函数
def foreach(f: String=>Unit):Unit//循环里面传了一个高阶函数,函数是一个。字符串作为参数,没有返回值
scala> rdd1.foreach(println(_))//把这个文件打印出来,此时rdd1相当于一个集合。那这个集合的每一个元素相当于每一行。
rdd在工作的时候,通过sc.textFole(...)去加载得到了rdd1.计算单词个数该如何
它每一个元素是一行,把一行的元素压扁.压扁是什么意思?如果不压扁会出现什么情况?
如果不压扁,那么这个集合就相当于嵌套的集合。每一个元素成数组了。把元素流出来放入外围的集合里面去。
第二步操作:做压扁操作,既然压扁。那么这个函数的返回值一定是可以迭代的量。不然就不能压扁。就因为它返回的是一个迭代的量是一种集合。它才把集合种的每一元素流到外面的集合里面去。这就是压扁。如果压扁成功了那么集合就,每个单词一行一行的了。压扁是rdd的方法。
scala> rdd1.collect //collect 收集,一收集它就变成了数组。每一个元素就变成了数组,每一个元素用逗号(,)隔开
[签名]
rest2:Array[String]=Array(helo world,helo world,helo world,helo world,helo world,helo world)
scala> rdd1.flatMap //压扁
[签名]
//(f:String=> TraversableOnce[U]这个也是一个高阶函数从字符串到TraversableOnce是可以进行一次迭代的意思
def flatMap[U](f:String=> TraversableOnce[U](implicit evidence$4:scla.reflect.CLassTag[U]):org.apache.spark.rdd.RDD[U])//implicit evidence$4:这个是隐式参数(柯里化)。flatMap是柯里化函数参数是隐式参数。只要传递第一个值就好了。
//如果要压扁每一行都要line,然后每一行切割split
scala> val rdd2= rdd1.flatMap(line=>{line.split(" ")})
[签名]
rdd2:org.apache.spark.rdd.RDD[String]=MapPartitionsRDD[2]at flatMap at <console>:26
scala> rdd.collect //收集一些
res3:Array[String]=Array(helo world,helo world,helo world,helo world,helo world,helo world)
然后分组,按单独分组在Spark中 标一成对。如果变成了两个元素的元组。那就是对偶。对于rdd2来讲,每一个元素就是一个单词。这样一来单词就成了单词就是key了。标一成对只要把同一个key的值累加起来就行 了。把每一个单词变成变成单词和1的对偶。
//rdd3
scala> val rdd3=rdd2.map(word=>{(word,1)}) //它是一个高阶,它是一个变换变成(word,1)
[签名]
rdd3:org.apache.spark.rdd.RDD[(String,Int)]=MapPartitionsRDD[3]at map at<console>:28
scala>rdd3.collect //再收集一些
[签名]
res4:Arry[String,Int]=Array((hello,1),(word1asdf,1),(hellod,1),(word13,1),(hello2,1),(word231,1),(hell2o,1),(word231,1),(hel234lo,1),(wor234d1,1))
scala> val rdd4=rdd3.reduceByKey
[签名]
//func:(Int,Int)一个高阶函数,两个整数到一个整数的变换,
def reduceByKey(func:(Int,Int)=>Int):org.apache.spark.rdd.RDD[(String,Int)]
def reduceByKey(func:(Int,Int)=>Int,numPartitions:Int):org.apache.spark.rdd.RDD[(String,Int)]
def reduceByKey(partitioner:org.apache.spark.Partitioner,func:(Int,Int)=>Int):org.apache.spark.rdd.RDD[(String,Int)]
//val rdd4=rdd3.reduceByKey((a:Int,b:Int)=>{})这个是匿名函数
scala> val rdd4=rdd3.reduceByKey((a:Int,b:Int)=>{a+b})
scala> rdd4.collect //收集一下,Spark比scala方便多了,scala提供了ByKey的方法。直接按Key去聚合值实现了wordd count的操作。
下一步就打印了,collect 返回了一个数组
scala>rdd4.collect
[签名]
//可以传一个偏函数PartialFunction[(String,Int),implicit evidence$29:scala带了一个隐式参数,返回值:Array
def collect[U](f:PartialFunction[(String,Int),U])(implicit evidence$29:scala.reflect.ClassTag[U]):org.apache.spark.rdd.RDD[U]
def collect():Array[(String,Int)] //这些是方法链编程
//先加载文件,然后压扁下划线切割按空来切紧接着标一成对(参数只在右侧出现一次的就可以用_了map((_,1)))
scala>sc.textFile("fil e:///home/centos/1.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
[签名]
注意了:凡是ByKey的方法都是按照Key去聚合它的值。
-----------------------------------------------------------------
在SparkShell下实现了word count
可以用分组来实现
scala>rdd1.collect //是每一行的值
scala>rdd2.collect //压扁后的单词
scala>rdd3.collect //标一成对的单词 这里没有map都是List,所以这里的key是可以重复的。
scala>rdd3.groupByKey
[签名]
//返回值RDD每个元素变成了单词和整数值的迭代Iteerable[Int]),它把同一个key下面的所有整数值聚在了一起(n多个1)
def groupByKey(): org.apache.spark.rdd.RDD[(String,Iteerable[Int])]
def groupByKey(numPartitions:Int):org.apache.spark.rdd.RDD[(String,Iterable[Int])]
def groupByKey(partitioner:org.apache.spark.Partitioner):org.apache.spark.rdd.RDD[(String,Iterable[Int])]
scala>val rdd6=rdd3.groupByKey() //rdd6就变成了Iterable[Int]
[签名]
rdd6:org.apache.spark.rdd.RDD[(String,Iterable[Int])]=ShuffledRDD[10]at groupByKey at<console>:30
scala>rdd6.collect //rdd6收集,分完组在统计它的个数
[签名]
//rdd6现在是单词和数字的迭代集合的映射
res11:Array[(String,Iterable[Int])]=Array((world2,CompactBuffer(1)),(world2,CompactBuffer(1,1,1)),(world5,CompactBuffer(1)),(world2,CompactBuffer(1)),)
scala>rdd6.map //变换
map mapPartitions mapPartitionsWithIndex mapValues//mapValues这里是对V变换,key是单词,V就是迭代器其实就是数字。把这些数字加起来就行了。可以不用加因为每个数字都是1,如果元素的个数就是它的总和。
scala>rdd6.mapValues
[签名]
//terable[Int]它是可以迭代的量,从头terable[Int]到=>U(是一个泛型)的映射
def mapValues[U](f:Iterable[Int]=>U):org.apache.spark.rdd.RDD[(String,U)]
scala>rdd6.mapValues(_.size)
scala>val rdd7=rdd6.mapValues(_.size) //这里又变成了RDD[(String,Int)]字符串和整型值对偶
[签名]
rdd7:org.apache.spark.rdd.RDD[(String,Int)]=MapPartitionsRDD[12]at mapValues at<console>:32
scala> rdd7.collect //通过它去变换,分完组之后它把值聚在一起。然后再对值进行变换
res13:Array[(String,Int)]=Array((world2,1),(world4,1),(hello,1),(world2,1))
一年的最高气温
scala>
RDD1的方法
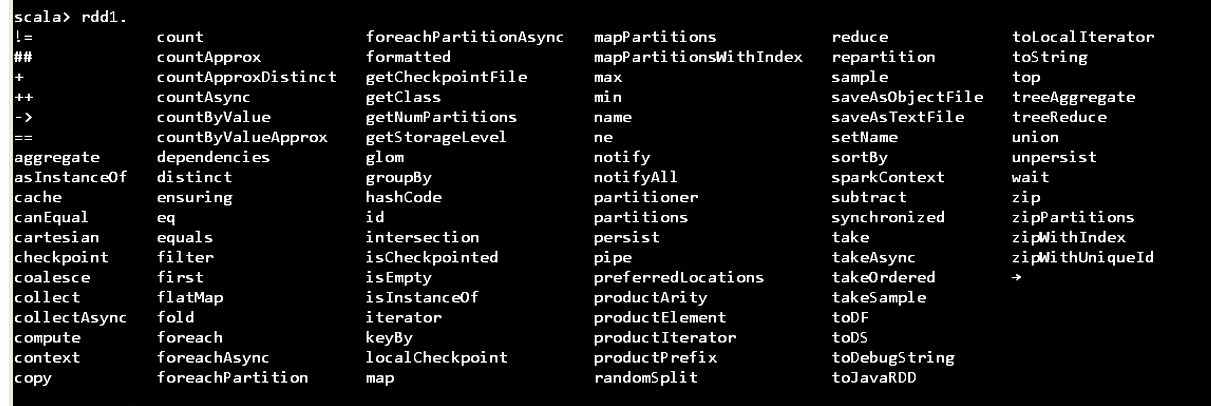
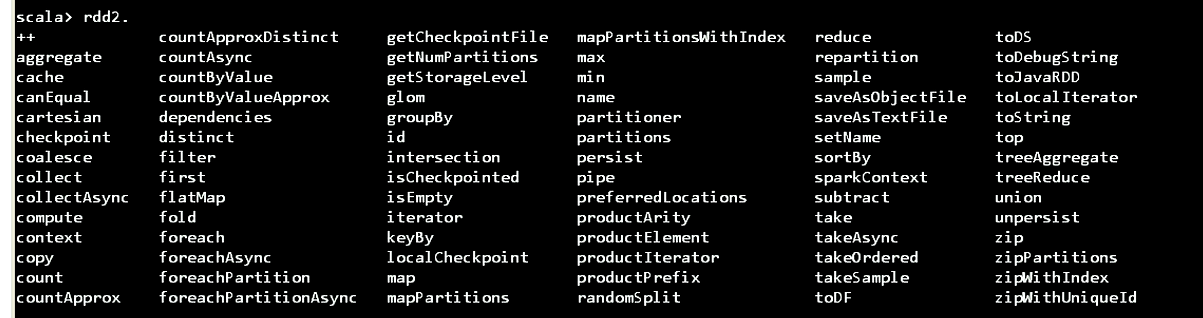
RDD2的方法
RDD3的方法,多被ByKey,reduce等一些方法,当你一旦变成key对的形式。rdd3就变成了Map.reduceByKey是按key来聚合。虽然很多bykey不是Map。如果是Map的话key就是唯一的,它就是唯一的。用scala来聚合,先得toList.就怕它相同的去重了。所以在Spark里面Map函数变成了一个二元元组的话。只要是二元元组的话,就提供各种ByKey的操作。但这个ByKey不是Map.reduceByKey是按照key来聚合它的值,严格来说是reduceVuluesByKey。reduceByKey是一个高阶,把两个值变成一个值。再去跟第三个值再聚合。reduceByKey将值累加除掉重复
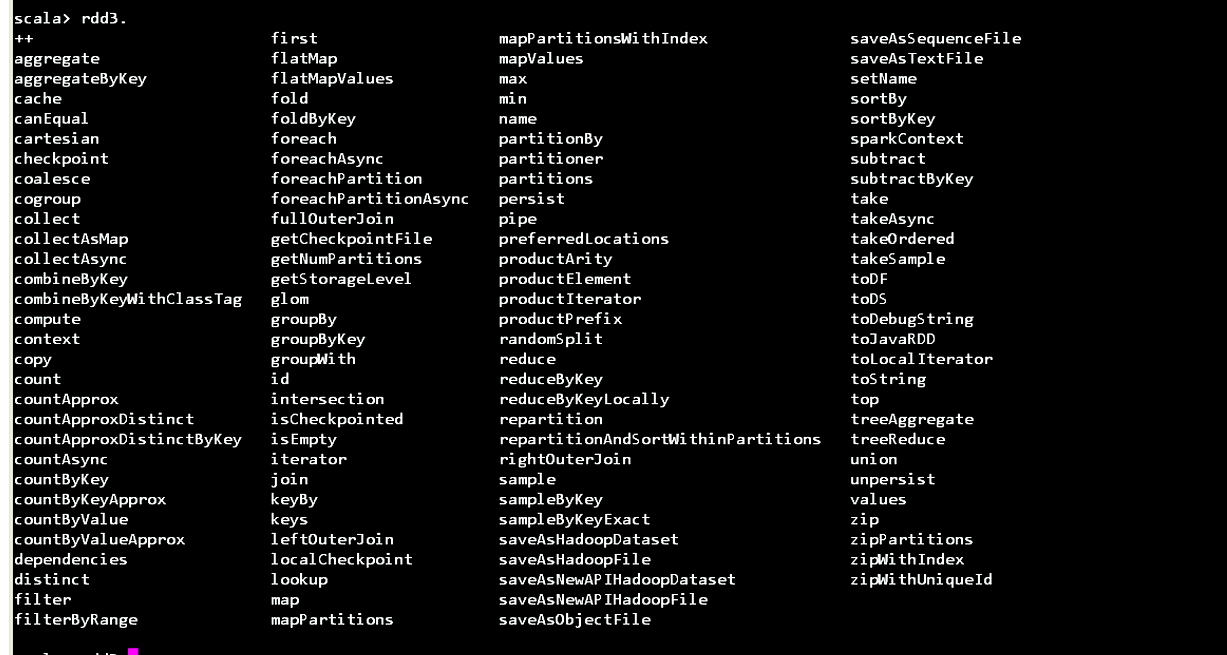
RDD4的方法
使用spark实现气温
[centos@s101 /home/centos]$cat temp.dat scala> val rdd1=sc.textFile("file:///home/centos/temp.dat") scala> rdd1.collect collect collect scala>rdd1.collect //rdd1一收集就变成了一行一行的数据 //压扁包含切割部分 scala>val rdd2=rdd1.flatMap(_.split(" ")) scala>rdd2.collect //这里不是压扁,压扁就是年度和气温值了分开了把它变成一个元组年度是key,气温是V //map的每一行都抓,先把它切开.切开以后变成了数组,变成数组之后返回的是一个元组(arr(0)就是年度arr(1)就是气温 scala> val rdd2=rdd1.map(line=>{var arr=line.split(" ");(arr(0),arr(1))}) scala>rdd2.collect //这样一来的话它就,气温和年度都成了字符串,应该把它变成数字(直接toOmt) scala>val rdd2=rdd1.map(line=>{var arr=line.split(" ");(arr(0).toInt,arr(1).toInt)}) scala>rdd2.collect //将气温和年度变成Int类型,现在它是二元元组的,就是一个对偶。就是一个map,变换。此时就可以调用reduceByKey scala>rdd2.reduceByKey //把两个整数聚成一个整数,找历年的最高气温。 // if() 取一个最大值。 scala>val rdd3=rdd2.reduceByKey((a,b)=>if(a>b) a else b) //还需要排序,按年度排序 scala>val rdd4=rdd3.sortBy sortBy sortByKey //按年度排序,年度就是Key scala>val rdd4=rdd3.sortByKey //ascending就是升序的意思numPartitions分区数 def sortByKey(ascending:Boolean,numPartitions:Int):org.apache.spark.rdd.RDD[(Int,Int)] scala> val rdd4=rdd3.sortByKey(true)//给它一个key按升序排序 scala>rdd4.collect //这样没有显示全 scala> rdd4.foreach(println) scala> val rdd4=rdd3.sortByKey(false).foreach(println) //按照气温高低来排序,就不能是sortByKey了。 scala> val rdd4=rdd3.sortBy scala>val rdd4=rdd3.sortBy //sortBy如何写 sortBy是泛型K,第一个参数是函数(从一个二元组组员到一个key的映射。并且这个key能比较大小(implicit ctag:scala.reflect.ClassTag[K]):柯里化函数)),第二个参数是升降序ascending:Boolean,第三个是分区numPartitions:Int,整个这个((Int,Int))=>K是一个函数,这个函数它有1个参数,这个参数的类型是二元组 def sortBy[K](f:((Int,Int))=>K,ascending:Boolean,numPartitions:Int)(implicit ord:Ordering[K],implicit ctag:scala.reflect.ClassTag[K]):org.apache.spache.spark.rdd.RDD[(Int,Int)] scala>val rdd4=rdd3.sortBy //((a,b)它是一个二元组,第二个组员是气温,它就是取出b。此刻是要降序ascending是升序 scala>val rdd4=rdd3.sortBy((a,b)=>b) scala>val rdd4=rdd3.sortyBy(t=>t._2,false) //按气温降序 false就是降序 scala>rdd4.collect scala>rdd.foreach(println) scala>val rdd4=rdd3.sortBy(t=>{- t_2},true)//让它取反后升序 scala>rdd4.collect //先收一下就变成了一个数组了,不collect一下它就没有做到一个集合。就不是分布式的了。 scala>rdd.foreach(println) 作业 1.聚合气温数据。聚合出max,min,avgscala>rdd1.collect //rdd1一收集就变成了一行一行的数据如下图

scala>rdd2.collect

scala>rdd2.collect //这样一来的话它就,气温和年度都成了字符串

scala>rdd2.collect //将气温和年度变成Int类型,现在它是二元元组的,就是一个对偶。就是一个map,变换。此时就可以调用reduceByKey

// if() 取一个最大值。

scala>val rdd3=rdd2.reduceByKey((a,b)=>if(a>b) a else b) 这里是按年度排序的,年度是key

scala>rdd4.collect

[Maven]
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> //这里指的是scala的版本。它依赖于那个 <artifactId>spark-core_2.11</artifactId> //这里是spark自己的版本 <version>2.1.0</version> </dependency> </dependencies> //再加一个单元测 <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> </dependency> </dependencies>
[Scala文件]
object WordCOuntScala{ def mian(args:Array[String]):Uint={ //创建spark配置对象 val conf=new SparkConf() //给名称//创建的时候先给它一个conf conf.setAppName("WCScala") //再给它一个Master conf.setMaster("local") //创建上下文,把conf交给上下文 val sc=new SparkContext() //此时需要参数 //加载文档 val rdd1=sc.textFile("file:///d:/mr/word.txt") //压扁 val rdd2=rdd1.flatMap(_.split(" ")) //标1成对 val rdd3=rdd2.map((_,1)) //开始聚合 val rdd4=rdd3.reduceByKey(_+_) val arr=rdd4.collect() //collect() Array[(String,Int)] //手动打印 arr.foreach(println) //链式编程 sc.textFile("file:///d:/mr/word.txt").flatMap(_.split(" ")).map((_,1)).redyceByKey(_+_).collect().foreach(println) println("hello world") } } sc是shell内置的spark对象上下文的变量。 [SparkContext] SparkContext(org.apache.spark) def this()=this(new SparkConf()) //它需要的是Spark的配置SparkConf class SparkContext(config:SparkConf)extends Logging{}[Java实现]
在java里面最好带包
com.dzc.spark.mr.WorldCount.Javapackage com.zdc.spark.mr import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.function,pairFlatMapFunction; import java.util.Arrays; import java.util.Iterator; public class WordCountJava{ public static void main(String[] args){ SparkConf conf=new SparkConf(); conf.setAppName("wcJava"); conf.setMaster("local"); //在scala里面加上java前缀就是java里面的了 Api //创建一个上下文对象 JavaSparkContext sc=new JavaSparkContext(conf); //加载文件 JavaRDD<String> rdd1=sc.textFile(path:"file:///d:/mr/word.txt"); //返回值是 JavaRDD<String> //压扁 //只要压扁就可以了 JavaRDD<String>rdd2=rdd1.flatMap(new FlatMapFunction<String,String>(){ public Iterator<String>call(String s)throws Exception{ String[] arr=s.split(regex:" "); return Arrays.asList(arr).iterator(); } }); //压扁,注意了是压扁成对PairFlatMapFunciton<String,String,Integer>String这个表示它原来元素的类型,能推断出来 在java 里面高阶函数就变成了PairFlatMapFunciton接口,用匿名内部类对象方式来传 public Iterator<Tuple2<String,Integer>>call(String s)throws Exception这里的String就是这里的一行。 它是一个元组迭代器 //rdd1.flatMap(new PairFlatMapFunciton<String,String,Integer>(){ //添加未实现的方法 //public Iterator<Tuple2<String,Integer>>call(String s)throws Exception{ // String[] arr=s.split(regex:" "); //它的返回值就是数组 //Arrays.asList(T...a)(java.util)List<T>,它要的是一个迭代器iterator() //return Arrays.asList(arr).iterator();//bian chen canshu 返回的是List // } // }); //这里要的是flatMapToPair(PairFlatMapFunction....JavaPairRDD<K2,V2>)这个映射成对 //flatMapToPair(PairFlatMapFunction....JavaPairRDD<K2,V2>),PairFlatMapFunction这是一个接口,Java是没有高阶函数概念的。scala到处都是传函数。返回函数。在Java里面是以匿名内部类对象的方式来传。 //标1成对 //mapToPair返回值def mapToPair[K2,V2](f:PairFunction[T,K2,V2]):JavaPairRDd[K2,V2]={def cm:ClassTag[(K2,V2)]=implicitly[ClassTag[(K2,V2)]]new JavaPairRDD(rdd.map[(K2,V2)](f)(cm))(fakeClassTag[K2],fakeClassTag[V2])} JavaPairRDD<String,Integer>rdd3=rdd2.mapToPair(new PairFunction<String,String,Interger>(){ //Tuple2<String,Integer>这个是元组,它要把每一个单词变成一个单词和一的元组 public Tuple2<String,Integer>call(String s)throws Exception{ return new Tuple2<String,Integer>(s,_2:1); } }); //按照key聚合 reduceByKey(Function2<Integer,Integer,Integer>func) Function2表示有两个参数的函数 JavaPairRDD<String,Integer>rdd4=rdd3.reduceByKey(new Function2<Integer,Integer,Integer>(){ public Integer call(Integer v1,Integer v2)throws Exception{ return v1+v2; //按key聚合,它是不会改变类型的。它两个整数聚成一个整数。它的返回值类型仍然是JavaPairRDD } }); //收集 List<Tuple2<String,Integer>>二元组 collect()//List<Tuple2<String,Integer>> List<Tuple2<String,Integer>> coll=rdd4.collect(); //每一个元素都是二元组,单词和个数的一个元组 en 条目就是 for(Tuple2<String,Integer>t:coll){ System.out.println(t); } } }
//分步实现
val rdd1 = sc.textFile("file:///home/centos/1.txt");
val rdd2 = rdd1.flatMap(line=>{line.split(" ")})
val rdd3 = rdd2.map(word=>{(word , 1)})
val rdd4 = rdd3.reduceByKey((a:Int,b:Int)=>{a + b})
rdd4.collect()
//一步完成(reduceByKey)
sc.textFile("file:///home/centos/1.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect()
//一步完成(groupByKey)
sc.textFile("file:///home/centos/1.txt").flatMap(_.split(" ")).map((_,1)).groupByKey().mapValues(_.size).collect()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号