Umeng项目day04
Umeng项目day04
1.reddis引入确保硬件信息一致
收的ngix的Web服务器,用反向代理。做负载均衡。设备id号,要保证发送的机型是一致的。不能今天发送的和第二天发送的是不一致的,这样导致后面的数据没法统计。在这里做的时候需要保证数据是一致的。同时这个手机可以安装多个App.这里有appId应用唯一标识,tenantId 租户唯一标识,企业用户
[centos@s101 /home/centos]$su root [root@s101 /home/centos]#cd /soft/redis [root@s101 /soft/redis]#ls [root@s101 /soft/redis]#cd conf/ [root@s101 /soft/redis/conf]#ls 7000 7001 7002 7003 7004 7005 nodes.conf 将conf拷贝出来 [root@s101 /soft/redis/conf]#cp 7000/redis.conf#ls 把它放入当前的目录下 [root@s101 /soft/redis/conf]#ls 在当前目录下修改 [root@s101 /soft/redis/conf]#nano redis.conf 把出现7000的都改成 6379(默认的端口) protected-mode no //把保护模式关闭,否则不让远程连接
[root@s101 /soft/redis/conf]#cd .. [root@s101 /soft/redis]#ls 启动redis,指定配置文件下的.在redis服务器中指定它 [root@s101 /soft/redis]#redis-server redis.conf 在当前目录下指定drdb文件 [root@s101 /soft/redis]#bg %1 [root@s101 /soft/redis]#clear 查看一下进程 [root@s101 /soft/redis]#ps -Af |grep redis [root@s101 /soft/redis]#redis-cli 127.0.0.1:6379>keys * 127.0.0.1:6379>set key1 tom1 127.0.0.1:6379>get key1 这里要保证每个设备都是dev001,在这里dev001这里就可以做key了。整个手机的硬件信息做value 设备和App也是唯一绑定的,它这里也存了一个版本version 127.0.0.1:6379> [root@s101 /soft/redis]# [root@s101 /soft/redis]# 设备和APP也是唯一绑定的,dev001_tianya->这个就应该是一个key。它里面存了一个版本。这里也可以把它放一起,放一起的话就需要遍历一下了。它有没有这个值,因为它是hash.对于它来说就是一个平台platform.在这里它就是一个key了。在这里也叫字段了。platform:ios brand:苹果 devicestyle:iphone7 ostype:ios11 tianya: 1.0 在这里就需要写一个类进行访问就行了。 ss
//引入jedis
[umeng_phone_pom.xml]
<dependencies>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependencies>
查询按照设备号来查询,返回的就是设备的信息这也相当于1个客户端
package main.java.com.dzc.UMeng.phone.util;
/**
*reids工具类
*/
public class RedisUtil{
//指定连接串
private static Jedis redis=new Jedis("s101",6379);
//在这里就可以查询设备信息了(将设备信息封装一下)
//通过设备id得到多个值
//按照设备id,查询设备信息
public static DeviceInfo getDdeviceInfo(String devid,"appplatform","brand","deviceStyle","ostype"){
List<String>list=redis.hmget(devid,"appplatform","brand","deviceStyle","ostype");
if(list !=null && !list.isEnpty()){
DeviceInfo dev=new DeviceInfo();
dev.setDeviceId(devid);
dev.setAppPlatform(list.get(0));
dev.setBrand(list.get(1));
dev.setDeviceStyle(list.get(2));
dev.setOsType(list.get(3));
return dev;
}
return null;
}
}
[LogUtil]
//生成日志聚合体
public static AppLogAggEntity genAppAgg()throws Exception{
BaseAppLog devoceInfo =RedisUtil.getDeviceInfo(devId);
if(deviceInfo !=null){
DataUtil.copyProperty(deviceInfo,agg);
}
}
[ DeviceInfo]硬件信息包含BaseAppLog deviceId,appVersion,appChannel,appPlatform,brand,osType,deviceStyle信息
/**
硬件信息.从redis里面取出,从redis里面取出RedisUitl就不是
*/
public class DeviceInfo{
private String deviceId; //设备唯一标识
private String appPlatform; //平台
private String brand; //品牌
private String osType; //操作系统,平台版本
private String deviceStyle; //机型
public String getdeviceId(){
return deviceId;
}
public void setdeviceId(String deviceId){
this.deviceId =deviceId;
}
public String getappPlatform(){
return appPlatform;
}
public void setappPlatform(String appPlatform){
this.appPlatform =appPlatform;
}
public String getbrand(){
return brand;
}
public void setbrand(String brand){
this.brand =brand;
}
public String getosType(){
return osType;
}
public void setosType(String osType){
this.osType =osType;
}
public String getdeviceStyle(){
return deviceStyle;
}
public void setdeviceStyle(String deviceStyle){
this.deviceStyle =deviceStyle;
}
}
[LogUtil]
BaseLogApp deviceInfo=RedisUtil.getDeviceInfo(devId);
if(deviceInfo !=null){
BaseLogApp.copyProperty(deviceInfo,agg);
}
改成
DeviceInfo dev=RedisUtil.getDeviceInfo(devId);
if(dev !=null){
DeviceInfo.copyProperty(dev,agg);
}
else{
//设备信息
String[] devInfo=DictUtil.getRandDeviceType().split("#");
agg.setAppPlatform(devInfo[0]);
agg.setBrand(devInfo[1]);
agg.setDeviceStyle(devInfo[2]);
//设备的品牌渠道
agg.setDeviceId("xxxx");//设备id,每一个设备都有唯一的标识号,设备id必须是一致的
//渠道可以通过字典来取
agg.setAppChannel(DictUtil.getRandOsType(devInfo[0]));//渠道
//通过机型随机选了一个
String osType=DoctUtil.getRandOsType(devInfo[0]);
agg.setOsType(osType);
//把信息生成之外,还要将它存入到redis里面去
RedisUtil.setDeviceInfo(devId,devInfo[0],
devInfo[1],
devInfo[2],
osType); //操作系统版本
}
//设置App信息
String appversion =DictUtil.getRandString("appversion");
String appid=DictUtil.getRandString("appId");
appversion=RedisUtil.getAppVersion(devId,appid,appversion);
agg.setAppId(appid);
agg.setAppVersion(appversion);
[TestDict]
127.0.0.1:6379>keys *
127.0.0.1:6379>del key1
127.0.0.1:6379>keys *
//通过redis保证硬件设备和app相一致
public void testRedis()throws Exception{
AppLogAggEntity agg=LogUtil.genAppagg();
System.out.println();
}
[RedisUtil]
public static DeviceInfo getDeviceInfo(String devid){
boolean have=redis.exsts(devid);
if(have){
List<String>list=redis.hmget(devid,"appplatform","brand","deviceStyle","ostype");
String[] devInfo=DictUtil.getRandDeviceType().split("#");
agg.setAppPlatform(devInfo[0]);
agg.setBrand(devInfo[1]);
agg.setDeviceStyle(devInfo[2]);
agg.setOsType(list.get[3]);
return dev
}
return null;
}
2.收集数据到nginx web服务器
[LogUtil]
//生成日志聚合体
public static AppLogAggEntity genAppAgg()throws Exception{
AppLogAggEntity agg=new AppLogAggEntity();
String devId=LogUtil.genDeviceId();
//设置devId
agg.setDeviceId(devId);
//硬件信息
DeviceInfo dev=RedisUtil.getDeviceInfo(devId);
if(dev !=null){
DataUtil.copyroperty(dev,agg);
}
else{
//硬件信息
String[] devInfo=DictUtil.getRandDeviceType().split("#");
agg.setAppPlatform(devInfo[0]);
agg.setBrand(devInfo[1]);
agg.setDeviceStyle(devInfo[2]);
String osType=DictUtil.getRandOsType(devInfo[0]);
agg.setIsType(osType);
RedisUtil.setDeviceInfo(devId,devInfo[0],devInfo[1],devInfo[2],osType);
}
}
[Main]
//将Agg的聚合体给它变成JSON,然后将他发走
/**
* 入口点程序
*/
public class Main {
public static void main(String[] args) throws Exception {
//建立连接
String strURL = "http://192.168.13.4/1.html" ;
URL url = new URL(strURL) ;
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
//设置请求方式
conn.setRequestMethod("POST");
//设置发送的内容类型
conn.setRequestProperty("Content-Type" , "application/json");
//发送客户端时间,用来对其
conn.setRequestProperty("client_time",new Date().getTime()+"");
//允许输出到服务器
conn.setDoOutput(true);
OutputStream out = conn.getOutputStream() ;
//客户端就开始一直发
String json="";
out.write(json.getBytes());
out.flush();
out.close();
int code = conn.getResponseCode() ;
if(code == 200){
System.out.println("发送ok!!");
}
prvate static void sendLog(AppLogAggEntity agg)throws Exception{
String strURL="http://192.168.13.4/1.html";
URL url=new URL(strURL);
HttpURLConnection conn=(HttpURLConnection)url.openConnection();
//设置请求方式
conn.setRequestMethod("POST");
//设置发送的内容类型
conn.setRequestProperty("Content-Type","application/json");
//允许输出到服务器
conn.setDoOutput(true);
OutputStream out=conn.getResponseCode();
out.close();
int code=conn.getResponseCode();
if(code==200){
System.out.println("发送OK!!!");
}
}
}
[umeng_phone]
<dependency>
<groupId>com.alibaba</groupId>
<artifactId> fastjson</artifactId>
<version>1.2.24</version>
</dependency>
[Main]
public class Main{
public static void main(String[] args)throws Exception{
for(;;){
//将文件进行周期性发送,不能发送太快.发送太快机器会比较忙,每隔一秒发一次
sendLog(LogUtil.genAppAgg());
Thread.sleep(1000);
}
}
private static void sendLog(AppLogAggEntity agg)throws Exception{
out.write(json.getBytes());
out.flush();
//把对象变成JSON字符串
String json=JSONObject.toJSONString(agg);
}
}
[Windos\system32\cmd.exe]
netstat -ano
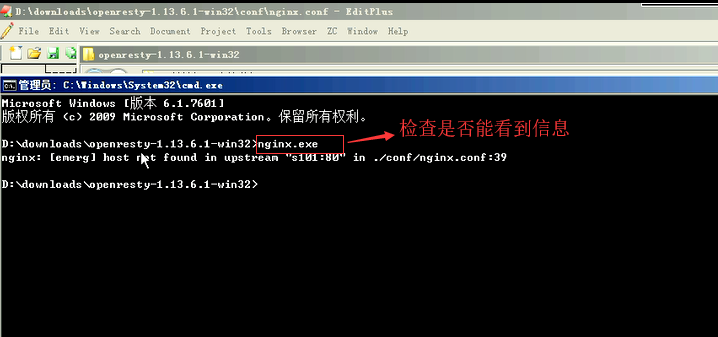

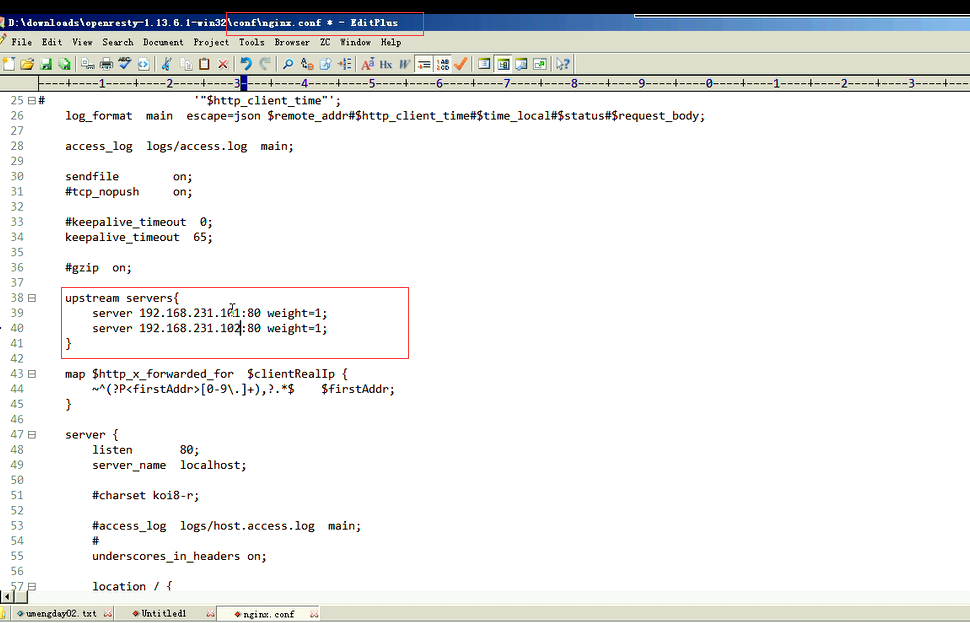
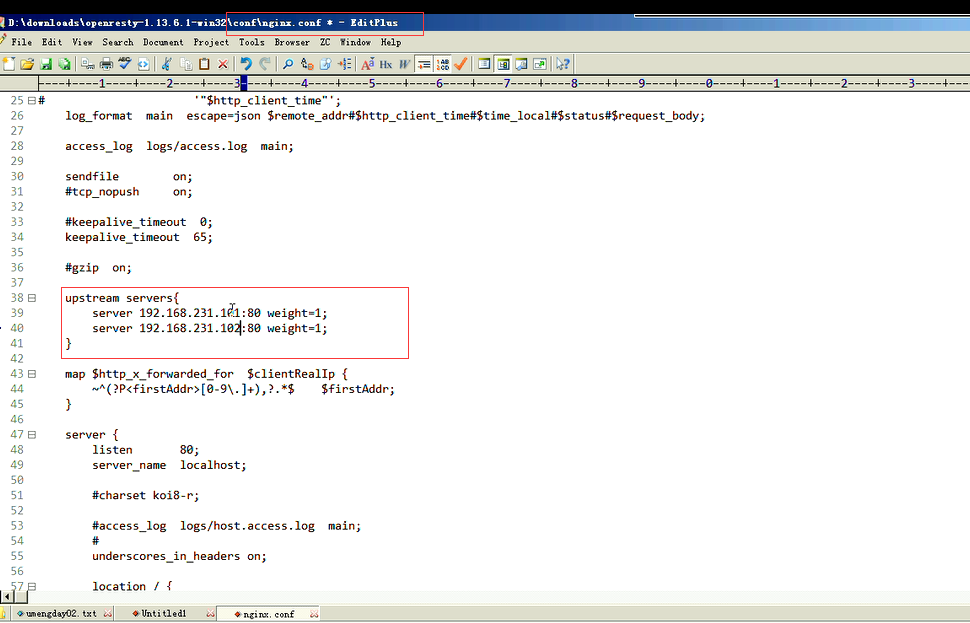

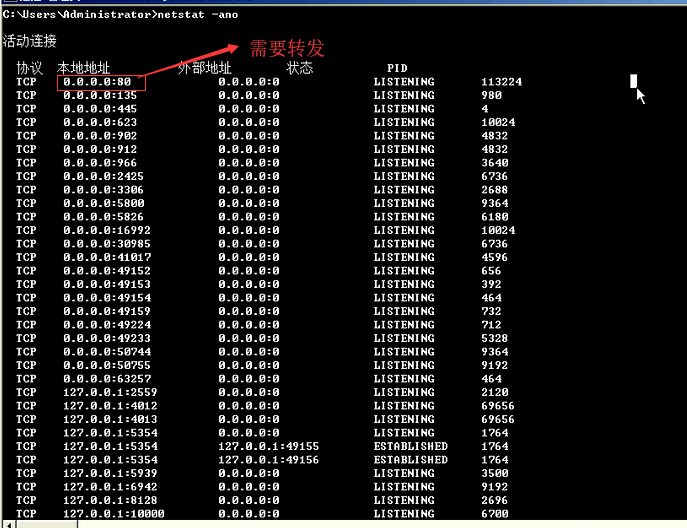
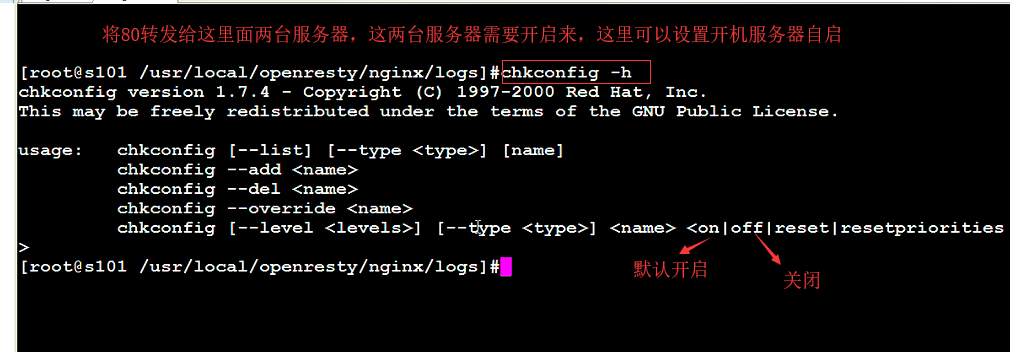
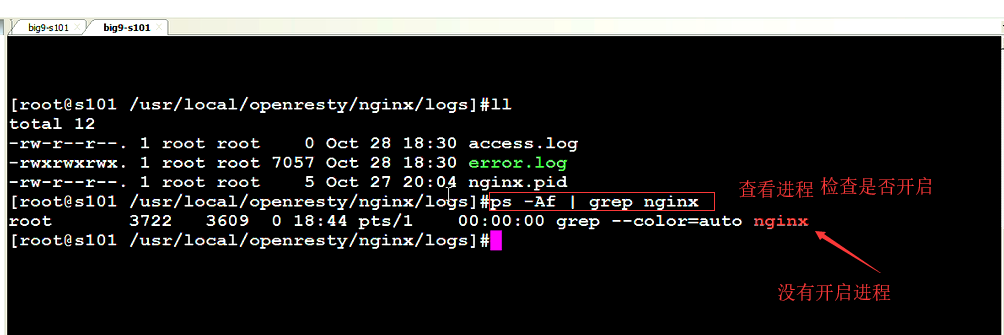

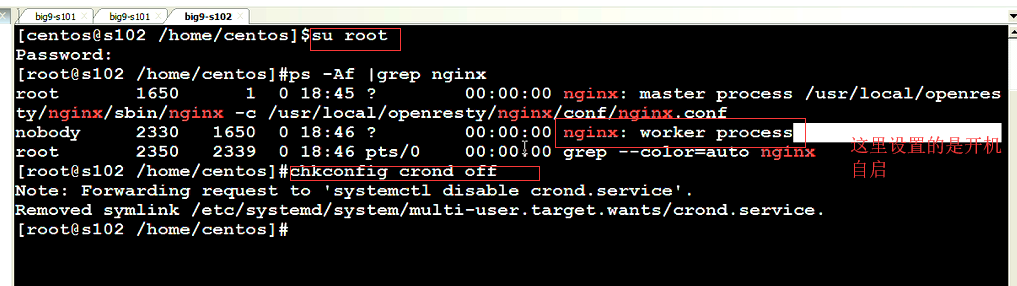

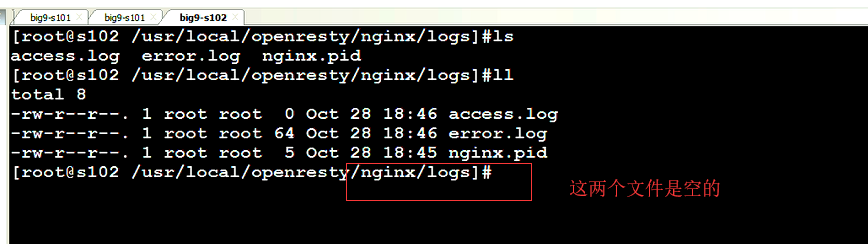
3.客户端时间发送
因为在ngix的配置文件中,添加了一个属性。它有一个日志格式,日志格式里面有一个http_client_time。这个时间没有上传。数据没有上传就导致它抓不到。抓不到就导致数据为空了。所以就需要将值传递给它。时间发送的时候,时间戳就是当前的。它是以属性的方式传上去。
4.flume收集acces日志到kafka
Kafka要启的时候还是要启动ZK的。Kafka在弄的时候还是需要在Centos里面去运行的。
对于Kafka来讲,从图形上从日志文件里去搜,把日志文件收到Kafka来去,这里面就需要配一个flime的节点。第一的话创建Kafka主题,收集access.log数据到Kafka集群。一个RDD分区就对应一个Kafka集群,不再是一些基于接受者方式了。
1.创建主题 //创建主题 需要指定分区和副本,分区数等于它的内核数。分区的目的在于并发。一个机器有几个核就可以并行多少个线程,集群的话就有多少个主机(就是它的总核数)partitions:分区数 replication:副本数(副本因子)replication-factor 1.1.kafka-topics.sh --zookeeper s102:2181 --partitions 4 --replication-factor 3 --create --topic big12-umeng-raw-logs SparkSjunmi:它是一个直向流。它是一个直接流。一个对应一个。一个RDD分区就对应一个Kafka集群,不再是一些基于接受者方式了。这里还可以配置首选位置,位置策略,消费者策略 //查看主题列表 1.2.kafka-topics.sh --zookeeper s102:2181 --list //启动消费者,测试主题 kafka-console-consumer.sh --zookeeper s102:2181 --topic big12-umeng-raw-logs 2.配置flume,收集access.log文件到kafka,这里用实施源叫exec源 a1.sources = r1 //源 a1.channels = c1 //通道 a1.sinks = k1 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /usr/local/openresty/nginx/logs/access.log a1.channels.c1.type = memory //内存通道 a1.channels.c1.capacity = 10000 //容量 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink //往Kafka发送数据 a1.sinks.k1.kafka.topic = big12-umeng-raw-logs /big12-umeng- raw-logs这是一个主题 a1.sinks.k1.kafka.bootstrap.servers = s102:9092 //Kafka服务器地址 a1.sinks.k1.kafka.flumeBatchSize = 20 //acks 0:不需要回执 1:leader写入磁盘后回执 -1:所有节点写入磁盘后回执 a1.sinks.k1.kafka.producer.acks = 1 //acks客户端发送者,消息生存者的切入模式 a1.sinks.k1.kafka.producer.linger.ms = 0 //linger多长时间,停留 a1.sources.r1.channels=c1 a1.sinks.k1.channel=c1 3.启动flume -n:是名称,启动flume需要指定某个代理。配置文件有很多代理。看一下是要启动的是那一个 flume-ng agent -f /soft/flume/conf/umeng_nginx_to_kafka.conf -n a1 4.复制配置文件到s102,进行相同操作。 略
这两个文件是要再这两个里面都有。因为现在Nginx外部服务器是负载聚合的。所以它每个服务器,它收到都要落到本地。如果都落到本地的话都需要配置flume把它们一起收到这个集群商量
将它发送走,发送到远程的机器上
5.flume收集kafka数据到hdfs
因为每天收到的数据量非常多,它是按日期来分区的。
收集kafka消息到hdfs
1.说明
每天上报的日志可能会含有以前的日志数据。但是每天上报的日志在一个以日期分割的目录内。还没有分区,只有在Hive里面有分区。还没有分区
ym/day
用户上报数据它是开启应用上报数据,开启应用上报的是上次上报完到这次上报之间的所有日志
2.umeng_kafka_to_hdfs.conf
a1.sources = r1
a1.channels = c1
a1.sinks = k1a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r1.batchSize = 5000 a1.sources.r1.batchDurationMillis = 2000 a1.sources.r1.kafka.bootstrap.servers = s102:9092 a1.sources.r1.kafka.topics = big12-umeng-raw-logs a1.sources.r1.kafka.consumer.group.id = g10 a1.channels.c1.type=memory a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = /user/centos/umeng_big11/raw-logs/%Y%m/%d/%H%M a1.sinks.k1.hdfs.filePrefix = events- a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 1 a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.hdfs.rollInterval = 30 a1.sinks.k1.hdfs.rollSize = 10240 a1.sinks.k1.hdfs.rollCount = 500 a1.sinks.k1.hdfs.useLocalTimeStamp = true a1.sinks.k1.hdfs.fileType = DataStream a1.sinks.k1.hdfs.fileType:分为两种:1.序列文件 2.纯文本DataStream
把r1和k1绑到通道上
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
3.准备hdfs
/user/centos/umeng_big12/raw-logs
4.启动flume进程
略
a1.sinks.k1.hdfs.fileType:分为两种:
1.序列文件 2.纯文本DataStream
6.常见创建库和表-加载数据到hive原生表
把Hive表创建出来,Hdfs的目录对应的是Hive的原生表。一加载就可以SQL的方式进行查询了。
准备hive
1.登录hive
2.创建新库
//不能使用-
create database big12_umeng;
3.建表
use big12_umeng ;
//创建hive的原生表,使用ym/day作为分区
create table raw_logs(servertimems float,
servertimestr string ,
clientip string ,
clienttimems bigint ,
status int,
json string)
PARTITIONED BY (ym string, day string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '#'
lines terminated by '\n';4.加载数据到原生表
hive>load data inpath '/user/centos/umeng_big12/raw-logs/ym=201810/day=28' into table raw_logs partition (ym=201810,day=28);5.查询
select serviertimems ,servertimestr ,clientpi,clienttimems , status ,json from raw_logs ;
6常见创建库和表
7.动态生成创建logs的ddl语句
如果原生表出来以后就可以做叉分了,叉分就可以用udtf函数叉开。叉开之前还需要做一些清洗。清洗包括两个步骤:时间又对齐的处理,客户端ClientMs与服务器时间Servertime之间他么是有时间差的。它不一定是同步的,时间 可能有不一致,不一致的问题会导致时间不准,统计的数据不对,假如说数据是在客户端上串上传大盘服务器,日志上传的数据不只是今天上传的数据,还有可能是昨天的数据。很多之前的数据也在里面。在客户端ClientMs里面 它记录了日志的时间,在日志里面的的确写入时间,这个时间就Nnginx服务器,Nginx服务器,它当时就落地时间,手机端记录日志发送的时间,它在上报的时间收获它会把时间报给服务器,单着问题是手机端时间和服务器时间它不同步,把时间对调跟服务器相同的使劲按上去,把差值加上取就型了。服务器时间是以原生日志数据在raw_logs,需要对它进行叉分, 需要对它做的是 以下几个步骤 1.时间对齐 2ip地址处理 3日志叉分 4实现格式转储parquet,列式存储,它统计的话更高效些,把相同的字段聚合在一起处理,而不是宣布在这种文件格式。编写Hive的udf/udtf函数实现日志清洗,将原生日志输几局的5方面日志拆分成5张子表对以后的每个子表进行单独的统计。原生日志表中的所有列的这些字段,那就是在叉分子表中u搜友的用到的,它们能对数据进行处理,就需要 我们用到uftf函数。
数据已经加载到Hive里面了,字段少了一个MS,因为它们都是字符串。除了时间是长整型之外,其它的全部都市字符串。时间工具类里面又用到了内省,它是生存了SQL,需要给它一个日志类,用内省的方式抽出它所有的字段(属性)它包裹了继承。
public static <T extends BaseLogApp>String genDDL(class<T> clazz)throws Exception{ String buffer=new StringBuffer(); buffer.append("create table"); BeanInfo bi=Introspector.getBeanInfo(clazz); PropertyDescriptor[] pps=bi.getPropertyDescriptors(); for(int i=0;i<pps.length;i++){ String name=pps[i].getName(); Method get=pps[i].getName(); Method set=pps[i].getWriteMethod(); if(get !=null && set !=null){ if(name.equalsIgnoreCase("createdAtMs")){ buffer.append("createdAtMs bigint ,"); //加完字段加换行符 buffer.append("\n"); }else{ buffer.append(name.toLowerCase()+"string"); } //最后一个属性 if(i !=(pps.length -1)){ buffer.append(" ,\r\n"); } } } buffer.append(")"); buffer.append("PARTITIONED BY (ym string, day string)\r\n"); buffer.append("stored as parquet"); return buffer.toString(); } [TestDict] public void testSenDDL()throws Exception(){ System.out.println(LogUtil.genDDL(AppStartupLog.class)); System.out.println(LogUtil.genDDL(AppEventLog.class)); System.out.println(LogUtil.genDDL(AppErrorLog.class)); System.out.println(LogUtil.genDDL(AppUsageLog.class)); System.out.println(LogUtil.genDDL(AppPageLog .class)); }
编写hive udf/udtf函数实现日志清洗
1.叉分日志
将raw_logs 叉分成5张日志子表。
startup_logs ;
usage_logs ;
...
2.创建子表
create table if not exists appstartuplogs (
appchannel string ,
appid string ,
appplatform string ,
appversion string ,
brand string ,
carrier string ,
country string ,
createdatms bigint ,
deviceid string ,
devicestyle string ,
ipaddress string ,
network string ,
ostype string ,
province string ,
screensize string ,
tenantid string)PARTITIONED BY (ym string, day string)
stored as parquet;
8.hive叉分函数-objectInspector
原生表的每一行,它都是日志的聚合体。需要把它拆开,拆开的话就需要把它拆到五张表里面去。Hive里面的典型UDTF函数,explode(炸裂函数)
[ForkUDTF.java]
//自定义叉分函数
//函数做成的最终形态:fork(servertimestr,clienttimems,clientip,json)
public class ForkUDTF extends GenericUDTF{
//对象转换器数组
private ObjectIinspectorConverters.Converter[]converters;
//初始化的时候是完成参数的校验,校验参数的合规性,这里它返回的是结构体返回器
//StructObjectInspector结构体对象检查器,因为叉分函数它进来的不管几列fork() 它输出的时候这一行可以有很多列。里面可以有很多列。这里它不是就是一列。它可以有很多列,每一个列它有名字。每一个列它都有类型。所以在这么多列,名称类型它搞在一起就是结构体。一个叉分函数,它可能需要输出很多的列。至于多少行是没有关系的。主要说的是一行。一行下面是有很多列的。而每一列它都有名称。还有值类型。整个列的集合是如何构成的?它用的就是StructOI(结构体OI)对象检查器。需要做的是把一条原生日志拆分成启动日志。而每一个启动日志的每一个字段都需要单独的起开。所以我们需要将字段做成字段集合的名称,字段检查器的集合。把名字和对象检查器搞出来,它们就形成了两个数组。这两个数组是一一对应的。把这两个数组交给方法,它就可以创建一个结构体对象检查器了。
//在原生表的中它是在JSON字符串中。现在需要对它进行拆分出来。做单独统计的,
public StructObjectInspector initialize(StrictObjectInspector argOIs)throws UDFAragumentException{
//字段名称集合
List<String>fieldnames =new ArrayList<String>();
//对象检查器集合
List<ObjectInspector> ois=new ArrayList<ObjectInspector>();
if(args.length !=4){
throw new UDFArgumentException("fork()需要4个参数");
//判断参数的类型,args[0]必须得有类型。它是枚举的类型。它首先得是基本类型,为Category类别。还得得是基本类别的中的字符串,字符串它是基本类别。保证第一个类型为基本类别,而且为基本类别的字符串类别。对象检查器可以得到类别,已经为基本类别了
//PrimitiveObjectInspector基本类别对象检查器,它是可以转过来的
//转过来以后再去得到它的基本类别getPrimitiveCategory
if(args[0].getCategory()!=ObjectInspector.Category.PRIMITIVE
&& ((PrimitiveObjectInspector)args[0]).getPrimitiveCategory()==PrimitiveObjectInspector.PrimitiveCategory.STRING){
throw new UDFArgumentException("fork()需要4个参数!!!!");
}
//STRING等价于Hadoop的文本类别text,也等价于java里面的String.它们都对应这个类别。其实它底层是不一样的。而传进来的参数,
//第一个值 String
//判断参数的类型
if(args[0].getCategory()==ObjectIinspec.Category.PRIMITIVE
||((PrimitiveObjectInspector)args[0]).getPrimitiveCategory()!=PrimitiveObjectInspector.PrimitiveCategory.STRING){
throw new UDFArgumentException("第一个参数不是string类型!!!");
}
}
//第二个值 bigint
if(args[1].getCategory()!=ObjectInspector.Category.PRIMITIVE
&& ((PrimitiveObjectInspector)args[1]).getPrimitiveCategory()==PrimitiveObjectInspector.PrimitiveCategory.LONG){
throw new UDFArgumentException("第二个参数不是bigint类型!!!");
}
//第三个值 string
if(args[2].getCategory()!=ObjectInspector.Category.PRIMITIVE
&& ((PrimitiveObjectInspector)args[1]).getPrimitiveCategory()==PrimitiveObjectInspector.PrimitiveCategory.STRONG){
throw new UDFArgumentException("第三个参数不是string类型!!!");
}
//第四个值 string
if(args[3].getCategory()!=ObjectInspector.Category.PRIMITIVE
&& ((PrimitiveObjectInspector)args[1]).getPrimitiveCategory()==PrimitiveObjectInspector.PrimitiveCategory.STRONG){
throw new UDFArgumentException("第四个参数不是string类型!!!");
}
//类型转换器
converters=new ObjectInspectorInspectorConverters.Converter[args.length];
//把你需要的对象检查器的类型放入进去就行了
converters[0]=ObjectInspectorConverters.getConverter(args[0],
PrimitiveObjectInspectorFactory.javaStringObjectInspector);
//
converters[1]=ObjectInspectorConverters.getConverter(args[1],
PrimitiveObjectInspectorFactory.javaLongObjectInspector);
converters[2]=ObjectInspectorConverters.getConverter(args[2],
PrimitiveObjectInspectorFactory.javaStringObjectInspector);
converters[3]=ObjectInspectorConverters.getConverter(args[3],
PrimitiveObjectInspectorFactory.javaStringObjectInspector);
try{
//通过内省的方式将字段集合和对象检查器集合抽出来,需要去组装它两,组装检查器。参数就是它们的集合
//将Javabean单独抽出来,放在公共类里面调用。
popOIS(AppStartupLog.class,fieldNames,ois);
}catch(Exception e){
e.printStackTrace();
}
//将启动日志叉分开来,它得有哪些信息?它得有所有字段的信息
// return super.initialize(argOIs);
//标准的检查器工厂可以拿到一个标准的结构体对象检查器
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,ois);
}
//组装对象检查器
private void popOIS(Class<AppStartupLog> appStartupLogClass,List<String>fieldNames,List<ObjectInspector> ois){
//把内省数据在走一遍,让它们和在一起输出
BeanInfo bi=Introspector.getBeanInfo(clazz);
PropertyDescripptor[] pps=bi.getPropertyDescriptors();
//开始循环
for(PropertyDescriptor pp: pps){
String name=pp.getName();
Class type=pp.getPropertyType();
Method get=pp.getReadMethod();
Method set=pp.getWriteMethod();
if(get !=null && set !=null){
if(type==Long.class ||type==long.class){
//在字段集中添加当前的名称
fieldNames.add(name);
//添加对象检查器的类型
ois.add(PrimitiveObjectInspectorFactory.javaLongObjectIinspector);
}
else if(type+=int.class ||type==Integer.class){
//在字段集中添加当前的名称
fieldNames.add(name);
//添加对象检查器的类型
ois.add(PrimitiveObjectInspectorFactory.javaIntObjectIinspector);
}
else(type==String.class ){
//在字段集中添加当前的名称
fieldNames.add(name);
//添加对象检查器的类型
ois.add(PrimitiveObjectInspectorFactory.javaStringObjectIinspector);
}
}
}
}
//开始处理计算过程,以对象数组的形式拿出数据,如何拿出数据?
public void process(Object[] args)throws HiveException{}
//
public void close() throws HiveException{}
}
//类型转换器,你要的参数用你想要的字符串类型提出来
//StrictObjectInspector argOIs已经给了输入的检查器对象
自定义udtf函数
---------------------------
1.ObjectInspector
对象检查器,检查对象的属性的,比如类型。
每个对象都对应一个OI(ObjectInspector)对象检查器ObjectInspector
进行函数定义的时候,看它是否和不和规范,如何判断类型?它传的不是实际的参数,传的是对象检查器
2.编写ForkUDTF函数
3.导出jar包
包含umeng_common和fastjson包
4.部署hive/lib
5.注册函数
hive>add jar /soft/hive/lib/umeng_hive.jar ;
hive>
drop function forkstartuplogs ;
drop function forkeventlogs ;
drop function forkerrorlogs ;
drop function forkusagelogs ;
drop function forkpagelogs ;
create function forkstartuplogs as 'com.oldboy.umeng.hive.udtf.ForkStartuplogsUDTF' ;
create function forkeventlogs as 'com.oldboy.umeng.hive.udtf.ForkEventlogsUDTF' ;
create function forkerrorlogs as 'com.oldboy.umeng.hive.udtf.ForkErrorlogsUDTF' ;
create function forkusagelogs as 'com.oldboy.umeng.hive.udtf.ForkUsagelogsUDTF' ;
create function forkpagelogs as 'com.oldboy.umeng.hive.udtf.ForkPagelogsUDTF' ;
fork(servertimestr , clienttimems , clientip ,json) --> -------------
-------------
在初始化对象返回器中,它叉分函数输出结构体类型的内容。
9.hive自定以叉分函数-注册与测试
udf和udtf加上UDAF是Hive中的三种自定义函数,普通函数udf,聚合函数udat(多行转一行),一行转多行udtf.叉分函数是指:你输入一条数据(可以是常量值,也可以是表中的一个记录)最终它会产生多条数据。它只是多转出了几次对象而已。单我么要说它生成多个列,udtf是一个叉分函数。它可以转换成多个列。udtf叫做表生成函数,表就是一个多行多列的二维表格。表结构取决于列。一个列就叫做一个字段。Hive是构建在Hadoop之上的。Hadoop里面是有串行化机制的。hadopp:Writable/Text/LongWritable /IntWritable 跟Java的 String/long/int是很像的。Hive Category:类别,类别包裹Hive的数据类型有基本类型(Primtive(String,bigint..这些可以对应hadoop的不同类型)),List,Map(列表类型),结构体(Struct),Union。
myfunc(f1)想要提取这个类型 ,它对于每一个对象(Object)。它都给了对象检查器(ObjectInspect),对象检查器它有一个方法。它可以。针对该对象的检查器。假如是Hadoop的Object的文本,ObjectInpsect.对象检查器它都会归并于HiveCategory(类别里面)。从Hadoop里面取出来的数据应该是Text文本。是想以操作字符串的形式,来操作它。就要用到字符串的检查器(OI.STRING),它两之间是需要一个转换的过程的。Hive提供了这个方法。Hive已经给了这个类叫做转换工厂(Converters.getConverter(srcOI(想对谁转换),cestOI(想转换成什么))),把ObjectInsect传给srcOI,把OISTRING传给cestOI.这里所得到的就是这个转换器。由于转换器已经指定 了是从srcOI到cestOI的转换,所以在通过转换器转换Object中的Text的值的时候,此时拿到值是串。对象检查器是输入的部分(src),它有四个参数。每一个对象检查器它都对应着一个转换器。在初始化的时候将转换器得到。就可以在process中调用它。在处理方法的时候通常会把类型的检查代码在调用一次。参数如果不对就会抛异常。它已经就不单单是检查器了。它已经是具体参数了。
public void process(Object[] args)throws HiveException{
//检查一下参数的个数有效性
if(args.length !=4){
throw new UDFArgumentException("fork()需要4个参数!!!");
}
//Object这个对象是输入的对象,
String servertimestr=(String)converters[0].convert(args[0]);
Long clienttimestr=(Long)converters[1].convert(args[1]);
String clientip=(String)converters[2].convert(args[2]);
String json=(String)converters[3].convert(args[3]);
//需要的是普通的替换,它生成的是新串 替换\” 为“
json=json.replace("\\\"","\“");
//将它解析成我们想要的数据,整个json字符串是它的聚合体。日志的聚合体
//解析json,返回日志聚合体对象,json在日志聚合体都带转义号。需要再次将数据改成双引号
AppLogAggEntity agg= JSONObject.parseObject(json,AppLogAggEntity.class);
//得到App的时候需要得到启动日志,每一个启动日志对象都得变成结构体。就是一行中的多个列。开始往外输出
//它这里整个是一个对象数组,它是对象数组的方式往外打
List<AppStartupLog> logs=agg.getStartupLogs();
//在初始化方法的时候告诉了它结构体的模式 ,拿到字段集合的时候就意味着。每一列的顺序就必须跟它完全吻合,如果跟它吻合,process方法就需要拿到字段的列表。如何拿?字段列表在当前列表下
// return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,ois);
//外层循环决定行数的
for(AppStartupLog log:logs){
Object[] arr=new Object[fieldNames.size()];
int i=0;
//里层循环决定列数,顺序和filedname顺序相同。因为在初始化方法中声明了它的返回值类型,就是表结构
for(String fname :fieldNames){
//得到字段该怎么办?拿到字段还需要得到字段所对应的值
//得到字段还可以得到字段是属性描述符
try{
//通过名称直接得到它的值
PropertyDescriptor pp=new PropertyDescriptor(fname,AppStartupLog.class);
//得到方法
Method get=pp.getReadMethod();
if(get !=null){
//按字段列表的顺序严格来迭代的。
Object retValue=get.invoke(log);
//所得到的值就应该按顺序方式添加到数组里面去
arr[i]=retValue;
}
i++;
}casch(Exception e){
e.printStackTrace();
}
//没有返回值就将值转发走,转发对象,其实就是输出一行。这就是Hive的UDTF函数。
forward(arr);
//自定义表生成函数,叉分启动日志
}
}
// for(String fieldName ;fieldNames){
//可以得到它的名称
//}
}
10.hive抽象与封装叉分函数
11.hive叉分函数子类-泛型抽象测试
11.1[BaseForkUDTF]
/**
* 自定义叉分函数
* 表生成函数
* fork(servertimestr , clienttimems , clientip ,json)
*/
public abstract class BaseForkUDTF<T> extends GenericUDTF {
private Class<T> clazz;
private ObjectInspectorConverters.Converter[] converters ;
//字段名称列表
List<String> fieldNames = null ;
//检查器列表
List<ObjectInspector> ois = null ;
//通过构造函数抽取子类的泛型化超类部分
public BaseForkUDTF(){
ParameterizedType type = (ParameterizedType) this.getClass().getGenericSuperclass();
clazz = (Class) type.getActualTypeArguments()[0];
}
/**
* 校验参数合规性
*/
public StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException {
//字段名称集合
fieldNames = new ArrayList<String>() ;
//对象检查器集合
ois = new ArrayList<ObjectInspector>() ;
if (args.length != 4) {
throw new UDFArgumentException("fork()需要4个参数!!!");
}
//判断参数的类型
//1.string
if(args[0].getCategory()!= ObjectInspector.Category.PRIMITIVE
|| ((PrimitiveObjectInspector)args[0]).getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING){
throw new UDFArgumentException("参数{1}不是string类型!!!");
}
//2.bigint
if (args[1].getCategory() != ObjectInspector.Category.PRIMITIVE || ((PrimitiveObjectInspector) args[1]).getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.LONG) {
throw new UDFArgumentException("参数{2}不是bigint类型!!!");
}
//3.string
if (args[2].getCategory() != ObjectInspector.Category.PRIMITIVE || ((PrimitiveObjectInspector) args[2]).getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING) {
throw new UDFArgumentException("参数{3}不是string类型!!!");
}
//4.string
if (args[3].getCategory() != ObjectInspector.Category.PRIMITIVE || ((PrimitiveObjectInspector) args[3]).getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING) {
throw new UDFArgumentException("参数{4}不是string类型!!!");
}
//类型转换器
converters = new ObjectInspectorConverters.Converter[args.length];
//保持每个参数对应的转换器
converters[0] = ObjectInspectorConverters.getConverter(args[0] , PrimitiveObjectInspectorFactory.javaStringObjectInspector) ;
converters[1] = ObjectInspectorConverters.getConverter(args[1] , PrimitiveObjectInspectorFactory.javaLongObjectInspector) ;
converters[2] = ObjectInspectorConverters.getConverter(args[2] , PrimitiveObjectInspectorFactory.javaStringObjectInspector) ;
converters[3] = ObjectInspectorConverters.getConverter(args[3] , PrimitiveObjectInspectorFactory.javaStringObjectInspector) ;
try {
popOIS(fieldNames , ois) ;
} catch (Exception e) {
e.printStackTrace();
}
//返回结构体对象检查器
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames , ois) ;
}
/**
* 组装对象检查器
* 将字段名称和对象检查器集合同步组装完成
* 每个字段都对应各自的对象检查器(ObjectInspector)
*/
private void popOIS(List<String> fieldNames, List<ObjectInspector> ois) throws Exception {
//获取clazz类的bean信息
BeanInfo bi = Introspector.getBeanInfo(clazz) ;
//得到所有属性
PropertyDescriptor[] pps = bi.getPropertyDescriptors();
for(PropertyDescriptor pp :pps){
String name = pp.getName() ;
Class type = pp.getPropertyType() ;
Method get = pp.getReadMethod() ;
Method set = pp.getWriteMethod() ;
//
if(get != null && set != null){
if(type == Long.class || type == long.class){
fieldNames.add(name) ;
ois.add(PrimitiveObjectInspectorFactory.javaLongObjectInspector) ;
}
else if(type == int.class || type ==Integer.class){
fieldNames.add(name);
ois.add(PrimitiveObjectInspectorFactory.javaIntObjectInspector);
}
else if(type == String.class){
fieldNames.add(name);
ois.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
}
}
}
}
public void process(Object[] args) throws HiveException {
//检查一下参数的个数有效性
if (args.length != 4) {
throw new UDFArgumentException("fork()需要4个参数!!!");
}
String servertimestr = (String) converters[0].convert(args[0]);
Long clienttimems = (Long) converters[1].convert(args[1]);
String clientip = (String) converters[2].convert(args[2]);
String json = (String) converters[3].convert(args[3]);
//替换\"为"
json = json.replace("\\\"" , "\"") ;
//解析json,返回日志聚合体对象
AppLogAggEntity agg = JSONObject.parseObject(json , AppLogAggEntity.class) ;
//TODO 时间对齐
alignTime(agg , servertimestr , clienttimems) ;
//
extraProcess(clientip) ;
List<T> logs = getLogs(agg) ;
//外层for循环决定行数
for(Object log : logs){
Object[] arr = new Object[fieldNames.size()] ;
int i = 0 ;
//内层for循环决定列数,顺序和filedname顺序相同
for(String fname : fieldNames){
try {
PropertyDescriptor pp = new PropertyDescriptor(fname , clazz) ;
Method get = pp.getReadMethod() ;
if(get != null){
Object retValue = get.invoke(log) ;
arr[i] = retValue ;
}
i ++ ;
} catch (Exception e) {
e.printStackTrace();
}
}
//转发对象,就是输出一行
forward(arr);
}
}
/**
* 额外的日志数据处理,有关于clientip地址的处理,默认空实现。
*/
protected void extraProcess(String clientip){
}
/**
* 时间对齐处理
*/
private void alignTime(AppLogAggEntity agg, String servertimestr, Long clienttimems) {
try {
//得到服务器时间戳
long servertimems = DateUtil.parseDateStrInUS(servertimestr) ;
//时间差额
long offset = servertimems - clienttimems ;
//得到所有的日志
List<AppBaseLog> logs = new ArrayList<AppBaseLog>() ;
logs.addAll(agg.getStartupLogs());
logs.addAll(agg.getEventLogs());
logs.addAll(agg.getErrorLogs());
logs.addAll(agg.getPageLogs());
logs.addAll(agg.getUsageLogs());
for(AppBaseLog log : logs){
log.setCreatedAtMs(log.getCreatedAtMs() + offset);
}
} catch (ParseException e) {
e.printStackTrace();
}
}
//抽象方法,子类必须重写
public abstract List<T> getLogs(AppLogAggEntity agg) ;
public void close() throws HiveException {
}
}
11.2[ForkErrorlogsUDTF]
/**
* 叉分事件日志
*/
public class ForkErrorlogsUDTF extends BaseForkUDTF<AppErrorLog>{
public List<AppErrorLog> getLogs(AppLogAggEntity agg) {
return agg.getErrorLogs();
}
}
11.3[ForkEventlogsUDTF]
/**
* 叉分事件日志
*/
public class ForkEventlogsUDTF extends BaseForkUDTF<AppEventLog>{
public List<AppEventLog> getLogs(AppLogAggEntity agg) {
return agg.getEventLogs();
}
}
11.4[ForkPagelogsUDTF]
/**
* 叉分启动日志
*/
public class ForkPagelogsUDTF extends BaseForkUDTF<AppPageLog>{
public List<AppPageLog> getLogs(AppLogAggEntity agg) {
return agg.getPageLogs();
}
}
11.5[ForkStartuplogsUDTF]
/**
* 叉分启动日志
*/
public class ForkStartuplogsUDTF extends BaseForkUDTF<AppStartupLog>{
public List<AppStartupLog> getLogs(AppLogAggEntity agg) {
return agg.getStartupLogs();
}
/**
* 重写该方法,设置地理信息
*/
protected void extraProcess(AppLogAggEntity agg , String clientip) {
List<AppStartupLog> logs = getLogs(agg) ;
for(AppStartupLog log : logs){
log.setIpAddress(clientip);
String[] arr = GeoUtil.getGeoInfo(clientip) ;
//国家
log.setCountry(arr[0]);
//省份
log.setProvince(arr[1]);
}
}
}
11.6[ForkUDTF]
/**
* 自定义叉分函数
* 表生成函数
* fork(servertimestr , clienttimems , clientip ,json)
*/
public class ForkUDTF extends GenericUDTF {
private ObjectInspectorConverters.Converter[] converters ;
//字段名称列表
List<String> fieldNames = null ;
//检查器列表
List<ObjectInspector> ois = null ;
/**
* 校验参数合规性
*/
public StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException {
//字段名称集合
fieldNames = new ArrayList<String>() ;
//对象检查器集合
List<ObjectInspector> ois = new ArrayList<ObjectInspector>() ;
if (args.length != 4) {
throw new UDFArgumentException("fork()需要4个参数!!!");
}
//判断参数的类型
//1.string
if(args[0].getCategory()!= ObjectInspector.Category.PRIMITIVE
|| ((PrimitiveObjectInspector)args[0]).getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING){
throw new UDFArgumentException("参数{1}不是string类型!!!");
}
//2.bigint
if (args[1].getCategory() != ObjectInspector.Category.PRIMITIVE || ((PrimitiveObjectInspector) args[1]).getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.LONG) {
throw new UDFArgumentException("参数{2}不是bigint类型!!!");
}
//3.string
if (args[2].getCategory() != ObjectInspector.Category.PRIMITIVE || ((PrimitiveObjectInspector) args[2]).getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING) {
throw new UDFArgumentException("参数{3}不是string类型!!!");
}
//4.string
if (args[3].getCategory() != ObjectInspector.Category.PRIMITIVE || ((PrimitiveObjectInspector) args[3]).getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING) {
throw new UDFArgumentException("参数{4}不是string类型!!!");
}
//类型转换器
converters = new ObjectInspectorConverters.Converter[args.length];
//保持每个参数对应的转换器
converters[0] = ObjectInspectorConverters.getConverter(args[0] , PrimitiveObjectInspectorFactory.javaStringObjectInspector) ;
converters[1] = ObjectInspectorConverters.getConverter(args[1] , PrimitiveObjectInspectorFactory.javaLongObjectInspector) ;
converters[2] = ObjectInspectorConverters.getConverter(args[2] , PrimitiveObjectInspectorFactory.javaStringObjectInspector) ;
converters[3] = ObjectInspectorConverters.getConverter(args[3] , PrimitiveObjectInspectorFactory.javaStringObjectInspector) ;
try {
popOIS(AppStartupLog.class ,fieldNames , ois) ;
} catch (Exception e) {
e.printStackTrace();
}
//返回结构体对象检查器
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames , ois) ;
}
/**
* 组装对象检查器
* 将字段名称和对象检查器集合同步组装完成
* 每个字段都对应各自的对象检查器(ObjectInspector)
*/
private void popOIS(Class<AppStartupLog> clazz, List<String> fieldNames, List<ObjectInspector> ois) throws Exception {
BeanInfo bi = Introspector.getBeanInfo(clazz) ;
PropertyDescriptor[] pps = bi.getPropertyDescriptors();
for(PropertyDescriptor pp :pps){
String name = pp.getName() ;
Class type = pp.getPropertyType() ;
Method get = pp.getReadMethod() ;
Method set = pp.getWriteMethod() ;
//
if(get != null && set != null){
if(type == Long.class || type == long.class){
fieldNames.add(name) ;
ois.add(PrimitiveObjectInspectorFactory.javaLongObjectInspector) ;
}
else if(type == int.class || type ==Integer.class){
fieldNames.add(name);
ois.add(PrimitiveObjectInspectorFactory.javaIntObjectInspector);
}
else if(type == String.class){
fieldNames.add(name);
ois.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
}
}
}
}
public void process(Object[] args) throws HiveException {
//检查一下参数的个数有效性
if (args.length != 4) {
throw new UDFArgumentException("fork()需要4个参数!!!");
}
String servertimestr = (String) converters[0].convert(args[0]);
Long clienttimems = (Long) converters[1].convert(args[1]);
String clientip = (String) converters[2].convert(args[2]);
String json = (String) converters[3].convert(args[3]);
//替换\"为"
json = json.replace("\\\"" , "\"") ;
//解析json,返回日志聚合体对象
AppLogAggEntity agg = JSONObject.parseObject(json , AppLogAggEntity.class) ;
List<AppStartupLog> logs = agg.getStartupLogs() ;
//外层for循环决定行数
for(AppStartupLog log : logs){
Object[] arr = new Object[fieldNames.size()] ;
int i = 0 ;
//内层for循环决定列数,顺序和filedname顺序相同
for(String fname : fieldNames){
try {
PropertyDescriptor pp = new PropertyDescriptor(fname , AppStartupLog.class) ;
Method get = pp.getReadMethod() ;
if(get != null){
Object retValue = get.invoke(log) ;
arr[i] = retValue ;
}
i ++ ;
} catch (Exception e) {
e.printStackTrace();
}
}
//转发对象,就是输出一行
forward(arr);
}
}
public void close() throws HiveException {
}
}
11.8[ForkUsagelogsUDTF]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号