iloc,loc,ix,df[]
总结一.
iloc可以把i当做第几个,所以是按行序号;其他的就清楚了.
1 import pandas 2 df = pandas.DataFrame({'a': [1, 2, 3, 4],'b': [5, 6, 7, 8], 'c': [9, 10, 11, 12]},index=["A", "B", "C", "D"]) # index:行名 3 print(df) 4 5 ## loc:以行列标签取值,行列之间用"," 6 print(df.loc['B', 'a']) 7 # 多行多列用":"隔开,行列之间用"," 8 print(df.loc['B':'C', 'a':'b']) # 注意:loc因为是用标签名来取数据的,所以左右都闭(逗比),即包含行"B和"C" 9 10 11 ## iloc:以行列序号取值(序号从0开始) 12 print(df.iloc[1,0]) 13 # 多行多列 14 print(df.iloc[1:3, 0:2]) # 注意:iloc是序号取数,左闭右开. 1:3实际上只包含1,2. 15 16 ## ix是上面两种都可以使用 17 print(df.ix['B', 'a']) 18 print(df.ix['B':'C', 'a':'b']) 19 print(df.ix[1,0]) 20 print(df.ix[1:3, 0:2])
参考文章:https://blog.csdn.net/qq1483661204/article/details/77587881
总结二.
第一个参数如.loc([1,2]),.iloc([2:3]),.ix[2]…则进行的是行选择
2).loc,.at,选列是只能是列名,不能是position
3).iloc,.iat,选列是只能是position,不能是列名
4)df[]只能进行行选择,或列选择,不能同时进行列选择,列选择只能是列名。行号和区间选择只能进行行选择。当index和columns标签值存在重复时,通过标签选择会优先返回行数据。df.只能进行列选择,不能进行行选择。
2).loc,.at,选列是只能是列名,不能是position
3).iloc,.iat,选列是只能是position,不能是列名
4)df[]只能进行行选择,或列选择,不能同时进行列选择,列选择只能是列名。行号和区间选择只能进行行选择。当index和columns标签值存在重复时,通过标签选择会优先返回行数据。df.只能进行列选择,不能进行行选择。
作者:3230
链接:https://www.jianshu.com/p/199a653e9668
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
import pandas as pd import numpy as np df = pd.DataFrame(np.arange(12).reshape(4, 3),columns=list('abc'), index=list('defg') ) print(df, '\n') #######loc # 操作多行,因为行是index,所以可以比较简单的操作 print(df.loc['d'], '\n') # 单行 print(df.loc['d': 'f'], '\n') #多行, d,e,f三行
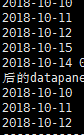
假如df中存在10-10到10-15这5行,现在运行df.loc["
2018-10-10
": ]
![]()
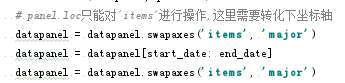
print(df.loc[['d', 'f']]) #多行,loc[]里的相当于列表,仅显示'd','f'两行 print(df.loc['a'], '\n') #error:the label [a] is not in the [index] print(df.loc['a': 'c']) # 操作多列,列就比较麻烦了,需要把行写成:,再配置列. print(df.loc[:, ['a', 'b']]) print(df.loc[:, :'b']) #####ix #错误的混合索引(想选取第一行和e行) print(df.ix[[0,'e']]) # Out[202]: # a b c # 0 NaN NaN NaN # e 3.0 4.0 5.0 #选取区域(这样也可行) df.ix['e':,:2] # Out[203]: # a b # e 3 4 # f 6 7 # g 9 10
#at/iat:通过标签或行号获取某个数值的具体位置。
#获取第2行,第3列位置的数据
df.iat[1,2]
Out[205]: 5
#获取f行,a列位置的数据
df.at['f','a']
Out[206]: 6
####直接索引df[]
# 选择行:
df[0:3] #
#选择列
df['a']
df.a
#选择多列
df['a', 'c']
#行号和区间索引只能用于行(预想选取C列的数据,
#但这里选取除了df的所有数据,区间索引只能用于行,
#因defg均>c,所以所有行均被选取出来)
df['c':]
# Out[212]:
# a b c
# d 0 1 2
# e 3 4 5
# f 6 7 8
# g 9 10 11
df['f':]
# Out[213]:
# a b c
# f 6 7 8
# g 9 10 11
新战场:https://blog.csdn.net/Stephen___Qin

 浙公网安备 33010602011771号
浙公网安备 33010602011771号