大数据综合项目设计.考试复习题
一、选择题
1. 对文件进行归档的命令为 D 。
A. dd B. cpio C. gzip D. tar
2. 改变文件所有者的命令为 C 。
A. chmod B. touch C. chown D. cat
3. 在给定文件中查找与设定条件相符字符串的命令为 A 。
A. grep B. gzip C. find D. sort
4. 建立一个新文件可以使用的命令为 D 。
A. chmod B. more C. cp D. touch(指令改变文件的时间记录)
5.在下列命令中,不能显示文本文件内容的命令是 D 。
A. more B. less C. tail D. join
6.删除文件命令为 D 。
A. mkdir B. rmdir C. mv D. rm
7. 以下哪一项不属于Hadoop可以运行的模式 C 。
A. 单机/本地模式 B. 伪分布式模式
C. 互联模式 D. 分布式模式
9. Spark SQL目前暂时不支持下列哪种语言 C 。
A. Scala B. Java C. Lisp D. Python
10. 在Spark2.0版本之前,Spark SQL中创建DataFrame和执行SQL的入口是 C 。
A. HiveContext B. SparkSession C. SQLContext D. SparkContext
11. 在DataFrame的操作中,用于实现对列名进行重命名的操作是 A 。
A. select() B. show() C. filter() D. map()
12. Scala是⼀种纯粹的面向对象语言,每⼀个值都是 D 。
A. 类 B. 接口 C. 特质 D. 对象
答案解析: Scala是⼀种纯粹的⾯向对象语言,每⼀个值都是对象。
13. DataFrame的结构类似于传统数据库的 B 。
A. ⼀维表格 B. ⼆维表格 C. 三维表格 D. 四维表格
答案解析: DataFrame的结构类似于传统数据库的⼆维表格。
14. Scala中,数组的遍历方式不包含 D 。
A. for循环遍历
B. while循环遍历
C. do...while循环遍历
D. do...for循环遍历
答案解析: 数组的遍历有三种方式,分别是for循环遍历、while循环遍历以及do...while循环遍历。
15. 使用Maven Projects工具,双击 D 选项,即可自动将项目打成Jar包。
A. clean B. test C. deploy D. package
16. 下列选项中,可以用于退出Spark-Shell客户端的命令是 A 。
A. :quit B. :wq C. :q D. :exit
17. 在Maven工程的pom.xml文件中,用于设置所需依赖的版本号的标签是 C 。
A. <dependency>
B. <groupId>
C. <properties>
D. <artifactId>
18. 下列选项中,Scala编译后文件的后缀名为 A 。
A. .class
B. .bash
C. .pyc
D. .sc
参考答案: A
19. DataFrame和RDD最大的区别是 B 。
A. 科学统计⽀持
B. Schema
C. 存储方式不⼀样
D. 外部数据源⽀持
20. 下列选项中,可用于Scala语言开发的工具是 D 。
A. Office B. PyCharm C. Notepad++ D. IntelliJ IDEA
21. 关于SparkSession对象说法错误的是 D 。
A. 从Spark2.0开始开始使用
B. 是Spark SQL的"入口"
C. 在Spark SQL程序开发过程中,第一个要创建的就是该对象
D. 在Spark2.0中,SparkSession不能实现SQLContext的所有功能
22. Spark2.0中,使用SparkSession.builder()时,关于master方法错误的是: C 。
A. 可以指定local模式
B. 可以指定spark://host:port
C. local[*]表示最多只能使用本机一半CPU核数
D. 可以使用Spark自身的Standlone运行模式
23. DataFrame说法正确的是 B 。
A. 不是一个分布式数据容器
B. 更像传统数据库的二维表格
C. 不支持嵌套数据
D. 不是分布式的Row对象的集合
24. 关于vim编辑器说法错误的是 A 。
A. 打开vim编辑器后,需要输入I,才能进入编辑状态
B. 从键盘输入":wq"3个字符,然后按<Enter>键,表示保存文件并退出
C. 从键盘输入":q"2个字符,然后按<Enter>键,表示不保存文件并退出
D. 从键盘输入":q!"3个字符,然后按<Enter>键,表示不保存文件并强制退出
25. 安装Spark2.1.0,Java版本要求 D 。
A. Java5及以上版本
B. Java6及以上版本
C. Java7及以上版本
D. Java8及以上版本
26. Hadoop(伪分布式)+Spark(Local模式)中,两者可以相互协作,下述说法错误的是 B 。
A. 由Hadoop的HDFS,HBase等组件负责数据存储和管理
B. Spark操作HDFS中的数据时,不需事先启动HDFS,即可直接进行操作
C. 由Spark负责计算
D. Spark压缩包解压缩后,即可以直接使用。
27. Spark-Shell的使用正确的说法是 B 。
A. spark-shell 会默认进入Python的交互式执行环境
B. spark-shell支持Scala编程语言
C. spark-shell不支持Python编程语言
D. spark-shell命令不会默认进入Scala的交互式执行环境
28. 关于IntelliJ IDEA说法错误的是 B 。
A. 分为社区版和商业版
B. 社区版的功能非常强大了,不需要使用商业版
C. 社区版IntelliJ IDEA,第一次使用Scala开发软件,需要安装Scala插件
D. IntelliJ IDEA是使用Java 语言开发的
29. 有关Kettle,错误的是 C 。
A. 是一款开源ETL软件
B. 是使用Java 语言开发的
C. 只能在Linux下运行
D. 其组件Spoon可以运行转换或者任务
30. Spark MLlib的机器学习算法库说明错误的是 D 。
A. 从1.2版本以后分为两个包:spark.mllib与spark.ml
B. spark.ml提供了基于DataFrame的、高层次的API
C. spark.mllib包含基于RDD的原始算法API
D. Spark官方推荐使用spark.mllib
31. 下面哪个不是RDD的特点 C 。
A. 可分区 B. 可序列化 C. 可修改 D. 可持久化
32. 使用saveAsTextFile存储数据到HDFS,要求数据类型为 D 。
A. List B.Array C. Seq D.RDD
33. Spark SQL可以处理数据源包括 D 。
A. Hive表
B. 数据文件、Hive表
C. 数据文件、Hive表、RDD
D. 数据文件、Hive表、RDD. 外部数据库
34.下列说法正确的是 C 。
A. Spark SQL的前身是Hive
B. DataFrame其实就是RDD
C. HiveContext继承了SqlContext
D. HiveContext只支持SQL语法解析器
35. 如何查看DataFrame对象的前10条记录? C 。
A. df.show() B. df.show(false)
C. df.show(10) D. df.collect()
36. DataFrame的groupBy方法返回的结果是什么类型? D 。
A. DataFrame B. Column
C. GroupedData D. RDD
37. 下列不属于Spark生态系统的是 B 。
A. Spark Streaming
B. Storm
C. Shark SQL
D. Spark R
38. 下列不属于Spark生态系统的是 B 。
A. Spark Streaming
B. Storm
C. Shark SQL
D. Spark R
39. 下列适合Spark大数据处理场景的是 D 。
A. 复杂的批处理
B. 基于历史数据的交互式查询
C. 基于实时数据流的数据处理
D. PB级的数据存储
40. 下列不是Spark的部署模式的是 C 。
A. 单机式
B. 单机伪分布式
C. 列分布式
D. 完全分布式
41. 在Spark的软件栈中,用于机器学习的是 B 。
A.Spark Streaming B. Mllib C. GraphX D. Spark Streaming
42. 机器学习研究如何通过计算的手段,利用经验来改善系统自身的性能,请问机器学习利用数据训练出什么 A 。
A. 模型 B. 表结构 C. 结果 D. 报表
43. 在Spark的软件栈中,用于交互式查询的是 A 。
A. SparkSQL B. Mllib C. GraphX D. Spark Streaming
44. 下面哪个方法不是用于创建RDD? D 。
A. makeRDD B. parallelize C. textFile D. saveAsTextFile
45. Spark支持的分布式资源管理器不包括: D 。
A. standalone B. Mesos C. YARN D. Local
46. 关于DataFrame的说法错误的是: B 。
A. DataFrame是由SchemaRDD发展而来
B. DataFrame直接继承了RDD
C. DataFrame实现了RDD的绝大多数功能
D. DataFrame是一个分布式Row对象的数据集合
47. 相比Spark,Spark SOL 有哪些优势? B 。
①Spark SQL摆脱了对Hive的依赖
②Spark SQL支持在Scala中写SQL语句
③Spark SQL支持parquet文件的读写,且保留了Schema
④Spark SQL 支持访问Hive,而Spark不支持
A. ①② B. ①②③ C. ①②③④ D. ②③④
48. vi中哪条命令是不保存强制退出 C 。
A. :wq B. :wq! C. :q! D. :quit
49. 在UNIX/Linux系统添加新用户的命令是 D 。
A. groupadd B. usermod C. userdel D. useradd
50. 删除文件命令为 D 。
A.mkdir B.move C.mv D.rm
51. 要切换成其他用户,则必须使用 C 命令。
A. ps B. ls C. su D. sudo
二、填空题
- Hadoop运行的模式有: 单机模式 、 伪分布模式 、 完全分布式 。
- Hadoop集群搭建中常用的4个配置文件为: core-site.xml 、 hdfs-site.xml、 mapred-site.xml 、 yarn-site.xml 。
- 格式化HDFS系统的命令为: hdfs namenode –format 。
- 启动HDFS的shell脚本为: start-dfs.sh 。
- 停止HDFS的shell脚本为: stop-dfs.sh 。
- Hadoop创建多级目录(如:/a/b/c)的命令为: hadoop fs –mkdir –p /a/b/c 。
- Hadoop显示根目录命令为: hadoop fs –lsr 。
- Hadoop包含的四大模块分别是: Hadoop Common 、 HDFS 、 Mapreduce 、 YARN 。
Linux基本命令
| 命令 | 含义 |
|---|---|
cd /home/hadoop |
把/home/hadoop设置为当前目录 |
cd .. |
返回上一级目录 |
cd ~ |
进入到当前Linux系统登录用户的主目录(或主文件夹)。在 Linux 系统中,~代表的是用户的主文件夹,即“/home/用户名”这个目录,如果当前登录用户名为 hadoop,则~就代表“/home/hadoop/”这个目录 |
ls |
查看当前目录中的文件 |
ls -l |
查看文件和目录的权限信息 |
cat /proc/version |
查看Linux系统内核版本信息 |
cat /home/hadoop/word.txt |
把/home/hadoop/word.txt这个文件全部内容显示到屏幕上 |
cat file1 file2 > file3 |
把当前目录下的file1和file2两个文件进行合并生成文件file3 |
HDFS基本命令:
第一类:文件路径增删改查系列:
hdfs dfs -mkdir dir 创建文件夹
hdfs dfs -rmr dir 删除文件夹dir
hdfs dfs -ls 查看目录文件信息
hdfs dfs -cat file 查看文件file
第二类:文件操作(上传下载复制)系列
hdfs dfs -rm file 删除文件file
hdfs dfs -put file dir 向dir文件上传file文件
hdfs dfs -put filea dir/fileb 向dir上传文件filea并且把filea改名为fileb
hdfs dfs -get file dir 下载file到本地文件夹
三、简答题
1.为什么一般情况下都不推荐使用root用户登录Linux系统进行日常的操作?
root是系统中唯一的超级用户,具有系统中所有的权限,如启动或停止一个进程、删除或增加用户、增加或者禁用硬件等等。
Linux中的root用户比Windows的Administrator用户的能力更大,足以把整个系统的大部分文件删掉,导致系统完全毁坏,不能再次使用。所以,用root进行不当的操作是相当危险的,轻微的可以造成死机,严重的甚至不能开机。因此,在实际使用中,除非确实需要,一般情况下都不推荐使用root用户登录Linux系统进行日常的操作。建议单独建立一个普通的用户,来学习大数据软件安装和开展编程实践。
2. 什么是 Node.js?
Node.js是一个基于 Chrome V8 引擎的服务器端 JavaScript运行环境;
Node.js是一个事件驱动、非阻塞式I/O的模型,轻量而又高效;
Node.js的包管理器npm是全球最大的开源库生态系统。
3. 为什么要用 Node. js?
原因如下。
(1)简单, Node. js用 JavaScript、JSON进行编码,简单好学。
(2)功能强大,非阻塞式I/O,在较慢的网络环境中,可以分块传输数据,事件驱动,擅长高并发访问。
(3)轻量级, Node. js本身既是代码又是服务器,前后端使用同一语言。
(4)可扩展,可以轻松应对多实例、多服务器架构,同时有海量的第三方应用组件。
4. npm是什么?,它的优势是什么?
npm是Node.js中管理和分发包的工具,可用于安装、卸载、发布、查看包等。
通过npm,可以安装和管理项目的依赖,还可以指明依赖项的具体版本号。
5. npm的作用是什么?
npm是同 Node .js一起安装的包管理工具,能解决 Node.
js代码部署上的很多问题。常见的使用场景有以下几种。
(1)允许用户从npm服务器下载别人编写的第三方包到本地。
(2)允许用户从npm服务器下载并安装别人编写的命令行程序到本地。
(3)允许用户将自己编写的包或命令行程序上传到npm服务器供别人使用。
6. Spark SQL简介?
Spark SQL 主要用于结构化数据的处理。其具有以下特点:
能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 DataFrame API 对结构化数据进行查询;
支持多种数据源,包括 Hive,Avro,Parquet,ORC,JSON 和 JDBC;
支持 HiveQL 语法以及用户自定义函数 (UDF),允许你访问现有的 Hive 仓库;
支持标准的 JDBC 和 ODBC 连接;
支持优化器,列式存储和代码生成等特性,以提高查询效率。
7. 什么是Spark MLlib?
MLlib 是 Spark 的机器学习库。其设计目标是使得机器学习变得简单且可扩展。
它提供了以下工具:
常见的机器学习算法:如分类,回归,聚类和协同过滤;
特征化:特征提取,转换,降维和选择;
管道:用于构建,评估和调整 ML 管道的工具;
持久性:保存和加载算法,模型,管道数据;
实用工具:线性代数,统计,数据处理等。
8. 什么是DataFrame
为了支持结构化数据的处理,Spark SQL 提供了新的数据结构 DataFrame。DataFrame 是一个由命名列组成的数据集。它在概念上等同于关系数据库中的表或 R/Python 语言中的 DataFrame。 由于 Spark SQL支持多种语言的开发,所以每种语言都定义了 DataFrame 的抽象,主要如下:
| 语言 | 主要抽象 |
|---|---|
| Scala | Dataset[T] & DataFrame (Dataset[Row] 的别名) |
| Java | Dataset[T] |
| Python | DataFrame |
| R | DataFrame |
9. DataFrame和RDD区别?
DataFrame 和 RDDs
最主要的区别在于一个面向的是结构化数据,一个面向的是非结构化数据,它们内部的数据结构如下:
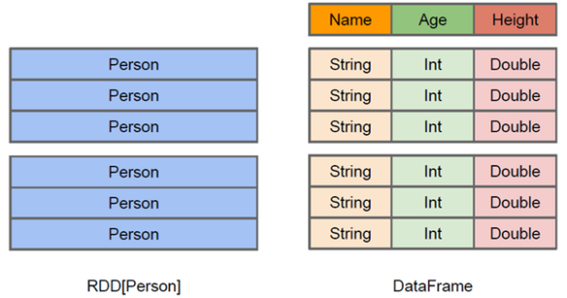
DataFrame 内部的有明确 Scheme
结构,即列名、列字段类型都是已知的,这带来的好处是可以减少数据读取以及更好地优化执行计划,从而保证查询效率。
DataFrame 和 RDDs 应该如何选择?
如果你想使用函数式编程而不是 DataFrame API,则使用 RDDs;
如果你的数据是非结构化的 (比如流媒体或者字符流),则使用 RDDs,
如果你的数据是结构化的 (如 RDBMS 中的数据) 或者半结构化的
(如日志),出于性能上的考虑,应优先使用 DataFrame。
10. 什么是推荐系统
推荐系统:通过分析用户的历史行为记录来了解用户的喜好,从⽽主动为用户推荐其感兴趣的信息,满⾜用户的个性化推荐需求
推荐系统是自动联系用户和物品的⼀种工具,和搜索引擎相⽐,推荐系统通过研究用户的兴趣偏好,进行个性化计算。推荐系统可发现用户的兴趣点,帮助用户从海量信息中去发掘自⼰潜在的需求
11. 什么是长尾理论?
"长尾"用来描述电子商务⽹站的商业模式和经济模式。
长尾理论:普通产品和冷门产品所共同占据的市场份额可以和那些少数热销产品所占据的市场份额相匹敌甚至更大
因此,可以通过发掘长尾商品并推荐给感兴趣的用户来提⾼销售额。这需要通过个性化推荐来实现
推荐系统可以创造全新的商业和经济模式,帮助实现长尾商品的销售。
推荐系统和长尾理论结合,可使得用户和商家共赢(用于得到感兴趣的商品,商家扩大了销售)
12. 推荐方法概述?
推荐系统的本质是建⽴用户与物品的联系,根据推荐算法的不同,推荐方法包括如下几类:
-
专家推荐:⼈工推荐,由资深的专业⼈⼠来进行物品的筛选和推荐,需要较多的⼈⼒成本
-
基于统计的推荐:基于统计信息的推荐(如热门推荐),易于实现,但对用户个性化偏好的描述能⼒较弱
-
基于内容的推荐:通过机器学习的方法去描述内容的特征,并基于内容的特征来发现相似的内容
-
协同过滤推荐:利用与目标用户相似的用户已有的商品评价信息,来预测目标用户对特定商品的喜好程度。是应用最早和最为成功的推荐方法之⼀。
-
混合推荐:结合多种推荐算法来提升推荐效果
13. 推荐系统的应用?
目前推荐系统已广泛应用于电子商务、在线视频、在线音乐、社交网络等各类网站和应用中。
如亚马逊网站利用用户的浏览历史记录来为用户推荐商品,推荐的主要是用户未浏览过,但可能感兴趣、有潜在购买可能性的商品。
14. Hadoop三种模式的区别?
(1)单机模式:只在一台机器上运行,存储是采用本地文件系统,没有采用分布式文件系统HDFS;
(2)伪分布式模式:存储采用分布式文件系统HDFS,但是,HDFS的名称节点和数据节点都在同一台机器上;
(3)分布式模式:存储采用分布式文件系统HDFS,而且,HDFS的名称节点和数据节点位于不同机器上。
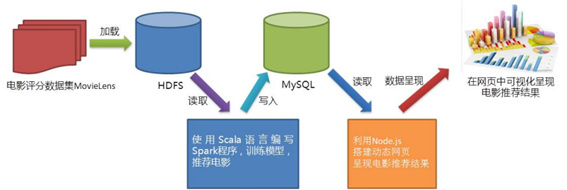
15. 给出电影推荐系统的数据分析整体过程?
(1)使用Kettle将数据文件从Linux本地文件导入到HDFS;
(2)使用Scala语言编写Spark程序,根据数据集训练模型,为用户推荐其最感兴趣的电影;
(3)利用Node.js搭建动态网页呈现电影推荐结果。
16. Shell也有多种不同的版本,简述常用版本的Shell?
Bourne Shell:由贝尔实验室开发;
BASH:是GNU的Bourne Again Shell,是GNU操作系统上默认的Shell;
Korn Shell:是对Bourne Shell的发展,在大部分内容上与Bourne Shell兼容;
C Shell:是SUN公司Shell的BSD版本;
Z Shell:Z是最后一个字母,也就是终极Shell,集成了BASH、ksh的重要特性,同时又增加了自己独有的特性。
17. 简述hadoop的安装配置
1.创建hadoop账户
2.配置主机名
3.配置hosts文件
4.配置免密码登录
5.安装和配置jdk、修改/etc/profile文件,配置环境变量
6.上传和安装hadoop
7.配置hadoop配置文件(hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml)
8.配置slaves文件
9.配置hadoop的环境变量
10.格式化namenode ----》hadoop namenode --format
11.启动hadoop ./start-all.sh
18. 试述两种典型的推荐算法UserCF和ItemCF算法的区别,以及各自优缺点
UserCF算法和ItemCF算法的思想、计算过程都相似
两者最主要的区别:
| 角度 | UserCF | ItemCF |
|---|---|---|
| 推荐角度 | 推荐那些和目标用户有共同兴趣爱好的其他用户所喜欢的物品 | 推荐那些和目标用户之前喜欢的物品类似的其他物品 |
| 推荐适用 | 推荐更偏向社会化:适合应用于新闻推荐、微博话题推荐等应用场景,其推荐结果在新颖性方面有一定的优势 | 推荐更偏向于个性化:适合应用于电子商务、电影、图书等应用场景,可以利用用户的历史行为给推荐结果作出解释,让用户更为信服推荐的效果 |
| 缺点 | 随着用户数目的增大,用户相似度计算复杂度越来越高。而且UserCF推荐结果相关性较弱,难以对推荐结果作出解释,容易受大众影响而推荐热门物品 | 倾向于推荐与用户已购买商品相似的商品,往往会出现多样性不足、推荐新颖度较低的问题 |
19. 基于模型的协同过滤
基于模型的协同过滤算法(ModelCF)是通过已经观察到的所有用户给产品的打分,来推断每个用户的喜好并向用户推荐适合的产品。实际上,ModelCF算法同时考虑了用户和物品两个方面,因此,它也可以看作是userCF和ItemCF算法的混合形式。
四、编程题
1. 使用Hadoop用户名登录Linux系统,启动Hadop,使用Hadoop提供的Shell完成如下操作:
1.1 在Linux系统的本地文件系统的"/home/hadoop"目录下新建一个文本文件test.txt,并在该文件中随意输入一些内容,然后上传到HDFS的"/data/input"目录下。
$ vi /home/hadoop/test.txt
$ hdfs dfs –put /home/hadoop/test.txt /data/input/
1.2 在spark-shell中读取Linux系统的本地文件"/home/hadoop/test.txt",然后统计出文件的行数。
$ cd /usr/local/spark
$ ./bin/spark-shell
scala>val textFile=sc.textFile("file:///home/hadoop/test.txt")
scala>textFile.count()
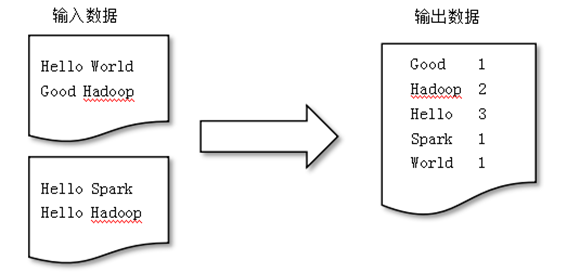
2. 任务:编写一个Spark应用程序,对某个文件中的单词进行词频统计。
scala> val textFile = sc.textFile("file:///usr/local/spark/mycode/wordcount/word.txt")
scala> val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
scala> wordCount.collect()
3.任务:编写一个Spark应用程序,实现JDBC连接数据库(DataFrame),已知数据库名称是"spark",表的名称是"student"。
//下面我们设置两条数据表示两个学生信息
val studentRDD = spark.sparkContext.parallelize(Array("3
Rongcheng M 26","4 Guanhua M 27")).map(_.split(" "))
//下面要设置模式信息
val schema = StructType(List(StructField("id",IntegerType, true),StructField("name", StringType,true),StructField("gender", StringType,true),StructField("age", IntegerType, true)))
//下面创建Row对象,每个Row对象都是rowRDD中的一行
val rowRDD = studentRDD.map(p => Row(p(0).toInt, p(1).trim,p(2).trim, p(3).toInt))
//建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
val studentDF = spark.createDataFrame(rowRDD, schema)
//下面创建一个prop变量用来保存JDBC连接参数
val prop = new Properties()
prop.put("user", "root") //表示用户名是root
prop.put("password", "hadoop") //表示密码是hadoop
prop.put("driver","com.mysql.jdbc.Driver")//表示驱动程序是com.mysql.jdbc.Driver
//下面就可以连接数据库,采用append模式,表示追加记录到数据库spark的student表中
studentDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/spark","spark.student", prop)
4. 任务:编写一个Spark应用程序,实现协同过滤算法。
val spark = SparkSession.builder().appName("sparkmllibtest").master("local[2]").getOrCreate()
val ratings = spark.sparkContext.textFile("file:///usr/local/spark/data/mllib/als/sample_movielens_ratings.txt").map(parseRating).toDF()
ratings.show()
//把MovieLens数据集划分训练集和测试集,其中,训练集占80%,测试集占20%
val Array(training,test) = ratings.randomSplit(Array(0.8,0.2))
//使用ALS来建立推荐模型,这里我们构建了两个模型,一个是显性反馈,一个是隐性反馈
val alsExplicit = new ALS().setMaxIter(5).setRegParam(0.01).setUserCol("userId").setItemCol("movieId").setRatingCol("rating")
val alsImplicit = new ALS().setMaxIter(5).setRegParam(0.01).setImplicitPrefs(true).setUserCol("userId").setItemCol("movieId").setRatingCol("rating")
//把推荐模型放在训练数据上训练
val modelExplicit = alsExplicit.fit(training)
val modelImplicit = alsImplicit.fit(training)
//使用训练好的推荐模型对测试集中的用户商品进行预测评分,得到预测评分的数据集
val predictionsExplicit = modelExplicit.transform(test).na.drop()
val predictionsImplicit = modelImplicit.transform(test).na.drop()
predictionsExplicit.show()
predictionsImplicit.show()
//通过计算模型的均方根误差来对模型进行评估,均方根误差越小,模型越准确
val evaluator = new RegressionEvaluator().setMetricName("rmse").setLabelCol("rating").setPredictionCol("prediction")
val rmseExplicit = evaluator.evaluate(predictionsExplicit)
val rmseImplicit = evaluator.evaluate(predictionsImplicit)
本文来自博客园,作者:海边星,转载请注明原文链接:https://www.cnblogs.com/StarsbySea/p/16503172.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号