

大数据分析基础——维度模型
1基本概念
维度模型的概念出自于数据仓库领域,是数据仓库建设中的一种数据建模方法。维度模型主要由事实表和维度表这两个基本要素构成。
1.1维度
维度是度量的环境,用来反映业务的一类属性 , 这类属性的集合构成一个维度 , 也可以称为实体对象。 维度属于一个数据域,如地理维度(其中包括国家、地区、 省以及城市等级别的内容)、时间维度(其中包括年、季、月、周、日等级别的内容)。
维度是维度建模的基础和灵魂。在维度建模中,将度量称为“事实” , 将环境描述为“维度”,维度是用于分析事实所需要的多样环境。例如, 在分析交易过程时,可以通过买家、卖家、商品和时间等维度描述交易发生的环境。
维度所包含的表示维度的列,称为维度属性。维度属性是查询约束条件、分组和报表标签生成的基本来源,是数据易用性的关键。
1.2事实表
事实表是维度模型的基本表,每个数据仓库都包含一个或者多个事实数据表。事实数据表可能包含业务销售数据,如销售商品所产生的数据,与软件中实际表概念一样。
事实表作为数据仓库维度建模的核心,紧紧围绕着业务过程来设计,通过获取描述业务过程的度量来表达业务过程,包含了引用的维度和与业务过程有关的度量。
事实表中一条记录所表达的业务细节程度被称为粒度。通常粒度可以通过两种方式来表述:一种是维度属性组合所表示的细节程度:一种是所表示的具体业务含义。
作为度量业务过程的事实,一般为整型或浮点型的十进制数值,有可加性、半可加性和不可加性三种类型。
相对维度来说,通常事实表要细长,行的增加速度也比维度表快的多,维度表正好相反。
事实表有三种类型 :
- 事务事实表:事务事实表用来描述业务过程,眼踪空间或时间上某点的度量事件,保存的是最原子的数据,也称为“原子事实表\周期快照事实表”。
- 周期快照事实表:周期快照事实表以具有规律性的、可预见的时间间隔记录事实 ,时间间隔如每天、每月、每年等。
- 累积快照事实表:累积快照事实表用来表述过程开始和结束之间的关键步骤事件,覆盖过程的整个生命周期,通常具有多个日期字段来记录关键时间点,当过程随着生命周期不断变化时,记录也会随着过程的变化而被修改。
1.3度量 / 原子指标
原子指标和度量含义相同,基于某一业务事件行为下的度量,是业务定义中不可 再拆分的指标,具有明确业务含义的名词 ,如支付金额。
事实表和维度交叉汇聚的点,度量和维度构成OLAP的主要概念,这里面对于在事实表或者一个多维立方体里面存放的数值型的、连续的字段,就是度量。
1.4维度表与事实表
维度表是事实表不可分割的部分。维度表是进入事实表的入口。丰富的维度属性给出了丰富的分析切割能力。维度给用户提供了使用数据仓库的接口。最好的属性是文本的和离散的。属性应该是真正的文字而不应是一些编码简写符号。应该通过用更为详细的文本属性取代编码,力求最大限度地减少编码在维度表中的使用。
维度表和事实表二者的融合也就是“维度模型”,“维度模型”一般采用“星型模式”或者“雪花模式”,“雪花模式”可以看作是“星型模式”的拓展,表现为在维度表中,某个维度属性可能还存在更细粒度的属性描述,即维度表的层级关系。
维度属性也可以存储到事实表中,这种存储到事实表中的维度列被称为“退化维度”。与其他存储在维表中的维度一样 ,退化维度也可以用来进行事实表的过滤查询、实现聚合操作等。
1.5维度与指标例子
下表显示的是一个维度(“城市”)和两个指标(“会话数”和“每次会话浏览页数”)。
| 维度 | 指标 | 指标 |
|---|---|---|
| 城市 | 会话数 | 每次会话浏览页数 |
| 旧金山 | 5,000 | 3.74 |
| 柏林 | 4,000 | 4.55 |
2 维度设计
2.1维度基本设计方法
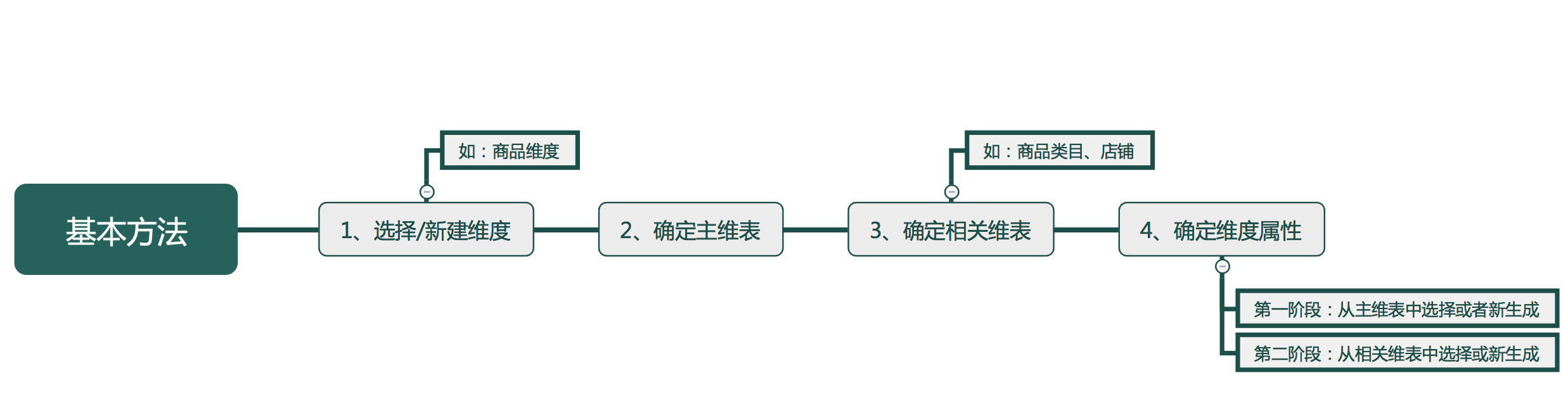
2.2维度的特点
2.2.1维度的层次结构
维度中的一些描述属性以层次方式或一对多的方式相互关联,可以被理解为包含连续主从关系的属性层次。比如商品类目的最低级别是叶子类目,叶子类目属于二级类目,二级类目属于一级类目。在属性的层次结构中进行钻取是数据钻取的方法之一。
2.2.2范式与反范式
当属性层次被实例化为一系列维度,而不是单一的维度时,被称为雪花模式。
大多数联机事务处理系统( OLTP)的底层数据结构在设计时采用此种规范化技术,通过规范化处理将重复属性移至其自身所属的表中,删除冗余数据。
将维度的属性层次合并到单个维度中的操作称为反规范化。分析系 统的主要目的是用于数据分析和统计,如何更方便用户进行统计分析决 定了分析系统的优劣。采用雪花模式,用户在统计分析的过程中需要 大 量的关联操作,使用复杂度高,同时查询性能很差;而采用反规范化处 理,则方便、易用且性能好。
2.3交叉探查
数据仓库总线架构的重要基石之一就是一致性维度。在针对不同数 据域进行迭代构建或并行构建时,存在很多需求是对于不同数据域的业 务过程或者同 一数据域的不同业务过程合并在 一起观察。比如对于日志数据域,统计了商品维度的最近一天的 PV 和 UV; 对于交易数据域, 统计了商品维度的最近一天的下单MV。现在将不同数据域的商品的 事实合并在一起进行数据探查 ,如计算转化率等,称为交叉探查。
2.4维度整合
我们先来看数据仓库的定义:数据仓库是一个面向主题的、集成的、 非易失的且随时间变化的数据集合,用来支持管理人员的决策。
数据由面向应用的操作型环境进人数据仓库后,需要进行数据 集成。将面向应用的数据转换为面向主题的数据仓库数据,本身就是一种集成。
具体体现在如下几个方面:
- 命名规范的统一。
- 字段类型的统一。
- 公共代码及代码值的统一。
- 业务含义相同的表的统一 。主要依据高内聚、低稠合的理念,在物理实现中,将业务关系大、源系统影响差异小的表进行整合。
表级别的整合,有两种表现形式。
-
垂直整合,即不同的来源表包含相同的数据集,只是存储的信息不同。比如商品基础信息表、 商品扩展信息表、商品库存信息表,这些表都属于商品相关信息表,依据维度设计方法,尽量整合至商品维度模型中,丰富其维度属性。
-
水平整合,即不同的来源表包含不同的数据集,不同子集之间无交叉,也可以存在部分交叉。如果进行整合,首先需要考虑各个体系是否有交叉,如果存在交叉,则需要去重;如果不存在交叉,则需要考虑不同子集的自然键是否存在冲突,如果不冲突, 则可以考虑将各子集的自然键作为整合后的表的自然键;另一种方式是设置超自然键,将来源表各子集的自然键加工成一个字段作为超自然键。
2.5维度拆分
水平拆分
维度通常可以按照类别或类型进行细分。由于维度分类的不同而存在特殊的维度属性,可以通过水平拆分的方式解决此问题。
在设计过程中需要重点考虑以下三个原则。
- 扩展性:当源系统、业务逻辑变化时,能通过较少的成本快速扩 展模型,保持核心模型的相对稳定性。软件工程中的高内聚、低 稠合的思想是重要的指导方针之 一 。
- 效能 : 在性能和成本方面取得平衡。通过牺牲一定的存储成本, 达到性能和逻辑的优化。
- 易用性:模型可理解性高、访问复杂度低。用户能够方便地从模 型中找到对应的数据表,并能够方便地查询和分析。
根据数据模型设计思想,在对维度进行水平拆分时,主要考虑如下两个依据。
- 维度的不同分类的属性差异情况
- 业务的关联程度
垂直拆分
在维度设计内容中,我们提到维度是维度建模的基础和灵魂,维度 属性的丰富程度直接决定了数据仓库的能力。在进行维度设计时,依据 维度设计的原则,尽可能丰富维度属性,同时进行反规范化处理。
某些维度属性的来源表产出时间较早,而某些维度属性的来 源 表产出时间较晚;或者某些维度属性的热度高、使用频繁,而某些维度属性的热度低、较少使用 ; 或者某些维度属性经常变化,而某些维度属性比较稳定。在“水平拆分”中提到的模型设计的三个原则同样适合解决此问题。
出于扩展性、产出时间、易用性等方面的考虑,设计 主从维度。主 维表存放稳定 、 产出时间早、热度高的属性;从维表存放变化较快、产 出时间晚、热度低的属性。
参考
《The Data Warehouse Toolkit-The Complete Guide to Dimensional Modeling》
《Google Analytics》
《大数据之路》
作者:高广超
链接:https://www.jianshu.com/p/58da1060f0f5
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号